CosyEdit2: Speech-Editing-Oriented Reinforcement Learning Unlocks Better Zero-Shot TTS
Pith reviewed 2026-06-29 20:25 UTC · model grok-4.3
The pith
Reinforcement learning tuned for speech editing also improves zero-shot TTS.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
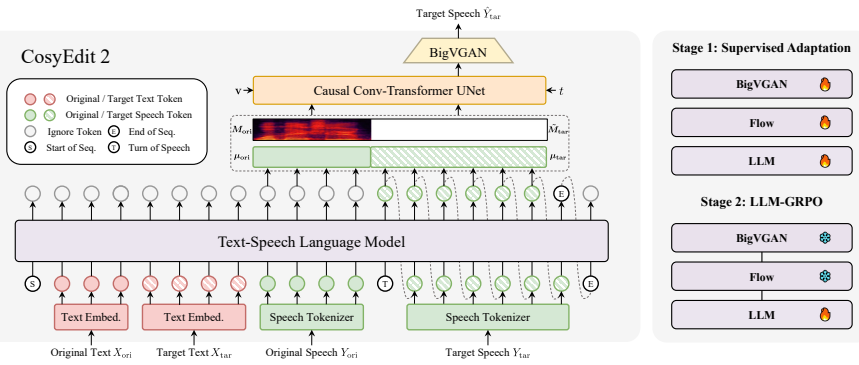
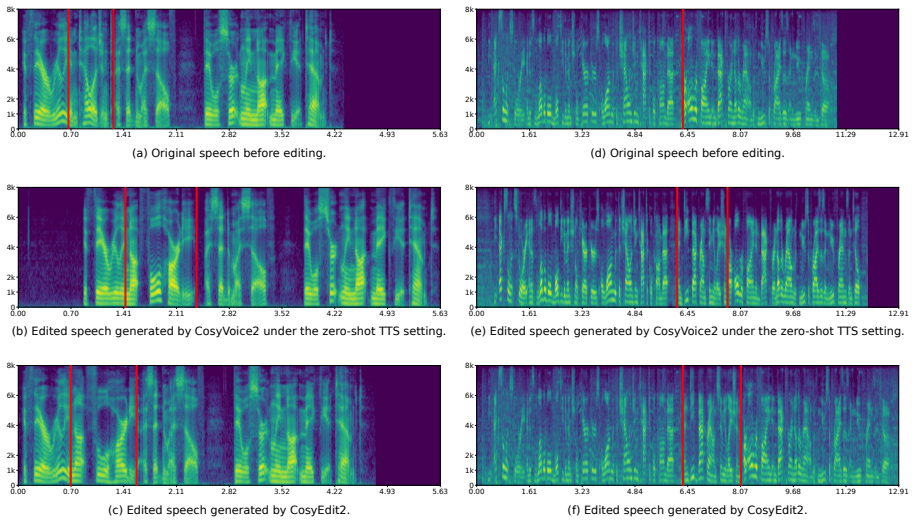
CosyEdit2 advances speech editing by progressing from supervised editing initialization to editing-oriented Group Relative Policy Optimization over target-speech-free data. This not only substantially advances speech editing performance but also unlocks better zero-shot TTS capability, revealing a deeper mutual relationship between the two tasks that share a generative foundation conditioned on speech prompts.
What carries the argument
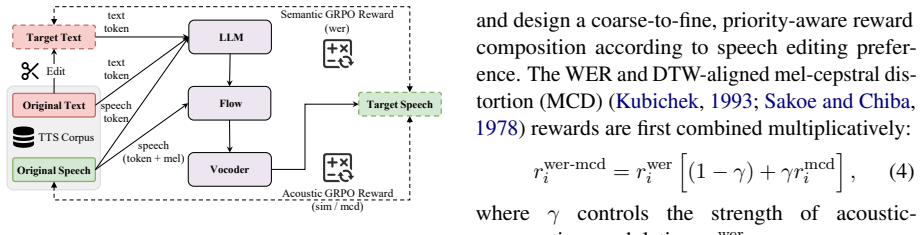
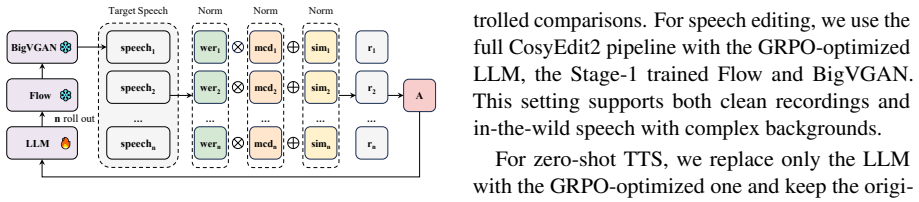
Editing-oriented Group Relative Policy Optimization (GRPO) applied after supervised fine-tuning, which supplies optimization signals for local acoustic consistency using target-speech-free data.
If this is right
- Speech editing achieves stricter local acoustic consistency with surrounding unedited content than SFT alone provides.
- Zero-shot TTS performance improves through the editing-oriented training signals.
- The mutual relationship between speech editing and zero-shot TTS strengthens via shared conditioning on speech prompts.
- Post-training can advance beyond SFT bottlenecks by using GRPO on unpaired data.
Where Pith is reading between the lines
- Training pipelines that combine editing and synthesis objectives could further exploit their mutual benefits in other conditional generative settings.
- Target-speech-free data strategies might reduce reliance on scarce paired datasets for related audio generation tasks.
- Local consistency enforcement via reinforcement learning could extend to other sequential editing problems such as music or video.
Load-bearing premise
That editing-oriented GRPO on target-speech-free data supplies optimization signals strong enough to overcome the limitations of imperfect paired editing data without introducing new inconsistencies in local acoustics.
What would settle it
A controlled comparison where the GRPO stage is added to the SFT baseline and zero-shot TTS metrics or local consistency scores in edited regions fail to improve or degrade relative to the SFT-only model.
Figures
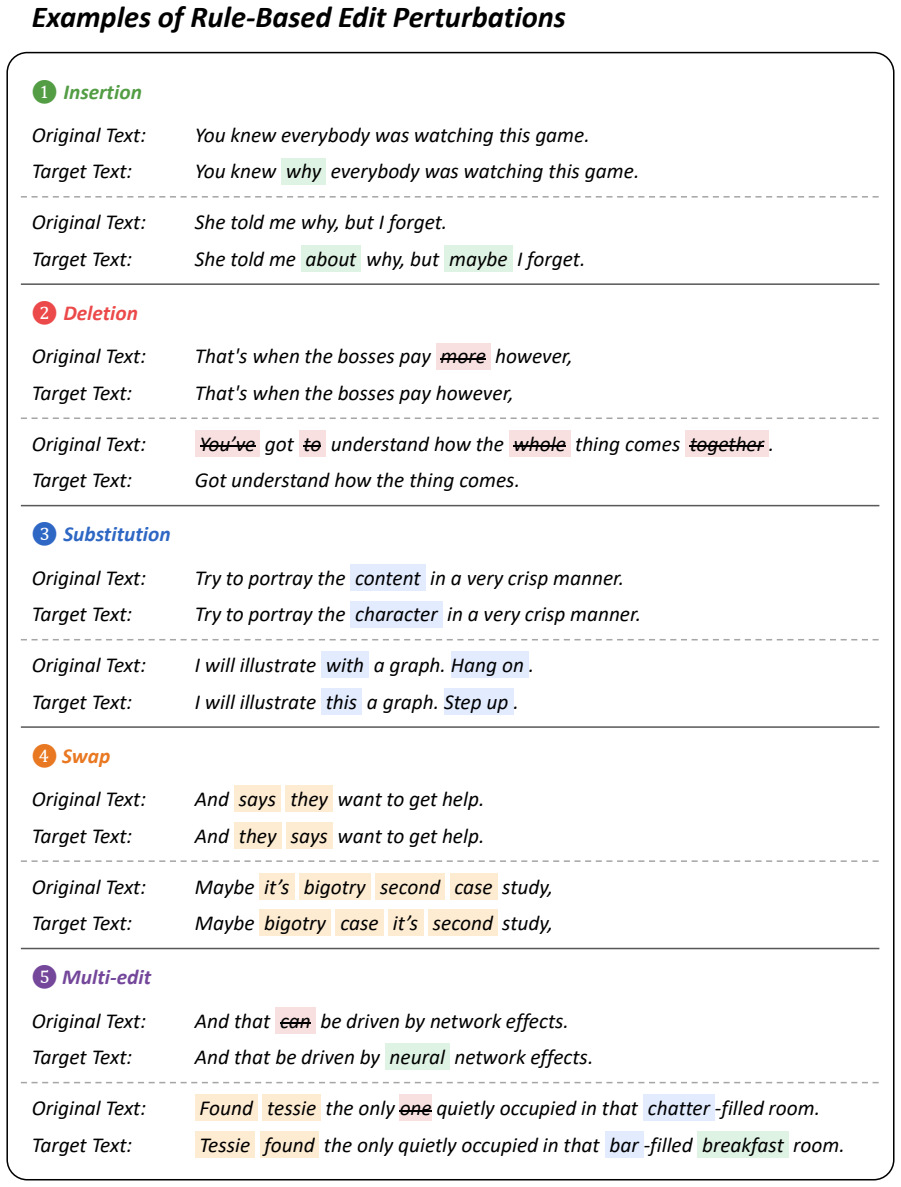
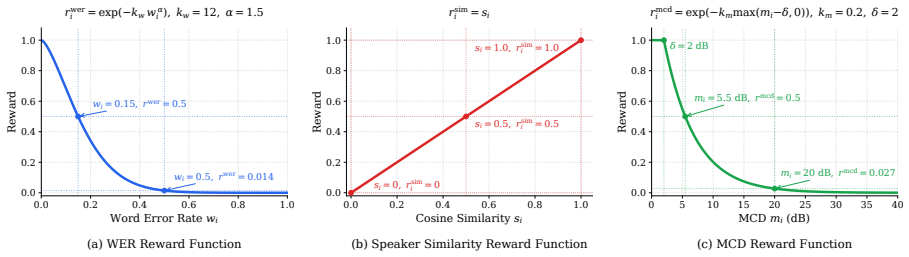
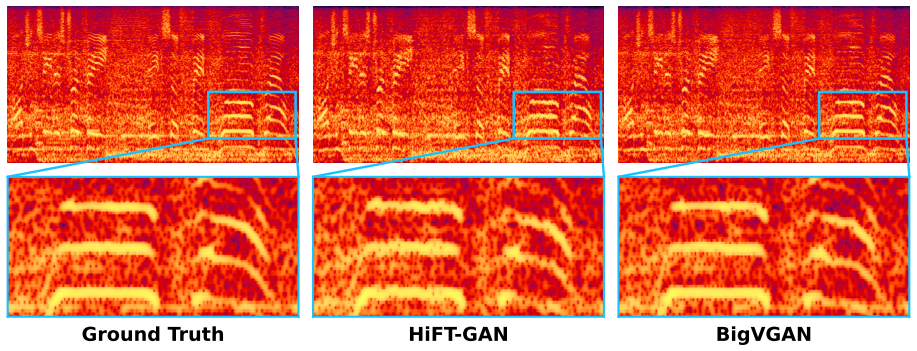
read the original abstract
Speech editing and zero-shot Text-to-Speech (TTS) share a similar generative foundation conditioned on speech prompts, yet speech editing demands far stricter local acoustic consistency with surrounding unedited content. While prior work has shown that Supervised Fine-Tuning (SFT) enables TTS models to acquire functional editing capability, this approach remains fundamentally bottlenecked by imperfect paired editing data and coarse-grained optimization signals. To address these limitations, we propose CosyEdit2, a speech editing model built on a two-stage post-training framework that progresses from supervised editing initialization to editing-oriented Group Relative Policy Optimization (GRPO) over target-speech-free data. Extensive experiments demonstrate that CosyEdit2 not only substantially advances speech editing performance, but also unlocks better zero-shot TTS capability, revealing a deeper mutual relationship between the two tasks. Audio samples are available at https://cjy1018.github.io/CosyEdit2.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CosyEdit2, a speech-editing model that employs a two-stage post-training pipeline: supervised fine-tuning (SFT) initialization on paired editing data, followed by editing-oriented Group Relative Policy Optimization (GRPO) on target-speech-free unpaired data. It claims this framework substantially advances speech-editing performance while also improving zero-shot TTS capability, thereby revealing a deeper mutual relationship between the two tasks.
Significance. If the empirical claims hold, the work would provide evidence that RL-based optimization on unpaired data can overcome limitations of imperfect paired data in speech editing and yield transferable gains to zero-shot TTS, supporting a bidirectional training relationship between the tasks.
major comments (1)
- [Abstract] Abstract: the central claim that 'extensive experiments demonstrate' substantial advances in speech editing and unlocked zero-shot TTS performance is unsupported by any reported metrics, baselines, statistical tests, or dataset details. Without these, the empirical foundation of the mutual-relationship conclusion cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for their review. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 'extensive experiments demonstrate' substantial advances in speech editing and unlocked zero-shot TTS performance is unsupported by any reported metrics, baselines, statistical tests, or dataset details. Without these, the empirical foundation of the mutual-relationship conclusion cannot be assessed.
Authors: The abstract is a high-level summary and does not contain numerical results, as is conventional due to length limits. The full manuscript reports the supporting experiments, including quantitative metrics on editing consistency and zero-shot TTS, baseline comparisons, and dataset details in the Experiments section. To directly address the concern, we will revise the abstract to include one or two key quantitative highlights (e.g., relative gains on standard metrics). revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description outline a standard empirical two-stage pipeline (SFT initialization followed by GRPO on target-speech-free data) whose central claim is an observed empirical improvement in both editing and zero-shot TTS. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing self-citations appear in the text. The derivation chain is self-contained as an experimental training procedure without any reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption RL policy optimization on group-relative rewards yields finer acoustic consistency than SFT on paired data
Reference graph
Works this paper leans on
-
[1]
Glm-tts technical report.arXiv preprint arXiv:2512.14291, 2025
Glm-tts technical report.arXiv preprint arXiv:2512.14291. Zhihao Du, Qian Chen, Shiliang Zhang, Kai Hu, Heng Lu, Yexin Yang, Hangrui Hu, Siqi Zheng, Yue Gu, Ziyang Ma, and 1 others. 2024a. Cosyvoice: A scal- able multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens.CoRR. Zhihao Du, Changfeng Gao, Yuxuan Wang, Fan Yu, Tiany...
-
[2]
Dnsmos p. 835: A non-intrusive perceptual objective speech quality metric to evaluate noise sup- pressors. InICASSP 2022-2022 IEEE international conference on acoustics, speech and signal process- ing (ICASSP), pages 886–890. IEEE. 10 Yong Ren, Jiangyan Yi, Jianhua Tao, Zhengqi Wen, and Tao Wang. 2026. Edit content, preserve acoustics: Imperceptible text-...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram. InICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 6199–6203. IEEE. Canxiang Yan, Chunxiang Jin, Dawei Huang, Haib- ing Yu, Han Peng, Hui Zhan, Jie Gao, Jing Peng, Jingdong ...
-
[4]
arXiv preprint arXiv:2511.21270 , year=
Multi-reward grpo for stable and prosodic single-codebook tts llms at scale.arXiv preprint arXiv:2511.21270. Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. 2026. In- dextts2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech. InProceedings of the AAAI Confer- ence ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.