Scalable Algorithm for Dynamic Quasi-clique Detection
Pith reviewed 2026-06-29 19:05 UTC · model grok-4.3
The pith
DMI uses MinHash schemes and periodic batch rebuilds to maintain the largest quasi-clique under continuous edge updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
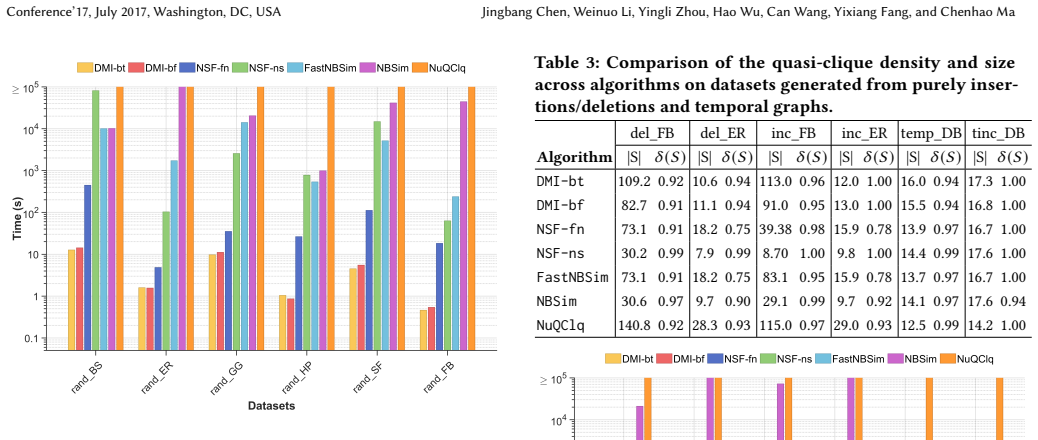
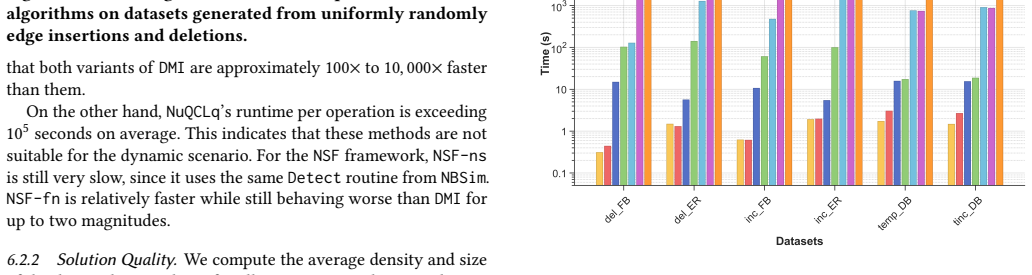
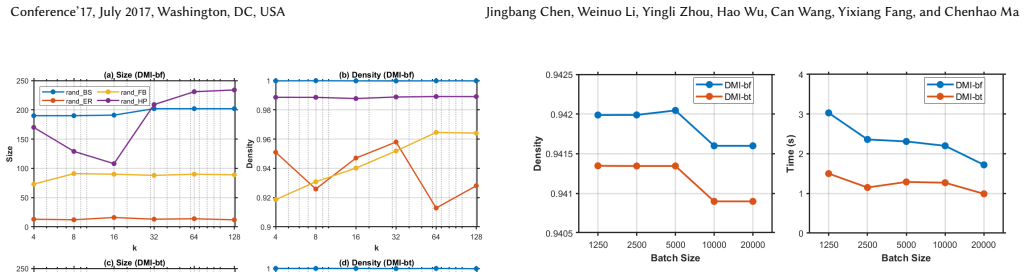
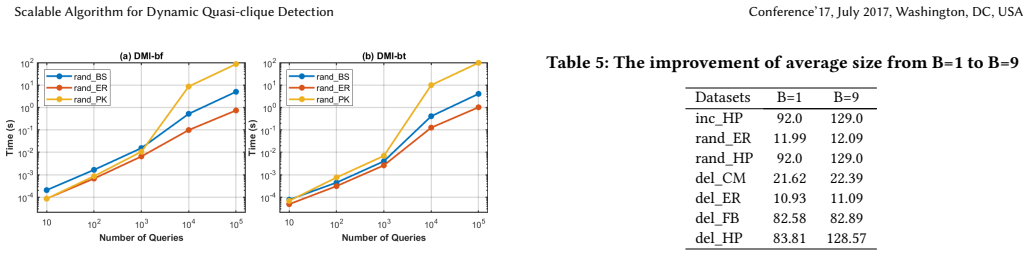
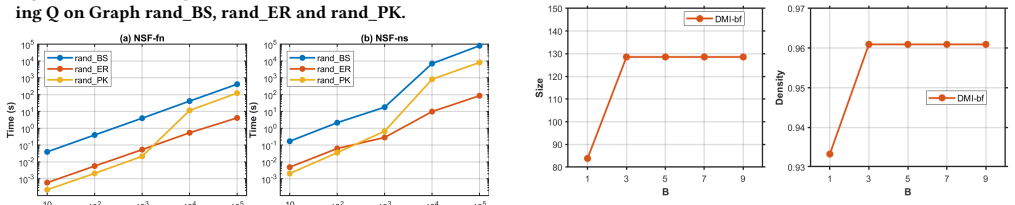
The authors establish that their DMI framework, built on l-buffered k-MinHash and Bottom-k MinHash schemes together with a batch reconstruction strategy, can maintain high-quality approximate maximum quasi-cliques in dynamic graphs efficiently, delivering up to four orders of magnitude speedup over static baselines while preserving solution quality.
What carries the argument
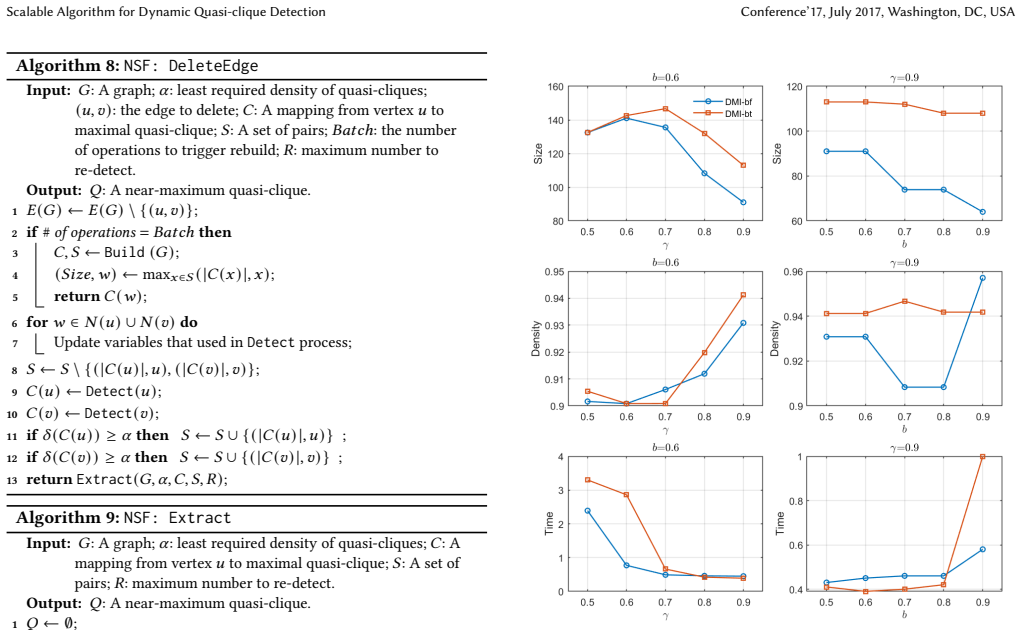
l-buffered k-MinHash and Bottom-k MinHash schemes combined with periodic batch reconstruction to maintain candidate quasi-cliques incrementally under updates.
If this is right
- Real-time dense subgraph mining becomes feasible in networks that change continuously.
- An alternative neighbor-search framework called NSF is also supplied for maintaining quasi-clique candidates.
- Applications in social networks, biology, and e-commerce can track dense substructures without full restarts after each change.
- The method supplies the first algorithmic support for the Dynamic Maximum Quasi-Clique Problem.
Where Pith is reading between the lines
- The same incremental MinHash approach could be tested on related problems such as dynamic community detection.
- Performance under very high update rates might require adjusting the reconstruction interval based on observed drift.
- The framework might extend naturally to weighted or directed edges if the hashing schemes are adapted accordingly.
Load-bearing premise
The l-buffered k-MinHash and Bottom-k MinHash schemes combined with periodic batch reconstruction maintain high-quality approximate quasi-clique candidates under frequent updates without significant bias or quality loss.
What would settle it
A stream of updates on a real graph where the quasi-clique size or density reported by DMI falls measurably below the result of a full static recomputation performed after the same updates.
Figures

read the original abstract
Identifying dense subgraphs known as quasi-cliques is pivotal in numerous graph mining tasks across domains such as social networks, biology, and e-commerce. While prior work has developed efficient algorithms for quasi-clique detection in static graphs, real-world networks are inherently dynamic, where edges appear and disappear continuously. This renders static methods inefficient and ill-suited for real-time analysis. In this paper, we initiate the study of the Dynamic Maximum Quasi-Clique Problem (DMQCP), which aims to maintain and update the largest quasi-clique in a graph under streaming graph updates. We propose DMI, a novel MinHash-based dynamic framework that supports fast, high-quality approximate maintenance of quasi-cliques. DMI leverages two update-efficient hashing schemes, i.e., $l$-buffered $k$-MinHash and Bottom-$k$ MinHash, to maintain candidate quasi-cliques incrementally. To ensure robustness and reduce bias, we further design a batch reconstruction strategy to periodically rebuild the candidate set, guaranteeing both stability and adaptability under frequent updates. Extensive experiments on real-world and synthetic datasets show that DMI achieves up to four orders of magnitude speedup over static baselines, while preserving solution quality. As a side product, we also propose a framework NSF that primarily uses the neighbor-search technique to maintain quasi-clique candidates while edge updating. This work establishes the first efficient algorithmic framework for dynamic quasi-clique extraction, enabling scalable and real-time dense subgraph mining in evolving networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Dynamic Maximum Quasi-Clique Problem (DMQCP) and proposes DMI, a MinHash-based dynamic framework that uses l-buffered k-MinHash and Bottom-k MinHash schemes together with periodic batch reconstruction to incrementally maintain approximate maximum quasi-clique candidates under streaming edge updates. It additionally presents NSF, a neighbor-search-based framework for the same task. Experiments on real-world and synthetic datasets are reported to demonstrate up to four orders of magnitude speedup relative to static baselines while preserving solution quality, establishing the first efficient algorithmic framework for dynamic quasi-clique extraction.
Significance. If the empirical claims hold, the work is significant for filling a gap in dynamic graph mining by enabling scalable, real-time dense subgraph analysis in evolving networks relevant to social networks, biology, and e-commerce. Strengths include the adaptation of established MinHash techniques to the dynamic setting, the provision of reproducible code, and direct static-versus-dynamic quality comparisons rather than untested assumptions.
minor comments (2)
- The abstract states that DMI 'preserves solution quality' but does not name the concrete quality metric (e.g., relative size, Jaccard overlap) used in the reported comparisons; this should be stated explicitly even in the abstract.
- The description of NSF is limited to a single sentence; a brief statement of how it differs from DMI in update mechanism would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on the Dynamic Maximum Quasi-Clique Problem and the DMI framework, as well as the recommendation to accept the manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper proposes a new algorithmic framework (DMI) for the dynamic maximum quasi-clique problem by applying established MinHash techniques (l-buffered k-MinHash and Bottom-k MinHash) plus a periodic batch reconstruction heuristic to streaming graph updates. No derivation chain, equations, or predictions are shown that reduce to fitted parameters or self-citations by construction; the central claims rest on empirical speed/quality comparisons against static baselines rather than any self-referential definition or uniqueness theorem imported from prior author work. The approach is self-contained against external benchmarks via reported experiments and reproducible code.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption MinHash sketches can efficiently approximate set similarities for identifying quasi-clique candidates under updates
Reference graph
Works this paper leans on
-
[1]
James Abello, Mauricio GC Resende, and Sandra Sudarsky. 2002. Massive quasi- clique detection. InLATIN 2002: Theoretical Informatics: 5th Latin American Sym- posium Cancun, Mexico, April 3–6, 2002 Proceedings 5. Springer, 598–612
2002
-
[2]
Balabhaskar Balasundaram, Sergiy Butenko, and Illya V Hicks. 2011. Clique relaxations in social network analysis: The maximum k-plex problem.Operations Research59, 1 (2011), 133–142
2011
-
[3]
Vladimir Batagelj and Matjaz Zaversnik. 2003. An O (m) algorithm for cores decomposition of networks.arXiv preprint cs/0310049(2003)
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[4]
Alex Beutel, Wanhong Xu, Venkatesan Guruswami, Christopher Palow, and Christos Faloutsos. 2013. Copycatch: stopping group attacks by spotting lockstep behavior in social networks. InWWW. 119–130
2013
-
[5]
Lijun Chang. 2019. Efficient maximum clique computation over large sparse graphs. InProceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 529–538
2019
-
[6]
Lijun Chang. 2023. Efficient maximum k-defective clique computation with improved time complexity.Proceedings of the ACM on Management of Data1, 3 (2023), 1–26
2023
-
[7]
Lijun Chang, Jeffrey Xu Yu, and Lu Qin. 2013. Fast maximal cliques enumeration in sparse graphs.Algorithmica66 (2013), 173–186
2013
-
[8]
Jiejiang Chen, Shaowei Cai, Shiwei Pan, Yiyuan Wang, Qingwei Lin, Mengyu Zhao, and Minghao Yin. 2021. NuQClq: An effective local search algorithm for maximum quasi-clique problem. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 12258–12266
2021
-
[9]
Lu Chen, Chengfei Liu, Rui Zhou, Jiajie Xu, and Jianxin Li. 2022. Efficient maximal biclique enumeration for large sparse bipartite graphs.Proceedings of the VLDB Endowment15, 8 (2022), 1559–1571
2022
-
[10]
James Cheng, Yiping Ke, Ada Wai-Chee Fu, Jeffrey Xu Yu, and Linhong Zhu. 2011. Finding maximal cliques in massive networks.ACM Transactions on Database Systems (TODS)36, 4 (2011), 1–34
2011
-
[11]
Andrea Clementi, Luciano Gualà, Luca Pepè Sciarria, and Alessandro Straziota
-
[12]
InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining
Maintaining k-MinHash Signatures over Fully-Dynamic Data Streams with Recovery. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 79–87
-
[13]
Alessio Conte, Mamadou Moustapha Kanté, Takeaki Uno, and Kunihiro Wasa
-
[14]
Maximal strongly connected cliques in directed graphs: Algorithms and bounds.Discrete Applied Mathematics303 (2021), 237–252
2021
-
[15]
Wanyun Cui, Yanghua Xiao, Haixun Wang, Yiqi Lu, and Wei Wang. 2013. Online search of overlapping communities. InProceedings of the 2013 ACM SIGMOD international conference on Management of data. 277–288
2013
-
[16]
Qiangqiang Dai, Rong-Hua Li, Meihao Liao, Hongzhi Chen, and Guoren Wang
-
[17]
InProceedings of the 2022 International Conference on Management of Data
Fast maximal clique enumeration on uncertain graphs: A pivot-based approach. InProceedings of the 2022 International Conference on Management of Data. 2034–2047
2022
-
[18]
Qiangqiang Dai, Rong-Hua Li, Meihao Liao, and Guoren Wang. 2023. Maximal defective clique enumeration.Proceedings of the ACM on Management of Data1, 1 (2023), 1–26
2023
-
[19]
Maximilien Danisch, Oana Balalau, and Mauro Sozio. 2018. Listing k-cliques in sparse real-world graphs. InProceedings of the 2018 World Wide Web Conference. 589–598
2018
-
[20]
Apurba Das, Michael Svendsen, and Srikanta Tirthapura. 2019. Incremental maintenance of maximal cliques in a dynamic graph.The VLDB Journal28, 3 (2019), 351–375
2019
-
[21]
Wen Deng, Weiguo Zheng, and Hong Cheng. 2024. Accelerating Maximal Clique Enumeration via Graph Reduction.Proceedings of the VLDB Endowment17, 10 (2024), 2419–3431
2024
-
[22]
Laxman Dhulipala, Quanquan C Liu, Julian Shun, and Shangdi Yu. 2021. Parallel batch-dynamic k-clique counting. InSymposium on Algorithmic Principles of Computer Systems (APOCS). SIAM, 129–143
2021
-
[23]
David Eppstein, Maarten Löffler, and Darren Strash. 2013. Listing all maximal cliques in large sparse real-world graphs.Journal of Experimental Algorithmics (JEA)18 (2013), 3–1
2013
-
[24]
Yixiang Fang, Xin Huang, Lu Qin, Ying Zhang, Wenjie Zhang, Reynold Cheng, and Xuemin Lin. 2020. A survey of community search over big graphs.VLDBJ 29, 1 (2020), 353–392
2020
-
[25]
Yixiang Fang, Wensheng Luo, and Chenhao Ma. 2022. Densest subgraph discovery on large graphs: Applications, challenges, and techniques.Proceedings of the VLDB Endowment15, 12 (2022), 3766–3769
2022
-
[26]
Irene Finocchi, Marco Finocchi, and Emanuele G Fusco. 2015. Clique counting in mapreduce: Algorithms and experiments.Journal of Experimental Algorithmics (JEA)20 (2015), 1–20
2015
-
[27]
David Gibson, Ravi Kumar, and Andrew Tomkins. 2005. Discovering large dense subgraphs in massive graphs. InVLDB. Citeseer, 721–732
2005
-
[28]
Guimu Guo, Da Yan, Lyuheng Yuan, Jalal Khalil, Cheng Long, Zhe Jiang, and Yang Zhou. 2022. Maximal directed quasi-clique mining. In2022 IEEE 38th international conference on data engineering (ICDE). IEEE, 1900–1913
2022
-
[29]
Bryan Hooi, Hyun Ah Song, Alex Beutel, Neil Shah, Kijung Shin, and Christos Faloutsos. 2016. Fraudar: Bounding graph fraud in the face of camouflage. In Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. 895–904
2016
-
[30]
Shweta Jain and C Seshadhri. 2020. The power of pivoting for exact clique counting. InProceedings of the 13th International Conference on Web Search and Data Mining. 268–276
2020
-
[31]
Rui Jiang, Zhidong Tu, Ting Chen, and Fengzhu Sun. 2006. Network motif identification in stochastic networks.Proceedings of the National Academy of Sciences103, 25 (2006), 9404–9409
2006
-
[32]
Aritra Konar and Nicholas D Sidiropoulos. 2020. Mining large quasi-cliques with quality guarantees from vertex neighborhoods. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 577–587
2020
-
[33]
Jérôme Kunegis. 2013. Konect: the koblenz network collection. InProceedings of the 22nd international conference on world wide web. 1343–1350
2013
-
[34]
Jure Leskovec and Andrej Krevl. 2014. SNAP Datasets: Stanford large network dataset collection
2014
-
[35]
Ronghua Li, Sen Gao, Lu Qin, Guoren Wang, Weihua Yang, and Jeffrey Xu Yu
-
[36]
VLDB Endow.(2020)
Ordering Heuristics for k-clique Listing.Proc. VLDB Endow.(2020)
2020
-
[37]
Can Lu, Jeffrey Xu Yu, Hao Wei, and Yikai Zhang. 2017. Finding the maximum clique in massive graphs.Proceedings of the VLDB Endowment10, 11 (2017), 1538–1549
2017
-
[38]
Bingqing Lyu, Lu Qin, Xuemin Lin, Ying Zhang, Zhengping Qian, and Jingren Zhou. 2020. Maximum biclique search at billion scale.Proceedings of the VLDB Endowment(2020)
2020
-
[39]
Chenhao Ma, Yixiang Fang, Reynold Cheng, Laks VS Lakshmanan, and Xiaolin Han. 2022. A convex-programming approach for efficient directed densest sub- graph discovery. InProceedings of the 2022 International Conference on Manage- ment of Data. 845–859
2022
-
[40]
Chenhao Ma, Yixiang Fang, Reynold Cheng, Laks VS Lakshmanan, Wenjie Zhang, and Xuemin Lin. 2021. Efficient directed densest subgraph discovery.ACM SIGMOD Record50, 1 (2021), 33–40
2021
-
[41]
Kazuhisa Makino and Takeaki Uno. 2004. New algorithms for enumerating all maximal cliques. InAlgorithm Theory-SW AT 2004: 9th Scandinavian Workshop on Algorithm Theory, Humlebæk, Denmark, July 8-10, 2004. Proceedings 9. Springer, 260–272
2004
-
[42]
Jiayang Pang, Chenhao Ma, and Yixiang Fang. 2024. A similarity-based approach for efficient large quasi-clique detection. InProceedings of the ACM Web Conference
2024
-
[43]
Jeffrey Pattillo, Alexander Veremyev, Sergiy Butenko, and Vladimir Boginski
-
[44]
On the maximum quasi-clique problem.Discrete Applied Mathematics161, 1-2 (2013), 244–257
2013
-
[45]
Celso C Ribeiro and José A Riveaux. 2019. An exact algorithm for the maximum quasi-clique problem.International Transactions in Operational Research26, 6 (2019), 2199–2229
2019
-
[46]
Stephen B Seidman. 1983. Network structure and minimum degree.Social networks5, 3 (1983), 269–287
1983
-
[47]
Mikkel Thorup. 2013. Bottom-k and priority sampling, set similarity and subset sums with minimal independence. InProceedings of the forty-fifth annual ACM symposium on Theory of computing. 371–380
2013
-
[48]
Etsuji Tomita, Akira Tanaka, and Haruhisa Takahashi. 2006. The worst-case time complexity for generating all maximal cliques and computational experiments. Theoretical computer science363, 1 (2006), 28–42
2006
-
[49]
Charalampos Tsourakakis. 2015. The k-clique densest subgraph problem. In WWW. 1122–1132
2015
-
[50]
Charalampos Tsourakakis, Francesco Bonchi, Aristides Gionis, Francesco Gullo, and Maria Tsiarli. 2013. Denser than the densest subgraph: extracting optimal quasi-cliques with quality guarantees. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 104–112
2013
-
[51]
Alexander Veremyev, Oleg A Prokopyev, Sergiy Butenko, and Eduardo L Pasiliao
-
[52]
Exact MIP-based approaches for finding maximum quasi-cliques and dense subgraphs.Computational Optimization and Applications64, 1 (2016), 177–214
2016
-
[53]
Yixuan Yang, Fei Hao, Beibei Pang, Geyong Min, and Yulei Wu. 2021. Dynamic maximal cliques detection and evolution management in social Internet of Things: A formal concept analysis approach.IEEE transactions on network science and engineering9, 3 (2021), 1020–1032
2021
-
[54]
Xiaowei Ye, Rong-Hua Li, Qiangqiang Dai, Hongzhi Chen, and Guoren Wang
-
[55]
InProceedings of the ACM web conference 2022
Lightning fast and space efficient k-clique counting. InProceedings of the ACM web conference 2022. 1191–1202
2022
-
[56]
Kaiqiang Yu and Cheng Long. 2023. Fast maximal quasi-clique enumeration: A pruning and branching co-design approach.Proceedings of the ACM on Manage- ment of Data1, 3 (2023), 1–26
2023
-
[57]
Yingli Zhou, Qingshuo Guo, and Yixiang Fang. 2025. Efficient k-Clique Densest Subgraph Discovery: Towards Bridging Practice and Theory.Proceedings of the VLDB Endowment18, 10 (2025), 3490–3503
2025
-
[58]
Yingli Zhou, Qingshuo Guo, Yixiang Fang, and Chenhao Ma. 2024. A Counting- based Approach for Efficient k-Clique Densest Subgraph Discovery.Proceedings Scalable Algorithm for Dynamic Quasi-clique Detection Conference’17, July 2017, Washington, DC, USA of the ACM on Management of Data2, 3 (2024), 1–27
2024
- [59]
-
[60]
Yi Zhou, Shan Hu, Mingyu Xiao, and Zhang-Hua Fu. 2021. Improving maximum k-plex solver via second-order reduction and graph color bounding. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 12453–12460. Conference’17, July 2017, Washington, DC, USA Jingbang Chen, Weinuo Li, Yingli Zhou, Hao Wu, Can Wang, Yixiang Fang, and Chenhao M...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.