Agentic AI Workload Characteristics
Pith reviewed 2026-06-29 20:09 UTC · model grok-4.3
The pith
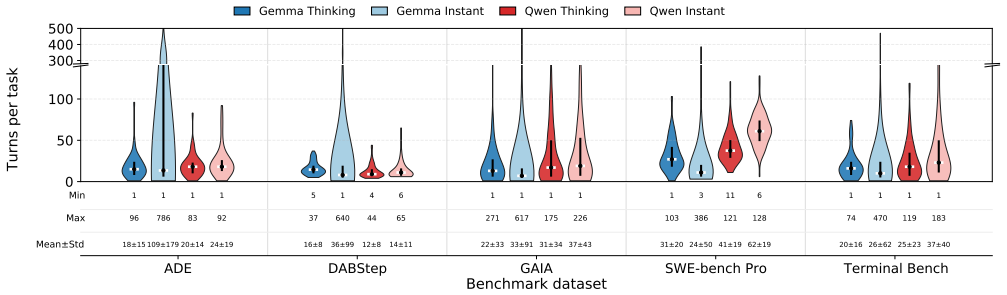
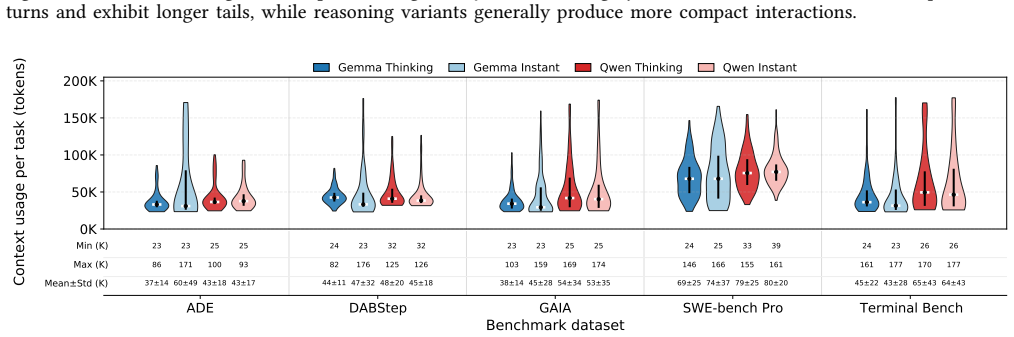
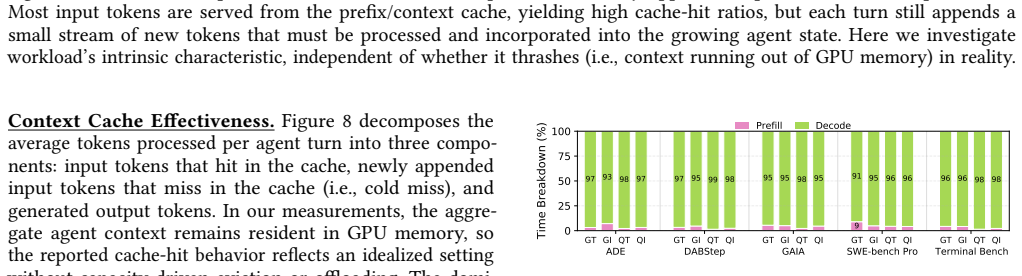
Agentic AI workloads become decode-dominated with context caching because most input tokens are reused across turns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
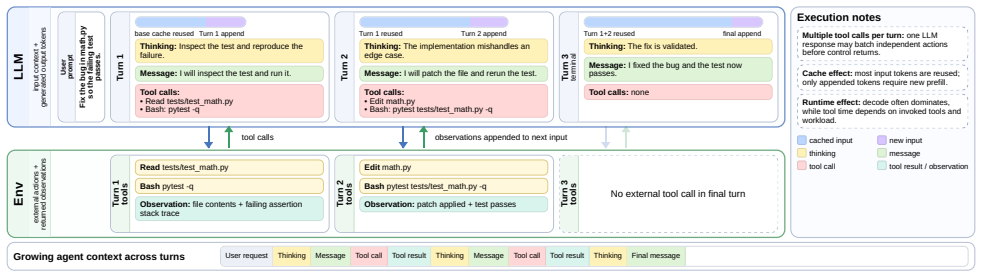
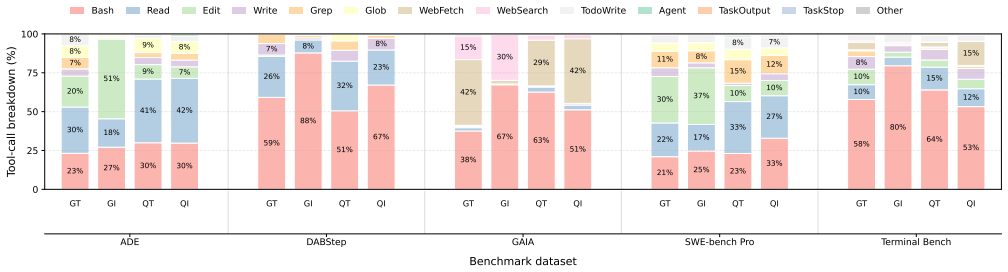
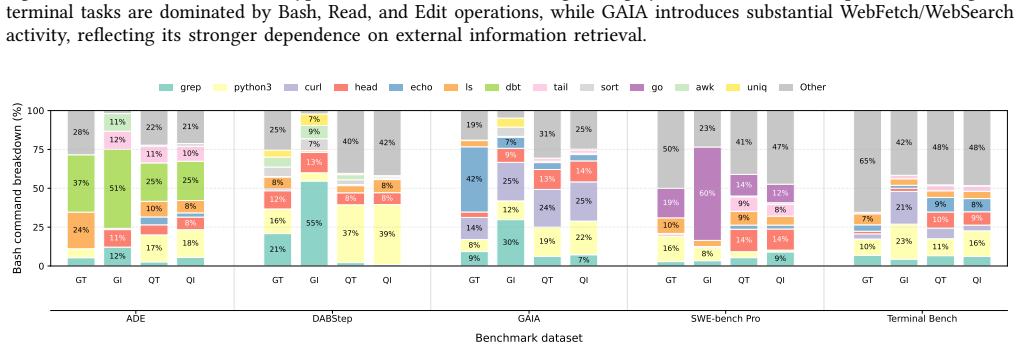
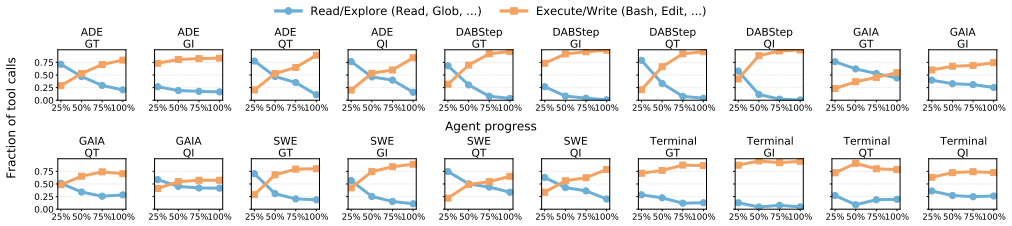
Agentic AI shifts LLM serving from isolated prompt-generation requests to stateful, multi-turn executions that repeatedly invoke the model, call tools, and grow context over time. With effective context caching, most input tokens are reused across turns, making execution decode-dominated while increasing dependence on long-lived KV-cache state. Tool use has a clear temporal structure, with agents shifting from read/explore behavior early in execution to execute/write behavior later.
What carries the argument
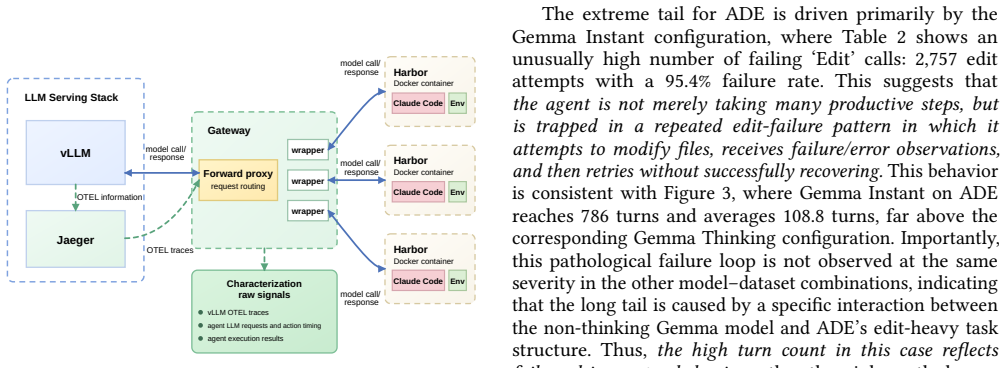
End-to-end tracing of ReAct-style agent executions that records both LLM calls and tool invocations across turns on multiple benchmarks.
If this is right
- Agentic workloads are not simply long-prompt workloads once caching is applied.
- Serving systems must jointly manage repeated model re-entry, persistent KV-cache state, and workload-dependent tool behavior.
- Decode phases dominate execution time, raising the relative cost of KV-cache residency.
- Tool-use patterns change over the lifetime of an agent run, so resource allocation can be phased accordingly.
Where Pith is reading between the lines
- Hardware designs that favor high decode throughput over prefill throughput may gain an advantage for agentic traffic.
- Caching policies could be tuned to the observed read-to-write transition rather than treating all context uniformly.
- Future benchmarks should include explicit measurement of token reuse rates and tool-phase timing to remain representative.
Load-bearing premise
The five chosen benchmarks and the ReAct-style pattern on Gemma and Qwen models stand in for the wider range of agentic workloads that will appear in production.
What would settle it
A new agentic benchmark suite or different model family that shows low token reuse under caching or lacks the early-read to late-write tool shift would falsify the reported workload characteristics.
Figures
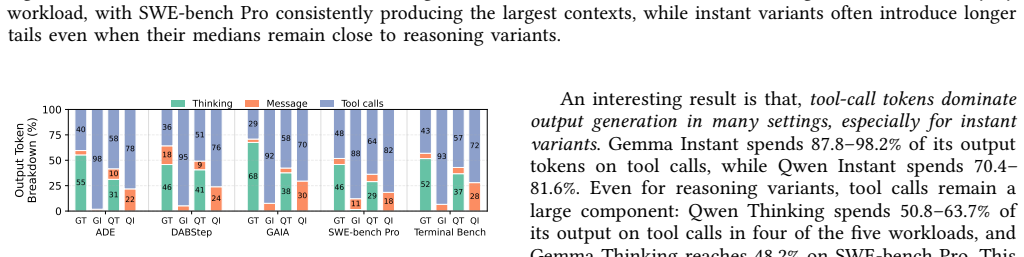
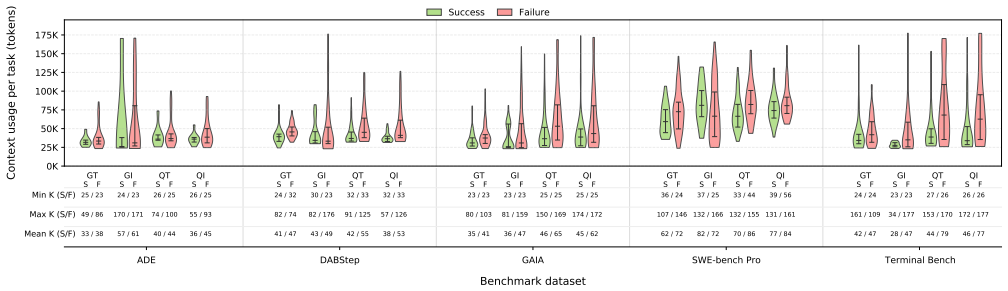
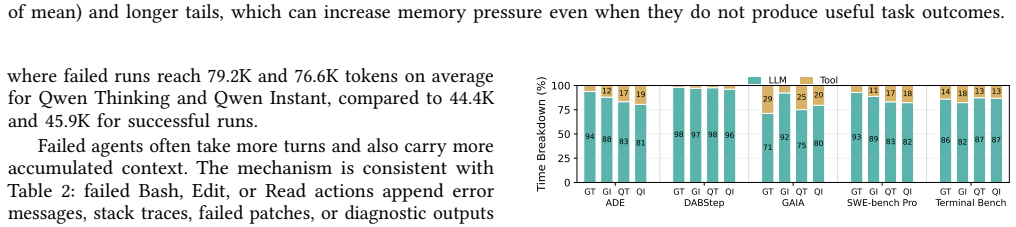
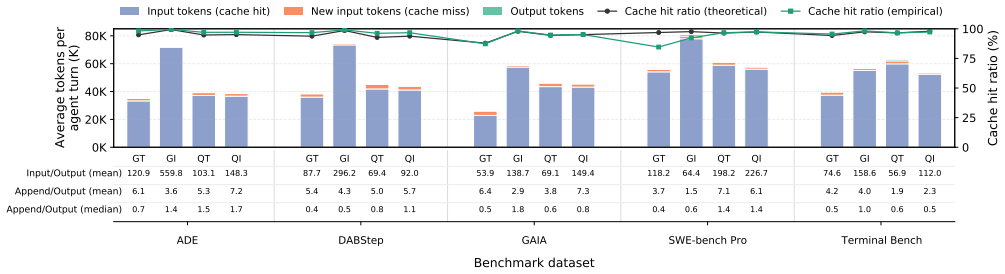

read the original abstract
Agentic AI shifts LLM serving from isolated prompt-generation requests to stateful, multi-turn executions that repeatedly invoke the model, call tools, and grow context over time. This paper characterizes ReAct-style agents from both the LLM-serving and tool-execution perspectives using an end-to-end tracing infrastructure across reasoning and non-reasoning Gemma and Qwen configurations on five agentic benchmarks. Our study shows that agentic workloads are not simply long-prompt workloads: with effective context caching, most input tokens are reused across turns, making execution decode-dominated while increasing dependence on long-lived KV-cache state. We also find that tool use has a clear temporal structure, with agents shifting from read/explore behavior early in execution to execute/write behavior later. These results show that efficient agentic serving must jointly manage repeated model re-entry, persistent context state, and workload-dependent tool behavior.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript characterizes ReAct-style agentic AI workloads via end-to-end tracing on five benchmarks using Gemma and Qwen models (reasoning and non-reasoning configurations). It claims that, with effective context caching, most input tokens are reused across turns (making execution decode-dominated and increasing dependence on long-lived KV-cache state) and that tool use exhibits a clear temporal structure, shifting from read/explore behavior early in execution to execute/write behavior later. These observations are used to argue that efficient agentic serving must jointly manage repeated model re-entry, persistent context state, and workload-dependent tool behavior.
Significance. If the traced patterns hold and prove representative, the work would provide actionable guidance for LLM serving systems targeting stateful multi-turn agents, particularly around KV-cache management and phase-aware scheduling. The end-to-end tracing infrastructure is a positive methodological contribution that supports reproducible measurement of these workload characteristics.
major comments (2)
- [Abstract] Abstract: the central claims that 'most input tokens are reused across turns, making execution decode-dominated' and that tool use has a 'clear temporal structure' are stated at a high level with no accompanying quantitative data (e.g., reuse ratios, token counts per phase, or statistical summaries) from the traces on the five benchmarks. This absence prevents evaluation of whether the measurements support the stated conclusions.
- [Abstract] Abstract (final sentence): the serving implications ('efficient agentic serving must jointly manage repeated model re-entry, persistent context state, and workload-dependent tool behavior') are drawn from ReAct-style traces on five specific benchmarks with Gemma/Qwen models. No analysis or discussion is supplied to establish that these execution graphs, control flows, or context-management strategies are representative of broader agentic workloads (e.g., parallel tool invocation or hierarchical planning), which could materially alter the reported token-reuse and phase-shift statistics.
minor comments (1)
- [Abstract] The abstract would be strengthened by briefly noting the number of traces, model scales, or key quantitative highlights to give readers an immediate sense of the data supporting the high-level findings.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight opportunities to strengthen the presentation of our quantitative results and the scope of our claims. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that 'most input tokens are reused across turns, making execution decode-dominated' and that tool use has a 'clear temporal structure' are stated at a high level with no accompanying quantitative data (e.g., reuse ratios, token counts per phase, or statistical summaries) from the traces on the five benchmarks. This absence prevents evaluation of whether the measurements support the stated conclusions.
Authors: We agree that the abstract would benefit from including key quantitative results to support the central claims. Although the body of the paper reports reuse ratios, per-phase token counts, and statistical summaries from the five benchmarks, we will revise the abstract to incorporate representative figures (e.g., average KV-cache reuse fractions and phase-transition statistics) so that the claims can be evaluated directly from the abstract. revision: yes
-
Referee: [Abstract] Abstract (final sentence): the serving implications ('efficient agentic serving must jointly manage repeated model re-entry, persistent context state, and workload-dependent tool behavior') are drawn from ReAct-style traces on five specific benchmarks with Gemma/Qwen models. No analysis or discussion is supplied to establish that these execution graphs, control flows, or context-management strategies are representative of broader agentic workloads (e.g., parallel tool invocation or hierarchical planning), which could materially alter the reported token-reuse and phase-shift statistics.
Authors: The manuscript is explicitly scoped to ReAct-style agents, as stated in the title, abstract, and methodology. We do not assert that the observed patterns generalize to all agentic paradigms. In the revision we will add an explicit limitations paragraph that delineates the ReAct focus, notes that alternative control flows (parallel invocation, hierarchical planning) could change reuse and phase statistics, and positions the serving implications as guidance for systems targeting ReAct-style workloads. revision: partial
Circularity Check
No circularity: purely observational workload measurements
full rationale
The paper reports direct measurements from end-to-end tracing of ReAct-style agents on five benchmarks using Gemma and Qwen models. No equations, fitted parameters, predictions, or derivation steps are present. Claims about token reuse after caching and temporal shifts in tool use are stated as empirical observations from the collected traces, with no reduction to self-defined quantities or self-citation chains. The representativeness assumption is external to any internal derivation and does not create circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Claude Code: Create custom subagents,
Anthropic, “Claude Code: Create custom subagents, ” https://code. claude.com/docs/en/sub-agents, 2026, accessed: 2026-05-21
2026
-
[2]
Claude Code: Overview,
——, “Claude Code: Overview, ” https://code.claude.com/docs/en/ overview, 2026, accessed: 2026-05-21
2026
-
[3]
Efficient and scalable agentic ai with heterogeneous systems,
Z. Asgar, M. Nguyen, and S. Katti, “Efficient and scalable agentic ai with heterogeneous systems, ”arXiv preprint arXiv:2507.19635, 2025
-
[4]
Unrolling the Codex agent loop,
M. Bolin, “Unrolling the Codex agent loop, ” https://openai.com/index/ unrolling-the-codex-agent-loop/, Jan. 2026, openAI. Accessed: 2026- 05-21
2026
-
[5]
arXiv preprint arXiv:2510.09665 , year=
Y. Cheng, Y. Liu, J. Yao, Y. An, X. Chen, S. Feng, Y. Huang, S. Shen, K. Du, and J. Jiang, “Lmcache: An efficient kv cache layer for enterprise-scale llm inference, ”arXiv preprint arXiv:2510.09665, 2025
-
[6]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
X. Deng, J. Da, E. Pan, Y. Y. He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, K. Sampath, M. Krishnan, S. Kundurthy, S. Hendryx, Z. Wang, V. Bharadwaj, J. Holm, R. Aluri, C. B. C. Zhang, N. Jacobson, B. Liu, and B. Kenstler, “SWE-Bench Pro: Can AI agents solve long-horizon software engineering tasks?”arXiv preprint arXiv:2509.16941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Dabstep: Data agent benchmark for multi-step reasoning,
A. Egg, M. Iglesias Goyanes, F. Kingma, A. Mora, L. von Werra, and T. Wolf, “Dabstep: Data agent benchmark for multi-step reasoning, ” arXiv preprint arXiv:2506.23719, 2025
-
[8]
AgentQuest: A modular benchmark framework to measure progress and improve LLM agents,
L. Gioacchini, G. Siracusano, D. Sanvito, K. Gashteovski, D. Friede, R. Bifulco, and C. Lawrence, “AgentQuest: A modular benchmark framework to measure progress and improve LLM agents, ” 2024. [Online]. Available: https://arxiv.org/abs/2404.06411
-
[9]
Gemma 4: Byte for byte, the most capa- ble open models,
Google DeepMind, “Gemma 4: Byte for byte, the most capa- ble open models, ” https://blog.google/innovation-and-ai/technology/ developers-tools/gemma-4/, Apr. 2026, accessed: 2026-05-21
2026
-
[10]
Harbor: A framework for evaluating and optimizing agents and models in container environments,
Harbor Framework Team, “Harbor: A framework for evaluating and optimizing agents and models in container environments, ” Jan. 2026. [Online]. Available: https://github.com/harbor-framework/harbor
2026
-
[11]
Jaeger Documentation,
Jaeger Authors, “Jaeger Documentation, ” https://www.jaegertracing. io/docs/latest/, 2026, accessed: 2026-05-21
2026
-
[12]
Highly accurate protein structure prediction with alphafold,
J. Jumper, R. Evans, A. Pritzel, T. Green, M. Figurnov, O. Ronneberger, K. Tunyasuvunakool, R. Bates, A. Žídek, A. Potapenkoet al., “Highly accurate protein structure prediction with alphafold, ”Nature, vol. 596, no. 7873, pp. 583–589, 2021
2021
-
[13]
Thunderagent: A simple, fast and program- aware agentic inference system,
H. Kang, Z. Li, X. Yang, W. Xu, Y. Chen, J. Wang, B. Chen, T. Krishna, C. Xu, and S. Arora, “Thunderagent: A simple, fast and program- aware agentic inference system, ”arXiv preprint arXiv:2602.13692, 2026
-
[14]
J. Kim, B. Shin, J. Chung, and M. Rhu, “The cost of dynamic reasoning: Demystifying AI agents and test-time scaling from an AI infrastructure perspective, ” 2025. [Online]. Available: https://arxiv.org/abs/2506.04301
-
[15]
Efficient memory management for large language model serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with PagedAttention, ” inProceedings of the 29th Symposium on Operating Systems Principles (SOSP ’23), 2023, pp. 611–626
2023
-
[16]
Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live
H. Li, Q. Mang, R. He, Q. Zhang, H. Mao, X. Chen, H. Zhou, A. Cheung, J. Gonzalez, and I. Stoica, “Continuum: Efficient and robust multi-turn LLM agent scheduling with KV cache time-to-live, ” arXiv preprint arXiv:2511.02230, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Parrot: Efficient serving of LLM-based applications with semantic variable,
C. Lin, Z. Han, C. Zhang, Y. Yang, F. Yang, C. Chen, and L. Qiu, “Parrot: Efficient serving of LLM-based applications with semantic variable, ” in18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), 2024, pp. 929–945. [Online]. Available: https://www.usenix.org/conference/osdi24/presentation/lin-chaofan
2024
-
[18]
AgentBench: Evaluating LLMs as agents,
X. Liu, H. Yu, H. Zhang, Y. Xu, X. Lei, H. Lai, Y. Gu, H. Ding, K. Men, K. Yang, S. Zhang, X. Deng, A. Zeng, Z. Du, C. Zhang, S. Shen, T. Zhang, Y. Su, H. Sun, M. Huang, Y. Dong, and J. Tang, “AgentBench: Evaluating LLMs as agents, ” inInternational Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=zAdUB0aCTQ
2024
-
[19]
AgentBoard: An analytical evaluation board of multi-turn LLM agents,
C. Ma, J. Zhang, Z. Zhu, C. Yang, Y. Yang, Y. Jin, Z. Lan, L. Kong, and J. He, “AgentBoard: An analytical evaluation board of multi-turn LLM agents, ” inAdvances in Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=4S8agvKjle
2024
-
[20]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
M. A. Merrill, A. G. Shaw, N. Carlini, B. Li, H. Raj, I. Bercovich, L. Shi, J. Y. Shin, T. Walshe, E. K. Buchanan, J. Shen, G. Ye, H. Lin, J. Poulos, M. Wang, M. Nezhurina, J. Jitsev, D. Lu, O. Menis Mastromichalakis, Z. Xu, Z. Chen, Y. Liu, R. Zhang, L. L. Chen, A. Kashyap, J.-L. Uslu, J. Li, J. Wu, M. Yan, S. Bian, V. Sharma, K. Sun, S. Dillmann, A. Ana...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[21]
GAIA: a benchmark for General AI Assistants
G. Mialon, C. Fourrier, C. Swift, T. Wolf, Y. LeCun, and T. Scialom, “GAIA: A benchmark for general AI assistants, ”arXiv preprint arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[22]
Introducing GPT-5.5,
OpenAI, “Introducing GPT-5.5, ” https://openai.com/index/ introducing-gpt-5-5/, Apr. 2026, accessed: 2026-05-21
2026
-
[23]
OpenClaw: Personal ai assistant,
OpenClaw, “OpenClaw: Personal ai assistant, ” https://openclaw.ai/, 2026, accessed: 2026-05-22
2026
-
[24]
OpenTelemetry Documentation,
OpenTelemetry Authors, “OpenTelemetry Documentation, ” https: //opentelemetry.io/docs/, 2026, accessed: 2026-05-21
2026
-
[25]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
S. Peng, E. Kalliamvakou, P. Cihon, and M. Demirer, “The impact of ai on developer productivity: Evidence from github copilot, ”arXiv preprint arXiv:2302.06590, 2023. [Online]. Available: https://arxiv.org/abs/2302.06590
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Qwen3.6-27B: Flagship-level coding in a 27b dense model,
Qwen Team, “Qwen3.6-27B: Flagship-level coding in a 27b dense model, ” https://qwen.ai/blog?id=qwen3.6-27b, Apr. 2026, accessed: 2026-05-21
2026
-
[27]
Towards Understanding, Analyzing, and Optimizing Agentic AI Execution: A CPU-Centric Perspective
R. Raj, S. Kundu, I. Vohra, H. Wang, and T. Krishna, “Towards understanding, analyzing, and optimizing agentic AI Execution: A CPU-centric perspective, ” 2025. [Online]. Available: https://arxiv.org/abs/2511.00739
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Alto: An efficient network orchestrator for compound AI systems,
K. Santhanam, D. Raghavan, M. S. Rahman, T. Venkatesh, N. Kunjal, P. Thaker, P. Levis, and M. Zaharia, “Alto: An efficient network orchestrator for compound AI systems, ” inProceedings of the 4th Workshop on Machine Learning and Systems (EuroMLSys ’24), 2024, pp. 117–125
2024
-
[29]
Toolformer: Language models can teach themselves to use tools,
T. Schick, J. Dwivedi-Yu, R. Dessi, R. Raileanu, M. Lomeli, E. Hambro, L. Zettlemoyer, N. Cancedda, and T. Scialom, “Toolformer: Language models can teach themselves to use tools, ” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023. [Online]. Available: https://openreview.net/forum?id=Yacmpz84TH
2023
-
[30]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, B. Labash, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning, ” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 36, 2023. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2023/hash/ 1b44b878bb782e6954cd888628510e90-Abstract-Conference.html 12
2023
-
[31]
ADE-bench: Analytics and data engineering benchmark,
B. Stancil and dbt Labs, “ADE-bench: Analytics and data engineering benchmark, ” https://github.com/dbt-labs/ade-bench, 2026, accessed: 2026-05-21
2026
-
[32]
Automatic Prefix Caching,
vLLM Team, “Automatic Prefix Caching, ” https://docs.vllm.ai/en/ latest/features/automatic_prefix_caching/, 2026, vLLM documentation. Accessed: 2026-05-21
2026
-
[33]
Efficient llm serving for agentic work- flows: A data systems perspective,
N. Wadlom, J. Shen, and Y. Lu, “Efficient llm serving for agentic work- flows: A data systems perspective, ”arXiv preprint arXiv:2603.16104, 2026
-
[34]
AgentRace: Benchmarking efficiency in LLM agent frameworks,
Y. Xu, B. Zeng, Z. Qiu, Z. Zhang, G. Yue, X. Liao, H. Jin, and Q. Li, “AgentRace: Benchmarking efficiency in LLM agent frameworks, ” 2026, submitted to ICLR 2026. [Online]. Available: https://openreview.net/forum?id=eUuxWAQA5F
2026
-
[35]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. R. Narasimhan, and O. Press, “SWE-agent: Agent-computer interfaces enable automated software engineering, ” inThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Webshop: Towards scalable real-world web interaction with grounded language agents,
S. Yao, H. Chen, J. Yang, and K. Narasimhan, “Webshop: Towards scalable real-world web interaction with grounded language agents, ” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 35, 2022. [Online]. Available: https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 82ad13ec01f9fe44c01cb91814fd7b8c-Abstract-Conference.html
2022
-
[37]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y. Cao, “React: Synergizing reasoning and acting in language models, ” inThe Eleventh International Conference on Learning Representations (ICLR), 2023
2023
-
[38]
KAIROS: Stateful, Context-Aware Power-Efficient Agentic Inference Serving
Y. Yuan, M. Chowdhury, and N. Talati, “Kairos: Stateful, context- aware power-efficient agentic inference serving, ” 2026. [Online]. Available: https://arxiv.org/abs/2604.16682
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[39]
arXiv preprint arXiv:2602.09345
Y. Zheng, J. Fan, Q. Fu, Y. Yang, W. Zhang, and A. Quinn, “AgentCgroup: Understanding and controlling OS resources of AI agents, ” 2026. [Online]. Available: https://arxiv.org/abs/2602.09345
-
[40]
Language agent tree search unifies reasoning, acting, and planning in language models,
A. Zhou, K. Yan, M. Shlapentokh-Rothman, H. Wang, and Y.-X. Wang, “Language agent tree search unifies reasoning, acting, and planning in language models, ” inProceedings of the 41st International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 235. PMLR, 2024, pp. 62 138–62 160. [Online]. Available: https://proceedings....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.