Totoro^+: An Adaptive and Scalable Edge Federated Learning System
Pith reviewed 2026-06-29 20:06 UTC · model grok-4.3
The pith
Totoro+ decentralizes federated learning by giving each application its own dedicated parameter server on edge nodes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Totoro+ re-architects centralized FL into a fully decentralized P2P system using DHT where each FL application has its own dedicated parameter server, and any edge node can serve as coordinator, aggregator, client selector, or worker for any combination of applications, enabled by a locality-aware P2P multi-ring structure, a publish/subscribe-based forest abstraction, and a game-theoretic path planning model with epsilon-approximate Nash equilibrium guarantee.
What carries the argument
DHT-based peer-to-peer model with locality-aware multi-ring structure, publish/subscribe forest abstraction, and game-theoretic path planning for epsilon-approximate Nash equilibrium.
If this is right
- The system scales gracefully with the number of FL applications and N edge nodes.
- It speeds up the total training time by 1.2×-14.0×.
- It achieves O(log N) hops for model dissemination and gradient aggregation with millions of nodes.
- It efficiently adapts to practical edge networks and churns.
Where Pith is reading between the lines
- The multi-role node design could reduce reliance on specialized infrastructure in dynamic edge settings.
- The approach might extend to optimize additional metrics such as energy use during path planning.
- Logarithmic scaling could support federated learning deployments in large-scale IoT networks with frequent node turnover.
Load-bearing premise
The game-theoretic path planning model delivers a guaranteed epsilon-approximate Nash equilibrium under realistic edge churn without new failure modes from multi-role nodes.
What would settle it
An experiment with high node churn rates where the path planning fails to maintain the approximate Nash equilibrium or causes training delays and failures.
Figures





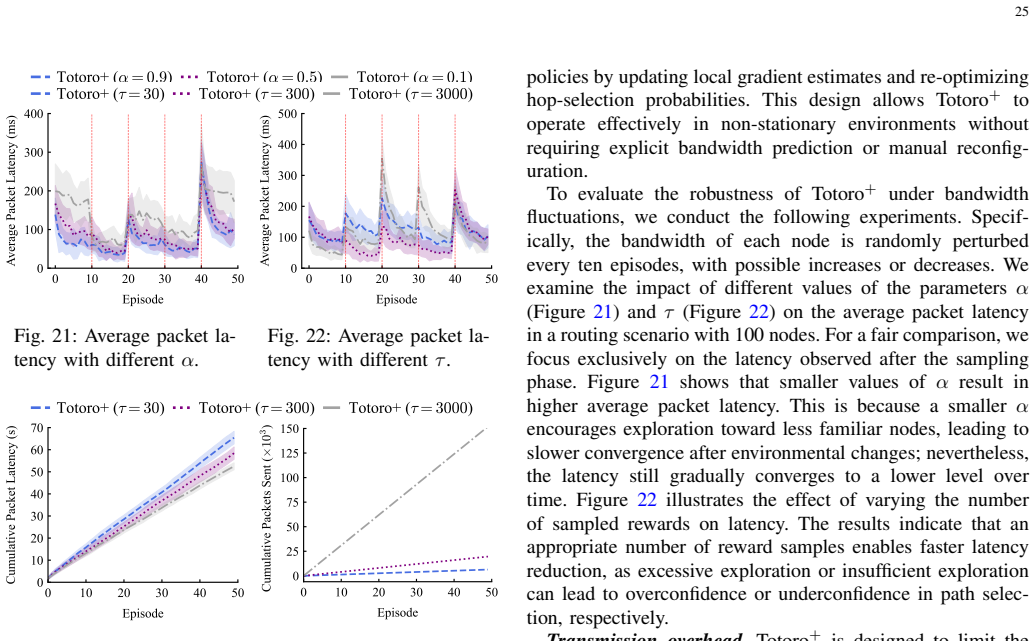
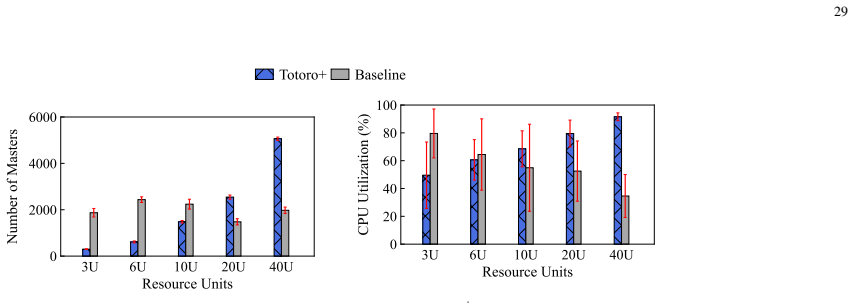
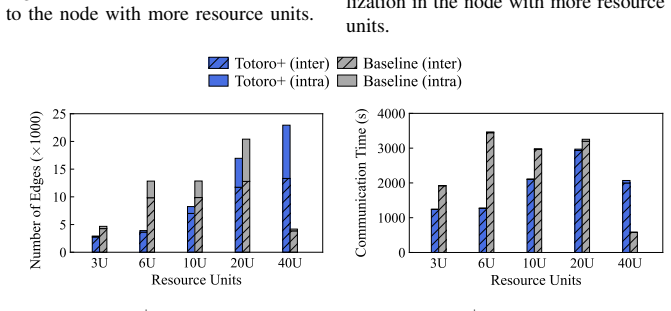
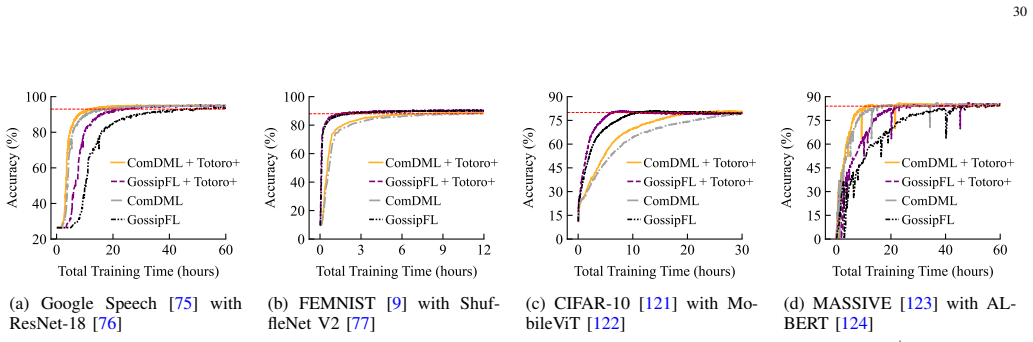
read the original abstract
Federated Learning (FL) is an emerging distributed machine learning (ML) technique that enables in-situ model training and inference on decentralized edge devices. We propose Totoro$^+$, a novel scalable FL system that enables massive FL applications to run simultaneously on edge networks. The key insight is to explore a distributed hash table (DHT)-based peer-to-peer (P2P) model to re-architect the centralized FL system design into a fully decentralized one. In contrast to previous studies where many FL applications shared one centralized parameter server, Totoro$^+$ assigns a dedicated parameter server to each application. Any edge node can act as any application's coordinator, aggregator, client selector, worker (participant device), or any combination of the above, thereby radically improving scalability and adaptivity. Totoro$^+$ introduces three innovations to realize its design: a locality-aware P2P multi-ring structure, a publish/subscribe-based forest abstraction, and a game-theoretic path planning model with a guarantee of an $\epsilon$-approximate Nash equilibrium. Real-world experiments on 500 Amazon EC2 servers show that Totoro$^+$ scales gracefully with the number of FL applications and $N$ edge nodes speeds up the total training time by $1.2\times-14.0\times$, achieves $\mathcal{O}(\log N)$ hops for model dissemination and gradient aggregation with millions of nodes, and efficiently adapts to the practical edge networks and churns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Totoro+, a fully decentralized edge federated learning system that replaces centralized parameter servers with a DHT-based P2P architecture. Each FL application receives a dedicated parameter server, and any edge node can dynamically assume roles including coordinator, aggregator, client selector, or worker. The design rests on three innovations: a locality-aware P2P multi-ring overlay, a publish/subscribe forest abstraction, and a game-theoretic path planning model asserted to deliver an ε-approximate Nash equilibrium. Experiments on 500 Amazon EC2 servers report 1.2×–14.0× speedups in total training time, O(log N) hops for dissemination and aggregation (extrapolated to millions of nodes), and adaptation to churn.
Significance. If the O(log N) bound, speedups, and ε-Nash guarantee are rigorously established, the work would meaningfully advance scalable concurrent FL on edge networks by removing single-point bottlenecks and providing a formal handle on dynamic role assignment.
major comments (3)
- [Abstract] Abstract: the O(log N) hop bound and million-node scalability claim rest on 500-node EC2 runs; no analytic derivation, larger-scale simulation, or measurement of per-node state growth is supplied to justify the extrapolation.
- [Abstract] Abstract (game-theoretic path planning model): the ε-approximate Nash equilibrium is asserted to hold while nodes dynamically act as coordinators/aggregators under churn, yet the 500-node experiments cannot exercise equilibrium computation cost or re-convergence after churn events at the claimed million-node regime; if equilibrium maintenance incurs super-logarithmic overhead, both the hop bound and reported speedups become unsupported.
- [Abstract] Abstract: the claim that any node can reliably serve multiple roles without introducing new failure modes or security issues is central to the adaptivity argument, but no analysis of coordinator/aggregator load imbalance or churn-induced re-election latency is provided.
minor comments (1)
- The abstract refers to 'practical edge networks and churns' without defining quantitative metrics (e.g., churn rate, latency distribution) or baselines used to evaluate adaptation efficiency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, clarifying the foundations of our claims while committing to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the O(log N) hop bound and million-node scalability claim rest on 500-node EC2 runs; no analytic derivation, larger-scale simulation, or measurement of per-node state growth is supplied to justify the extrapolation.
Authors: The O(log N) bound is inherited from the standard DHT properties of the multi-ring overlay (analogous to Chord), which have been analytically proven in prior literature; our locality-aware extension preserves the bound while adding edge-specific optimizations. The 500-node experiments confirm the bound in practice and show graceful scaling. To directly address the extrapolation, we will add (i) a concise analytic derivation of hop count and state growth, (ii) per-node state measurements, and (iii) results from larger-scale simulations (up to 10k nodes) in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract (game-theoretic path planning model): the ε-approximate Nash equilibrium is asserted to hold while nodes dynamically act as coordinators/aggregators under churn, yet the 500-node experiments cannot exercise equilibrium computation cost or re-convergence after churn events at the claimed million-node regime; if equilibrium maintenance incurs super-logarithmic overhead, both the hop bound and reported speedups become unsupported.
Authors: The game-theoretic path planner computes an ε-approximate Nash equilibrium locally within small node groups using a distributed algorithm whose per-decision cost is bounded by O(log N). Experiments already demonstrate stable churn adaptation on 500 nodes. We agree that explicit complexity analysis and larger-scale re-convergence data would strengthen the claims; we will add both a formal complexity argument and additional simulation results showing equilibrium maintenance overhead remains logarithmic under churn. revision: yes
-
Referee: [Abstract] Abstract: the claim that any node can reliably serve multiple roles without introducing new failure modes or security issues is central to the adaptivity argument, but no analysis of coordinator/aggregator load imbalance or churn-induced re-election latency is provided.
Authors: Role flexibility is enabled by the DHT and pub/sub forest, which distribute responsibilities and inherit load-balancing properties from the overlay. Our experiments already measure adaptation under churn. We will add an explicit analysis section that reports observed load-imbalance metrics, re-election latencies, and a discussion of potential failure modes. A brief treatment of inherited DHT security properties and mitigation strategies will also be included. revision: yes
Circularity Check
No circularity: claims rest on independent architectural design and external benchmarks
full rationale
The paper presents three explicit innovations (locality-aware P2P multi-ring, pub/sub forest, game-theoretic path planning) whose performance claims are evaluated via 500-node EC2 experiments and standard DHT properties for O(log N) hops. No equations, fitted parameters, or self-referential definitions appear in the abstract or described structure; the ε-Nash guarantee is asserted as a model property rather than derived from the reported speedups or hop counts. The derivation chain is therefore self-contained against external benchmarks and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Edge nodes can reliably perform multiple FL roles (coordinator, aggregator, worker) under churn
Reference graph
Works this paper leans on
-
[1]
Totoro: A scalable federated learning engine for the edge,
C.-W. Ching, X. Chen, T. Kim, B. Ji, Q. Wang, D. Da Silva, and L. Hu, “Totoro: A scalable federated learning engine for the edge,” inProceedings of the Nineteenth European Conference on Computer Systems, 2024, p. 182–199. [Online]. Available: https://doi.org/10.1145/3627703.3629575
-
[2]
Asynchronous online federated learning for edge devices with non-iid data,
Y . Chen, Y . Ning, M. Slawski, and H. Rangwala, “Asynchronous online federated learning for edge devices with non-iid data,” inIEEE International Conference on Big Data, 2020, pp. 15–24
2020
-
[3]
Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation,
Y . Chen, X. Sun, and Y . Jin, “Communication-efficient federated deep learning with layerwise asynchronous model update and temporally weighted aggregation,”IEEE Transactions on Neural Networks and Learning Systems, vol. 31, no. 10, pp. 4229–4238, 2020
2020
-
[4]
Federated multi-task learning,
V . Smith, C.-K. Chiang, M. Sanjabi, and A. S. Talwalkar, “Federated multi-task learning,”Advances in neural information processing sys- tems, vol. 30, 2017
2017
-
[5]
Federated learning for mobile keyboard prediction,
A. Hardet al., “Federated learning for mobile keyboard prediction,” arXiv preprint arXiv:1811.03604, 2018
Pith/arXiv arXiv 2018
-
[6]
Applied federated learning: Improving google keyboard query suggestions,
T. Yanget al., “Applied federated learning: Improving google keyboard query suggestions,”arXiv preprint arXiv:1812.02903, 2018
Pith/arXiv arXiv 2018
-
[7]
IBM federated learning: an enterprise framework white paper v0. 1,
H. Ludwiget al., “IBM federated learning: an enterprise framework white paper v0. 1,”arXiv preprint arXiv:2007.10987, 2020
arXiv 2007
-
[8]
https: //www.tensorflow.org/federated
Tensorflow federated: Machine learning on decentralized data. https: //www.tensorflow.org/federated
-
[9]
Leaf: A benchmark for federated settings,
S. Caldaset al., “Leaf: A benchmark for federated settings,”arXiv preprint arXiv:1812.01097, 2018
arXiv 2018
-
[10]
FLOAT: Federated learning optimizations with auto- mated tuning,
A. F. Khan, A. A. Khan, A. M. Abdelmoniem, S. Fountain, A. R. Butt, and A. Anwar, “FLOAT: Federated learning optimizations with auto- mated tuning,” inProceedings of the Nineteenth European Conference on Computer Systems, 2024, pp. 200–218
2024
-
[11]
REFL: Resource-efficient federated learning,
A. M. Abdelmoniem, A. N. Sahu, M. Canini, and S. A. Fahmy, “REFL: Resource-efficient federated learning,” inProceedings of the Eighteenth European Conference on Computer Systems, 2023, pp. 215–232
2023
-
[12]
https://github.com/ OpenMined/PySyft
PySyft: A library for easy federated learning. https://github.com/ OpenMined/PySyft
-
[13]
United states department of transportation annual modal research plans,
“United states department of transportation annual modal research plans,” https://www.transportation.gov/sites/dot.gov/files/2024-08/ AMRP%20FY2024%20-%202025%20ITSJPO.pdf
2024
-
[14]
Long short-term memory,
S. Hochreiter and J. Schmidhuber, “Long short-term memory,”Neural Computation, vol. 9, no. 8, pp. 1735–1780, 1997
1997
-
[15]
Driver monitoring-based lane-change prediction: A personalized federated learning framework,
R. Du, K. Han, R. Gupta, S. Chen, S. Labi, and Z. Wang, “Driver monitoring-based lane-change prediction: A personalized federated learning framework,” inIEEE Intelligent Vehicles Symposium, 2023, pp. 1–7
2023
-
[16]
Fedstream: A federated learn- ing framework on heterogeneous streaming data for next-generation traffic analysis,
N. Wang, X. Li, Z. Guan, and S. Yuan, “Fedstream: A federated learn- ing framework on heterogeneous streaming data for next-generation traffic analysis,”IEEE Transactions on Network Science and Engineer- ing, vol. 11, no. 3, pp. 2485–2496, 2023
2023
-
[17]
Ai- empowered trajectory anomaly detection for intelligent transportation systems: A hierarchical federated learning approach,
X. Wang, W. Liu, H. Lin, J. Hu, K. Kaur, and M. S. Hossain, “Ai- empowered trajectory anomaly detection for intelligent transportation systems: A hierarchical federated learning approach,”IEEE Transac- tions on Intelligent Transportation Systems, vol. 24, no. 4, pp. 4631– 4640, 2022
2022
-
[18]
http://www.bittorrent.com/
Bittorrent. http://www.bittorrent.com/
-
[19]
http://storj.io/
Storj.io. http://storj.io/
-
[20]
https://freenetproject.org/
Freenet: The free network. https://freenetproject.org/
-
[21]
Peer-assisted content distribution in akamai netses- sion,
M. Zhaoet al., “Peer-assisted content distribution in akamai netses- sion,” inProceedings of the 2013 conference on Internet measurement conference, 2013, pp. 31–42
2013
-
[22]
On scaling decentralized blockchains: (a position paper),
K. Cromanet al., “On scaling decentralized blockchains: (a position paper),” inInternational conference on financial cryptography and data security. Springer, 2016, pp. 106–125
2016
-
[23]
https://www.freepastry.org/FreePastry/
Pastry. https://www.freepastry.org/FreePastry/
-
[24]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury, G. Chanan, T. Killeen, Z. Lin, N. Gimelshein, L. Antiga, A. Desmaison, A. Kopf, E. Yang, Z. DeVito, M. Raison, A. Tejani, S. Chilamkurthy, B. Steiner, L. Fang, J. Bai, and S. Chintala, “PyTorch: An imperative style, high-performance deep learning library,” inAdvances in Neural Information Processing Sy...
-
[25]
Available: https://proceedings.neurips.cc/paper files/ paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf
[Online]. Available: https://proceedings.neurips.cc/paper files/ paper/2019/file/bdbca288fee7f92f2bfa9f7012727740-Paper.pdf
2019
-
[26]
https:// openfl.readthedocs.io/
OpenFL - an open-source framework for federated learning. https:// openfl.readthedocs.io/
-
[27]
FedScale: Benchmarking model and system performance of federated learning at scale,
F. Lai, Y . Dai, S. Singapuram, J. Liu, X. Zhu, H. Madhyastha, and M. Chowdhury, “FedScale: Benchmarking model and system performance of federated learning at scale,” inProceedings of the 39th International Conference on Machine Learning, vol. 162. PMLR, 17–23 Jul 2022, pp. 11 814–11 827. [Online]. Available: https://proceedings.mlr.press/v162/lai22a.html
2022
-
[28]
A crowdsourcing framework for on-device federated learning,
S. R. Pandey, N. H. Tran, M. Bennis, Y . K. Tun, A. Manzoor, and C. S. Hong, “A crowdsourcing framework for on-device federated learning,” IEEE Transactions on Wireless Communications, vol. 19, no. 5, pp. 3241–3256, 2020
2020
-
[29]
CoPiFL: A collusion-resistant and privacy-preserving federated learning crowdsourcing scheme using blockchain and homo- morphic encryption,
R. Xionget al., “CoPiFL: A collusion-resistant and privacy-preserving federated learning crowdsourcing scheme using blockchain and homo- morphic encryption,”Future Generation Computer Systems, vol. 156, pp. 95–104, 2024
2024
-
[30]
PAPAY A: Practical, private, and scalable federated learning,
D. Hubaet al., “PAPAY A: Practical, private, and scalable federated learning,”Proceedings of Machine Learning and Systems, vol. 4, pp. 814–832, 2022
2022
-
[31]
FLINT: A platform for federated learning integration,
E. Wang, B. Chen, M. Chowdhury, A. Kannan, and F. Liang, “FLINT: A platform for federated learning integration,”Proceedings of Machine Learning and Systems, vol. 5, pp. 21–34, 2023
2023
-
[32]
Towards federated learning at scale: System design,
K. Bonawitzet al., “Towards federated learning at scale: System design,” inProceedings of Machine Learning and Systems, vol. 1, 2019, pp. 374–388
2019
-
[33]
Federated evaluation and tuning for on-device personalization: System design & applications,
M. Pauliket al., “Federated evaluation and tuning for on-device personalization: System design & applications,”arXiv preprint arXiv:2102.08503, 2021
arXiv 2021
-
[34]
Testing the resilience of mec-based iot applications against resource exhaustion attacks,
R. Pietrantuono, M. Ficco, and F. Palmieri, “Testing the resilience of mec-based iot applications against resource exhaustion attacks,”IEEE Transactions on Dependable and Secure Computing, vol. 21, no. 2, pp. 804–818, 2024
2024
-
[35]
TiFL: A tier-based federated learning system,
Z. Chaiet al., “TiFL: A tier-based federated learning system,” in Proceedings of the 29th international symposium on high-performance parallel and distributed computing, 2020, pp. 125–136
2020
-
[36]
Oort: Efficient federated learning via guided participant selection,
F. Lai, X. Zhu, H. V . Madhyastha, and M. Chowdhury, “Oort: Efficient federated learning via guided participant selection,” in15th USENIX Symposium on Operating Systems Design and Implementation, 2021, pp. 19–35
2021
-
[37]
Client selection for federated learning with heterogeneous resources in mobile edge,
T. Nishio and R. Yonetani, “Client selection for federated learning with heterogeneous resources in mobile edge,” inIEEE International Conference on Communications, 2019, pp. 1–7
2019
-
[38]
QSGD: Communication-efficient sgd via gradient quantization and encoding,
D. Alistarh, D. Grubic, J. Li, R. Tomioka, and M. V ojnovic, “QSGD: Communication-efficient sgd via gradient quantization and encoding,” Advances in neural information processing systems, vol. 30, 2017. 17
2017
-
[39]
signSGD with majority vote is communication efficient and fault tolerant,
J. Bernstein, J. Zhao, K. Azizzadenesheli, and A. Anandkumar, “signSGD with majority vote is communication efficient and fault tolerant,” inInternational Conference on Learning Representations, 2019
2019
-
[40]
Communication-efficient learning of deep networks from decentral- ized data,
B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y Arcas, “Communication-efficient learning of deep networks from decentral- ized data,” inArtificial intelligence and statistics. PMLR, 2017, pp. 1273–1282
2017
-
[41]
Semi-synchronous federated learning for energy-efficient training and accelerated conver- gence in cross-silo settings,
D. Stripelis, P. M. Thompson, and J. L. Ambite, “Semi-synchronous federated learning for energy-efficient training and accelerated conver- gence in cross-silo settings,”ACM Transactions on Intelligent Systems and Technology, vol. 13, no. 5, pp. 1–29, 2022
2022
-
[42]
Asynchronous federated optimiza- tion,
C. Xie, S. Koyejo, and I. Gupta, “Asynchronous federated optimiza- tion,” inAdvances in Neural Information Processing Systems Workshop on Optimization for Machine Learning, 2020
2020
-
[43]
Adaptive federated learning in resource constrained edge computing systems,
S. Wanget al., “Adaptive federated learning in resource constrained edge computing systems,”IEEE Journal on Selected Areas in Commu- nications, vol. 37, no. 6, pp. 1205–1221, 2019
2019
-
[44]
Federated learning for edge networks: Resource optimization and incentive mechanism,
L. U. Khanet al., “Federated learning for edge networks: Resource optimization and incentive mechanism,”IEEE Communications Mag- azine, vol. 58, no. 10, pp. 88–93, 2020
2020
-
[45]
Serverless edge computing: vision and challenges,
M. S. Aslanpouret al., “Serverless edge computing: vision and challenges,” inProceedings of the 2021 Australasian computer science week multiconference, 2021, pp. 1–10
2021
-
[46]
Edge-assisted democratized learning toward federated analytics,
S. R. Pandeyet al., “Edge-assisted democratized learning toward federated analytics,”IEEE Internet of Things Journal, vol. 9, no. 1, pp. 572–588, 2022
2022
-
[47]
AgileDART: An agile and scalable edge stream processing engine,
C.-W. Ching, X. Chen, C. Kim, T. Wang, D. Chen, D. Da Silva, and L. Hu, “AgileDART: An agile and scalable edge stream processing engine,”IEEE Transactions on Mobile Computing, vol. 24, no. 5, pp. 4510–4528, 2025
2025
-
[48]
Kalmia: A heterogeneous qos-aware scheduling framework for dnn tasks on edge servers,
Z. Fu, J. Ren, D. Zhang, Y . Zhou, and Y . Zhang, “Kalmia: A heterogeneous qos-aware scheduling framework for dnn tasks on edge servers,” inConference on Computer Communications, 2022, pp. 780– 789
2022
-
[49]
Learning in congestion games with bandit feedback,
Q. Cui, Z. Xiong, M. Fazel, and S. S. Du, “Learning in congestion games with bandit feedback,”Advances in Neural Information Pro- cessing Systems, vol. 35, pp. 11 009–11 022, 2022
2022
-
[50]
Pastry: Scalable, decentralized object lo- cation, and routing for large-scale peer-to-peer systems,
A. Rowstron and P. Druschel, “Pastry: Scalable, decentralized object lo- cation, and routing for large-scale peer-to-peer systems,” inIFIP/ACM International Conference on Distributed Systems Platforms. Springer, 2001, pp. 329–350
2001
-
[51]
Chord: A scalable peer-to-peer lookup service for internet applica- tions,
I. Stoica, R. Morris, D. Karger, M. F. Kaashoek, and H. Balakrishnan, “Chord: A scalable peer-to-peer lookup service for internet applica- tions,”ACM SIGCOMM computer communication review, vol. 31, no. 4, pp. 149–160, 2001
2001
-
[52]
Tapestry: a resilient global-scale overlay for service deployment,
B. Zhao, L. Huang, J. Stribling, S. Rhea, A. Joseph, and J. Kubiatowicz, “Tapestry: a resilient global-scale overlay for service deployment,” IEEE Journal on Selected Areas in Communications, vol. 22, no. 1, pp. 41–53, 2004
2004
-
[53]
Fedhealth: A federated transfer learning framework for wearable healthcare,
Y . Chen, X. Qin, J. Wang, C. Yu, and W. Gao, “Fedhealth: A federated transfer learning framework for wearable healthcare,”IEEE Intelligent Systems, vol. 35, no. 4, pp. 83–93, 2020
2020
-
[54]
Fedsens: A federated learning approach for smart health sensing with class imbalance in resource constrained edge computing,
D. Y . Zhang, Z. Kou, and D. Wang, “Fedsens: A federated learning approach for smart health sensing with class imbalance in resource constrained edge computing,” inIEEE Conference on Computer Com- munications, 2021, pp. 1–10
2021
-
[55]
Kademlia: A peer-to-peer informa- tion system based on the xor metric,
P. Maymounkov and D. Mazieres, “Kademlia: A peer-to-peer informa- tion system based on the xor metric,” inInternational workshop on peer-to-peer systems. Springer, 2002, pp. 53–65
2002
-
[56]
Topologically-aware overlay construction and server selection,
S. Ratnasamy, M. Handley, R. Karp, and S. Shenker, “Topologically-aware overlay construction and server selection,” inProceedings.Twenty-First Annual Joint Conference of the IEEE Computer and Communications Societies, vol. 3, 2002, pp. 1190–1199 vol.3
2002
-
[57]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,”Proceedings of Machine learning and systems, vol. 2, pp. 429–450, 2020
2020
-
[58]
Differentially private federated learning: A client level perspective,
R. C. Geyer, T. Klein, and M. Nabi, “Differentially private federated learning: A client level perspective,” inAdvances in Neural Information Processing Systems Workshop: Machine Learning on the Phone and other Consumer Devices, 2017
2017
-
[59]
BatchCrypt: Efficient homomorphic encryption for Cross-Silo federated learning,
C. Zhang, S. Li, J. Xia, W. Wang, F. Yan, and Y . Liu, “BatchCrypt: Efficient homomorphic encryption for Cross-Silo federated learning,” inUSENIX annual technical conference, 2020, pp. 493–506
2020
-
[60]
Joint con- figuration adaptation and bandwidth allocation for edge-based real-time video analytics,
C. Wang, S. Zhang, Y . Chen, Z. Qian, J. Wu, and M. Xiao, “Joint con- figuration adaptation and bandwidth allocation for edge-based real-time video analytics,” inIEEE Conference on Computer Communications, 2020, pp. 257–266
2020
-
[61]
Stochastic online shortest path routing: The value of feedback,
M. S. Talebi, Z. Zou, R. Combes, A. Proutiere, and M. Johansson, “Stochastic online shortest path routing: The value of feedback,”IEEE Transactions on Automatic Control, vol. 63, no. 4, pp. 915–930, 2018
2018
-
[62]
Regret analysis of stochastic and nonstochastic multi-armed bandit problems,
S. Bubecket al., “Regret analysis of stochastic and nonstochastic multi-armed bandit problems,”Foundations and Trends® in Machine Learning, vol. 5, no. 1, pp. 1–122, 2012
2012
-
[63]
Algorithmic game theory,
T. Roughgarden, “Algorithmic game theory,”Communications of the ACM, vol. 53, no. 7, pp. 78–86, 2010
2010
-
[64]
Independent policy gradient for large-scale Markov potential games: Sharper rates, func- tion approximation, and game-agnostic convergence,
D. Ding, C.-Y . Wei, K. Zhang, and M. Jovanovic, “Independent policy gradient for large-scale Markov potential games: Sharper rates, func- tion approximation, and game-agnostic convergence,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 5166–5220
2022
-
[65]
Learning to compete, compromise, and cooperate in repeated general-sum games,
J. W. Crandall and M. A. Goodrich, “Learning to compete, compromise, and cooperate in repeated general-sum games,” in Proceedings of the 22nd International Conference on Machine Learning, 2005, p. 161–168. [Online]. Available: https://doi.org/10. 1145/1102351.1102372
arXiv 2005
-
[66]
Policy gradient methods find the nash equilibrium in n-player general-sum linear-quadratic games,
B. Hambly, R. Xu, and H. Yang, “Policy gradient methods find the nash equilibrium in n-player general-sum linear-quadratic games,” Journal of Machine Learning Research, vol. 24, no. 139, pp. 1–56,
-
[67]
Available: http://jmlr.org/papers/v24/21-0842.html
[Online]. Available: http://jmlr.org/papers/v24/21-0842.html
-
[68]
Lattimore and C
T. Lattimore and C. Szepesv ´ari,Bandit algorithms. Cambridge University Press, 2020
2020
-
[69]
Online influence maxi- mization under independent cascade model with semi-bandit feedback,
Z. Wen, B. Kveton, M. Valko, and S. Vaswani, “Online influence maxi- mization under independent cascade model with semi-bandit feedback,” Advances in neural information processing systems, vol. 30, 2017
2017
-
[70]
An algorithm for quadratic programming,
M. Franket al., “An algorithm for quadratic programming,”Naval research logistics quarterly, vol. 3, no. 1-2, pp. 95–110, 1956
1956
-
[71]
https://pytorch.org/
PyTorch. https://pytorch.org/
-
[72]
Scribe: a large-scale and decentralized application-level multicast infrastructure,
M. Castro, P. Druschel, A.-M. Kermarrec, and A. Rowstron, “Scribe: a large-scale and decentralized application-level multicast infrastructure,” IEEE Journal on Selected Areas in Communications, vol. 20, no. 8, pp. 1489–1499, 2002
2002
-
[73]
https://docs.pytorch.org/vision/stable/index.html
torchvision. https://docs.pytorch.org/vision/stable/index.html
-
[74]
https://huggingface.co/docs/transformers/ en/index
Hugging Face Transformers. https://huggingface.co/docs/transformers/ en/index
-
[75]
Optimal edge user allocation in edge computing with variable sized vector bin packing,
P. Laiet al., “Optimal edge user allocation in edge computing with variable sized vector bin packing,” in16th International Conference on Service-Oriented Computing. Springer, 2018, pp. 230–245
2018
-
[76]
Symbiotic lab,
“Symbiotic lab,” https://symbioticlab.org/
-
[77]
Speech commands: A dataset for limited-vocabulary speech recognition,
P. Warden, “Speech commands: A dataset for limited-vocabulary speech recognition,”arXiv preprint arXiv:1804.03209, 2018
Pith/arXiv arXiv 2018
-
[78]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, June 2016
2016
-
[79]
ShuffleNet V2: Practical guidelines for efficient cnn architecture design,
N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “ShuffleNet V2: Practical guidelines for efficient cnn architecture design,” inProceedings of the European Conference on Computer Vision, September 2018
2018
-
[80]
AWStream: Adaptive wide-area streaming analytics,
B. Zhang, X. Jin, S. Ratnasamy, J. Wawrzynek, and E. A. Lee, “AWStream: Adaptive wide-area streaming analytics,” inProceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, 2018, pp. 236–252
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.