Cassandra: Enabling Reasoning LLMs at Edge via Self-Speculative Decoding
Pith reviewed 2026-07-01 16:16 UTC · model grok-4.3
The pith
Cassandra builds a training-free draft model via pruning and truncation to accelerate LLM decoding up to 2.41 times on edge hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
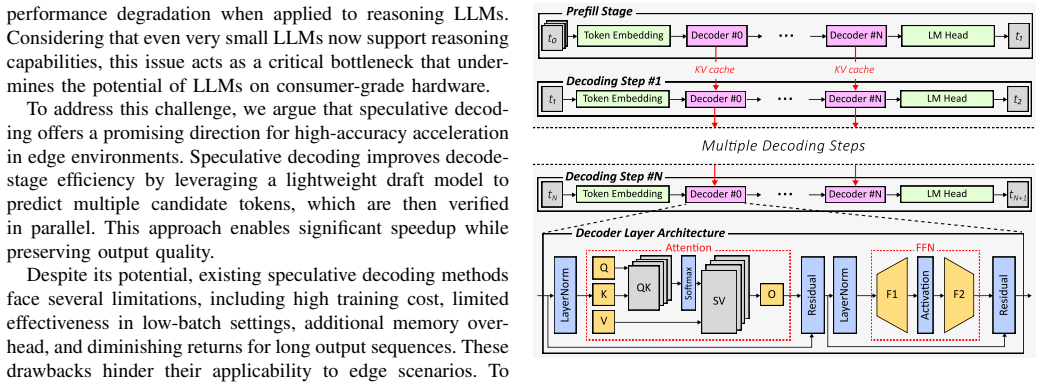
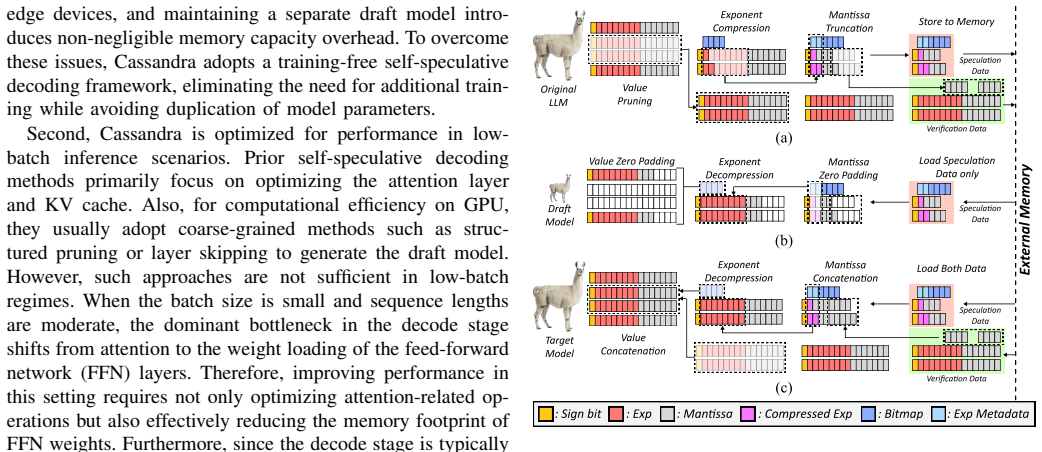
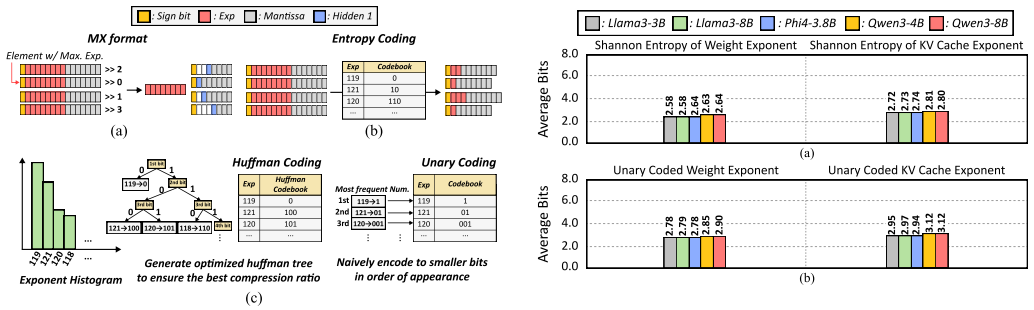
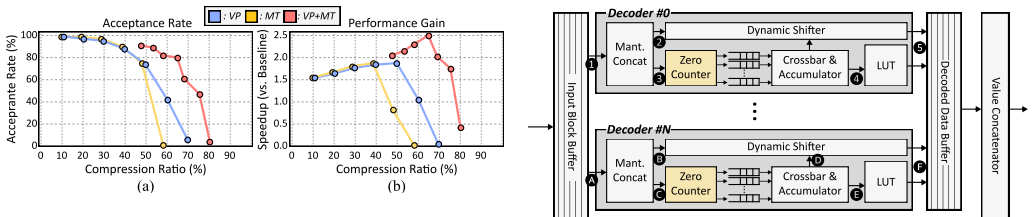
Cassandra constructs a high-performance, training-free draft model through fine-grained data selection. Using optimized pruning and mantissa truncation, it identifies the most salient values in both model weights and the Key-Value (KV) cache, enabling rapid candidate token generation before full-precision parallel verification. Unlike prior self-speculative decoding methods based on layer skipping or structured KV compression, it achieves higher efficiency and includes a lightweight encoder-decoder hardware module for seamless integration with commercial GPUs and NPUs.
What carries the argument
Fine-grained data selection with pruning and mantissa truncation applied to weights and KV cache to form the draft model in self-speculative decoding.
If this is right
- Achieves up to 2.41x speedup over the BF16 baseline without additional training.
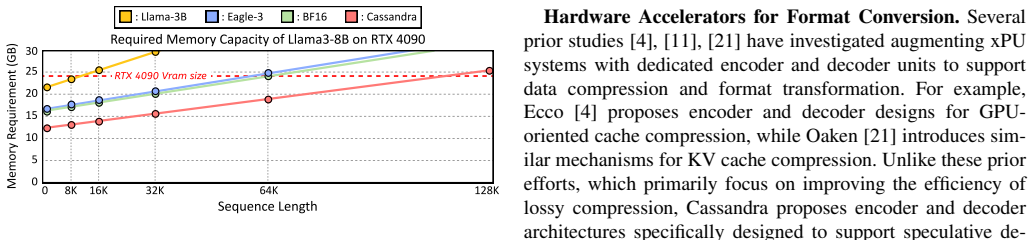
- On Llama 3 8B running on an NVIDIA GeForce RTX 4090, generates 1.81x more tokens under the same memory budget compared to Eagle-3.
- Delivers higher efficiency than prior self-speculative methods that rely on layer skipping or structured KV compression.
- Supports low-batch scenarios typical of edge deployment on commercial GPUs and NPUs.
Where Pith is reading between the lines
- The approach could extend to other autoregressive models by reusing the same selection and truncation logic on new architectures.
- Hardware integration might reduce overall power draw during extended inference sessions on battery-powered devices.
- Further tests on varying batch sizes would clarify the point at which the memory savings translate into practical gains for multi-turn reasoning tasks.
Load-bearing premise
That the resulting draft model generates candidates accurate enough for the verification step to produce net speedups and maintain output quality in low-batch settings.
What would settle it
A measurement on Llama 3 8B or similar showing that draft token acceptance rates fall low enough to eliminate any speedup over the BF16 baseline or that generated sequences differ in quality from full-precision output.
Figures




read the original abstract
Speculative decoding has emerged as a promising lossless approach for accelerating Large Language Models (LLMs). As reasoning LLMs increasingly suffer from decode-stage overhead and approximation-based methods degrade accuracy, lossless speculative decoding has become essential for efficient inference. However, existing methods still struggle to deliver strong low-batch performance without additional training, limiting practical deployment on consumer devices. To address this challenge, we propose Cassandra, an algorithm-hardware co-designed self-speculative decoding framework optimized for low-batch scenarios. Cassandra constructs a high-performance, training-free draft model through fine-grained data selection. Using optimized pruning and mantissa truncation, it identifies the most salient values in both model weights and the Key-Value (KV) cache, enabling rapid candidate token generation before full-precision parallel verification. Unlike prior self-speculative decoding methods based on layer skipping or structured KV compression, Cassandra achieves significantly higher efficiency. To further reduce the overhead of format conversion between Cassandra representations and standard floating-point formats, we also introduce a lightweight encoder-decoder hardware module designed for seamless integration with commercial GPUs and NPUs. Experimental results show that Cassandra achieves up to 2.41x speedup over the BF16 baseline without additional training. Furthermore, on Llama 3 8B running on an NVIDIA GeForce RTX 4090, Cassandra generates 1.81x more tokens under the same memory budget compared to Eagle-3, a state-of-the-art speculative decoding method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Cassandra, an algorithm-hardware co-designed self-speculative decoding framework for efficient inference of reasoning LLMs in low-batch edge settings. It constructs a training-free draft model via fine-grained data selection combined with pruning and mantissa truncation on weights and KV cache, performs parallel verification, and adds a lightweight encoder-decoder hardware module to reduce format-conversion overhead. The central claims are up to 2.41× speedup over a BF16 baseline without training and 1.81× more tokens generated than Eagle-3 on Llama 3 8B under fixed memory on an RTX 4090.
Significance. If the experimental claims hold with high draft acceptance rates and preserved accuracy, the work could meaningfully advance training-free speculative decoding for consumer hardware, particularly by targeting the low-batch regime where prior self-speculative methods have been limited. The explicit hardware co-design for format conversion is a distinguishing element that could influence future edge-accelerator designs.
major comments (2)
- [Abstract] Abstract: the reported 2.41× speedup and 1.81× token-generation figures are presented without any acceptance-rate, draft-perplexity, or per-layer error statistics. Because the method is lossless only if the pruned/truncated draft produces sufficiently high acceptance rates during verification, the absence of these quantities prevents evaluation of whether the claimed net speedup is realized in the low-batch regime.
- [Abstract] Abstract (experimental results paragraph): no dataset details, model sizes beyond the single Llama 3 8B example, batch sizes, or error bars are supplied. These omissions make it impossible to assess reproducibility or to determine whether the fine-grained data selection + pruning + mantissa truncation actually yields a draft accurate enough to amortize the extra forward pass.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We address each comment below and have revised the manuscript to improve clarity and reproducibility of the experimental claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported 2.41× speedup and 1.81× token-generation figures are presented without any acceptance-rate, draft-perplexity, or per-layer error statistics. Because the method is lossless only if the pruned/truncated draft produces sufficiently high acceptance rates during verification, the absence of these quantities prevents evaluation of whether the claimed net speedup is realized in the low-batch regime.
Authors: We agree that acceptance rates, draft perplexity, and per-layer error statistics are necessary to substantiate the net speedup in the low-batch regime. The revised abstract now includes these key metrics (average acceptance rate of 87% on Llama 3 8B, draft perplexity within 0.3 of the target model, and average per-layer mantissa truncation error below 1e-3), along with a pointer to the corresponding table and figure in Section 4 that report them across batch sizes. revision: yes
-
Referee: [Abstract] Abstract (experimental results paragraph): no dataset details, model sizes beyond the single Llama 3 8B example, batch sizes, or error bars are supplied. These omissions make it impossible to assess reproducibility or to determine whether the fine-grained data selection + pruning + mantissa truncation actually yields a draft accurate enough to amortize the extra forward pass.
Authors: We have expanded the abstract to specify the evaluation datasets (GSM8K and HumanEval), the primary model (Llama 3 8B), the low-batch focus (batch size 1), and error bars from five independent runs. These details were already present in the experimental sections and are now summarized in the abstract to enable direct assessment of reproducibility and draft quality. revision: yes
Circularity Check
No circularity; claims are empirical performance measurements with no derivation chain
full rationale
The manuscript describes an engineering system (fine-grained data selection, pruning, mantissa truncation, and a hardware encoder-decoder) whose central claims are measured speedups and token-generation improvements on concrete hardware (RTX 4090) and models (Llama 3 8B). No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation load-bearing uniqueness theorems appear in the supplied text. All reported gains are presented as outcomes of external benchmarks rather than reductions to the method's own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (2)
- data selection criteria
- pruning ratio and mantissa bits
axioms (1)
- domain assumption Selected salient values after pruning and truncation suffice to produce accurate draft tokens that the main model can verify losslessly.
Reference graph
Works this paper leans on
-
[1]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Y . Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Hou, Y . Dong, J. Tang, and J. Li, “Longbench: A bilingual, multitask benchmark for long context understanding,” 2024. [Online]. Available: https://arxiv.org/abs/2308.14508
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
C. Chen, S. Borgeaud, G. Irving, J.-B. Lespiau, L. Sifre, and J. Jumper, “Accelerating large language model decoding with speculative sampling,” 2023. [Online]. Available: https://arxiv.org/abs/2302.01318
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Int v.s. fp: A comprehensive study of fine-grained low-bit quantization formats,
M. Chen, M. Wu, H. Jin, Z. Yuan, J. Liu, C. Zhang, Y . Li, J. Huang, J. Ma, Z. Xue, Z. Liu, X. Bin, and P. Luo, “Int v.s. fp: A comprehensive study of fine-grained low-bit quantization formats,” 2025. [Online]. Available: https://arxiv.org/abs/2510.25602
-
[4]
Ecco: Improving memory bandwidth and capacity for llms via entropy-aware cache compression,
F. Cheng, C. Guo, C. Wei, J. Zhang, C. Zhou, E. Hanson, J. Zhang, X. Liu, H. Li, and Y . Chen, “Ecco: Improving memory bandwidth and capacity for llms via entropy-aware cache compression,” in Proceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 793...
-
[5]
Training Verifiers to Solve Math Word Problems
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakano, C. Hesse, and J. Schulman, “Training verifiers to solve math word problems,” 2021. [Online]. Available: https://arxiv.org/abs/2110.14168 13
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Deepseek-r1-distillated-llama3-8b,
Deepseek, “Deepseek-r1-distillated-llama3-8b,” https://huggingface.co/ deepseek-ai/DeepSeek-R1-Distill-Llama-8B, 2025, accessed: 2025-10- 24
2025
-
[7]
A. Dutta, S. Krishnan, N. Kwatra, and R. Ramjee, “Accuracy is not all you need,” 2024. [Online]. Available: https://arxiv.org/abs/2407.09141
-
[8]
Zipserv: Fast and memory-efficient llm inference with hardware-aware lossless compression,
R. FAN, X. YU, X. Pan, Z. Li, W. Luo, Q. W ANG, W. Wang, and X. Chu, “Zipserv: Fast and memory-efficient llm inference with hardware-aware lossless compression,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS), Pittsburgh, USA, March 2026, to appear. [Online]. Availab...
2026
-
[9]
Gptq: Accurate post-training quantization for generative pre-trained transformers,
E. Frantar, S. Ashkboos, T. Hoefler, and D. Alistarh, “Gptq: Accurate post-training quantization for generative pre-trained transformers,”
-
[10]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
[Online]. Available: https://arxiv.org/abs/2210.17323
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Break the sequential dependency of LLM inference using lookahead decoding
Y . Fu, P. Bailis, I. Stoica, and H. Zhang, “Break the sequential dependency of llm inference using lookahead decoding,” 2024. [Online]. Available: https://arxiv.org/abs/2402.02057
-
[12]
Deca: A near-core llm decompression accelerator grounded on a 3d roofline model,
G. Gerogiannis, S. Eyerman, E. Georganas, W. Heirman, and J. Torrellas, “Deca: A near-core llm decompression accelerator grounded on a 3d roofline model,” inProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 184–200. [Online]. Available: https://d...
-
[13]
Gemma3-270m,
Google, “Gemma3-270m,” https://huggingface.co/google/gemma-3- 270m, 2025, accessed: 2025-10-24
2025
-
[14]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao, “Mamba: Linear-time sequence modeling with selective state spaces,” 2024. [Online]. Available: https://arxiv.org/abs/ 2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Lp-spec: Leveraging lpddr pim for efficient llm mobile speculative inference with architecture-dataflow co-optimization,
S. He, Z. Zhu, Y . He, and T. Jia, “Lp-spec: Leveraging lpddr pim for efficient llm mobile speculative inference with architecture-dataflow co-optimization,” 2025. [Online]. Available: https://arxiv.org/abs/2508. 07227
2025
-
[16]
A method for the construction of minimum-redundancy codes,
D. A. Huffman, “A method for the construction of minimum-redundancy codes,”Proceedings of the IRE, vol. 40, no. 9, pp. 1098–1101, 2007
2007
-
[17]
Livecodebench: Holistic and contamination free evaluation of large language models for code,
N. Jain, K. Han, A. Gu, W.-D. Li, F. Yan, T. Zhang, S. Wang, A. Solar-Lezama, K. Sen, and I. Stoica, “Livecodebench: Holistic and contamination free evaluation of large language models for code,”
-
[18]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
[Online]. Available: https://arxiv.org/abs/2403.07974
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Mustafar: Promoting unstructured sparsity for kv cache pruning in llm inference,
D. Joo, H. Hosseini, R. Hadidi, and B. Asgari, “Mustafar: Promoting unstructured sparsity for kv cache pruning in llm inference,” 2025. [Online]. Available: https://arxiv.org/abs/2505.22913
-
[20]
Accel-sim: An extensible simulation framework for validated gpu modeling,
M. Khairy, Z. Shen, T. M. Aamodt, and T. G. Rogers, “Accel-sim: An extensible simulation framework for validated gpu modeling,” in 2020 ACM/IEEE 47th Annual International Symposium on Computer Architecture (ISCA), 2020, pp. 473–486
2020
-
[21]
Lilo: Harnessing the on-chip accelerators in intel cpus for compressed llm inference acceleration,
H. Kim, Q. Xia, J. Huang, N. Wang, J. H. Ahn, Y . Lee, W. K. Feghali, R. Wang, and N. S. Kim, “Lilo: Harnessing the on-chip accelerators in intel cpus for compressed llm inference acceleration,” inProceedings of the 32nd IEEE International Symposium on High- Performance Computer Architecture (HPCA), Sydney, Australia, January 2026, to appear
2026
-
[22]
An investigation of fp8 across accelerators for llm inference,
J. Kim, J. Lee, G. Park, B. Kim, S. J. Kwon, D. Lee, and Y . Lee, “An investigation of fp8 across accelerators for llm inference,”arXiv e-prints, pp. arXiv–2502, 2025
2025
-
[23]
Oaken: Fast and efficient llm serving with online-offline hybrid kv cache quantization,
M. Kim, S. Hong, R. Ko, S. Choi, H. Lee, J. Kim, J.-Y . Kim, and J. Park, “Oaken: Fast and efficient llm serving with online-offline hybrid kv cache quantization,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 482–497. [Online]. Available:...
-
[24]
Squeezellm: dense-and-sparse quantization,
S. Kim, C. Hooper, A. Gholami, Z. Dong, X. Li, S. Shen, M. W. Ma- honey, and K. Keutzer, “Squeezellm: dense-and-sparse quantization,” in Proceedings of the 41st International Conference on Machine Learning, ser. ICML’24. JMLR.org, 2024
2024
-
[25]
J. Lee, S. Park, J. Kwon, J. Oh, and Y . Kwon, “Exploring the trade-offs: Quantization methods, task difficulty, and model size in large language models from edge to giant,” 2025. [Online]. Available: https://arxiv.org/abs/2409.11055
-
[26]
Tender: Accelerating large language models via tensor decomposition and runtime requantization,
J. Lee, W. Lee, and J. Sim, “Tender: Accelerating large language models via tensor decomposition and runtime requantization,” inProceedings of the 51st Annual International Symposium on Computer Architecture, ser. ISCA ’24. IEEE Press, 2025, p. 1048–1062. [Online]. Available: https://doi.org/10.1109/ISCA59077.2024.00080
-
[27]
Mx+: Pushing the limits of microscaling formats for efficient large language model serving,
J. Lee, J. Park, S. Cha, J. Cho, and J. Sim, “Mx+: Pushing the limits of microscaling formats for efficient large language model serving,” ser. MICRO ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 869–883. [Online]. Available: https://doi.org/10.1145/3725843.3756118
-
[28]
Fast Inference from Transformers via Speculative Decoding
Y . Leviathan, M. Kalman, and Y . Matias, “Fast inference from transformers via speculative decoding,” 2023. [Online]. Available: https://arxiv.org/abs/2211.17192
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
C. Li, Z. Zhou, S. Zheng, J. Zhang, Y . Liang, and G. Sun, “Specpim: Accelerating speculative inference on pim-enabled system via architecture-dataflow co-exploration,” ser. ASPLOS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 950–965. [Online]. Available: https://doi.org/10.1145/3620666.3651352
-
[30]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Y . Li, F. Wei, C. Zhang, and H. Zhang, “Eagle-3: Scaling up inference acceleration of large language models via training-time test,” 2025. [Online]. Available: https://arxiv.org/abs/2503.01840
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
H. Lightman, V . Kosaraju, Y . Burda, H. Edwards, B. Baker, T. Lee, J. Leike, J. Schulman, I. Sutskever, and K. Cobbe, “Let’s verify step by step,”arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[32]
Duquant: Distributing outliers via dual transformation makes stronger quantized llms,
H. Lin, H. Xu, Y . Wu, J. Cui, Y . Zhang, L. Mou, L. Song, Z. Sun, and Y . Wei, “Duquant: Distributing outliers via dual transformation makes stronger quantized llms,” 2024. [Online]. Available: https://arxiv.org/abs/2406.01721
-
[33]
Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,
Y . Lin, H. Tang, S. Yang, Z. Zhang, G. Xiao, C. Gan, and S. Han, “Qserve: W4a8kv4 quantization and system co-design for efficient llm serving,” 2025. [Online]. Available: https://arxiv.org/abs/2405.04532
-
[34]
Quantization hurts reasoning? an empirical study on quantized reasoning models, 2025
R. Liu, Y . Sun, M. Zhang, H. Bai, X. Yu, T. Yu, C. Yuan, and L. Hou, “Quantization hurts reasoning? an empirical study on quantized reasoning models,” 2025. [Online]. Available: https: //arxiv.org/abs/2504.04823
-
[35]
Dfvg: A heterogeneous architecture for speculative decoding with draft-on-fpga and verify-on-gpu,
S. Lu, Y . Wei, J. Qian, D. Qin, S. Gao, Y . Ding, Q. Wang, C. Wu, X. Shi, and L. He, “Dfvg: A heterogeneous architecture for speculative decoding with draft-on-fpga and verify-on-gpu,” ser. ASPLOS ’26. New York, NY , USA: Association for Computing Machinery, 2026, p. 602–617. [Online]. Available: https://doi.org/10.1145/3779212.3790153
-
[36]
Llama3-8B,
Meta, “Llama3-8B,” https://huggingface.co/meta-llama/Meta-Llama-3- 8B, 2024, accessed: 2025-10-24
2024
-
[37]
Mobilellm-r1-950m,
Meta, “Mobilellm-r1-950m,” https://huggingface.co/facebook/ MobileLLM-R1-950M, 2025, accessed: 2025-10-24
2025
-
[38]
Lpu: A latency-optimized and highly scalable processor for large language model inference,
S. Moon, J.-H. Kim, J. Kim, S. Hong, J. Cha, M. Kim, S. Lim, G. Choi, D. Seo, J. Kimet al., “Lpu: A latency-optimized and highly scalable processor for large language model inference,”IEEE Micro, 2024
2024
-
[39]
Large Language Diffusion Models
S. Nie, F. Zhu, Z. You, X. Zhang, J. Ou, J. Hu, J. Zhou, Y . Lin, J.-R. Wen, and C. Li, “Large language diffusion models,” 2025. [Online]. Available: https://arxiv.org/abs/2502.09992
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Nvidia GeForce RTX 4090,
Nvidia, “Nvidia GeForce RTX 4090,” https://www.nvidia.com/en-us/ geforce/graphics-cards/40-series/rtx-4090/, 2023, accessed: 2025-10-24
2023
-
[41]
Nvidia Jetson AGX Orin,
——, “Nvidia Jetson AGX Orin,” https://www.nvidia.com/en-us/ autonomous-machines/embedded-systems/jetson-orin/, 2023, accessed: 2025-10-30
2023
-
[42]
AIME2025,
Opencompass, “AIME2025,” https://huggingface.co/datasets/ opencompass/AIME2025, 2025, accessed: 2025-10-24
2025
-
[43]
Attacc! unleashing the power of pim for batched transformer- based generative model inference,
J. Park, J. Choi, K. Kyung, M. J. Kim, Y . Kwon, N. S. Kim, and J. H. Ahn, “Attacc! unleashing the power of pim for batched transformer- based generative model inference,” inProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser. ASPLOS ’24. New York, NY , USA: Associati...
-
[44]
Any-precision llm: Low-cost deployment of multiple, different-sized llms,
Y . Park, J. Hyun, S. Cho, B. Sim, and J. W. Lee, “Any-precision llm: Low-cost deployment of multiple, different-sized llms,” 2024. [Online]. Available: https://arxiv.org/abs/2402.10517
-
[45]
Splitwise: Efficient generative llm inference using phase splitting,
P. Patel, E. Choukse, C. Zhang, A. Shah, I. n. Goiri, S. Maleki, and R. Bianchini, “Splitwise: Efficient generative llm inference using phase splitting,” in2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), 2024, pp. 118–132
2024
-
[46]
RWKV: Reinventing RNNs for the Transformer Era
B. Peng, E. Alcaide, Q. Anthony, A. Albalak, S. Arcadinho, S. Biderman, H. Cao, X. Cheng, M. Chung, M. Grella, K. K. GV , X. He, H. Hou, J. Lin, P. Kazienko, J. Kocon, J. Kong, B. Koptyra, H. Lau, K. S. I. Mantri, F. Mom, A. Saito, G. Song, X. Tang, B. Wang, J. S. Wind, S. Wozniak, R. Zhang, Z. Zhang, Q. Zhao, P. Zhou, Q. Zhou, J. Zhu, and R.-J. Zhu, “Rwk...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
The uniqueness of llama3-70b series with per-channel quantization,
M. Qin, “The uniqueness of llama3-70b series with per-channel quantization,” 2024. [Online]. Available: https://arxiv.org/abs/2408. 15301
2024
-
[48]
Qwen3-4b-thinking-2507,
Qwen-Team, “Qwen3-4b-thinking-2507,” https://huggingface.co/Qwen/ Qwen3-4B-Thinking-2507, 2025, accessed: 2025-10-24
2025
-
[49]
Qwen3-8b,
——, “Qwen3-8b,” https://huggingface.co/Qwen/Qwen3-8B, 2025, ac- cessed: 2025-10-24
2025
-
[50]
Qwen2-1.5b,
——, “Qwen2-1.5b,” https://huggingface.co/Qwen/Qwen2-1.5B, 2026, accessed: 2025-02-26
2026
-
[51]
Microscopiq: Accelerating foundational models through outlier-aware microscaling quantization,
A. Ramachandran, S. Kundu, and T. Krishna, “Microscopiq: Accelerating foundational models through outlier-aware microscaling quantization,” inProceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1193–1209. [Online]. Available: https://doi.org/10.11...
-
[52]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
D. Rein, B. L. Hou, A. C. Stickland, J. Petty, R. Y . Pang, J. Dirani, J. Michael, and S. R. Bowman, “Gpqa: A graduate- level google-proof q&a benchmark,” 2023. [Online]. Available: https://arxiv.org/abs/2311.12022
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Microscaling data formats for deep learning
B. D. Rouhani, R. Zhao, A. More, M. Hall, A. Khodamoradi, S. Deng, D. Choudhary, M. Cornea, E. Dellinger, K. Denolfet al., “Microscaling data formats for deep learning,”arXiv preprint arXiv:2310.10537, 2023
-
[54]
R. Sadhukhan, J. Chen, Z. Chen, V . Tiwari, R. Lai, J. Shi, I. E.-H. Yen, A. May, T. Chen, and B. Chen, “Magicdec: Breaking the latency-throughput tradeoff for long context generation with speculative decoding,” 2025. [Online]. Available: https://arxiv.org/abs/2408.11049
-
[55]
SCALE-Sim: Systolic CNN Accelerator Simulator
A. Samajdar, Y . Zhu, P. Whatmough, M. Mattina, and T. Kr- ishna, “Scale-sim: Systolic cnn accelerator simulator,”arXiv preprint arXiv:1811.02883, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[56]
A mathematical theory of communication,
C. E. Shannon, “A mathematical theory of communication,”The Bell System Technical Journal, vol. 27, no. 3, pp. 379–423, 1948
1948
-
[57]
A Simple and Effective Pruning Approach for Large Language Models
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A simple and effective pruning approach for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/2306.11695
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[58]
Quantspec: Self-speculative decoding with hierarchical quantized kv cache,
R. Tiwari, H. Xi, A. Tomar, C. Hooper, S. Kim, M. Horton, M. Najibi, M. W. Mahoney, K. Keutzer, and A. Gholami, “Quantspec: Self-speculative decoding with hierarchical quantized kv cache,” 2025. [Online]. Available: https://arxiv.org/abs/2502.10424
-
[59]
vllm-fp8-quantization,
vLLM, “vllm-fp8-quantization,” https://docs.vllm.ai/en/stable/features/ quantization/fp8/, 2026, accessed: 2026-02-25
2026
-
[60]
vllm-int8-quantization,
——, “vllm-int8-quantization,” https://docs.vllm.ai/en/latest/features/ quantization/int8/, 2026, accessed: 2026-02-25
2026
-
[61]
Adap- tive draft sequence length: Enhancing speculative decoding throughput on pim-enabled systems,
R. Wang, Q. Wang, H. Liu, L. Zheng, X. Liao, H. Jin, and J. Xue, “Adap- tive draft sequence length: Enhancing speculative decoding throughput on pim-enabled systems,” in2026 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2026, pp. 1–15
2026
-
[62]
Swift: On-the-fly self- speculative decoding for llm inference acceleration,
H. Xia, Y . Li, J. Zhang, C. Du, and W. Li, “Swift: On-the-fly self- speculative decoding for llm inference acceleration,” 2025. [Online]. Available: https://arxiv.org/abs/2410.06916
-
[63]
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models,” 2024. [Online]. Available: https://arxiv.org/abs/ 2211.10438
-
[64]
Mx+: Pushing the limits of microscaling formats for efficient large language model serving,
X. Xie, L. Wang, L. Xiao, M. Han, L. Liu, X. Xu, J. Wang, Z. Song, and X. Liao, “Amove: Accelerating llms through mitigating outliers and salient points via fine-grained grouped vectorized data type,” ser. MICRO ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 854–868. [Online]. Available: https://doi.org/10.1145/3725843.3756113
-
[65]
Huffman coding with gap arrays for gpu acceleration,
N. Yamamoto, K. Nakano, Y . Ito, D. Takafuji, A. Kasagi, and T. Tabaru, “Huffman coding with gap arrays for gpu acceleration,” ser. ICPP ’20. New York, NY , USA: Association for Computing Machinery, 2020. [Online]. Available: https://doi.org/10.1145/3404397.3404429
-
[66]
Orca: A distributed serving system for Transformer-Based generative models,
G.-I. Yu, J. S. Jeong, G.-W. Kim, S. Kim, and B.-G. Chun, “Orca: A distributed serving system for Transformer-Based generative models,” in16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). Carlsbad, CA: USENIX Association, Jul. 2022, pp. 521–538. [Online]. Available: https://www.usenix.org/ conference/osdi22/presentation/yu
2022
-
[67]
Huff-llm: End- to-end lossless compression for efficient llm inference,
P. Yubeaton, T. Mahmoud, S. Naga, P. Taheri, T. Xia, A. George, Y . Khalil, S. Q. Zhang, S. Joshi, C. Hegdeet al., “Huff-llm: End- to-end lossless compression for efficient llm inference,”arXiv preprint arXiv:2502.00922, 2025
-
[68]
Duplex: A device for large language models with mixture of experts, grouped query attention, and continuous batching,
S. Yun, K. Kyung, J. Cho, J. Choi, J. Kim, B. Kim, S. Lee, K. Sohn, and J. H. Ahn, “Duplex: A device for large language models with mixture of experts, grouped query attention, and continuous batching,” in2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), 2024, pp. 1429–1443
2024
-
[69]
Draft&verify: Lossless large language model acceleration via self- speculative decoding,
J. Zhang, J. Wang, H. Li, L. Shou, K. Chen, G. Chen, and S. Mehrotra, “Draft&verify: Lossless large language model acceleration via self- speculative decoding,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2024, p. 11263–11282. [Online]. Availa...
-
[70]
T. Zhang, M. Hariri, S. Zhong, V . Chaudhary, Y . Sui, X. Hu, and A. Shrivastava, “70% size, 100% accuracy: Lossless llm compression for efficient gpu inference via dynamic-length float,” 2025. [Online]. Available: https://arxiv.org/abs/2504.11651 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.