Birkhoff Decompositions and Photonic Interconnects Wait! Don't Forget the Compute!
Pith reviewed 2026-07-01 16:16 UTC · model grok-4.3
The pith
A greedy max-weight decomposition for MoE all-to-all on photonic interconnects bounds matchings and avoids compute fragmentation that plagues Birkhoff-von Neumann schedules.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
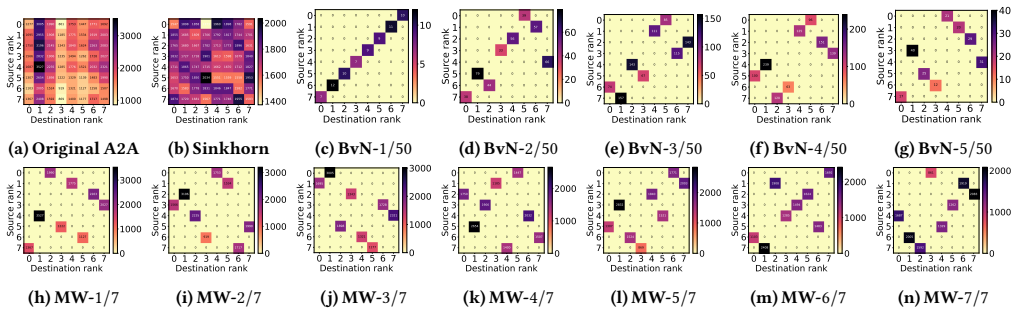
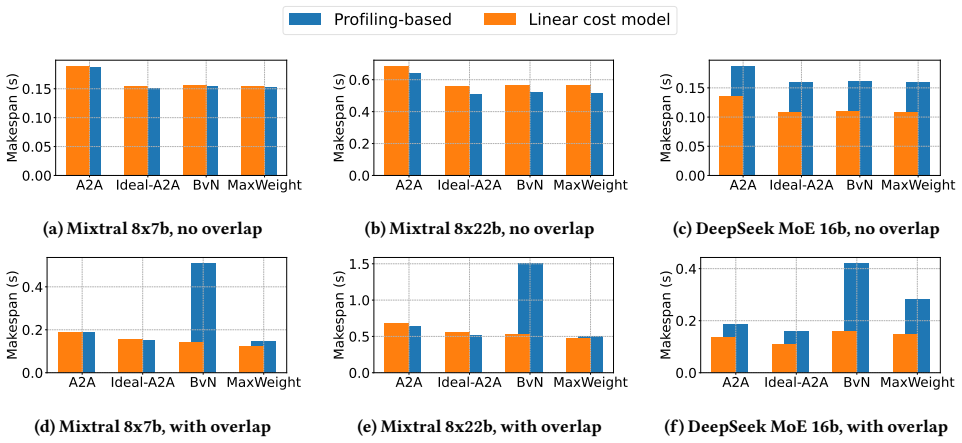
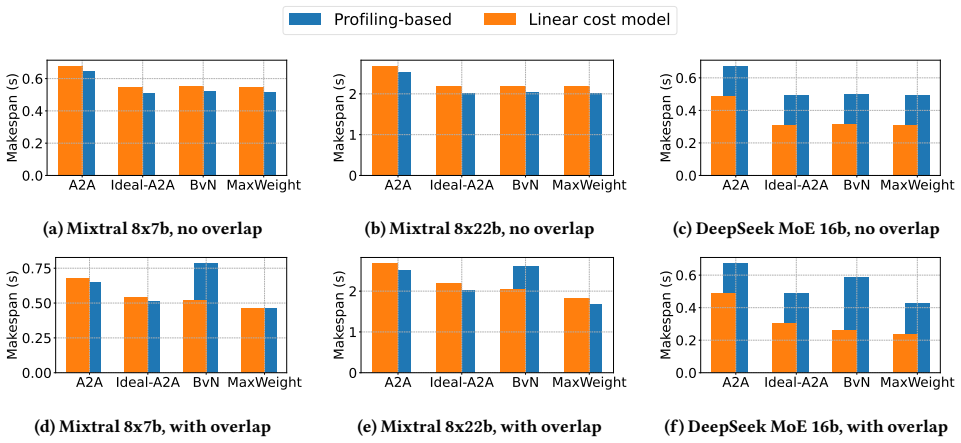
The dispatch-compute-combine structure of MoE fundamentally challenges classical scheduling techniques such as Birkhoff-von Neumann decomposition: communication matrices are rarely doubly stochastic, producing scheduling bubbles, and the excessive matchings fragment execution into small batches that trigger severe compute inefficiencies due to fixed execution overheads; a simple greedy max-weight decomposition strategy that bounds the number of matchings while preserving large batch sizes per matching improves overlap efficiency, reduces compute overheads, and approaches the performance of an ideal congestion-free all-to-all.
What carries the argument
Greedy max-weight decomposition strategy that bounds the number of matchings while preserving large batch sizes per matching.
If this is right
- Improves overlap efficiency between communication and computation in MoE execution.
- Reduces compute overheads caused by fixed execution costs on small batches.
- Approaches the performance of an ideal congestion-free all-to-all.
Where Pith is reading between the lines
- The same bounded-matching principle could apply to other distributed workloads that combine skewed communication with batch-sensitive compute stages.
- Photonic interconnect controllers might benefit from exposing batch-size constraints to the scheduler rather than treating communication as an isolated optimization.
- Hardware experiments that vary the overhead per expert invocation would directly test how much the greedy bound matters in practice.
Load-bearing premise
The fixed execution overheads in the dispatch-compute-combine structure of MoE make small-batch fragmentation from excessive matchings severely inefficient.
What would settle it
Measure end-to-end training throughput or latency of an MoE model on a photonic interconnect testbed when using Birkhoff-von Neumann schedules versus the proposed greedy max-weight schedules.
Figures

read the original abstract
The growing demand for efficient communication in distributed training and inference has sparked significant interest in reconfigurable photonic interconnects across both academia and industry. Mixture-of-Experts (MoE) models, with their highly skewed communication patterns, present a natural opportunity for such circuit-switched fabrics. However, existing approaches largely optimize communication in isolation, overlooking the interaction between communication and the expert computation that follows. In this paper, we revisit circuit scheduling for all-to-all communication in MoE execution. We show that the dispatch--compute--combine structure fundamentally challenges classical scheduling techniques such as Birkhoff--von Neumann (BvN) decomposition. First, MoE communication matrices are rarely doubly stochastic, introducing significant scheduling bubbles in BvN-based schedules. Second, while decomposition enables communication--compute overlap, the excessive number of matchings produced by BvN fragments execution into small batches, leading to severe compute inefficiencies due to fixed execution overheads. Motivated by these observations, we explore a simple greedy max-weight decomposition strategy that bounds the number of matchings while preserving large batch sizes per matching. Despite its simplicity, the approach significantly improves overlap efficiency, reduces compute overheads, and approaches the performance of an ideal congestion-free all-to-all.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that Birkhoff-von Neumann (BvN) decomposition is ill-suited for scheduling all-to-all communication in Mixture-of-Experts (MoE) models over photonic interconnects. It identifies two issues: MoE traffic matrices are rarely doubly stochastic (producing scheduling bubbles) and BvN generates too many matchings, fragmenting the dispatch-compute-combine pipeline into small batches that incur high fixed compute overheads. The authors propose a simple greedy max-weight decomposition that limits the number of matchings while preserving larger per-matching batches, claiming this yields better overlap efficiency, lower compute overhead, and performance close to an ideal congestion-free all-to-all.
Significance. If the fragmentation penalty and the greedy method's gains are empirically validated on real MoE workloads and accelerators, the work would usefully shift attention from pure communication optimization to the joint communication-compute scheduling problem in reconfigurable photonic fabrics for large-scale training. The emphasis on bounding matchings to protect batch sizes is a concrete, actionable insight for circuit-switched MoE systems.
major comments (3)
- [Abstract, §3] Abstract and §3 (motivation): the central claim that BvN produces 'excessive' matchings leading to 'severe compute inefficiencies' due to fixed overheads is stated without any reported statistics on typical matching counts, resulting batch-size distributions, or measured per-batch launch overheads on target hardware. This leaves the severity of the fragmentation penalty unquantified and the motivation for the greedy bound unsupported by data.
- [Abstract, §4] Abstract and §4 (proposed method): the greedy max-weight decomposition is described only at a high level; no pseudocode, complexity analysis, or proof that it bounds the number of matchings (relative to BvN) while preserving large batches appears. Without these, it is impossible to assess whether the approach actually mitigates the stated BvN drawbacks or merely trades one set of inefficiencies for another.
- [§5] Evaluation section (presumed §5): the abstract asserts that the greedy method 'significantly improves overlap efficiency, reduces compute overheads, and approaches the performance of an ideal congestion-free all-to-all,' yet no end-to-end speedup numbers, comparison tables against BvN or ideal baselines, or ablation on matching count versus batch size are referenced. Load-bearing performance claims therefore rest on unshown results.
minor comments (2)
- [Title] The paper title uses an informal exclamation that may not align with the formal tone expected by the journal; consider a more descriptive title.
- [§2] Notation for traffic matrices, matchings, and overhead terms should be introduced consistently with equation numbers once the full derivations appear.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed report. The comments highlight opportunities to strengthen the quantification of BvN drawbacks and the presentation of the greedy method and its evaluation. We address each point below and commit to revisions that directly respond to the concerns while preserving the core technical contributions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (motivation): the central claim that BvN produces 'excessive' matchings leading to 'severe compute inefficiencies' due to fixed overheads is stated without any reported statistics on typical matching counts, resulting batch-size distributions, or measured per-batch launch overheads on target hardware. This leaves the severity of the fragmentation penalty unquantified and the motivation for the greedy bound unsupported by data.
Authors: We agree that explicit quantification would strengthen the motivation. The current manuscript motivates the issue via the dispatch-compute-combine structure and the non-doubly-stochastic nature of MoE matrices, but does not report concrete matching counts, batch-size histograms, or hardware launch-overhead measurements. In the revision we will add these statistics, drawn from BvN decompositions of representative MoE all-to-all matrices and micro-benchmarks of per-batch overheads on the target accelerators, to make the fragmentation penalty concrete. revision: yes
-
Referee: [Abstract, §4] Abstract and §4 (proposed method): the greedy max-weight decomposition is described only at a high level; no pseudocode, complexity analysis, or proof that it bounds the number of matchings (relative to BvN) while preserving large batches appears. Without these, it is impossible to assess whether the approach actually mitigates the stated BvN drawbacks or merely trades one set of inefficiencies for another.
Authors: The greedy max-weight procedure is intentionally simple, but the referee is correct that the manuscript presents it at a high level. We will include pseudocode, a complexity statement, and an argument (supported by both analysis and empirical counts) showing that the number of matchings is bounded while per-matching batch sizes remain substantially larger than those produced by BvN. This will allow readers to evaluate the trade-offs directly. revision: yes
-
Referee: [§5] Evaluation section (presumed §5): the abstract asserts that the greedy method 'significantly improves overlap efficiency, reduces compute overheads, and approaches the performance of an ideal congestion-free all-to-all,' yet no end-to-end speedup numbers, comparison tables against BvN or ideal baselines, or ablation on matching count versus batch size are referenced. Load-bearing performance claims therefore rest on unshown results.
Authors: The evaluation does contain simulation and emulation results comparing the greedy approach to BvN and an ideal baseline, but the referee correctly notes that the abstract claims are not accompanied by explicit numeric references or ablations in the current text. We will revise the abstract and evaluation section to include concrete end-to-end speedup figures, comparison tables, and an ablation study that isolates the effect of matching count on batch size and overall efficiency. revision: yes
Circularity Check
No circularity; claims rest on qualitative observations of MoE structure without equations or self-referential reductions
full rationale
The paper states two observations (MoE matrices rarely doubly stochastic; BvN produces excessive matchings that fragment batches) and proposes a greedy max-weight decomposition to bound matchings while preserving batch size. No equations, fitted parameters, self-citations, or derivations appear in the abstract or described text. The performance claims are presented as direct consequences of the proposed strategy rather than predictions that reduce to inputs by construction. The argument is self-contained against external benchmarks and does not invoke any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption MoE communication matrices are rarely doubly stochastic
- domain assumption Fixed execution overheads make small-batch fragmentation from excessive matchings severely inefficient
Reference graph
Works this paper leans on
-
[1]
When light bends to the collective will: A theory and vision for adaptive photonic scale-up domains
Vamsi Addanki. When light bends to the collective will: A theory and vision for adaptive photonic scale-up domains. InProceedings of the 24th ACM Workshop on Hot Topics in Networks, HotNets ’25, page 326–334, New York, NY, USA, 2025. Association for Computing Machinery.doi:10.1145/3772356.3772395
-
[2]
Mars: Near-optimal throughput with shallow buffers in reconfigurable datacenter networks.Proc
Vamsi Addanki, Chen Avin, and Stefan Schmid. Mars: Near-optimal throughput with shallow buffers in reconfigurable datacenter networks.Proc. ACM Meas. Anal. Comput. Syst., 7(1), mar 2023. doi:10.1145/3579312
-
[3]
Shale: A practical, scalable oblivious reconfigurable network
Daniel Amir, Nitika Saran, Tegan Wilson, Robert Kleinberg, Vishal Shrivastav, and Hakim Weatherspoon. Shale: A practical, scalable oblivious reconfigurable network. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, page 449–464, New York, NY, USA, 2024. Association for Computing Machinery. doi:10.1145/3651890.3672248
-
[4]
Reconfigurability within collective communication algorithms
Rukshani Athapathu and George Porter. Reconfigurability within collective communication algorithms. InProceedings of the 2nd Workshop on Networks for AI Computing, NAIC ’25, page 43–49, New York, NY, USA, 2025. Association for Computing Machinery. doi:10.1145/3748273.3749203
-
[5]
Revolutionizing datacenter networks via reconfigurable topologies.Commun
Chen Avin and Stefan Schmid. Revolutionizing datacenter networks via reconfigurable topologies.Commun. ACM, 68(6):44–53, June 2025. doi:10.1145/3708980
-
[6]
Sirius: A flat datacenter network with nanosecond optical switching
Hitesh Ballani, Paolo Costa, Raphael Behrendt, Daniel Cletheroe, Istvan Haller, Krzysztof Jozwik, Fotini Karinou, Sophie Lange, Kai Shi, Benn Thomsen, and Hugh Williams. Sirius: A flat datacenter network with nanosecond optical switching. InProceedings of the Annual Conference of the ACM Special Interest Group on Data Communication on the Appli- cations, ...
-
[7]
Tres observaciones sobre el algebra lin- eal.Univ
G BIRKHOFF. Tres observaciones sobre el algebra lin- eal.Univ. Nac. Tucuman, Ser. A, 5:147–154, 1946. URL: https://cir.nii.ac.jp/crid/1570572699525842816
-
[8]
Costly circuits, submodular schedules and approximate carathéodory theorems
Shaileshh Bojja Venkatakrishnan, Mohammad Alizadeh, and Pramod Viswanath. Costly circuits, submodular schedules and approximate carathéodory theorems. InProceedings of the 2016 ACM SIGMETRICS International Conference on Measurement and Modeling of Computer Science, SIGMETRICS ’16, page 75–88, New York, NY, USA, 2016. Asso- ciation for Computing Machinery....
-
[9]
David F. Crouse. On implementing 2d rectangular assignment algorithms.IEEE Transactions on Aerospace and Electronic Systems, 52(4):1679–1696, 2016.doi:10.1109/TAES.2016.140952. 7
-
[10]
Helios: a hybrid electrical/optical switch architecture for modular data centers
Nathan Farrington, George Porter, Sivasankar Radhakrishnan, Hamid Hajabdolali Bazzaz, Vikram Subramanya, Yeshaiahu Fainman, George Papen, and Amin Vahdat. Helios: a hybrid electrical/optical switch architecture for modular data centers. InProceedings of the ACM SIGCOMM 2010 Conference, SIGCOMM ’10, page 339–350, New York, NY, USA, 2010. Association for Co...
-
[11]
Switch transformers: scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res., 23(1), 1 2022
2022
-
[12]
MoETuner: Optimized Mixture of Expert Serving with Balanced Expert Placement and Token Routing,
Seokjin Go and Divya Mahajan. MoETuner: Optimized Mixture of Expert Serving with Balanced Expert Placement and Token Routing,
- [13]
-
[14]
Gurobi Optimizer Reference Manual, 2023
Gurobi Optimization, LLC. Gurobi Optimizer Reference Manual, 2023. URL: https://www.gurobi.com
2023
-
[15]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
S M Johnson. Optimal two- and three-stage production schedules with setup times included.Naval Research Logistics Quarterly, 1(1):61–68, 1954. URL: https://onlinelibrary .wiley.com/doi/abs/ 10.1002/nav.3800010110,doi:10.1002/nav.3800010110
-
[17]
Norman P. Jouppi and Andy Swing. A machine learning supercomputer with an optically reconfigurable interconnect and embeddings support. In2023 IEEE Hot Chips 35 Symposium (HCS), pages 1–24, 2023. doi:10.1109/HCS59251.2023.10254691
-
[18]
Scheduling opportunistic links in two-tiered reconfigurable datacenters
Janardhan Kulkarni, Stefan Schmid, and Paweł Schmidt. Scheduling opportunistic links in two-tiered reconfigurable datacenters. InPro- ceedings of the 33rd ACM Symposium on Parallelism in Algorithms and Architectures, SPAA ’21, page 318–327, New York, NY, USA, 2021. Asso- ciation for Computing Machinery.doi:10.1145/3409964.3461786
-
[19]
A case for server-scale photonic connectivity
Abhishek Vijaya Kumar, Arjun Devraj, Darius Bunandar, and Rachee Singh. A case for server-scale photonic connectivity. InProceedings of the 23rd ACM Workshop on Hot Topics in Networks, HotNets ’24, page 290–299, New York, NY, USA, 2024. Association for Computing Machinery.doi:10.1145/3696348.3696856
-
[20]
Xudong Liao, Yijun Sun, Han Tian, Xinchen Wan, Yilun Jin, Zilong Wang, Zhenghang Ren, Xinyang Huang, Wenxue Li, Kin Fai Tse, Zhizhen Zhong, Guyue Liu, Ying Zhang, Xiaofeng Ye, Yiming Zhang, and Kai Chen. Mixnet: A runtime reconfigurable optical-electrical fabric for distributed mixture-of-experts training. InProceedings of the ACM SIGCOMM 2025 Conference,...
-
[21]
Mukerjee, Conglong Li, Nicolas Feltman, George Papen, Stefan Savage, Srinivasan Seshan, Geoffrey M
He Liu, Matthew K. Mukerjee, Conglong Li, Nicolas Feltman, George Papen, Stefan Savage, Srinivasan Seshan, Geoffrey M. Voelker, David G. Andersen, Michael Kaminsky, George Porter, and Alex C. Snoeren. Scheduling techniques for hybrid circuit/packet networks. InProceed- ings of the 11th ACM Conference on Emerging Networking Experiments and Technologies, Co...
-
[22]
Mellette, Alex Forencich, Rukshani Athapathu, Alex C
William M. Mellette, Alex Forencich, Rukshani Athapathu, Alex C. Snoeren, George Papen, and George Porter. Realizing rotornet: Toward practical microsecond scale optical networking. InProceedings of the ACM SIGCOMM 2024 Conference, ACM SIGCOMM ’24, page 392–414, New York, NY, USA, 2024. Association for Computing Machinery. doi:10.1145/3651890.3672273
-
[23]
Mellette, Rob McGuinness, Arjun Roy, Alex Forencich, George Papen, Alex C
William M. Mellette, Rob McGuinness, Arjun Roy, Alex Forencich, George Papen, Alex C. Snoeren, and George Porter. Rotornet: A scal- able, low-complexity, optical datacenter network. InProceedings of the Conference of the ACM Special Interest Group on Data Communication, SIGCOMM ’17, page 267–280, New York, NY, USA, 2017. Association for Computing Machiner...
-
[24]
A survey of reconfigurable optical net- works.Optical Switching and Networking, 41:100621, 2021
Matthew Nance Hall, Klaus-Tycho Foerster, Stefan Schmid, and Ramakrishnan Durairajan. A survey of reconfigurable optical net- works.Optical Switching and Networking, 41:100621, 2021. URL: https: //www.sciencedirect.com/science/article/pii/S1573427721000187, doi:10.1016/j.osn.2021.100621
-
[25]
Integrating microsecond circuit switching into the data center
George Porter, Richard Strong, Nathan Farrington, Alex Forencich, Pang Chen-Sun, Tajana Rosing, Yeshaiahu Fainman, George Papen, and Amin Vahdat. Integrating microsecond circuit switching into the data center. InProceedings of the ACM SIGCOMM 2013 Conference on SIGCOMM, SIGCOMM ’13, page 447–458, New York, NY, USA, 2013. As- sociation for Computing Machin...
-
[26]
Mahir Rahman, Samuel Joseph, Nihar Kodkani, Behnaz Arzani, and Vamsi Addanki. Harvest: Adaptive photonic switching schedules for collective communication in scale-up domains, 2026. URL: https://arxiv.org/abs/2602.09188,arXiv:2602.09188
-
[27]
Chronos: Presched- uled circuit switching for llm training
Sundararajan Renganathan and Nick McKeown. Chronos: Presched- uled circuit switching for llm training. InProceedings of the 2nd Workshop on Networks for AI Computing, NAIC ’25, page 89–97, New York, NY, USA, 2025. Association for Computing Machinery. doi:10.1145/3748273.3749210
-
[28]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer, 2017. URL: https://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
Industry insight: photonics to scale ai data centers.npj Nanophotonics, 3(1):8, 2026
Luis Torrijos-Morán and Daniel Pérez-López. Industry insight: photonics to scale ai data centers.npj Nanophotonics, 3(1):8, 2026
2026
-
[30]
Dynamic Hierarchical Birkhoff-von Neu- mann Decomposition for All-to-All GPU Communication, 2026
Yen-Chieh Wu, Cheng-Shang Chang, Duan-Shin Lee, and H Jonathan Chao. Dynamic Hierarchical Birkhoff-von Neu- mann Decomposition for All-to-All GPU Communication, 2026. URL: https://arxiv.org/abs/2602.22756
-
[31]
Actina: Adapting circuit-switching techniques for ai networking architectures
Zhenguo Wu, Benjamin Klenk, Larry Dennison, and Keren Bergman. Actina: Adapting circuit-switching techniques for ai networking architectures. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, SC ’25, page 1211–1222, New York, NY, USA, 2025. Association for Computing Machinery.doi:10.1145/371228...
-
[32]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
Mixture-of-Experts with Expert Choice Routing
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Zhao, Andrew M Dai, zhifeng Chen, Quoc V Le, and James Laudon. Mixture-of-Experts with Expert Choice Routing. In S Koyejo, S Mohamed, A Agarwal, D Belgrave, K Cho, and A Oh, editors,Advances in Neural Information Processing Sys- tems, volume 35, pages 7103–7114. Curran Associates, Inc., 2022...
2022
-
[34]
Resiliency at scale: Managing Google’s TPUv4 machine learning supercomputer
Yazhou Zu, Alireza Ghaffarkhah, Hoang-Vu Dang, Brian Towles, Steven Hand, Safeen Huda, Adekunle Bello, Alexander Kolbasov, Arash Rezaei, Dayou Du, Steve Lacy, Hang Wang, Aaron Wisner, Chris Lewis, and Henri Bahini. Resiliency at scale: Managing Google’s TPUv4 machine learning supercomputer. In21st USENIX Symposium on Networked Systems Design and Implement...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.