Revisiting Bruck: Phase-Efficient All-to-All Communication in Reconfigurable Networks
Pith reviewed 2026-06-29 15:46 UTC · model grok-4.3
The pith
ReTri finishes All-to-All in ceiling of log base 3 of n phases by co-designing the schedule with network reconfigurations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
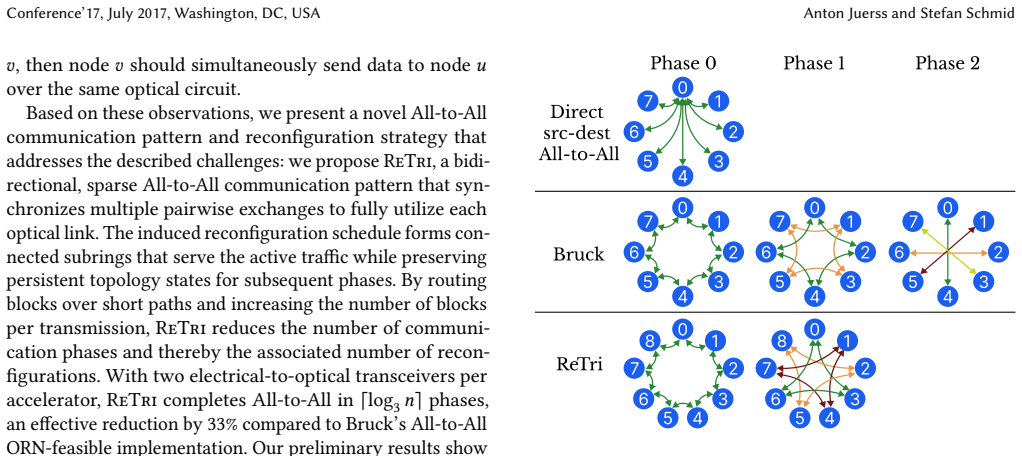
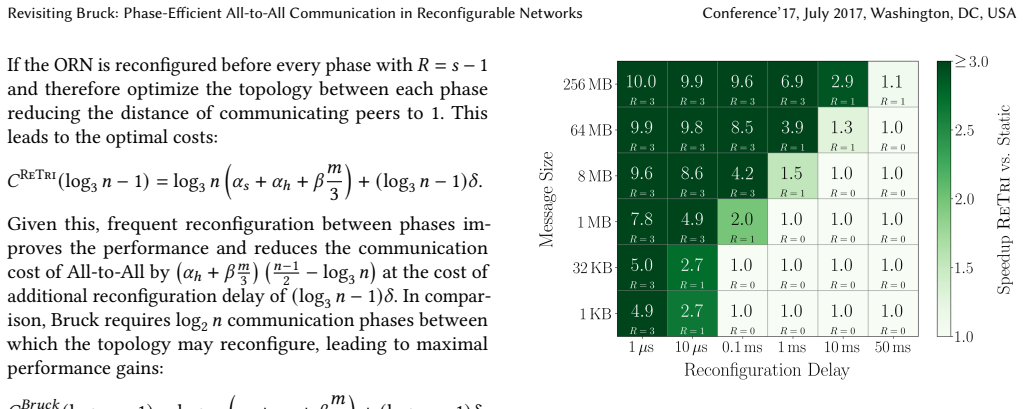
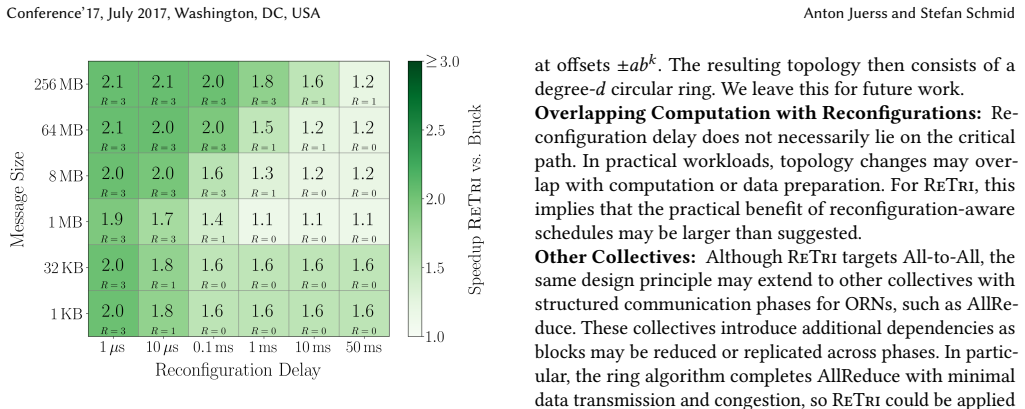
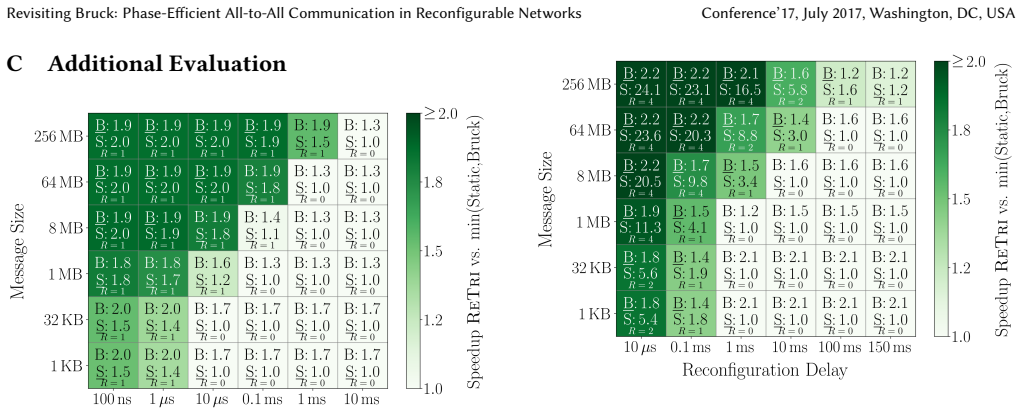
ReTri is a bidirectional All-to-All schedule for ORNs. ReTri uses balanced ternary block propagation to complete All-to-All in ceiling of log base 3 of n phases. The induced reconfiguration strategy from ReTri's pairwise bidirectional exchanges allows reconfiguration delays to be amortized across multiple phases. Preliminary simulations show that ReTri improves completion time by up to 10 times over static All-to-All, even for millisecond-scale reconfiguration delays, and improves reconfigurable Bruck by up to 2.1 times.
What carries the argument
balanced ternary block propagation, which divides the All-to-All pattern into phases whose topology states can be reused to amortize reconfiguration time
If this is right
- All-to-All communication requires only ceiling of log base 3 of n phases instead of more phases required by prior schedules.
- Reconfiguration delays are distributed across the phases rather than paid fully in each one.
- Completion time improves by up to 10 times compared with static networks even when reconfigurations take milliseconds.
- ReTri outperforms a reconfigurable adaptation of the Bruck algorithm by up to 2.1 times.
Where Pith is reading between the lines
- The same amortization logic could be tested on other collective patterns that also admit sparse reusable topology sequences.
- Hardware experiments that vary the number of nodes and the exact reconfiguration latency would show how the log base 3 scaling behaves at larger sizes.
- If the structured-phase assumption holds for real ML training loops, the method could reduce the communication fraction of end-to-end training time.
Load-bearing premise
The communication pattern must consist of structured phases that can be served by sparse and reusable topology states.
What would settle it
A measurement on an optical reconfigurable network showing that the total time for ReTri exceeds the time for static All-to-All when reconfiguration delay reaches one millisecond.
Figures
read the original abstract
All-to-All communication is a key performance bottleneck for distributed machine learning (ML) and high-performance computing (HPC) workloads, where dense traffic increasingly stresses scale-up interconnects. While these ML and HPC workloads have driven unprecedented infrastructure demand, optical reconfigurable networks (ORNs) offer a promising path forward. By adapting the physical topology to the active workload, they improve communication cost and bandwidth utilization. However, their benefit is critically contingent on whether the collective consists of structured phases that can be served by sparse and reusable topology states. In this paper, we revisit Bruck's All-to-All implementation and demonstrate the benefits of topology optimization in which both communication pattern and reconfiguration strategy are co-designed. We present ReTri, a bidirectional All-to-All schedule for ORNs. ReTri uses balanced ternary block propagation to complete All-to-All in $\lceil \log_3 n\rceil$ phases. The induced reconfiguration strategy from ReTri's pairwise bidirectional exchanges allow reconfiguration delays to be amortized across multiple phases. Preliminary simulations show that ReTri improves completion time by up to $10\times$ over static All-to-All, even for millisecond-scale reconfiguration delays, and improving reconfigurable Bruck by up to $2.1\times$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ReTri, a co-designed bidirectional All-to-All schedule for optical reconfigurable networks (ORNs). It employs balanced ternary block propagation to complete the collective in ⌈log₃ n⌉ phases while inducing a reconfiguration schedule whose delays are amortized across pairwise exchanges. Preliminary simulations report up to 10× improvement in completion time versus static All-to-All (even at millisecond reconfiguration delays) and up to 2.1× versus reconfigurable Bruck.
Significance. If the algorithmic claims and performance numbers hold under rigorous evaluation, the work would be a useful contribution to collective communication in reconfigurable networks. The explicit derivation of a ⌈log₃ n⌉ phase bound from balanced ternary structure, together with the amortization argument, provides a clean, parameter-free algorithmic result that directly addresses the precondition that ORN benefits require structured, reusable topology states. The co-design of schedule and reconfiguration is a strength.
major comments (1)
- [§5 (Evaluation)] §5 (Evaluation): the reported speedups (10× vs. static, 2.1× vs. reconfigurable Bruck) rest on preliminary simulations. No error bars, dataset sizes, network parameters, or full methodology are described, rendering the quantitative claims unverifiable and load-bearing for the practical significance asserted in the abstract and conclusion.
minor comments (2)
- [Abstract, §3] Abstract and §3: the phrase “the induced reconfiguration strategy from ReTri’s pairwise bidirectional exchanges allow reconfiguration delays to be amortized” contains a subject-verb agreement error (“allow” should be “allows”).
- [§3] §3: the precise mapping from balanced ternary digits to the bidirectional exchange pattern and the resulting topology states should be illustrated with a small-n example (e.g., n=9) to make the amortization argument concrete.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment. We agree that the evaluation in §5 is described at a preliminary level and requires expansion to support the quantitative claims. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [§5 (Evaluation)] §5 (Evaluation): the reported speedups (10× vs. static, 2.1× vs. reconfigurable Bruck) rest on preliminary simulations. No error bars, dataset sizes, network parameters, or full methodology are described, rendering the quantitative claims unverifiable and load-bearing for the practical significance asserted in the abstract and conclusion.
Authors: We agree that the simulation details are insufficiently specified. In the revised version we will expand §5 with: (i) explicit network parameters (node counts, link bandwidths, reconfiguration delay values tested), (ii) number of independent runs and input sizes, (iii) error bars or confidence intervals on all reported speedups, and (iv) a complete methodology subsection describing the simulator, traffic generation, and measurement procedure. These additions will make the 10× and 2.1× figures verifiable while preserving the preliminary nature of the results. revision: yes
Circularity Check
No significant circularity identified
full rationale
The derivation of the ⌈log₃ n⌉ phase bound follows directly from the balanced ternary block propagation and bidirectional pairwise exchanges in the ReTri schedule, which is a standard consequence of each phase expanding reach by a factor of three; this is not obtained by fitting or self-definition. Reconfiguration amortization is presented as a consequence of the induced topology states being reusable across phases, without reducing to a fitted parameter renamed as prediction. All performance numbers are explicitly labeled preliminary simulations. No load-bearing step relies on self-citation chains, uniqueness theorems imported from the authors' prior work, or ansatzes smuggled via citation; the central claims remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The collective consists of structured phases that can be served by sparse and reusable topology states.
Reference graph
Works this paper leans on
-
[1]
[n. d.]. ns-3 Network Simulator. https://www.nsnam.org/. Accessed: 2026-03-26
2026
-
[2]
Vamsi Addanki. 2025. When Light Bends to the Collective Will: A The- ory and Vision for Adaptive Photonic Scale-up Domains. InProceedings of the 24th ACM Workshop on Hot Topics in Networks(UMD Campus, College Park, MD, USA)(HotNets ’25). Association for Computing Ma- chinery, New York, NY, USA, 326–334. doi:10.1145/3772356.3772395
-
[3]
Rukshani Athapathu and George Porter. 2025. Reconfigurability within Collective Communication Algorithms. InProceedings of the 2nd Work- shop on Networks for AI Computing(Coimbra, Portugal)(NAIC ’25). Association for Computing Machinery, New York, NY, USA, 43–49. doi:10.1145/3748273.3749203
-
[4]
Chen Avin and Stefan Schmid. 2019. Toward demand-aware network- ing: a theory for self-adjusting networks.SIGCOMM Comput. Commun. Rev.48, 5 (Jan. 2019), 31–40. doi:10.1145/3310165.3310170
-
[5]
Jehoshua Bruck, Ching-Tien Ho, Shlomo Kipnis, and Derrick Weath- ersby. 1994. Efficient algorithms for all-to-all communications in multi- port message-passing systems(SPAA ’94). doi:10.1145/181014.181756
-
[6]
CALIENT Technologies, Inc. 2022. Calient’s Optical Circuit Switch (S-Series) Datasheet. https://www.calient.net/wp-content/uploads/ 2022/06/Datasheet_Calients-Optical-Circuit-Switches.pdf Accessed: 2025-07-03
2022
-
[7]
Eric Ding, Chuhan Ouyang, and Rachee Singh. 2025. Photonic Rails in ML Datacenters(HotNets ’25). Association for Computing Machinery, New York, NY, USA, 149–159. doi:10.1145/3772356.3772414
-
[8]
Nathan Farrington, Alex Forencich, George Porter, P.-C. Sun, Joseph E. Ford, Yeshaiahu Fainman, George C. Papen, and Amin Vahdat. 2013. A Multiport Microsecond Optical Circuit Switch for Data Center Net- working.IEEE Photonics Technology Letters25, 16 (2013), 1589–1592. doi:10.1109/LPT.2013.2270462
-
[9]
Nathan Farrington, George Porter, Sivasankar Radhakrishnan, Hamid Hajabdolali Bazzaz, Vikram Subramanya, Yeshaiahu Fainman, George Papen, and Amin Vahdat. 2010. Helios: a hybrid electri- cal/optical switch architecture for modular data centers.SIGCOMM Comput. Commun. Rev.40, 4 (Aug. 2010), 339–350. doi:10.1145/1851275. 1851223
-
[10]
Monia Ghobadi, Ratul Mahajan, Amar Phanishayee, Nikhil Devanur, Ja- nardhan Kulkarni, Gireeja Ranade, Pierre-Alexandre Blanche, Houman Rastegarfar, Madeleine Glick, and Daniel Kilper. 2016. ProjecToR: Agile Reconfigurable Data Center Interconnect. InProceedings of the 2016 ACM SIGCOMM Conference(Florianopolis, Brazil)(SIGCOMM ’16). As- sociation for Compu...
-
[11]
Norm Jouppi, George Kurian, Sheng Li, et al. 2023. TPU v4: An Opti- cally Reconfigurable Supercomputer for Machine Learning with Hard- ware Support for Embeddings(ISCA ’23). Association for Computing Machinery, New York, NY, USA, Article 82, 14 pages. doi:10.1145/ 3579371.3589350
- [12]
-
[13]
Anton Juerss and Stefan Schmid. 2026. Bridge: Optimizing Collective Communication Schedules in Reconfigurable Networks with Reusable Subrings. arXiv:2605.12766 [cs.NI] https://arxiv.org/abs/2605.12766
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Mehrdad Khani, Manya Ghobadi, Mohammad Alizadeh, et al . 2021. SiP-ML: high-bandwidth optical network interconnects for machine learning training(SIGCOMM ’21). Association for Computing Machin- ery, New York, NY, USA, 657–675. doi:10.1145/3452296.3472900
-
[15]
Abhishek Vijaya Kumar, Arjun Devraj, Darius Bunandar, and Rachee Singh. 2024. A case for server-scale photonic connectivity(HotNets ’24). Association for Computing Machinery, New York, NY, USA, 290–299. doi:10.1145/3696348.3696856
-
[16]
Xudong Liao, Yijun Sun, Han Tian, Xinchen Wan, et al. 2025. MixNet: A Runtime Reconfigurable Optical-Electrical Fabric for Distributed Mixture-of-Experts Training. InProceedings of the ACM SIGCOMM 2025 Conference (SIGCOMM ’25). Association for Computing Machinery, New York, NY, USA, 554–574. doi:10.1145/3718958.3750465
-
[17]
Mellette, Rob McGuinness, Arjun Roy, Alex Forencich, George Papen, Alex C
William M. Mellette, Rob McGuinness, Arjun Roy, Alex Forencich, George Papen, Alex C. Snoeren, and George Porter. 2017. Rotor- Net: A Scalable, Low-complexity, Optical Datacenter Network. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication(Los Angeles, CA, USA)(SIGCOMM ’17). As- sociation for Computing Machinery, New Y...
-
[18]
Polatis (a HUBER+SUHNER company). n.d.. Series 7000 — 384×384- port Software-Defined Optical Circuit Switch. https://www.polatis. com/ Accessed: 2025-07-01
2025
-
[19]
George Porter, Richard Strong, Nathan Farrington, Alex Forencich, Pang Chen-Sun, Tajana Rosing, Yeshaiahu Fainman, George Papen, and Amin Vahdat. 2013. Integrating microsecond circuit switching into the data center.SIGCOMM Comput. Commun. Rev.43, 4 (Aug. 2013), 447–458. doi:10.1145/2534169.2486007
-
[20]
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, et al . 2024. Alibaba HPN: A Data Center Network for Large Language Model Training (ACM SIGCOMM ’24). Association for Computing Machinery, New York, NY, USA, 691–706. doi:10.1145/3651890.3672265
-
[21]
Le Qin, Junwei Cui, Weilin Cai, Meng Niu, Yan Yang, and Jiayi Huang
-
[22]
InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO ’25)
Optimizing All-to-All Collective Communication with Fault Tolerance on Torus Networks. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO ’25). Association for Computing Machinery, New York, NY, USA, 659–674. doi:10.1145/ 3725843.3756057 Conference’17, July 2017, Washington, DC, USA Anton Juerss and Stefan Schmid
- [23]
-
[24]
Paul Sack and William Gropp. 2015. Collective Algorithms for Multi- ported Torus Networks.ACM Trans. Parallel Comput.1, 2, Article 12 (Feb. 2015), 33 pages. doi:10.1145/2686882
-
[25]
Daniele De Sensi, Tommaso Bonato, David Saam, and Torsten Hoefler
-
[26]
In 21st USENIX Symposium on Networked Systems Design and Implemen- tation (NSDI 24)
Swing: Short-cutting Rings for Higher Bandwidth Allreduce. In 21st USENIX Symposium on Networked Systems Design and Implemen- tation (NSDI 24). USENIX Association, 1445–1462
-
[27]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. TACCL: Guiding Collective Algorithm Synthe- sis using Communication Sketches. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). USENIX Association, 593–612
2023
-
[28]
Rajeev Thakur, Rolf Rabenseifner, and William Gropp. 2005. Optimiza- tion of Collective Communication Operations in MPICH.IJHPCA19 (01 2005), 49–66
2005
-
[29]
Weiyang Wang, Moein Khazraee, Zhizhen Zhong, Manya Ghobadi, Zhi- hao Jia, Dheevatsa Mudigere, Ying Zhang, and Anthony Kewitsch. 2023. TopoOpt: Co-optimizing Network Topology and Parallelization Strat- egy for Distributed Training Jobs. USENIX Association, Boston, MA, 739–767. https://www.usenix.org/conference/nsdi23/presentation/ wang-weiyang
2023
-
[30]
William Won, Taekyung Heo, Saeed Rashidi, Srinivas Sridharan, Sudar- shan Srinivasan, and Tushar Krishna. 2023. ASTRA-sim2.0: Modeling Hierarchical Networks and Disaggregated Systems for Large-model Training at Scale. 283–294. doi:10.1109/ISPASS57527.2023.00035 A Proof of Minimal Subrings forReTri Lemma 1.For phase 𝑘, the subrings 𝑆 (𝑘) 𝑖 are minimal unde...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.