Extreme-Scale Interconnection Networks
Pith reviewed 2026-07-01 15:57 UTC · model grok-4.3
The pith
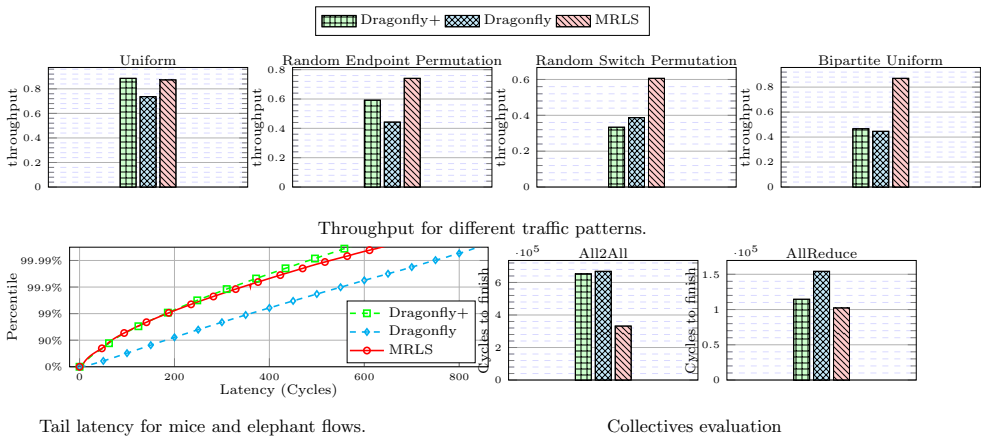
Multipass Random Leaf-Spine networks deliver up to 100 percent faster All2All collectives than Dragonfly or Fat-Tree at 100,000 endpoints.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
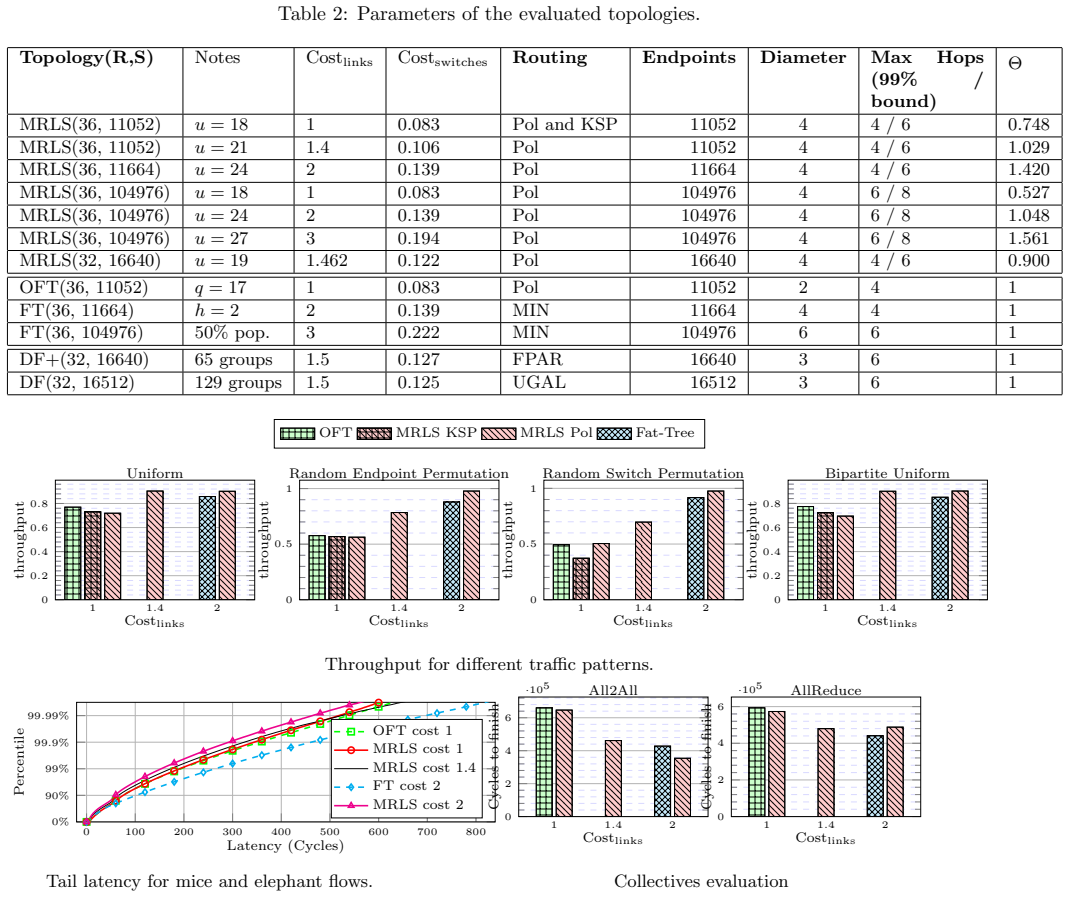
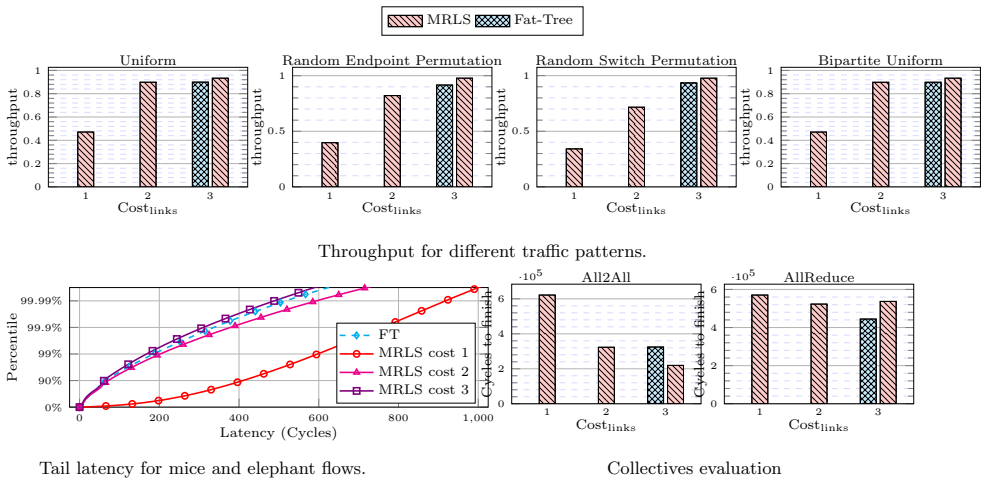
MRLS topologies inherit the scalability advantages of their source constructions while exceeding Fat-Tree throughput and routing flexibility when paired with non-minimal paths; exhaustive simulator runs establish a 50 percent reduction in All2All completion time against Fat-Tree and a 100 percent reduction against Dragonfly for a 100,000-endpoint collective.
What carries the argument
The Multipass Random Leaf-Spine topology together with non-minimal routing strategies that exploit multiple passes through the leaf and spine layers.
If this is right
- Extreme-scale systems can reach higher endpoint counts without proportional increases in switch radix or cabling cost.
- Collective operations that dominate AI training and scientific simulation workloads complete in substantially less time under the same traffic load.
- Routing flexibility increases because non-minimal paths become viable without sacrificing overall network capacity.
- Designers gain additional topology choices that trade minimal path length for reduced congestion on common traffic patterns.
Where Pith is reading between the lines
- If the simulator results translate to hardware, MRLS could reduce the number of network tiers needed for a given scale, lowering both power and failure rates.
- The same non-minimal routing approach might be applied to other folded-Clos variants to test whether the observed gains are specific to the random-leaf construction.
- At scales beyond 100k endpoints the relative advantage may grow or shrink depending on how congestion scales with diameter; targeted larger simulations would clarify the trend.
Load-bearing premise
The interconnection network simulator accurately reproduces the latency, throughput, and congestion behavior that the proposed topologies would exhibit on real extreme-scale hardware.
What would settle it
Execution of the same 100,000-endpoint All2All collective on physical switches wired according to an MRLS layout versus an equivalent Fat-Tree, with direct measurement of completion time.
Figures



read the original abstract
Extreme-scale data centers are the backbone of next-generation computing, enabling breakthroughs in science, artificial intelligence, and global innovation through unprecedented processing power and scalability. This work examines leaf-spine network topologies that offer extreme scalability--connecting a vast number of endpoints--while delivering strong performance at low cost. It takes as a starting point two alternatives to the widely used Fat-Tree topology: the Orthogonal Fat-Tree and the Random Folded Clos. The resulting Multipass Random Leaf-Spine (MRLS) networks inherit their advantages and surpass Fat-Trees in both throughput and flexibility. To fully leverage the topological properties of these networks, various non-minimal routing strategies are considered. An exhaustive evaluation using an interconnection network simulator provides insight into the trade-offs and scalability of these topologies under realistic conditions, positioning them as a promising solution for extreme-scale systems. The MRLS achieves a 50% speedup against a Fat-Tree for an All2All collective comprising 100k endpoints, and 100% against Dragonfly networks for the same collective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Multipass Random Leaf-Spine (MRLS) networks, extending Orthogonal Fat-Tree and Random Folded Clos designs, as scalable, low-cost alternatives to Fat-Tree topologies for extreme-scale data centers. It examines non-minimal routing strategies and reports, via exhaustive interconnection-network simulation, a 50% speedup over Fat-Tree and 100% over Dragonfly for All2All collectives at 100k endpoints.
Significance. If the simulation results prove reliable, MRLS could supply a flexible, high-throughput topology option for next-generation interconnects. The work's emphasis on scalability and routing trade-offs addresses a practical need in large-scale systems, though the absence of validation details weakens the evidential basis for the reported gains.
major comments (1)
- [Abstract / Evaluation] Abstract and evaluation description: The central performance claims (50% speedup vs. Fat-Tree, 100% vs. Dragonfly for 100k-endpoint All2All) are presented solely as outcomes of an interconnection-network simulator without any reference to calibration against hardware, cross-validation, modeled latency/congestion accuracy at scale, traffic-pattern specifics, or error bars. This directly undermines the load-bearing claim of topological superiority, as the deltas could be simulator artifacts.
Simulated Author's Rebuttal
We thank the referee for their careful review and constructive feedback. We address the major comment point-by-point below and will revise the manuscript to improve clarity on the evaluation methodology.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: The central performance claims (50% speedup vs. Fat-Tree, 100% vs. Dragonfly for 100k-endpoint All2All) are presented solely as outcomes of an interconnection-network simulator without any reference to calibration against hardware, cross-validation, modeled latency/congestion accuracy at scale, traffic-pattern specifics, or error bars. This directly undermines the load-bearing claim of topological superiority, as the deltas could be simulator artifacts.
Authors: We acknowledge that the abstract and evaluation description emphasize the simulation outcomes without sufficient methodological detail. The manuscript evaluates MRLS using a standard interconnection-network simulator under All2All traffic at 100k endpoints, as described in the full evaluation section. To strengthen the evidential basis, we will revise the abstract and add an expanded subsection on the simulator. This will include: references to prior literature validating the simulator's latency and congestion models at scale; explicit traffic-pattern parameters for the All2All collective; and results with error bars from multiple independent runs. Direct hardware calibration at this scale is not feasible, as no 100k-endpoint systems of this type exist for testing, which is why simulation is the established method in the field for extreme-scale topology studies. These additions will clarify that the reported 50% and 100% gains are simulation-derived but rest on transparent, reproducible modeling choices rather than artifacts. revision: yes
Circularity Check
No circularity: performance claims are direct simulator outputs
full rationale
The paper reports MRLS speedups (50% vs Fat-Tree, 100% vs Dragonfly) exclusively as outcomes of an interconnection-network simulator run at 100k endpoints. The abstract and reader's summary contain no equations, fitted parameters, self-citations used as load-bearing premises, or definitional reductions. No derivation chain reduces a claimed result to its own inputs by construction; the evaluation is presented as an independent empirical step.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Leaf-spine topologies can be scaled to extreme endpoint counts while preserving strong performance at low cost.
Reference graph
Works this paper leans on
-
[1]
An analysis and comparison of the development status of green data centers in China,
J. Lin, S. Hu, Z. Lu, and R. Deng, “An analysis and comparison of the development status of green data centers in China,” in2023 IEEE 8th Interna- tional Conference on Smart Cloud (SmartCloud), IEEE. IEEE Computer Society, 2023, pp. 130– 135
2023
-
[2]
Top 10 largest AI datacenters in 2026,
SemiAnalysis, “Top 10 largest AI datacenters in 2026,” https://www.youtube.com/watch?v= a-9egkpaZUw, Jan. 2026
2026
-
[3]
K. F. Pilz, J. Sanders, R. Rahman, and L. Heim, “Trends in AI supercomputers,”arXiv preprint arXiv:2504.16026, 2025
-
[4]
Top500: The list,
TOP500 Team, “Top500: The list,” https://www. top500.org/, 2025
2025
-
[5]
Technology-driven, highly-scalable dragonfly topology,
J. Kim, W. J. Dally, S. Scott, and D. Abts, “Technology-driven, highly-scalable dragonfly topology,” in2008 International Symposium on Computer Architecture. IEEE Computer Society, 2008, pp. 77–88
2008
-
[6]
Fault-tolerant orthogonal fat-trees as intercon- nection networks,
M. Valerio, L. Moser, and P. Melliar-Smith, “Fault-tolerant orthogonal fat-trees as intercon- nection networks,” inProceedings 1st Interna- tional Conference on Algorithms and Architec- tures for Parallel Processing, vol. 2, IEEE. IEEE Computer Society, 1995, pp. 749–754
1995
-
[7]
Cost-effective diameter-two topologies: analysis and evalua- tion,
G. Kathareios, C. Minkenberg, B. Prisacari, G. Rodriguez, and T. Hoefler, “Cost-effective diameter-two topologies: analysis and evalua- tion,” inSC ’15: Proceedings of the Interna- tional Conference for High Performance Comput- ing, Networking, Storage and Analysis. Associa- tion for Computing Machinery, 2015, pp. 1–11
2015
-
[8]
Random folded Clos topologies for datacenter networks,
C. Camarero, C. Mart´ ınez, and R. Beivide, “Random folded Clos topologies for datacenter networks,” in2017 IEEE International Sympo- sium on High Performance Computer Architecture (HPCA). IEEE Computer Society, 2017, pp. 193– 204
2017
-
[9]
Projective networks: Topologies for large parallel computer systems,
C. Camarero, C. Mart´ ınez, E. Vallejo, and R. Bei- vide, “Projective networks: Topologies for large parallel computer systems,”IEEE Transactions on Parallel and Distributed Systems, vol. 28, no. 7, pp. 2003–2016, 02 2017
2003
-
[10]
Slim Fly: A cost effec- tive low-diameter network topology,
M. Besta and T. Hoefler, “Slim Fly: A cost effec- tive low-diameter network topology,” inSC ’14: Proceedings of the International Conference for High Performance Computing, Networking, Stor- age and Analysis. IEEE Computer Society, 2014, pp. 348–359
2014
-
[11]
BCube: a high performance, server-centric network architecture for modular data centers,
C. Guo, G. Lu, D. Li, H. Wu, X. Zhang, Y. Shi, C. Tian, Y. Zhang, and S. Lu, “BCube: a high performance, server-centric network architecture for modular data centers,” inProceedings of the ACM SIGCOMM 2009 Conference on Data Communication, ser. SIGCOMM ’09. New York, NY, USA: Association for Computing Machinery, 2009, p. 63–74. [Online]. Available: https:...
-
[12]
Fat-trees: Universal networks for hardware-efficient supercomputing,
C. E. Leiserson, “Fat-trees: Universal networks for hardware-efficient supercomputing,”IEEE Trans- actions on Computers, vol. C-34, no. 10, pp. 892– 901, 1985
1985
-
[13]
A study of non-blocking switching networks,
C. Clos, “A study of non-blocking switching networks,”The Bell System Technical Journal, vol. 32, no. 2, pp. 406–424, 1953
1953
-
[14]
Communication requirements and interconnect optimization for high-end scientific applications,
S. Kamil, L. Oliker, A. Pinar, and J. Shalf, “Communication requirements and interconnect optimization for high-end scientific applications,” IEEE Transactions on Parallel and Distributed Systems, vol. 21, no. 2, pp. 188–202, Feb. 2010
2010
-
[15]
Characterizing parallel scien- tific applications on commodity clusters: An em- pirical study of a tapered fat-tree,
E. A. Le´ on, I. Karlin, A. Bhatele, S. H. Langer, C. Chambreau, L. H. Howell, T. D’Hooge, and M. L. Leininger, “Characterizing parallel scien- tific applications on commodity clusters: An em- pirical study of a tapered fat-tree,” inSC ’16: Proceedings of the International Conference for High Performance Computing, Networking, Stor- age and Analysis, Nov....
2016
-
[16]
Effective quality- of-service policy for capacity high-performance computing systems,
A. Jokanovic, J. C. Sancho, J. Labarta, G. Ro- driguez, and C. Minkenberg, “Effective quality- of-service policy for capacity high-performance computing systems,” in2012 IEEE 14th Interna- tional Conference on High Performance Comput- ing and Communication 2012 IEEE 9th Interna- tional Conference on Embedded Software and Sys- tems, Jun. 2012, pp. 598–607
2012
-
[17]
Reducing complexity in tree- like computer interconnection networks,
J. Navaridas, J. Miguel-Alonso, F. J. Ridruejo, and W. Denzel, “Reducing complexity in tree- like computer interconnection networks,”Parallel computing, vol. 36, no. 2-3, pp. 71–85, 2010
2010
-
[18]
High throughput data center topology design,
A. Singla, P. B. Godfrey, and A. Kolla, “High throughput data center topology design,” in11th USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 14). USENIX: The Advanced Computing Systems Association, 2014, pp. 29–41
2014
-
[19]
On Moore graphs with diameters 2 and 3,
A. J. Hoffman and R. R. Singleton, “On Moore graphs with diameters 2 and 3,”IBM Journal of Research and Development, vol. 4, no. 5, pp. 497– 504, 1960
1960
-
[20]
Principles and practices of interconnection network,
W. Dally and B. Towles, “Principles and practices of interconnection network,” 01 2004
2004
-
[21]
Minimal rewiring: Efficient live expansion for Clos data center networks,
S. Zhao, R. Wang, J. Zhou, J. Ong, J. C. Mogul, and A. Vahdat, “Minimal rewiring: Efficient live expansion for Clos data center networks,” in16th USENIX Symposium on Networked Systems De- sign and Implementation (NSDI 19). USENIX: 13 The Advanced Computing Systems Association, 2019, pp. 221–234
2019
-
[22]
Jellyfish: networking data centers randomly,
A. Singla, C.-Y. Hong, L. Popa, and P. B. Godfrey, “Jellyfish: networking data centers randomly,” in Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation, ser. NSDI’12. USA: USENIX Association, 2012, p. 17
2012
-
[23]
On random wiring in practicable folded Clos networks for modern datacenters,
C. Camarero, C. Martınez, and R. Beivide, “On random wiring in practicable folded Clos networks for modern datacenters,”IEEE Transactions on Parallel and Distributed Systems, vol. 29, no. 8, pp. 1780–1793, 2018
2018
-
[24]
Generating random regular graphs quickly,
A. Steger and N. C. Wormald, “Generating random regular graphs quickly,”Combinatorics, Probability and Computing, vol. 8, no. 04, pp. 377– 396, 1999
1999
-
[25]
Modelling standard and random- ized slimmed folded Clos networks,
C. Camarero, J. Corral, C. Mart´ ınez, and R. Beivide, “Modelling standard and random- ized slimmed folded Clos networks,” inEuro- pean Conference on Parallel Processing, Springer. Springer, 2020, pp. 185–199
2020
-
[26]
Bollob´ as,Random Graphs, 2nd ed
B. Bollob´ as,Random Graphs, 2nd ed. Cambridge studies in advanced mathematics, 2001
2001
-
[27]
Multi- path routing in the Jellyfish network,
Z. ALzaid, S. Bhowmik, and X. Yuan, “Multi- path routing in the Jellyfish network,” in2021 IEEE international parallel and distributed pro- cessing symposium workshops (IPDPSW), IEEE. IEEE Computer Society, 2021, pp. 832–841
2021
-
[28]
Po- larized routing: an efficient and versatile algo- rithm for large direct networks,
C. Camarero, C. Mart´ ınez, and R. Beivide, “Po- larized routing: an efficient and versatile algo- rithm for large direct networks,” in2021 IEEE Symposium on High-Performance Interconnects (HOTI). IEEE Computer Society, 2021, pp. 52– 59
2021
-
[29]
RNG: Flat Datacenter Networks at Scale
G. Bernardi, R. Mahajan, C. Seshadhri, E. Car- lesso, C. M. Joseph, S. Kumar, P. Manikonda, L. Popa, R. Ram, S. Robinson, and E. Tennent, “Expanding into reality: Random graphs for datacenter networks,”arXiv preprint arXiv:2604.15261, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
A scheme for fast parallel communication,
L. G. Valiant, “A scheme for fast parallel communication,”SIAM Journal on Computing, vol. 11, no. 2, pp. 350–361, 1982. [Online]. Available: https://doi.org/10.1137/0211027
-
[31]
The CAMINOS interconnection networks sim- ulator,
C. Camarero, D. Postigo, and P. Fuentes, “The CAMINOS interconnection networks sim- ulator,”Journal of Parallel and Distributed Computing, vol. 204, p. 105136, 2025. [On- line]. Available: https://www.sciencedirect.com/ science/article/pii/S0743731525001030
2025
-
[32]
Dragonfly+: Low cost topology for scaling datacenters,
A. Shpiner, Z. Haramaty, S. Eliad, V. Zdornov, B. Gafni, and E. Zahavi, “Dragonfly+: Low cost topology for scaling datacenters,” in2017 IEEE 3rd International Workshop on High-Performance Interconnection Networks in the Exascale and Big- Data Era (HiPINEB). IEEE, 2017, pp. 1–8
2017
-
[33]
Op- timization of collective communication operations in mpich,
R. Thakur, R. Rabenseifner, and W. Gropp, “Op- timization of collective communication operations in mpich,”The International Journal of High Per- formance Computing Applications, vol. 19, no. 1, pp. 49–66, 2005
2005
-
[34]
Beyond fat- trees without antennae, mirrors, and disco-balls,
S. Kassing, A. Valadarsky, G. Shahaf, M. Schapira, and A. Singla, “Beyond fat- trees without antennae, mirrors, and disco-balls,” inProceedings of the Conference of the ACM Special Interest Group on Data Communication, 2017, pp. 281–294
2017
-
[35]
Martingale approach to the coupon col- lection problem,
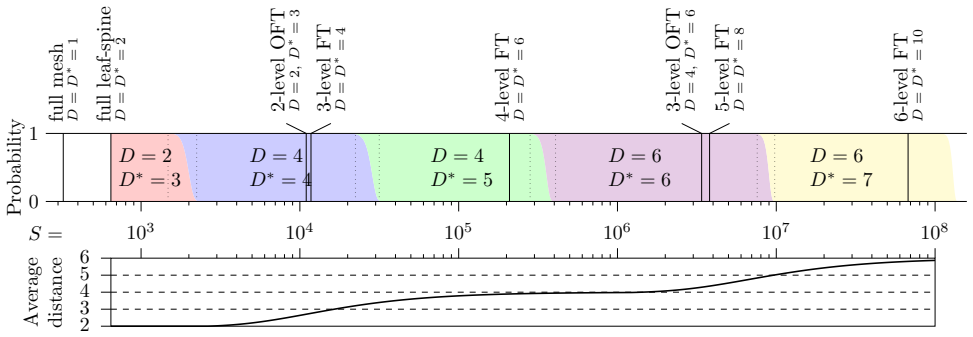
N. Kan, “Martingale approach to the coupon col- lection problem,”Journal of Mathematical Sci- ences, vol. 127, no. 1, pp. 1737–1744, 2005. A Average Distance and Proba- bilities This appendix explains the mathematical details be- hind the graphs shown in Figures 3 and 4. Most of Figure 3 can be estimated experimentally by generat- ing many networks near t...
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.