MuChator: Enabling Active Music Discovery via Conversational Music LLMs in Douyin Music
Pith reviewed 2026-06-29 15:38 UTC · model grok-4.3
The pith
MuChator lets users describe situational music needs in natural language to an LLM that has been pre-trained on music knowledge, tuned on synthesized query-song triplets, and aligned via hybrid preference rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
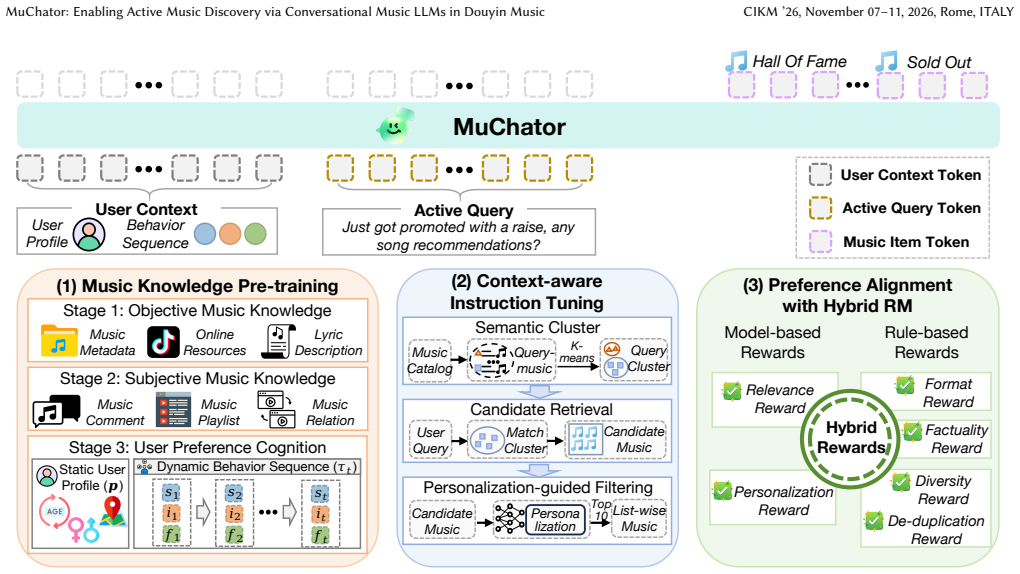
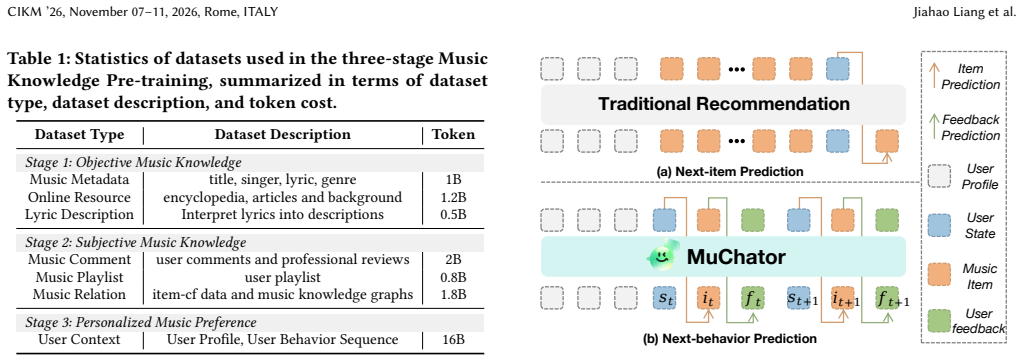
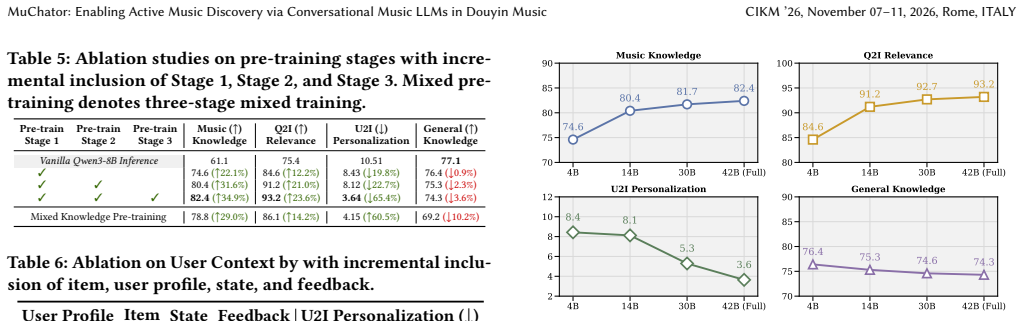
MuChator is an interactive MusicLLM-based framework with three components: Music Knowledge Pre-training that incrementally injects objective music knowledge, subjective music knowledge, and personalized preferences; Context-aware Instruction Tuning that uses an automated synthesis pipeline to build high-quality user-query-music triplets aligning the model with active and situational intents; and Preference Alignment with Hybrid RM that jointly models intent relevance, personalized preferences, and basic constraints before optimizing via GRPO-based reinforcement learning. The framework enables natural-language expression of music intents on feed-based platforms, outperforms proprietary models
What carries the argument
The three-component MuChator framework that pre-trains LLMs on layered music knowledge, synthesizes situational query-song triplets for instruction tuning, and applies GRPO reinforcement learning to a hybrid reward model combining relevance, preference, and constraint signals.
If this is right
- Users on large music platforms can move from passive scrolling to stating colloquial or situational requests and receive relevant song suggestions.
- Music-domain LLMs can incorporate collaborative reasoning about queries once objective facts, subjective attributes, and personal tastes are injected in stages.
- Automated triplet synthesis reduces reliance on manual annotation for training conversational recommenders.
- Hybrid reward modeling plus GRPO optimization produces outputs that jointly satisfy relevance, personalization, and platform constraints.
- The same pipeline yields measurable lifts in engagement metrics when deployed at scale.
Where Pith is reading between the lines
- The same staged knowledge injection and automated triplet construction could be tested in adjacent domains such as short-video or podcast recommendation where user intents are also situational.
- If the synthesis pipeline generalizes, platforms could bootstrap conversational interfaces with far less labeled data than current supervised methods require.
- Successful deployment implies that feed-based interfaces may evolve toward optional chat layers that capture intent without replacing the core recommendation engine.
Load-bearing premise
The automated synthesis pipeline produces high-quality user-query-music triplets that successfully align the LLM with active and situational user intents.
What would settle it
An online A/B test on Douyin Music showing no statistically significant rise in user active days after replacing the prior system with MuChator would falsify the deployment benefit claim.
Figures
read the original abstract
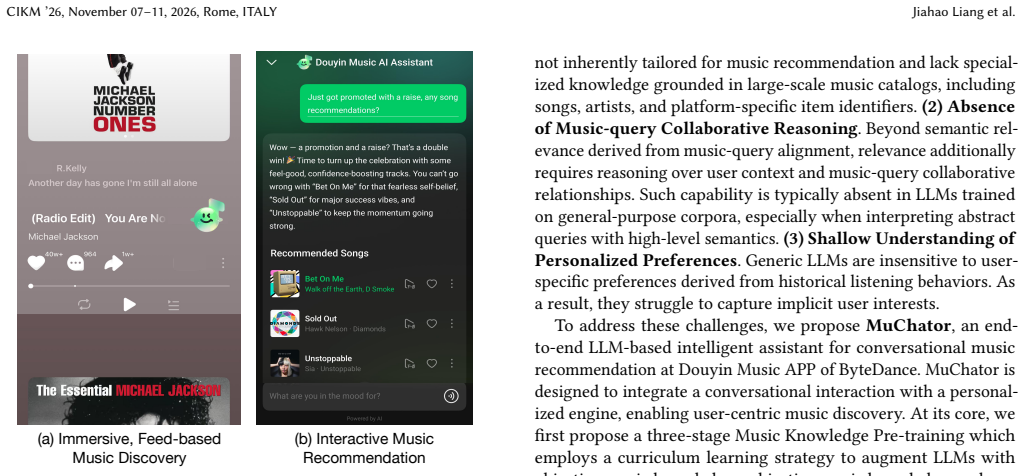
Douyin Music, a large-scale platform with millions of daily users, adopts an immersive, feed-based discovery paradigm, where users passively explore music through continuous recommendations. While effective for passive music discovery, this paradigm restricts users to recommendation results and provides limited support for explicitly specifying listening intents. Unlike conventional search, where users express well-defined intents through explicit queries such as specific songs or artists, real-world active music discovery is often situational and colloquial, involving vague or underspecified requests. While LLMs enable natural language interaction, their direct use in music discovery remains limited by insufficient music-domain knowledge, lack of music-query collaborative reasoning, and shallow understanding of personalized preferences. To address these challenges, we introduce MuChator, an interactive MusicLLM-based framework that enables users to actively express situational music intents in natural language. MuChator incorporates three key components: (1) Music Knowledge Pre-training, a three-stage scheme that incrementally injects objective music knowledge, subjective music knowledge, and personalized music preferences into LLMs; (2) Context-aware Instruction Tuning, which constructs high-quality user-query-music triplets through an automated synthesis pipeline to align LLMs with active and situational user intents; and (3) Preference Alignment with Hybrid RM, which jointly models intent relevance, personalized preferences, and basic constraints, and is optimized using GRPO-based reinforcement learning. Extensive evaluations on industrial music recommendation datasets demonstrate that MuChator outperforms leading proprietary models, such as Gemini-3-Pro. The model has been deployed on Douyin Music App within ByteDance, with 46.49\% improvement of user active days in online A/B test.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MuChator, an interactive MusicLLM framework for active music discovery on Douyin Music. It proposes three components: (1) Music Knowledge Pre-training to incrementally add objective, subjective, and personalized music knowledge; (2) Context-aware Instruction Tuning via an automated pipeline generating user-query-music triplets; and (3) Preference Alignment using a Hybrid RM optimized with GRPO reinforcement learning. The central claims are outperformance over Gemini-3-Pro on industrial datasets and a 46.49% lift in user active days from an online A/B test after deployment on the Douyin Music App.
Significance. If the empirical claims are substantiated with proper reporting, the work would demonstrate a practical path for adapting LLMs to situational, natural-language music intents in a large-scale industrial feed-based platform, with the deployment providing evidence of real-world applicability in shifting from passive to active discovery.
major comments (3)
- [Abstract] Abstract: the claim that MuChator 'outperforms leading proprietary models, such as Gemini-3-Pro' on 'industrial music recommendation datasets' is unsupported by any tables, numerical results, baselines, dataset sizes, ablation studies, or statistical tests. This is load-bearing for the evaluation component of the central contribution.
- [Abstract] Abstract: the headline result of '46.49% improvement of user active days in online A/B test' is presented without any information on randomization, control condition, cohort size, test duration, active-days definition, statistical tests, or checks for confounds. This prevents causal attribution to the three proposed components and is load-bearing for the deployment claim.
- [Abstract] Abstract (component 2): the automated synthesis pipeline for 'high-quality user-query-music triplets' is asserted to align the LLM with 'active and situational user intents,' yet no quality metrics, human validation, or ablation of the pipeline are supplied. This is load-bearing for the Context-aware Instruction Tuning contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in the abstract. We will revise the abstract and, where appropriate, the main text to include key supporting details from our experiments and deployment while preserving the paper's focus.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that MuChator 'outperforms leading proprietary models, such as Gemini-3-Pro' on 'industrial music recommendation datasets' is unsupported by any tables, numerical results, baselines, dataset sizes, ablation studies, or statistical tests. This is load-bearing for the evaluation component of the central contribution.
Authors: We agree the abstract claim would be stronger with explicit references. The Experiments section contains tables comparing MuChator against Gemini-3-Pro and other baselines on our industrial datasets, including dataset sizes, ablation results, and statistical significance. In revision we will update the abstract to cite the key numerical improvements and point readers to the relevant tables and sections. revision: yes
-
Referee: [Abstract] Abstract: the headline result of '46.49% improvement of user active days in online A/B test' is presented without any information on randomization, control condition, cohort size, test duration, active-days definition, statistical tests, or checks for confounds. This prevents causal attribution to the three proposed components and is load-bearing for the deployment claim.
Authors: We acknowledge that the abstract lacks sufficient A/B test metadata. The Deployment section reports the observed lift along with test duration and basic setup; we will revise the abstract to include cohort size, randomization method, active-days definition, and statistical significance while noting that full confound checks appear in the main text. revision: yes
-
Referee: [Abstract] Abstract (component 2): the automated synthesis pipeline for 'high-quality user-query-music triplets' is asserted to align the LLM with 'active and situational user intents,' yet no quality metrics, human validation, or ablation of the pipeline are supplied. This is load-bearing for the Context-aware Instruction Tuning contribution.
Authors: We agree that validation evidence for the triplet synthesis pipeline should be referenced. The Context-aware Instruction Tuning section describes the pipeline and includes human validation scores plus ablation studies on triplet quality. We will revise the abstract to briefly note these quality metrics and the human evaluation results. revision: yes
Circularity Check
No circularity: framework components and A/B result are independent of self-referential fits
full rationale
The paper presents MuChator as a three-component engineering system (Music Knowledge Pre-training, Context-aware Instruction Tuning via automated triplet synthesis, Preference Alignment with Hybrid RM + GRPO) whose outputs are validated on industrial datasets and reported via a separate online A/B deployment metric. No equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or component descriptions. The 46.49% active-days lift is stated as an external outcome rather than a quantity derived from the same synthesis or reward signals by construction. The derivation chain therefore remains self-contained and does not reduce to its inputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can absorb objective music facts, subjective opinions, and personalized preferences through incremental pre-training stages
- domain assumption An automated synthesis pipeline can generate training triplets that capture active and situational music intents
invented entities (1)
-
Hybrid RM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Guojia An, Jie Zou, Jiwei Wei, Chaoning Zhang, Fuming Sun, and Yang Yang. 2025. Beyond whole dialogue modeling: Contextual disentanglement for conversational recommendation. InSIGIR
2025
-
[2]
Qibin Chen, Junyang Lin, Yichang Zhang, Ming Ding, Yukuo Cen, Hongxia Yang, and Jie Tang. 2019. Towards knowledge-based recommender dialog system. In EMNLP
2019
-
[3]
Konstantina Christakopoulou, Filip Radlinski, and Katja Hofmann. 2016. Towards conversational recommender systems. InKDD
2016
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multi- modality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Sunhao Dai, Ninglu Shao, Haiyuan Zhao, Weijie Yu, Zihua Si, Chen Xu, Zhongx- iang Sun, Xiao Zhang, and Jun Xu. 2023. Uncovering chatgpt’s capabilities in recommender systems. InRecSys
2023
-
[6]
Huy Dao, Yang Deng, Dung D Le, and Lizi Liao. 2024. Broadening the view: Demonstration-augmented prompt learning for conversational recommendation. InSIGIR
2024
-
[7]
Yashar Deldjoo, Markus Schedl, and Peter Knees. 2024. Content-driven music recommendation: Evolution, state of the art, and challenges.Computer Science Review(2024)
2024
-
[8]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Seungheon Doh, Keunwoo Choi, and Juhan Nam. 2025. TALKPLAY: Multimodal Music Recommendation with Large Language Models. InNeurIPS Workshop
2025
-
[10]
Seungheon Doh, Keunwoo Choi, and Juhan Nam. 2025. Talkplay-tools: Conver- sational music recommendation with llm tool calling. InNeurIPS Workshop
2025
- [11]
-
[12]
Jianyu Guan, Zongming Yin, Tianyi Zhang, Leihui Chen, Yin Zhang, Fei Huang, Shuguang Han, and Jufeng Chen. 2025. Effective two-stage knowledge transfer for multi-entity cross-domain recommendation. InKDD
2025
-
[13]
Ming He, Wenbo Luo, Yongjie Zheng, Junkai Zhang, and Xiaolei Gao. 2025. EEG- FSL: An EEG-Based Few-Shot Learning Framework for Music Recommendation. InCIKM
2025
-
[14]
Zhankui He, Zhouhang Xie, Rahul Jha, Harald Steck, Dawen Liang, Yesu Feng, Bodhisattwa Prasad Majumder, Nathan Kallus, and Julian McAuley. 2023. Large language models as zero-shot conversational recommenders. InCIKM
2023
-
[15]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk
-
[16]
Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[17]
Xin Jin, Wu Zhou, Jinyu Wang, Duo Xu, and Yongsen Zheng. 2023. An Order- Complexity Aesthetic Assessment Model for Aesthetic-aware Music Recommen- dation. InACM MM
2023
-
[18]
Erkang Jing, Yezheng Liu, Yidong Chai, Shuo Yu, Longshun Liu, Yuanchun Jiang, and Yang Wang. 2025. Emotion-aware personalized music recommendation with a heterogeneity-aware deep bayesian network.TOIS(2025)
2025
-
[19]
Shijun Li, Wenqiang Lei, Qingyun Wu, Xiangnan He, Peng Jiang, and Tat-Seng Chua. 2021. Seamlessly unifying attributes and items: Conversational recommen- dation for cold-start users.TOIS(2021)
2021
-
[20]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Ning Liu, Yunsen Tang, Haitao Yuan, Hongtao Lv, Lili Jiang, Zhen Li, Wei Zhang, and Jianyong Wang. 2025. Incomplete Multi-View Drug Recommendation via Multi-Level Representation Learning and Curriculum Learning. InKDD
2025
-
[22]
Zhiyuan Liu, Wei Xu, Wenping Zhang, and Qiqi Jiang. 2023. An emotion-based personalized music recommendation framework for emotion improvement.In- formation Processing & Management(2023)
2023
-
[23]
Xingyu Lu, Jinpeng Wang, Jieming Zhu, Zhicheng Zhang, Deqing Zou, Hai-Tao Zheng, Shu-Tao Xia, and Rui Zhang. 2025. ROMA: Recommendation-Oriented Language Model Adaptation Using Multi-Modal Multi-Domain Item Sequences. InKDD
2025
-
[24]
Alessandro B Melchiorre, Elena V Epure, Shahed Masoudian, Gustavo Escobedo, Anna Hausberger, Manuel Moussallam, and Markus Schedl. 2025. Just ask for mu- sic (jam): Multimodal and personalized natural language music recommendation. InRecSys
2025
-
[25]
OpenAI. 2025. GPT-5. https://openai.com/zh-Hans-CN/index/introducing-gpt-5
2025
-
[26]
Sergio Oramas, Vito Claudio Ostuni, Tommaso Di Noia, Xavier Serra, and Euge- nio Di Sciascio. 2016. Sound and music recommendation with knowledge graphs. TIST(2016)
2016
-
[27]
Diego Sánchez-Moreno, Ana B Gil González, M Dolores Muñoz Vicente, Vivian F López Batista, and María N Moreno García. 2016. A collaborative filtering method for music recommendation using playing coefficients for artists and users.Expert Systems with Applications(2016)
2016
-
[28]
Markus Schedl, Hamed Zamani, Ching-Wei Chen, Yashar Deldjoo, and Mehdi Elahi. 2018. Current challenges and visions in music recommender systems research.IJMIR(2018)
2018
-
[29]
Elena Shakirova. 2017. Collaborative filtering for music recommender system. In EIConRus
2017
-
[30]
Rong Shan, Jianghao Lin, Chenxu Zhu, Bo Chen, Menghui Zhu, Kangning Zhang, Jieming Zhu, Ruiming Tang, Yong Yu, and Weinan Zhang. 2025. An automatic graph construction framework based on large language models for recommenda- tion. InKDD
2025
-
[31]
Tiancheng Shen, Jia Jia, Yan Li, Yihui Ma, Yaohua Bu, Hanjie Wang, Bo Chen, Tat-Seng Chua, and Wendy Hall. 2020. Peia: Personality and emotion integrated attentive model for music recommendation on social media platforms. InAAAI
2020
-
[32]
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang
-
[33]
BERT4Rec: Sequential recommendation with bidirectional encoder repre- sentations from transformer. InCIKM
-
[34]
Kai Tian, Yirong Mao, Wendong Bi, Hanjie Wang, and Que Wenhui. 2025. MuCPT: Music-related Natural Language Model Continued Pretraining. InNeurIPS Work- shop
2025
-
[35]
Aaron Van den Oord, Sander Dieleman, and Benjamin Schrauwen. 2013. Deep content-based music recommendation. InNeurIPS
2013
-
[36]
Dongjing Wang, Xin Zhang, Yao Wan, Dongjin Yu, Guandong Xu, and Shuiguang Deng. 2021. Modeling sequential listening behaviors with attentive temporal point process for next and next new music recommendation.TMM(2021)
2021
-
[37]
Dongjing Wang, Xin Zhang, Yuyu Yin, Dongjin Yu, Guandong Xu, and Shuiguang Deng. 2023. Multi-view enhanced graph attention network for session-based music recommendation.TOIS(2023)
2023
-
[38]
Dongjing Wang, Xin Zhang, Dongjin Yu, Guandong Xu, and Shuiguang Deng
-
[39]
TNNLS(2020)
CAME: Content-and context-aware music embedding for recommendation. TNNLS(2020)
2020
-
[40]
Shijia Wang, Tianpei Ouyang, Yunfan Zhou, Qiang Xiao, Yintao Ren, Yifei Pan, Fangjian Li, and Chuanjiang Luo. 2025. Enhanced Emotion-aware Music Recom- mendation via Large Language Models. InKDD
2025
-
[41]
Xinxi Wang and Ye Wang. 2014. Improving content-based and hybrid music recommendation using deep learning. InACM MM
2014
-
[42]
Xiaolei Wang, Kun Zhou, Ji-Rong Wen, and Wayne Xin Zhao. 2022. Towards unified conversational recommender systems via knowledge-enhanced prompt learning. InKDD
2022
-
[43]
Yunjia Xi, Muyan Weng, Wen Chen, Chao Yi, Dian Chen, Gaoyang Guo, Mao Zhang, Jian Wu, Yuning Jiang, Qingwen Liu, et al. 2025. Bursting filter bubble: Enhancing serendipity recommendations with aligned large language models. In KDD
2025
-
[44]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Zhenye Yang, Jinpeng Chen, Huan Li, Xiongnan Jin, Xuanyang Li, Junwei Zhang, Hongbo Gao, Kaimin Wei, and Senzhang Wang. 2025. STEP: Stepwise Curriculum Learning for Context-Knowledge Fusion in Conversational Recommendation. In CIKM
2025
-
[46]
Junjie Zhang, Ruobing Xie, Yupeng Hou, Xin Zhao, Leyu Lin, and Ji-Rong Wen
-
[47]
Recommendation as instruction following: A large language model em- powered recommendation approach.TOIS(2025)
2025
-
[48]
Kun Zhou, Wayne Xin Zhao, Shuqing Bian, Yuanhang Zhou, Ji-Rong Wen, and Jingsong Yu. 2020. Improving conversational recommender systems via knowl- edge graph based semantic fusion. InKDD
2020
-
[49]
Yongchun Zhu, Jingwu Chen, Ling Chen, Yitan Li, Feng Zhang, and Zuotao Liu
-
[50]
Interest clock: Time perception in real-time streaming recommendation system. InSIGIR
-
[51]
Yongchun Zhu, Guanyu Jiang, Jingwu Chen, Feng Zhang, Qi Wu, and Zuotao Liu. 2025. Long-Term Interest Clock: Fine-Grained Time Perception in Streaming Recommendation System. InWWW
2025
-
[52]
Yaochen Zhu, Chao Wan, Harald Steck, Dawen Liang, Yesu Feng, Nathan Kallus, and Jundong Li. 2025. Collaborative Retrieval for Large Language Model-based Conversational Recommender Systems. InWWW
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.