Lost in the Evidence? Reproducing Document Position and Context Size Effects in RAG
Pith reviewed 2026-06-29 15:35 UTC · model grok-4.3
The pith
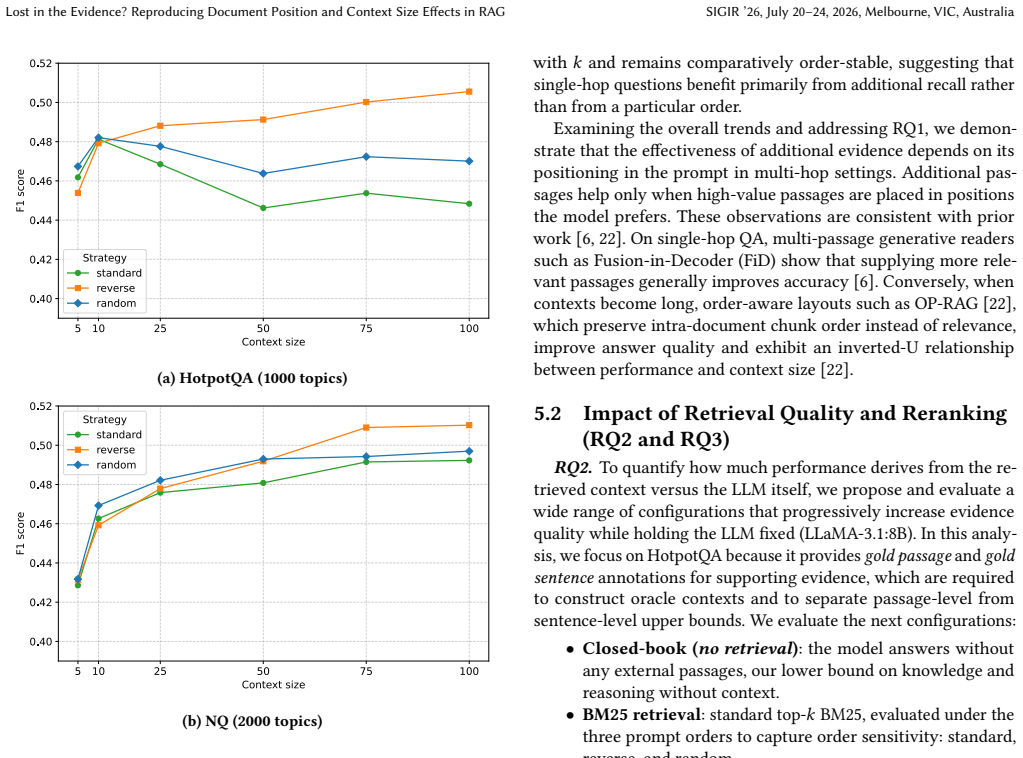
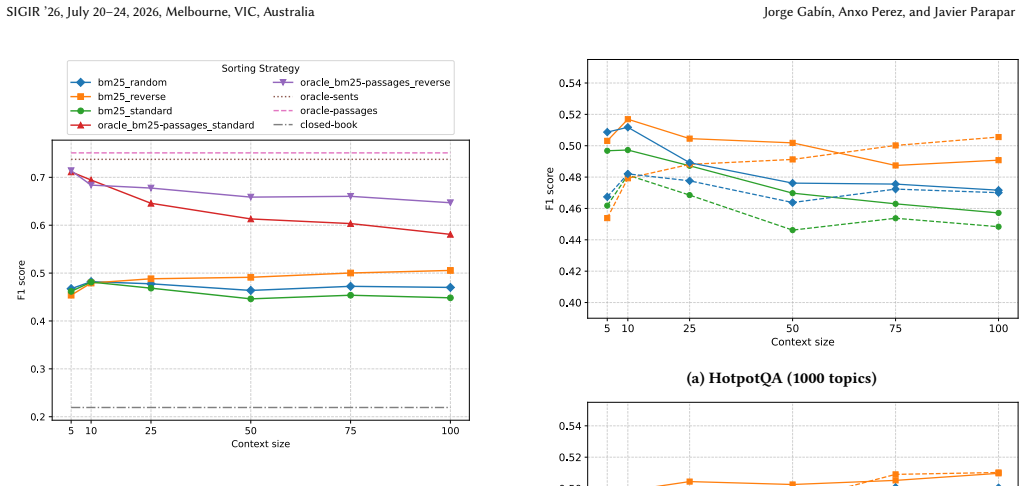
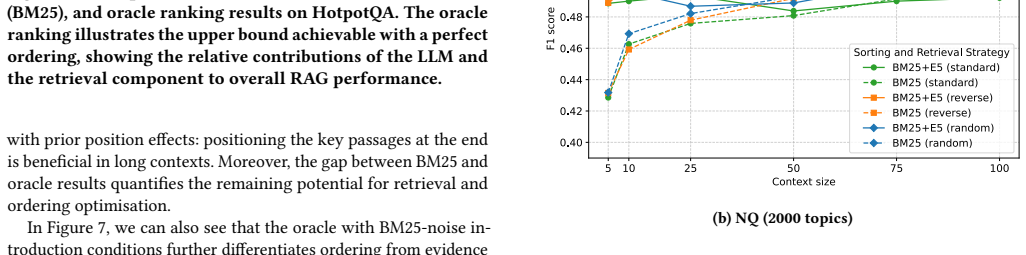
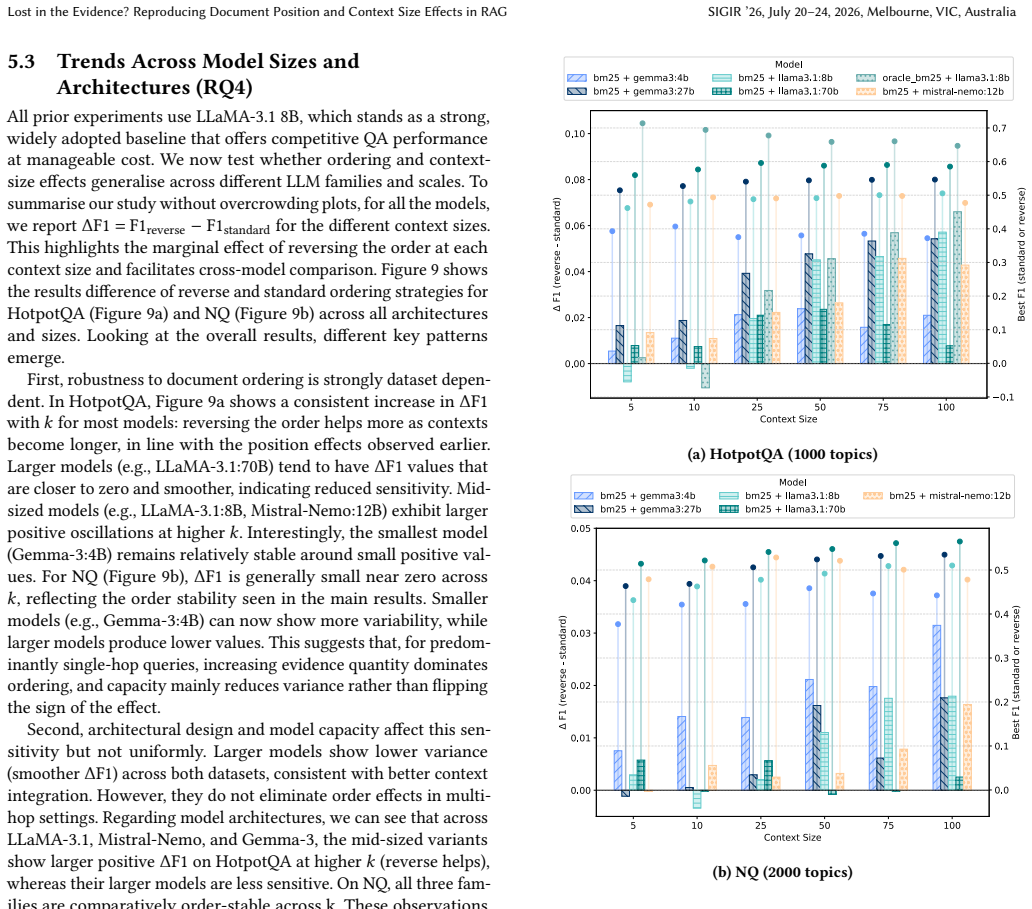
Document position and context size effects in RAG interact strongly with retrieval quality and model choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
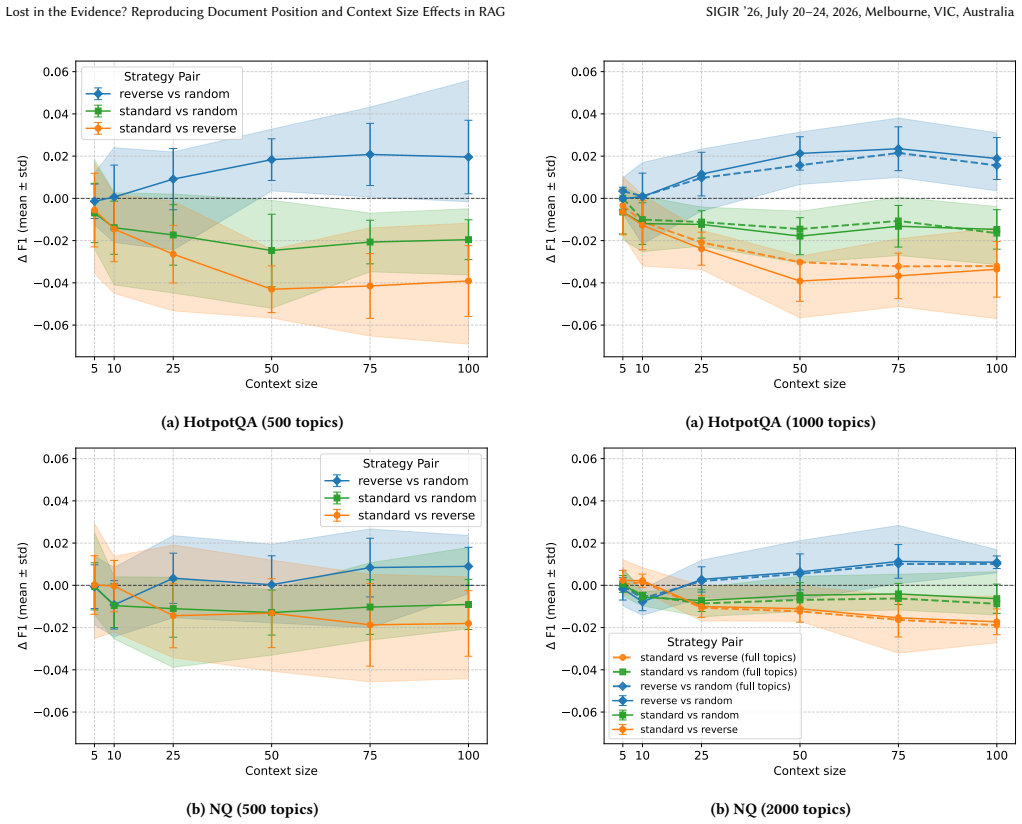
The authors establish that both document position and context size interact strongly with retrieval quality and model choice. Conclusions reached in idealized oracle-access experiments therefore do not transfer to realistic RAG pipelines in which relevance is supplied by an actual retriever. The work supplies a practical calibration procedure, based on repeated subset sampling across topic budgets, that yields stable evaluation trends at manageable cost, and it documents specific discrepancies with earlier industry findings that trace to limited topic coverage and reliance on LLM judges.
What carries the argument
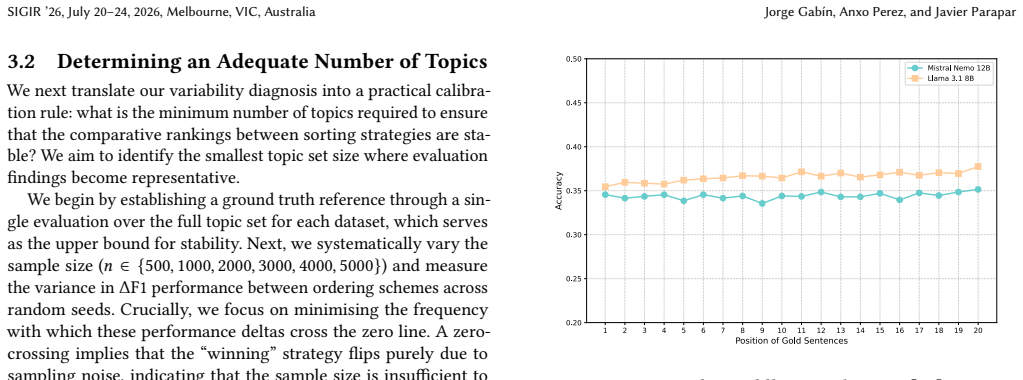
The calibration procedure that identifies stable topic counts by repeated subset sampling across multiple topic budgets.
If this is right
- Small topic sets can mask or exaggerate ordering effects.
- Discrepancies with prior industry results arise from limited topic coverage and use of LLM-based judges.
- Under imperfect retrieval, document order and context size affect downstream performance differently than they do under oracle access.
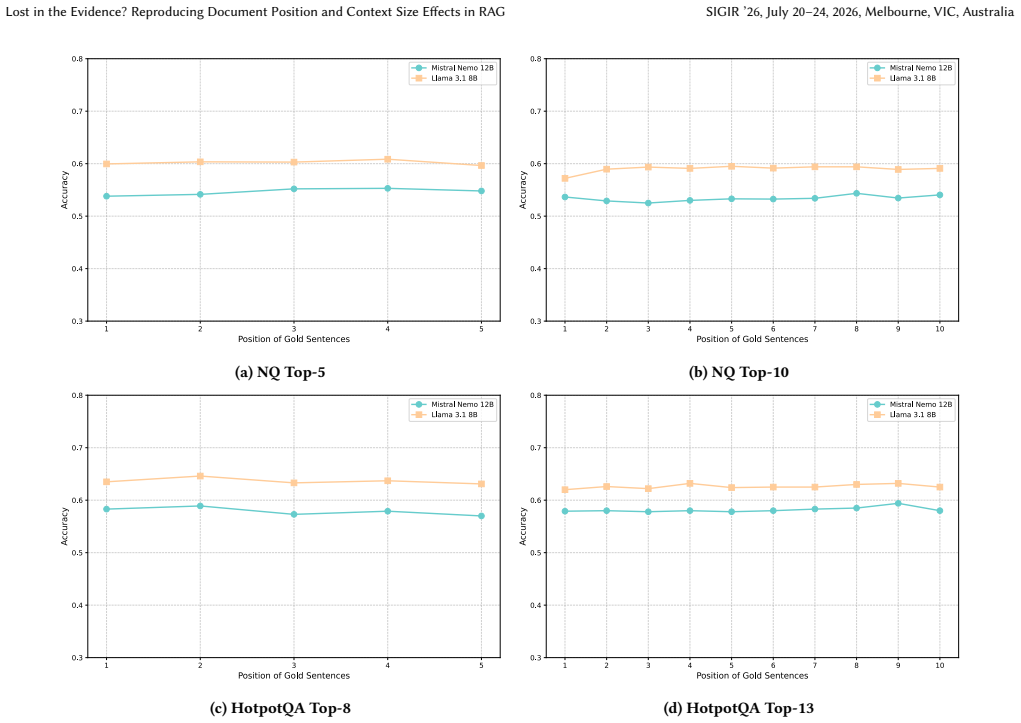
- Modern LLMs continue to exhibit positional biases, but those biases are modulated by retrieval quality.
Where Pith is reading between the lines
- RAG builders should evaluate ordering and length choices with actual retrievers rather than oracle documents.
- Stable claims about position effects require topic sets large enough to survive the calibration check.
- Improving retriever precision may reduce the practical importance of position-handling techniques.
Load-bearing premise
Trends observed through repeated subset sampling of topics will generalize beyond the particular datasets, models, and evaluation protocols used in the study.
What would settle it
A new experiment on a different collection of LLMs and retrievers that finds position and length effects remain unchanged across oracle and realistic retrieval conditions would falsify the claimed interaction.
Figures
read the original abstract
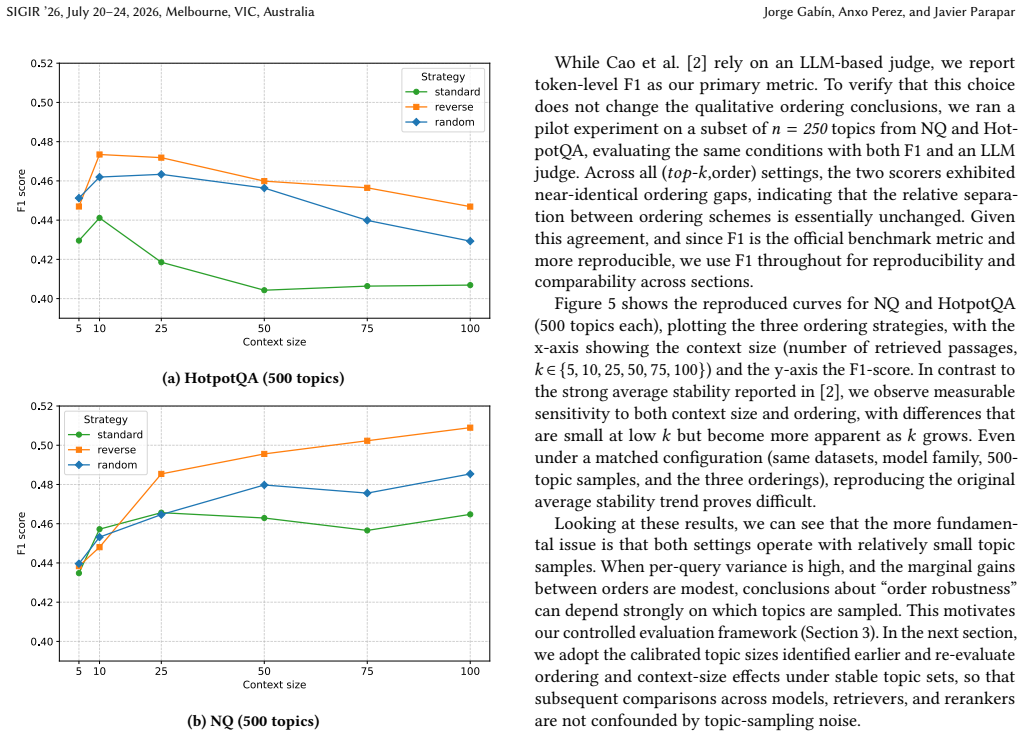
Retrieval-Augmented Generation (RAG) systems rely on retrieved documents being concatenated into a model's input context, making both document ordering and context size critical yet controversial design choices. Prior work reports position-based effects such as lost in the middle and related long-context phenomena. However, empirical findings remain inconsistent and hard to reproduce across models, datasets, and evaluation protocols. In this paper, we present a systematic reproducibility study that revisits these claims and examines how they evolve with contemporary LLMs under a controlled evaluation framework. We first show that topic sampling is a major source of variance: small topic sets can mask or exaggerate ordering effects. Based on repeated subset sampling across multiple topic budgets, we provide a practical calibration procedure that identifies topic counts yielding stable trends at feasible cost. Using these fixed topic sets, we then reproduce and extend results on position sensitivity, re-evaluating lost in the middle and positional biases in modern LLMs. Then, we also study a more realistic RAG scenario in which relevance is mediated by a retriever rather than oracle access to ground-truth documents. In this setting, we re-examine a recent industry study and identify discrepancies to evaluation choices such as limited topic coverage and reliance on LLM-based judges. Finally, we conduct an analysis of how retrieval order and context size affect downstream LLM performance under imperfect retrieval. Our results demonstrate that both factors interact strongly with retrieval quality and model choice, and that conclusions drawn from idealised setups do not always transfer to real-world RAG pipelines. We release all code and configurations to support reproducibility and future work on robust RAG evaluation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematic reproducibility study on document position and context size effects in RAG systems. It identifies topic sampling as a major source of variance, proposes a calibration procedure based on repeated subset sampling to select stable topic budgets, reproduces position sensitivity (including lost in the middle) in modern LLMs using these fixed sets, examines discrepancies with a prior industry study in a realistic retriever-mediated RAG setting, and analyzes how retrieval order and context size interact with retrieval quality and model choice. The central claim is that idealized-setup conclusions do not always transfer to real-world RAG pipelines. All code and configurations are released.
Significance. If the calibration procedure produces stable trends that generalize and the non-transferability findings hold, the work would be significant for RAG evaluation practices by underscoring the need for adequate topic coverage and cautioning against over-reliance on idealized oracle-retrieval setups. The explicit release of code and configurations is a clear strength that directly supports the reproducibility focus of the study.
major comments (1)
- [Calibration procedure (§3)] Calibration procedure (described in the abstract and §3): The procedure relies on repeated subset sampling over the study's specific datasets and models to identify topic counts yielding stable trends, but provides no explicit validation that these budgets remain stable when other variance sources (retriever ranking distributions, LLM judge variance, or prompt templates) differ. This is load-bearing for the central claim that conclusions do not transfer from idealized to realistic RAG, as unaccounted variance could render the fixed topic sets insufficient outside the tested configurations.
minor comments (2)
- [Abstract] Abstract: The description of the realistic RAG scenario and discrepancies with the industry study would benefit from naming the specific prior work and evaluation choices (e.g., topic coverage limits or LLM judge reliance) to improve clarity for readers.
- [Abstract and §1] The manuscript states that code is released but does not include the repository URL or DOI in the abstract or introduction; adding this would aid immediate reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the reproducibility focus and code release. We address the single major comment below.
read point-by-point responses
-
Referee: The procedure relies on repeated subset sampling over the study's specific datasets and models to identify topic counts yielding stable trends, but provides no explicit validation that these budgets remain stable when other variance sources (retriever ranking distributions, LLM judge variance, or prompt templates) differ. This is load-bearing for the central claim that conclusions do not transfer from idealized to realistic RAG, as unaccounted variance could render the fixed topic sets insufficient outside the tested configurations.
Authors: We thank the referee for this observation. The calibration is intentionally derived from repeated subset sampling on the specific datasets and models in our experiments to isolate and control topic-sampling variance; it is presented as a practical, setup-specific tool rather than a universally validated budget. We agree that no explicit cross-validation is provided against additional variance sources such as retriever ranking distributions, LLM judge variance, or prompt templates. In revision we will add a short discussion paragraph in §3 that (a) states the scope of the calibration, (b) notes that practitioners should re-run the procedure when introducing new variance sources, and (c) clarifies that the non-transferability results are demonstrated under the calibrated topic sets within the configurations we tested. The released code already enables such re-calibration, so the limitation is addressable by users. This addition does not change the empirical findings but makes the claims more precise. revision: partial
Circularity Check
Empirical reproducibility study with no circular derivations
full rationale
This paper is a controlled empirical reproducibility study on RAG position and context effects. It describes a calibration procedure based on repeated subset sampling to select stable topic budgets, but this is an experimental design choice for variance control rather than any derivation, equation, or fitted parameter that reduces to its own inputs by construction. No self-citation load-bearing steps, uniqueness theorems, ansatzes, or renamings of known results appear in the load-bearing claims. The central findings rest on direct experimental comparisons across models, retrievers, and datasets, which are externally falsifiable and independent of the calibration outputs themselves.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in LLM evaluation such as the validity of LLM-based judges for assessment.
Reference graph
Works this paper leans on
-
[1]
Chen Amiraz, Florin Cuconasu, Simone Filice, and Zohar Karnin. 2025. The Distracting Effect: Understanding Irrelevant Passages in RAG. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Moham- mad Taher Pilehvar (Eds.). Association for Compu...
-
[2]
Shuyang Cao, Karthik Radhakrishnan, David Rosenberg, Steven Lu, Pengxiang Cheng, Lu Wang, and Shiyue Zhang. 2025. Evaluating the Retrieval Robustness of Large Language Models. (05 2025). doi:10.48550/arXiv.2505.21870
-
[3]
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, and Haofen Wang. 2023. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997 2, 1 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Ming-Wei Chang
-
[5]
InProceedings of the 37th International Conference on Machine Learning (ICML’20)
REALM: retrieval-augmented language model pre-training. InProceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 368, 10 pages
-
[6]
Jan Hutter, David Rau, Maarten Marx, and Jaap Kamps. 2025. Lost but Not Only in the Middle - Positional Bias in Retrieval Augmented Generation. InAdvances in Information Retrieval - 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6-10, 2025, Proceedings, Part I (Lecture Notes in Computer Science, Vol. 15572), Claudia Hauf...
-
[7]
Gautier Izacard and Edouard Grave. 2021. Leveraging Passage Retrieval with Generative Models for Open Domain Question Answering. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, Paola Merlo, Jorg Tiedemann, and Reut Tsarfaty (Eds.). Association for Computational Linguistics, Online...
-
[8]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense Passage Retrieval for Open- Domain Question Answering. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (Eds.). Association for Com...
-
[9]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: A Benchmark for Question Answering Research.Tr...
-
[10]
Alexandre Lacoste, Alexandra Luccioni, Victor Schmidt, and Thomas Dandres
-
[11]
Quantifying the Carbon Emissions of Machine Learning.arXiv preprint arXiv:1910.09700(2019)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[12]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InProceedings of the 34th International Conference on Neural Information Processing Systems(Van...
2020
-
[13]
Oscar Lithgow-Serrano, David Kletz, Vani Kanjirangat, David Adametz, Marzio Lunghi, Claudio Bonesana, Matilde Tristany-Farinha, Yuntao Li, Detlef Rep- plinger, Marco Pierbattista, Stefania Stan, and Oleg Szehr. 2025. Assessing RAG System Capabilities on Financial Documents. InProceedings of The 10th Work- shop on Financial Technology and Natural Language ...
-
[14]
Lost in the Middle: How Language Models Use Long Contexts,
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the Middle: How Language Models Use Long Contexts.Transactions of the Association for Computational Linguistics 12 (2024), 157–173. doi:10.1162/tacl_a_00638
-
[15]
2025.RAG and the Future of Intelligent Enterprise Applications
Microsoft. 2025.RAG and the Future of Intelligent Enterprise Applications. White Paper. Microsoft. https://cdn-dynmedia-1.microsoft.com/is/content/ microsoftcorp/microsoft/final/en-us/microsoft-product-and-services/March- 2025-rag-and-the-future-of-intelligent-enterprise-applications.pdf
2025
-
[16]
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. 2020. AmbigQA: Answering Ambiguous Open-domain Questions. InProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 5783–5797
2020
-
[17]
Rodrigo Nogueira and Kyunghyun Cho. 2019. Passage Re-ranking with BERT. ArXivabs/1901.04085 (2019). https://api.semanticscholar.org/CorpusID:58004692
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[18]
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Frame- work: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (April 2009), 333–389. doi:10.1561/1500000019
-
[19]
Fangzheng Tian, Debasis Ganguly, and Craig Macdonald. 2025. Is Relevance Propagated from Retriever to Generator in RAG?. InAdvances in Information Retrieval - 47th European Conference on Information Retrieval, ECIR 2025, Lucca, Italy, April 6-10, 2025, Proceedings, Part I (Lecture Notes in Computer Science, Vol. 15572), Claudia Hauff, Craig Macdonald, Die...
-
[20]
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. 2024. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[21]
Anbang Xu, Tan Yu, Min Du, Pritam Gundecha, Yufan Guo, Xinliang Zhu, May Wang, Ping Li, and Xinyun Chen. 2024. Generative AI and Retrieval-Augmented Generation (RAG) Systems for Enterprise. InProceedings of the 33rd ACM In- ternational Conference on Information and Knowledge Management(Boise, ID, USA)(CIKM ’24). Association for Computing Machinery, New Yo...
-
[22]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Ellen Riloff, David Chiang, Julia Hockenmaier, and Jun’ichi Tsujii (...
-
[23]
Hao Yu, Aoran Gan, Kai Zhang, Shiwei Tong, Qi Liu, and Zhaofeng Liu. 2025. Eval- uation of Retrieval-Augmented Generation: A Survey. InBig Data, Wenwu Zhu, Hui Xiong, Xiuzhen Cheng, Lizhen Cui, Zhicheng Dou, Junyu Dong, Shanchen Pang, Li Wang, Lanju Kong, and Zhenxiang Chen (Eds.). Springer Nature Singa- pore, Singapore, 102–120
2025
- [24]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.