Joint Optimization of Relevance and Engagement in Multi-Task Ranking for E-Commerce with Efficient LLM Supervision
Pith reviewed 2026-06-29 15:11 UTC · model grok-4.3
The pith
A multi-task ranking system uses an ordinal relevance head and LLM-generated labels to enable controllable trade-offs between semantic quality and engagement in e-commerce search.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
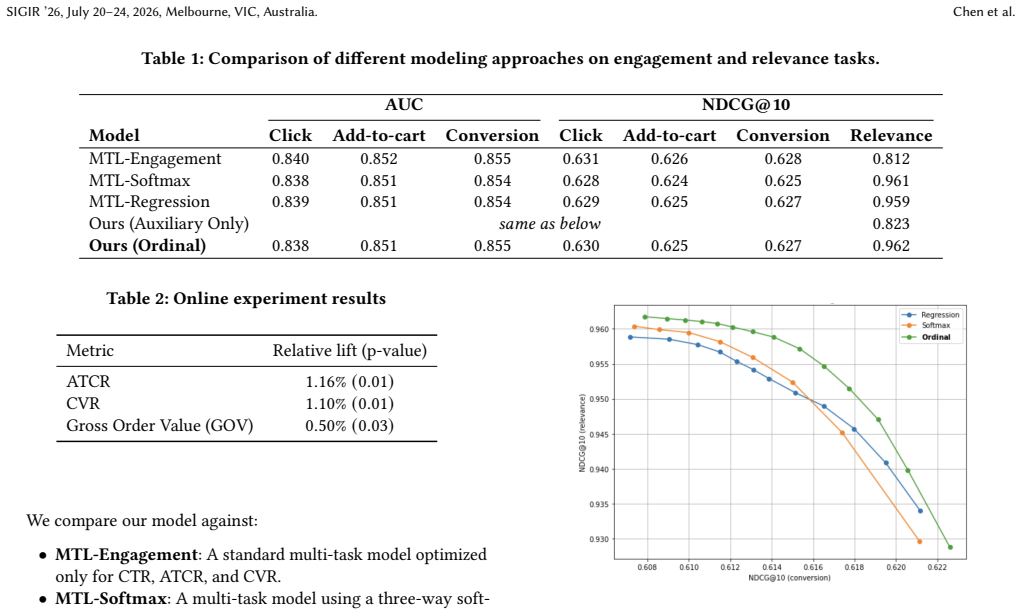
The architecture employs an ordinal relevance head that predicts cumulative probabilities over relevance thresholds, preserving the inherent ordering of labels. These outputs are integrated with engagement heads through a unified value model scoring function, enabling systematic balancing of semantic quality and short-term behavioral signals. Fine-tuned lightweight LLMs generate three-level ordinal relevance labels to provide high-quality supervision at scale while addressing label distribution sensitivity.
What carries the argument
The ordinal relevance head that predicts cumulative probabilities over relevance thresholds, integrated with engagement heads via a unified value model scoring function.
Load-bearing premise
Fine-tuned lightweight LLMs can generate three-level ordinal relevance labels at scale with high alignment to human annotations and without introducing label distribution sensitivity that would undermine the multi-task optimization.
What would settle it
A large-scale human annotation study on a held-out sample of query-item pairs showing low agreement with the LLM labels, followed by retraining that produces no gain or a loss in NDCG@10 and online engagement metrics.
Figures

read the original abstract
Optimizing industrial search ranking models solely for user engagement signals often introduces systematic biases, prioritizing popular or price-anchored items that may not satisfy semantic intent. We present a production-scale multi-task ranking system that integrates semantic relevance as a primary optimization objective, enabling explicit and controllable relevance-engagement trade-offs. Our architecture employs an ordinal relevance head that predicts cumulative probabilities over relevance thresholds, preserving the inherent ordering of labels. These outputs are integrated with engagement heads through a unified value model scoring function, enabling systematic balancing of semantic quality and short-term behavioral signals. To provide high-quality supervision for this multi-task framework, we utilize fine-tuned lightweight Large Language Models (LLMs) to generate three-level ordinal relevance labels: irrelevant, moderately relevant, and highly relevant. We address challenges regarding label distribution sensitivity and ensure high alignment with human annotations to enable efficient labeling for over 100 million query-item pairs. Evaluation across offline metrics, including NDCG@10, and online A/B experiments demonstrates that our approach significantly improves semantic alignment while preserving core engagement objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to present a production-scale multi-task ranking architecture for e-commerce search that adds an ordinal relevance head (predicting cumulative probabilities over three-level labels) to engagement heads via a unified value model scoring function. Fine-tuned lightweight LLMs are used to label >100M query-item pairs with irrelevant/moderately/highly relevant labels; the system is reported to deliver NDCG@10 gains offline and positive A/B results while allowing controllable relevance-engagement trade-offs.
Significance. If the central claims hold, the work would be significant for industrial IR systems by demonstrating a practical way to inject semantic relevance signals at scale without sacrificing engagement metrics. The use of ordinal heads and a unified scorer to manage trade-offs, combined with LLM supervision for massive labeling, addresses a common production pain point.
major comments (2)
- [Abstract] Abstract: the claim that the fine-tuned LLMs achieve 'high alignment with human annotations' for the three-level ordinal labels is unsupported by any reported agreement metrics (kappa, accuracy, or confusion matrices versus human raters). This is load-bearing for the multi-task claims because the NDCG@10 and A/B gains are attributed to the relevance head; without label-quality evidence or noise ablations, attribution to the ordinal component versus other modeling choices cannot be assessed.
- [Abstract] Abstract: no description is given of how the cumulative-probability outputs of the ordinal head are combined with the engagement heads inside the unified value model, nor of any sensitivity analysis under the reported label distributions. This prevents verification that the architecture actually enables the claimed 'systematic balancing' rather than being dominated by engagement signals.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and indicate planned changes to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the fine-tuned LLMs achieve 'high alignment with human annotations' for the three-level ordinal labels is unsupported by any reported agreement metrics (kappa, accuracy, or confusion matrices versus human raters). This is load-bearing for the multi-task claims because the NDCG@10 and A/B gains are attributed to the relevance head; without label-quality evidence or noise ablations, attribution to the ordinal component versus other modeling choices cannot be assessed.
Authors: We agree that the abstract does not report quantitative agreement metrics to support the alignment claim. The manuscript body contains validation details on label quality, but the abstract would be strengthened by including them. We will revise the abstract to report key metrics (e.g., accuracy and Cohen's kappa versus human raters) and note any label-noise considerations to better support attribution of the observed gains. revision: yes
-
Referee: [Abstract] Abstract: no description is given of how the cumulative-probability outputs of the ordinal head are combined with the engagement heads inside the unified value model, nor of any sensitivity analysis under the reported label distributions. This prevents verification that the architecture actually enables the claimed 'systematic balancing' rather than being dominated by engagement signals.
Authors: The abstract describes the integration at a high level via the unified value model but does not detail the combination mechanism or sensitivity analysis. We will revise the abstract to briefly explain how the ordinal cumulative probabilities are converted to a relevance score and combined with engagement predictions in the scoring function, and we will reference the sensitivity analysis performed across label distributions (with full details retained in the methods section). revision: yes
Circularity Check
No significant circularity; claims rest on external evaluation
full rationale
The provided abstract and context describe a multi-task architecture using LLM-generated ordinal labels, integrated via a unified scoring function, with evaluation on NDCG@10 and A/B tests. No equations, self-citations, or derivations are exhibited that reduce any claimed result to a fitted input or self-definition by construction. The central claims depend on external human alignment and online experiments rather than internal redefinitions, satisfying the criteria for a self-contained derivation chain.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sanjay Agrawal, Faizan Ahemad, and Vivek Sembium. 2025. Rationale-Guided Distillation for E-Commerce Relevance Classification: Bridging Large Language Models and Lightweight Cross-Encoders. InProceedings of the 31st International Conference on Computational Linguistics: Industry Track. Association for Compu- tational Linguistics, 136–148. https://aclantho...
2025
-
[2]
Cong Fu, Kun Wang, Jiahua Wu, Yizhou Chen, Guangda Huzhang, Yabo Ni, Anxiang Zeng, and Zhiming Zhou. 2024. Residual Multi-Task Learner for Ap- plied Ranking. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. doi:10.1145/3637528.3671523
-
[4]
Thorsten Joachims, Adith Swaminathan, and Tobias Schnabel. 2017. Unbiased Learning-to-Rank with Biased Feedback. InProceedings of the Tenth ACM Inter- national Conference on Web Search and Data Mining
2017
-
[5]
Qi Liu, Atul Singh, Jingbo Liu, Cun Mu, and Zheng Yan. 2024. Towards More Relevant Product Search Ranking Via Large Language Models: An Empirical Study.arXiv(2024). arXiv:2409.17460 [cs.IR] doi:10.48550/arXiv.2409.17460
-
[6]
Navid Mehrdad, Hrushikesh Mohapatra, Mossaab Bagdouri, Prijith Chandran, Alessandro Magnani, Xunfan Cai, Ajit Puthenputhussery, Sachin Yadav, Tony Lee, ChengXiang Zhai, and Ciya Liao. 2024. Large Language Models for Relevance Judgment in Product Search.arXiv(2024). arXiv:2406.00247 [cs.IR] doi:10.48550/ arXiv.2406.00247
-
[7]
Lalitesh Morishetti, Abhay Kumar, Jonathan Scott, Kaushiki Nag, Gunjan Sharma, Shanu Vashishtha, Rahul Sridhar, Rohit Chatter, and Kannan Achan. 2025. Person- alized Product Search Ranking: A Multi-Task Learning Approach with Tabular and Non-Tabular Data.arXiv(2025). arXiv:2508.09636 [cs.IR] doi:10.48550/arXiv. 2508.09636
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[8]
OpenAI. 2024. GPT-4o mini: Advancing Cost-Efficient Intelligence. https:// openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/. Accessed: 2026-04-29
2024
-
[9]
OpenAI. 2024. GPT-4o System Card. https://openai.com/index/gpt-4o-system- card/. Accessed: 2026-04-29
2024
-
[10]
OpenAI. 2025. OpenAI o3 and o4-mini System Card. https://openai.com/index/o3- o4-mini-system-card/. Accessed: 2026-04-29
2025
-
[11]
Rahmani, Clemencia Siro, Mohammad Aliannejadi, Nick Craswell, Charles L
Hossein A. Rahmani, Clemencia Siro, Mohammad Aliannejadi, Nick Craswell, Charles L. A. Clarke, Guglielmo Faggioli, Bhaskar Mitra, Paul Thomas, and Emine Yilmaz. 2025. Judging the Judges: A Collection of LLM-Generated Relevance Judgements.arXiv(2025). arXiv:2502.13908 [cs.IR] doi:10.48550/arXiv.2502.13908
-
[12]
Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is ChatGPT Good at Search? Investi- gating Large Language Models as Re-Ranking Agents. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 14918–14937. https://ac...
2023
-
[13]
Han Wang, Mukuntha Narayanan Sundararaman, Onur Gungor, Yu Xu, Krishna Kamath, Rakesh Chalasani, Kurchi Subhra Hazra, and Jinfeng Rao. 2024. Im- proving Pinterest Search Relevance Using Large Language Models.arXiv(2024). arXiv:2410.17152 [cs.IR] doi:10.48550/arXiv.2410.17152
-
[14]
Han Wang, Alex Whitworth, Pak Ming Cheung, Zhenjie Zhang, and Krishna Kamath. 2025. LLM-based Relevance Assessment for Web-Scale Search Evaluation at Pinterest.arXiv(2025). arXiv:2509.03764 [cs.IR] doi:10.48550/arXiv.2509.03764
- [15]
-
[16]
Jiaqi Xi, Raghav Saboo, Luming Chen, Martin Wang, and Sudeep Das. 2026. Mine and Refine: Optimizing Graded Relevance in E-Commerce Search Retrieval.arXiv (2026). arXiv:2602.17654 [cs.IR] doi:10.48550/arXiv.2602.17654
-
[17]
Honglei Zhuang, Zhen Qin, Kai Hui, Junru Wu, Le Yan, Xuanhui Wang, and Michael Bendersky. 2024. Beyond Yes and No: Improving Zero-Shot LLM Rankers via Scoring Fine-Grained Relevance Labels. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 2: Short Paper...
-
[18]
Shengyao Zhuang, Honglei Zhuang, Bevan Koopman, and Guido Zuccon. 2024. A Setwise Approach for Effective and Highly Efficient Zero-shot Ranking with Large Language Models. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval. doi:10.1145/ 3626772.3657813
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.