CXL-ClusterSim: Modeling CXL-based Disaggregated Memory Cluster for Pooling and Sharing using gem5 and SST
Pith reviewed 2026-06-29 14:49 UTC · model grok-4.3
The pith
CXL-ClusterSim combines gem5 and SST to simulate CXL disaggregated memory clusters at scale.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
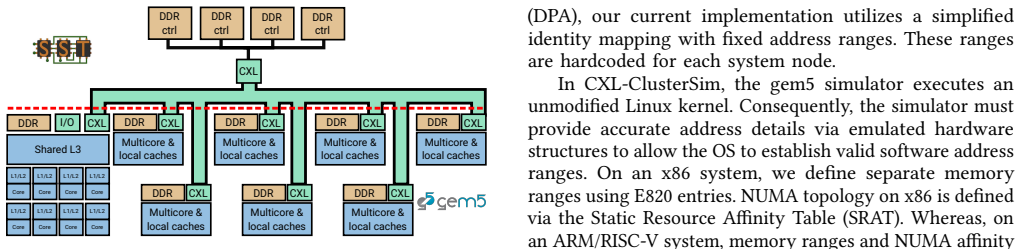
CXL-ClusterSim is a full-system simulation framework that merges gem5 for high-fidelity modeling of individual nodes with SST for scalable parallel execution across clusters, enabling evaluation of CXL-based memory disaggregation for improved resource utilization.
What carries the argument
The CXL-ClusterSim framework integrates gem5 and SST to model CXL protocol behavior in disaggregated memory clusters.
Load-bearing premise
The integration of gem5 and SST can preserve modeling fidelity for CXL behavior and cluster interactions without major accuracy loss or slowdown.
What would settle it
Running the same workload on both CXL-ClusterSim and a real CXL-enabled hardware cluster and finding large discrepancies in measured latency or throughput.
Figures







read the original abstract
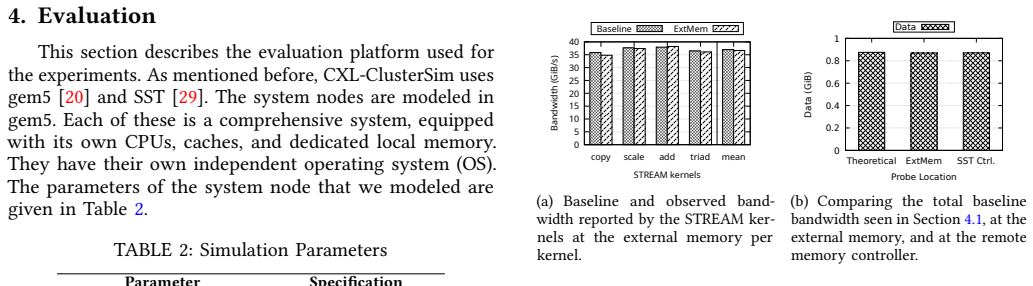
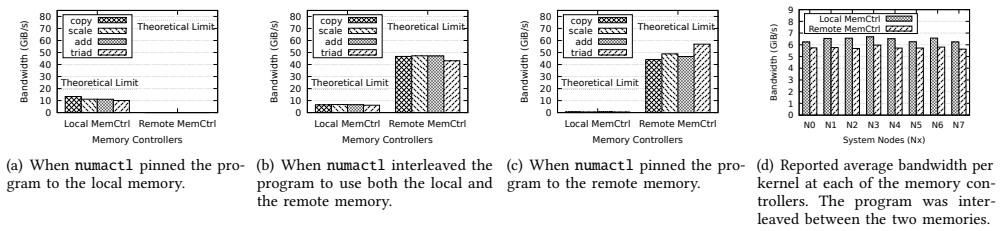
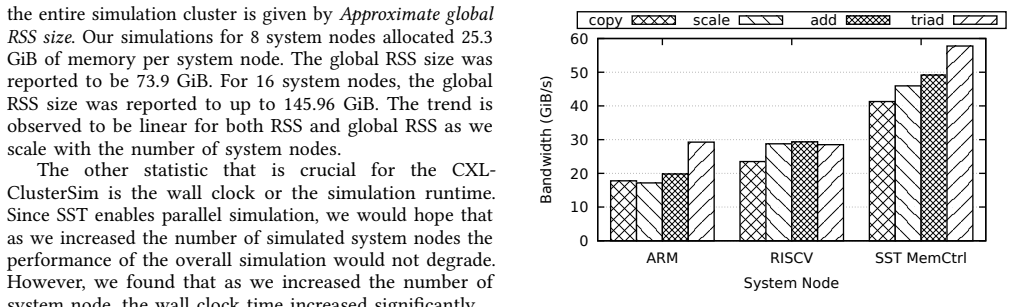
Large-scale AI training and inference require hundreds of gigabytes to terabytes of DRAM with high peak to average utilization ratios, resulting in overprovisioning. In cloud computing, DRAM constitutes a significant share of the cost. Yet, as shown by recent articles, DRAM is heavily under utilized. Memory disaggregation is a solution to both these problems. With the advent of the CXL protocol, there is renewed interest in designing and optimizing computing systems with disaggregated memory. However, at present, there are limited simulation tools available for exploring the design space and evaluating the performance tradeoffs in computer systems with disaggregated memory. In this paper, we propose CXL-ClusterSim, a full-system modeling and simulation framework by combining the gem5 simulator for fidelity, with the Structural Simulation Toolkit (SST) for parallel simulation. We outline the challenges in creating this simulation infrastructure and present a design that is scalable, flexible, and reasonably fast to help computer architects to explore the design space of CXL-based disaggregated memory and identify new opportunities for hardware/software codesign and performance optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CXL-ClusterSim, a full-system simulation framework that integrates the gem5 simulator (for modeling fidelity) with the Structural Simulation Toolkit (SST) (for parallel execution) to enable exploration of CXL-based disaggregated memory clusters for pooling and sharing. It outlines integration challenges and claims the resulting design is scalable, flexible, and reasonably fast for computer architects studying hardware/software co-design opportunities in memory disaggregation.
Significance. A validated implementation of this framework could address the current scarcity of simulation tools for CXL disaggregated memory systems and support design-space exploration at cluster scale. However, the manuscript supplies no validation data, performance measurements, fidelity comparisons to standalone gem5, or evidence that the gem5-SST coupling preserves CXL link, coherence, and memory-pool semantics, so the practical significance cannot yet be assessed.
major comments (2)
- [Abstract / §1] Abstract and §1 (Introduction): The central claim that the framework is 'scalable, flexible, and reasonably fast' while preserving 'sufficient modeling fidelity for CXL protocol behavior and cluster-scale interactions' is unsupported; the text contains no simulation speed results, accuracy metrics versus a pure-gem5 baseline, or timing-accuracy data for CXL transactions.
- [Design / Integration description] The integration layer between gem5 and SST is identified as the least-secured point for preserving transaction ordering, latency distributions, and bandwidth contention, yet no section demonstrates that the chosen synchronization or abstraction mechanisms maintain these properties at cluster scale.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript describing CXL-ClusterSim. The work focuses on the design of a gem5-SST integration framework for CXL disaggregated memory, including integration challenges. We acknowledge that the manuscript does not include quantitative validation, speed results, or fidelity metrics, as it is primarily a design and architecture paper rather than an evaluation study. We will revise the text to ensure claims are appropriately qualified.
read point-by-point responses
-
Referee: [Abstract / §1] Abstract and §1 (Introduction): The central claim that the framework is 'scalable, flexible, and reasonably fast' while preserving 'sufficient modeling fidelity for CXL protocol behavior and cluster-scale interactions' is unsupported; the text contains no simulation speed results, accuracy metrics versus a pure-gem5 baseline, or timing-accuracy data for CXL transactions.
Authors: We agree that these claims lack supporting quantitative data in the manuscript. The paper's scope is the proposal of the framework architecture and discussion of integration challenges, not empirical evaluation. We will revise the abstract and §1 to remove or qualify the unsupported claims (e.g., stating design goals rather than demonstrated properties) and add a note that performance and fidelity evaluations are planned future work. revision: yes
-
Referee: [Design / Integration description] The integration layer between gem5 and SST is identified as the least-secured point for preserving transaction ordering, latency distributions, and bandwidth contention, yet no section demonstrates that the chosen synchronization or abstraction mechanisms maintain these properties at cluster scale.
Authors: The manuscript describes the integration mechanisms chosen to address ordering, latency, and contention. However, we acknowledge the absence of any demonstration or empirical evidence that these mechanisms preserve the required properties at cluster scale. We will expand the relevant design section with additional detail on the synchronization approach and its rationale, while explicitly noting the lack of validation and the assumptions involved. Full demonstration would require new experiments. revision: partial
- Providing empirical validation data, speed measurements, accuracy metrics, or cluster-scale demonstrations of semantic preservation, as no such experiments or results exist in the current work.
Circularity Check
No circularity: tool-construction paper with no derivations or predictions
full rationale
The paper is a description of a proposed simulation framework (CXL-ClusterSim) that integrates two established external simulators (gem5 and SST). No equations, fitted parameters, predictions, or derivation chains exist in the text. The central claim is a design proposal for scalability and flexibility, not a result derived from inputs by construction. All load-bearing elements are engineering choices justified by reference to the capabilities of the base tools rather than self-referential reduction. This matches the default expectation of no circularity for non-derivational work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption gem5 provides high-fidelity modeling of individual CPU and memory systems
- domain assumption SST supports scalable parallel simulation of large systems
Reference graph
Works this paper leans on
-
[1]
CXL®4.0 Specification
“CXL®4.0 Specification. ” [Online]. Available: https:// computeexpresslink.org/cxl-specification/"
-
[2]
CXL®Specification
“CXL®Specification. ” [Online]. Available: https://computeexpresslink. org/cxl-specification/"
-
[3]
GPT-4 architecture, datasets, costs and more leaked,
“GPT-4 architecture, datasets, costs and more leaked, ” 2020. [Online]. Available: https://the-decoder.com/ gpt-4-architecture-datasets-costs-and-more-leaked/"
2020
-
[4]
Compute Express Link (CXL): All you need to know,
“Compute Express Link (CXL): All you need to know, ” 2024. [Online]. Available: https://www.rambus.com/blogs/compute-express-link/"
2024
-
[5]
Memory disaggregation: why now and what are the challenges,
M. K. Aguilera, E. Amaro, N. Amit, E. Hunhoff, A. Yelam, and G. Zellweger, “Memory disaggregation: why now and what are the challenges, ”SIGOPS Oper. Syst. Rev., vol. 57, no. 1, p. 38–46, jun
-
[6]
Available: https://doi.org/10.1145/3606557.3606563
[Online]. Available: https://doi.org/10.1145/3606557.3606563
-
[7]
pd-gem5: Simulation Infrastructure for Parallel/Distributed Computer Systems ,
M. Alian, D. Kim, and N. Sung Kim, “ pd-gem5: Simulation Infrastructure for Parallel/Distributed Computer Systems , ”IEEE Computer Architecture Letters, vol. 15, no. 01, pp. 41–44, Jan. 2016. [Online]. Available: https://doi.ieeecomputersociety.org/10.1109/LCA. 2015.2438295
work page doi:10.1109/lca 2016
-
[8]
Xerxes: Extensive exploration of scalable hardware systems with CXL-Based simulation framework,
Y. An, S. Yi, B. Mao, Q. Li, M. Zhang, D. Zhou, K. Zhou, N. Xiao, G. Sun, Y. Luo, and J. Zhang, “Xerxes: Extensive exploration of scalable hardware systems with CXL-Based simulation framework, ” in24th USENIX Conference on File and Storage Technologies (FAST 26). Santa Clara, CA: USENIX Association, Feb. 2026, pp. 329–345. [Online]. Available: https: //ww...
2026
-
[9]
The NAS Parallel Benchmarks,
D. H. Bailey, E. Barszcz, J. T. Barton, D. S. Browning, R. L. Carter, L. Dagum, R. A. Fatoohi, P. O. Frederickson, T. A. Lasinski, R. S. Schreiberet al., “The NAS Parallel Benchmarks, ”The International Journal of Supercomputing Applications, vol. 5, no. 3, pp. 63–73, 1991
1991
-
[10]
S. Beamer, K. Asanović, and D. Patterson, “The gap benchmark suite, ” 2017. [Online]. Available: https://arxiv.org/abs/1508.03619
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[11]
Enabling reproducible and agile full-system simulation,
B. R. Bruce, A. Akram, H. Nguyen, K. Roarty, M. Samani, M. Friborz, T. Reddy, M. D. Sinclair, and J. Lowe-Power, “Enabling reproducible and agile full-system simulation, ” in2021 IEEE International Sym- posium on Performance Analysis of Systems and Software (ISPASS). IEEE, 2021, pp. 183–193
2021
-
[12]
Starnuma: Mitigating numa challenges with memory pooling,
A. Cho and A. Daglis, “Starnuma: Mitigating numa challenges with memory pooling, ” inProceedings of the 2024 57th IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’24. IEEE Press, 2024, p. 997–1012. [Online]. Available: https: //doi.org/10.1109/MICRO61859.2024.00077
-
[13]
Ai and memory wall,
A. Gholami, Z. Yao, S. Kim, C. Hooper, M. W. Mahoney, and K. Keutzer, “Ai and memory wall, ”IEEE Micro, 2024
2024
-
[14]
Direct access, {High- Performance} memory disaggregation with {DirectCXL},
D. Gouk, S. Lee, M. Kwon, and M. Jung, “Direct access, {High- Performance} memory disaggregation with {DirectCXL}, ” in2022 USENIX Annual Technical Conference (USENIX ATC 22), 2022, pp. 287–294
2022
-
[15]
Simulating DRAM controllers for future system architecture exploration,
A. Hansson, N. Agarwal, A. Kolli, T. F. Wenisch, and A. N. Udipi, “Simulating DRAM controllers for future system architecture exploration, ” in2014 IEEE International Symposium on Performance Analysis of Systems and Software, ISPASS 2014, Monterey, CA, USA, March 23-25, 2014. IEEE Computer Society, 2014, pp. 201–210. [Online]. Available: https://doi.org/1...
-
[16]
Sst + gem5 = a scalable simulation infrastructure for high performance computing,
M. Hsieh, K. Pedretti, J. Meng, A. Coskun, M. Levenhagen, and A. Rodrigues, “Sst + gem5 = a scalable simulation infrastructure for high performance computing, ” inProceedings of the 5th International ICST Conference on Simulation Tools and Techniques, ser. SIMUTOOLS ’12. Brussels, BEL: ICST (Institute for Computer Sciences, Social- Informatics and Telecom...
2012
-
[17]
OpenCAPI (Open Coherent Accelerator Processor Interface),
IBM, “OpenCAPI (Open Coherent Accelerator Processor Interface), ”
-
[18]
Available: https://docs.kernel.org/userspace-api/ accelerators/ocxl.html
[Online]. Available: https://docs.kernel.org/userspace-api/ accelerators/ocxl.html
-
[19]
Gen-z zmmu and memory interleave„
G.-Z. Interconnect, “Gen-z zmmu and memory interleave„ ” Gen-Z Consortium, Tech. Rep., July 2017. [Online]. Available: https://genzconsortium.org/wp-content/uploads/2018/05/ Gen-Z-MMUand-Memory-Interleave.pdf
2017
-
[20]
Pond: Cxl-based memory pooling systems for cloud platforms,
H. Li, D. S. Berger, L. Hsu, D. Ernst, P. Zardoshti, S. Novakovic, M. Shah, S. Rajadnya, S. Lee, I. Agarwal, M. D. Hill, M. Fontoura, and R. Bianchini, “Pond: Cxl-based memory pooling systems for cloud platforms, ” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ser...
-
[21]
System-level implications of disaggregated memory,
K. Lim, Y. Turner, J. R. Santos, A. AuYoung, J. Chang, P. Ranganathan, and T. F. Wenisch, “System-level implications of disaggregated memory, ” inIEEE International Symposium on High-Performance Comp Architecture (HPCA). IEEE, 2012, pp. 1–12
2012
-
[22]
The gem5 simulator: Version 20.0+,
J. Lowe-Power, A. M. Ahmad, A. Akram, M. Alian, R. Amslinger, M. Andreozzi, A. Armejach, N. Asmussen, B. Beckmann, S. Bharadwaj, G. Black, G. Bloom, B. R. Bruce, D. R. Carvalho, J. Castrillon, L. Chen, N. Derumigny, S. Diestelhorst, W. Elsasser, C. Escuin, M. Fariborz, A. Farmahini-Farahani, P. Fotouhi, R. Gambord, J. Gandhi, D. Gope, T. Grass, A. Gutierr...
2020
-
[23]
S.-L. Lu, T. Karnik, G. Srinivasa, K.-Y. Chao, D. Carmean, and J. Held, “Scaling the "memory wall", ” inProceedings of the International Conference on Computer-Aided Design, ser. ICCAD ’12. New York, NY, USA: Association for Computing Machinery, 2012, p. 271–272. [Online]. Available: https://doi.org/10.1145/2429384.2429437
-
[24]
Tpp: Transparent page placement for cxl-enabled tiered-memory,
H. A. Maruf, H. Wang, A. Dhanotia, J. Weiner, N. Agarwal, P. Bhattacharya, C. Petersen, M. Chowdhury, S. Kanaujia, and P. Chauhan, “Tpp: Transparent page placement for cxl-enabled tiered-memory, ” inProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ser. ASPLOS 2023. New...
-
[25]
Stream: Sustainable memory bandwidth in high performance computers,
J. D. McCalpin, “Stream: Sustainable memory bandwidth in high performance computers, ” University of Virginia, Charlottesville, Virginia, Tech. Rep., 1991-2007, a continually updated technical report. http://www.cs.virginia.edu/stream/. [Online]. Available: http://www.cs.virginia.edu/stream/ 12
1991
-
[26]
Memory bandwidth and machine balance in current high performance computers,
——, “Memory bandwidth and machine balance in current high performance computers, ”IEEE Computer Society Technical Committee on Computer Architecture (TCCA) Newsletter, pp. 19–25, Dec. 1995
1995
-
[27]
Famfs Shared Memory Filesystem Framework - User Space Repo,
MICRON, “Famfs Shared Memory Filesystem Framework - User Space Repo, ” Tech. Rep., 2024. [Online]. Available: https: //github.com/cxl-micron-reskit/famfs
2024
-
[28]
dist-gem5: Distributed simulation of computer clusters,
A. Mohammad, U. Darbaz, G. Dozsa, S. Diestelhorst, D. Kim, and N. S. Kim, “dist-gem5: Distributed simulation of computer clusters, ” in2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). IEEE, 2017, pp. 153–162
2017
-
[29]
gem5/sst integration 2021: Scaling full-system simulations
H. Nguyen and J. Lowe-Power, “gem5/sst integration 2021: Scaling full-system simulations. ” [Online]. Available: https://www.gem5.org/events/isca-2022#:~: text=gem5/SST%20Integration%202021%3A%20Scaling%20Full% 2Dsystem%20Simulations
2021
-
[30]
Dracksim: Simulating cxl-enabled large-scale disaggregated memory systems,
A. Puri, K. Bellamkonda, K. Narreddy, J. Jose, V. Tamarapalli, and V. Narayanan, “Dracksim: Simulating cxl-enabled large-scale disaggregated memory systems, ” inProceedings of the 38th ACM SIGSIM Conference on Principles of Advanced Discrete Simulation, ser. SIGSIM-PADS ’24. New York, NY, USA: Association for Computing Machinery, 2024, p. 3–14. [Online]. ...
-
[31]
The structural simulation toolkit,
A. F. Rodrigues, K. S. Hemmert, B. W. Barrett, C. Kersey, R. Oldfield, M. Weston, R. Risen, J. Cook, P. Rosenfeld, E. Cooper-Balis, and B. Jacob, “The structural simulation toolkit, ”SIGMETRICS Perform. Eval. Rev., vol. 38, no. 4, p. 37–42, mar 2011. [Online]. Available: https://doi.org/10.1145/1964218.1964225
-
[32]
Dramsim2: A cycle accurate memory system simulator,
P. Rosenfeld, E. Cooper-Balis, and B. Jacob, “Dramsim2: A cycle accurate memory system simulator, ”IEEE Computer Architecture Letters, vol. 10, no. 1, pp. 16–19, 2011
2011
-
[33]
Compute express link,
D. D. Sharma, “Compute express link, ”CXL Consortium White Paper, 2019
2019
-
[34]
Compute express link®: An open industry-standard intercon- nect enabling heterogeneous data-centric computing,
——, “Compute express link®: An open industry-standard intercon- nect enabling heterogeneous data-centric computing, ” in2022 IEEE Symposium on High-Performance Interconnects (HOTI), 2022, pp. 5–12
2022
-
[35]
An introduction to the compute express link (cxl) interconnect,
D. D. Sharma, R. Blankenship, and D. S. Berger, “An introduction to the compute express link (cxl) interconnect, ” 2024
2024
-
[36]
Demystifying cxl memory with genuine cxl-ready systems and devices,
Y. Sun, Y. Yuan, Z. Yu, R. Kuper, C. Song, J. Huang, H. Ji, S. Agarwal, J. Lou, I. Jeong, R. Wang, J. H. Ahn, T. Xu, and N. S. Kim, “Demystifying cxl memory with genuine cxl-ready systems and devices, ” inProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture, ser. MICRO ’23. New York, NY, USA: Association for Computing Machi...
-
[37]
A novel, highly integrated simulator for parallel and distributed systems,
N. Tampouratzis, I. Papaefstathiou, A. Nikitakis, A. Brokalakis, S. Andrianakis, A. Dollas, M. Marcon, and E. Plebani, “A novel, highly integrated simulator for parallel and distributed systems, ” ACM Transactions on Architecture and Code Optimization (TACO), vol. 17, no. 1, pp. 1–28, 2020
2020
-
[38]
Asynchronous memory access unit: Exploiting massive parallelism for far memory access,
L. Wang, X. Zhang, S. Wang, Z. Jiang, T. Lu, M. Chen, S. Luo, and K. Huang, “Asynchronous memory access unit: Exploiting massive parallelism for far memory access, ”ACM Trans. Archit. Code Optim., vol. 21, no. 3, Sep. 2024. [Online]. Available: https://doi.org/10.1145/3663479
-
[39]
Y. Wang, L. Wu, S. Gao, Y. Tang, J. Luo, Z. Wang, Y. Ou, D. Dong, N. Xiao, and M. Lai, “Cohet: A cxl-driven coherent heterogeneous computing framework with hardware-calibrated full-system simulation, ” 2026. [Online]. Available: https://arxiv.org/ abs/2511.23011
-
[40]
Cxl-dmsim: A full-system cxl disaggregated memory simulator with comprehensive silicon validation,
Y. Wang, L. Wu, W. Hong, Y. Ou, Z. Wang, S. Gao, J. Zhang, S. Ma, D. Dong, X. Qi, M. Lai, and N. Xiao, “Cxl-dmsim: A full-system cxl disaggregated memory simulator with comprehensive silicon validation, ”IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, vol. 45, no. 4, pp. 1787–1801, 2026. 13
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.