Throughput-Optimized Networks at Scale
Pith reviewed 2026-06-29 09:51 UTC · model grok-4.3
The pith
A linear optimization framework synthesizes network topologies that deliver 2.1x higher throughput than best TPU torus designs for uniform random traffic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
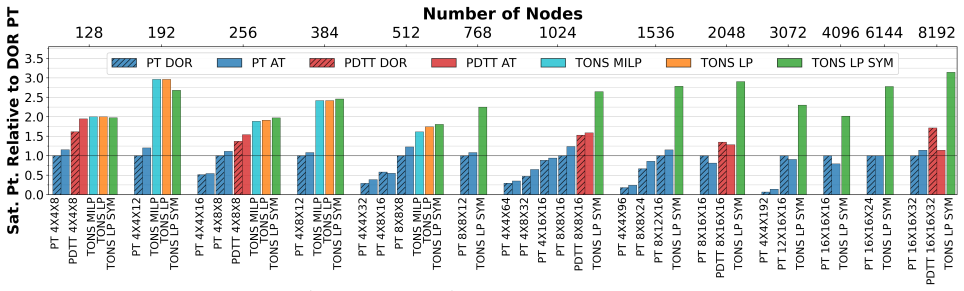
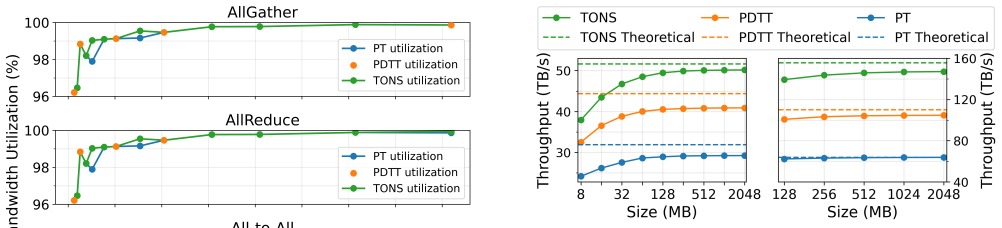
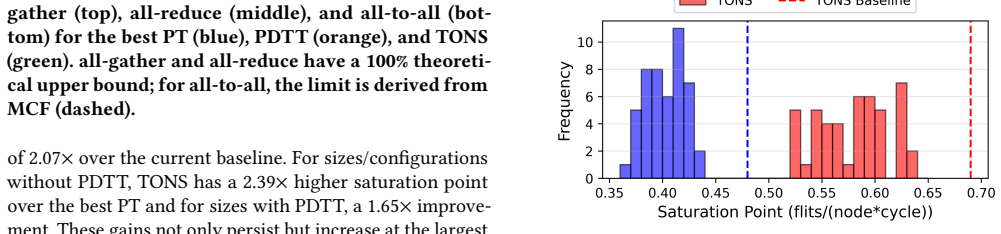
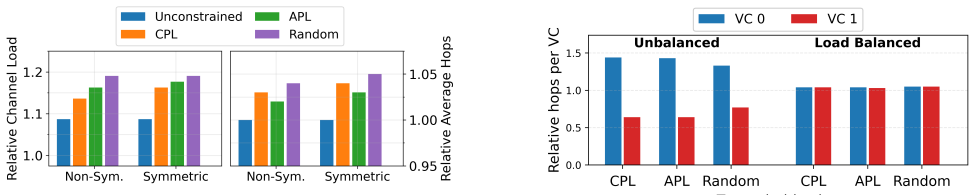
TONS formulates topology synthesis as a linear optimization problem that maximizes a throughput-centric proxy metric, using theory and heuristics to scale to thousands of nodes. It further introduces a deadlock-free routing scheme compatible with limited virtual channels and optical switch faults, enabling the synthesized topologies to realize their predicted throughput gains in simulation. On uniform random and all-to-all traffic, TONS networks achieve geometric mean speedups of 2.1x and 1.6x over the best TPU v4/5p torus variants.
What carries the argument
Linear optimization of a throughput-centric proxy metric for topology synthesis, paired with a deadlock-free routing scheme that works under limited virtual channels and optical switch faults.
If this is right
- Existing TPU torus networks leave terabytes per second of throughput unused on uniform random and all-to-all patterns.
- Automated synthesis can produce custom topologies at the scale of thousands of accelerators without manual design.
- The same linear-optimization plus routing pipeline can be re-run when traffic patterns or hardware constraints change.
- Deadlock-free routing with few virtual channels is sufficient to realize the predicted gains even when optical switches experience faults.
Where Pith is reading between the lines
- The same proxy-metric approach could be applied to other accelerator fabrics that support reconfigurable topologies.
- If the proxy remains predictive, future hardware generations could expose more degrees of freedom for topology choice rather than fixing a torus.
- Operators might reduce the total number of links or switches while still meeting target training throughput by adopting the synthesized designs.
- The framework could be extended to jointly optimize topology and collective algorithms rather than treating collectives separately.
Load-bearing premise
The throughput-centric proxy metric maximized by the linear optimization accurately predicts realized throughput gains once the deadlock-free routing is applied under limited virtual channels and optical switch faults.
What would settle it
A head-to-head simulation or hardware run in which the proxy metric ranks two candidate topologies one way but the measured end-to-end throughput under the deadlock-free routing and realistic faults ranks them the opposite way.
Figures
read the original abstract
Datacenter network design plays a critical role in AI training by supporting scaling to thousands of accelerators. An open problem, designing a near-optimal throughput oriented network-topology, routing, and collectives-has not been achieved at scale and with broad applicability to physical/implementation constraints. We address this problem with a compelling use-case, Google's TPU v4/5p supercomputer where the topology may be reconfigured to achieve higher all-to-all throughput, supporting large, parallelized AI training. We show that the existing TPU networks leave terabytes per second of throughput on the table and we fill that gap. This paper presents Throughput Optimized Networks at Scale (TONS), an automated network synthesis framework that meets the high-throughput demands of modern computing. TONS formulates topology synthesis as a linear optimization problem that maximizes a throughput-centric proxy metric, using theory and heuristics to scale to thousands of nodes. We further introduce a deadlock-free routing scheme compatible with limited virtual channels and optical switch faults, enabling the synthesized topologies to realize their predicted throughput gains in simulation. Evaluating uniform random and all-to-all traffic, TONS networks have a geometric mean speedups of 2.1x and 1.6x, respectively, over the best TPU v4/5p torus variants.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents TONS, an automated framework for synthesizing datacenter network topologies via linear optimization that maximizes a throughput-centric proxy metric. It includes a deadlock-free routing scheme compatible with limited virtual channels and optical switch faults, and claims geometric mean speedups of 2.1x (uniform random) and 1.6x (all-to-all) over the best TPU v4/5p torus variants, evaluated in simulation for TPU-scale AI training workloads.
Significance. If the proxy-to-realized-throughput correlation holds under the stated constraints, the work would address a practical gap in scaling high-throughput networks for large AI training clusters by providing an automated, optimization-driven alternative to manual torus designs. The use of linear programming with scaling heuristics and explicit handling of routing constraints is a strength, but the absence of reported validation metrics for the proxy's predictive accuracy limits the assessed impact.
major comments (2)
- [Abstract] Abstract (paragraph on TONS formulation and evaluation): the central speedup claims (2.1x/1.6x geometric means) rest on the assertion that topologies from the proxy-maximizing LP realize higher throughput once the deadlock-free routing is applied; however, no correlation data, error bars, or ablation showing proxy vs. simulated throughput under VC limits and fault-induced path restrictions is supplied, leaving the transfer from proxy to realized performance unverified.
- [Evaluation] Evaluation section (implied by abstract claims): the traffic models (uniform random, all-to-all) and simulation setup must demonstrate that the proxy remains predictive rather than an overestimate once the full routing stack with limited VCs and optical faults is enforced; without this, the reported speedups cannot be taken as evidence that the optimization delivers the claimed gains.
minor comments (1)
- [Abstract] Abstract: the phrase 'using theory and heuristics to scale to thousands of nodes' would benefit from a brief citation or pointer to the specific scaling technique employed.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The major comments highlight the need for stronger validation of the proxy metric's correlation with realized simulation throughput. We address each point below and commit to revisions that add the requested correlation analysis and ablations while preserving the core claims, which are grounded in full-stack simulations.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on TONS formulation and evaluation): the central speedup claims (2.1x/1.6x geometric means) rest on the assertion that topologies from the proxy-maximizing LP realize higher throughput once the deadlock-free routing is applied; however, no correlation data, error bars, or ablation showing proxy vs. simulated throughput under VC limits and fault-induced path restrictions is supplied, leaving the transfer from proxy to realized performance unverified.
Authors: The reported geometric mean speedups are obtained from cycle-accurate simulations that apply the complete deadlock-free routing scheme, including limited virtual channels and optical switch fault handling. The LP maximizes the proxy during synthesis, but the final performance numbers reflect realized throughput under these constraints. We agree that an explicit correlation analysis (proxy value vs. simulated throughput) with error bars and ablations would better demonstrate the proxy's predictive accuracy. We will add a dedicated subsection and figure in the revised manuscript. revision: yes
-
Referee: [Evaluation] Evaluation section (implied by abstract claims): the traffic models (uniform random, all-to-all) and simulation setup must demonstrate that the proxy remains predictive rather than an overestimate once the full routing stack with limited VCs and optical faults is enforced; without this, the reported speedups cannot be taken as evidence that the optimization delivers the claimed gains.
Authors: Our evaluation already enforces the full routing stack (deadlock-free paths, VC limits, and faults) when measuring throughput for both uniform random and all-to-all traffic. The speedups therefore reflect realized performance rather than proxy estimates. To directly address predictability concerns, we will include additional correlation plots, ablation studies varying VC counts and fault rates, and quantitative metrics (e.g., Pearson correlation) between proxy and simulation results in the revised evaluation section. revision: yes
Circularity Check
No circularity: proxy maximization and simulation evaluation remain distinct steps
full rationale
The paper formulates topology synthesis as an LP maximizing an explicitly throughput-centric proxy metric, then separately introduces a deadlock-free routing scheme and reports geometric-mean speedups from simulation of the resulting topologies under uniform random and all-to-all traffic. No equation or claim reduces the reported simulation gains to the proxy value by construction, nor does any load-bearing step rely on a self-citation whose content is itself unverified or defined in terms of the target result. The separation between proxy optimization and post-routing simulation evaluation keeps the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[n. d.]. TPU v4. https://cloud.google.com/tpu/docs/v4. ([n. d.]). [Ac- cessed 11-09-2025]
2025
-
[2]
2026. TPU v5p. https://docs.cloud.google.com/tpu/docs/v5p. (2026). [Accessed 11-09-2025]
2026
-
[3]
Hussam Abu-Libdeh, Paolo Costa, Antony Rowstron, Greg O’Shea, and Austin Donnelly. 2010. Symbiotic routing in future data centers. InProceedings of the ACM SIGCOMM 2010 conference. 51–62
2010
-
[4]
Paul Barham, Aakanksha Chowdhery, Jeff Dean, Sanjay Ghemawat, Steven Hand, Daniel Hurt, Michael Isard, Hyeontaek Lim, Ruoming Pang, Sudip Roy, et al . 2022. Pathways: Asynchronous distributed dataflow for ml.Proceedings of Machine Learning and Systems4 (2022), 430–449
2022
-
[5]
Prithwish Basu, Liangyu Zhao, Jason Fantl, Siddharth Pal, Arvind Krishnamurthy, and Joud Khoury. 2024. Efficient all-to-all collective communication schedules for direct-connect topologies. InProceedings of the 33rd International Symposium on High-Performance Parallel and Distributed Computing. 28–41
2024
-
[6]
Maciej Besta and Torsten Hoefler. 2014. Slim fly: A cost effective low- diameter network topology. InSC’14: proceedings of the international conference for high performance computing, networking, storage and analysis. IEEE, 348–359
2014
-
[7]
Christian Bliek1ú, Pierre Bonami, and Andrea Lodi. 2014. Solving mixed-integer quadratic programming problems with IBM-CPLEX: a progress report. InProceedings of the twenty-sixth RAMP symposium. 16–17
2014
-
[9]
Jose M Camara, Miquel Moreto, Enrique Vallejo, Ramon Beivide, Jose Miguel-Alonso, Carmen Martínez, and Javier Navaridas. 2010. Twisted torus topologies for enhanced interconnection networks.IEEE Trans- actions on Parallel and Distributed Systems21, 12 (2010), 1765–1778
2010
-
[10]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradb...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Meghan Cowan, Saeed Maleki, Madanlal Musuvathi, Olli Saarikivi, and Yifan Xiong. 2023. Mscclang: Microsoft collective communication language. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2. 502–514
2023
-
[12]
Curtis, Tommy Carpenter, Mustafa Elsheikh, Alejandro López-Ortiz, and S
Andrew R. Curtis, Tommy Carpenter, Mustafa Elsheikh, Alejandro López-Ortiz, and S. Keshav. 2012. REWIRE: An optimization-based framework for unstructured data center network design. In2012 Pro- ceedings IEEE INFOCOM. 1116–1124. https://doi.org/10.1109/INFCOM. 2012.6195470
-
[13]
Dally and Seitz. 1987. Deadlock-Free Message Routing in Multipro- cessor Interconnection Networks.IEEE Trans. Comput.C-36, 5 (1987), 547–553. https://doi.org/10.1109/TC.1987.1676939
-
[14]
2004.Principles and practices of interconnection networks
William James Dally and Brian Patrick Towles. 2004.Principles and practices of interconnection networks. Elsevier
2004
-
[15]
Jens Domke, Torsten Hoefler, and Satoshi Matsuoka. 2016. Routing on the Dependency Graph: A New Approach to Deadlock-Free High- Performance Routing. InProceedings of the 25th ACM International Symposium on High-Performance Parallel and Distributed Computing (HPDC ’16). Association for Computing Machinery, New York, NY, USA, 3–14. https://doi.org/10.1145/2...
-
[16]
Jens Domke, Torsten Hoefler, and Wolfgang E. Nagel. 2011. Deadlock- Free Oblivious Routing for Arbitrary Topologies. In2011 IEEE In- ternational Parallel and Distributed Processing Symposium. 616–627. https://doi.org/10.1109/IPDPS.2011.65 17
-
[17]
Yuanyuan Dong, Eli V Olinick, T Jason Kratz, and David W Matula
-
[18]
A compact linear programming formulation of the maximum concurrent flow problem.Networks65, 1 (2015), 68–87
2015
-
[19]
J. Duato. 1995. A necessary and sufficient condition for deadlock-free adaptive routing in wormhole networks.IEEE Transactions on Parallel and Distributed Systems6, 10 (1995), 1055–1067. https://doi.org/10. 1109/71.473515
1995
-
[20]
Jack Edmonds. 1965. Maximum matching and a polyhedron with 0, 1-vertices.Journal of research of the National Bureau of Standards B69, 125-130 (1965), 55–56
1965
-
[21]
Anup Gangwar et. al. 2020. Automated Synthesis of Custom Networks- on-Chip for Real World Applications. InProceedings of the 39th Interna- tional Conference on Computer-Aided Design (ICCAD ’20). Association for Computing Machinery, New York, NY, USA, Article 41, 9 pages. https://doi.org/10.1145/3400302.3415656
- [22]
-
[23]
Natalie Enright Jerger et. al. 2014. NoC Architectures for Silicon Interposer Systems: Why Pay for more Wires when you Can Get them (from your interposer) for Free?. In2014 47th Annual IEEE/ACM International Symposium on Microarchitecture. 458–470. https://doi. org/10.1109/MICRO.2014.61
-
[24]
Sangeetha Abdu Jyothi et. al. 2016. Measuring and Understanding Throughput of Network Topologies. InSC ’16: Proceedings of the In- ternational Conference for High Performance Computing, Networking, Storage and Analysis. 761–772. https://doi.org/10.1109/SC.2016.64
-
[25]
Nathan Farrington, George Porter, Sivasankar Radhakrishnan, Hamid Hajabdolali Bazzaz, Vikram Subramanya, Yeshaiahu Fainman, George Papen, and Amin Vahdat. 2010. Helios: a hybrid electri- cal/optical switch architecture for modular data centers. InProceedings of the ACM SIGCOMM 2010 Conference. 339–350
2010
-
[26]
Yinxiao Feng, Yuchen Wei, Dong Xiang, and Kaisheng Ma. 2024. Eval- uating Chiplet-based Large-Scale Interconnection Networks via Cycle- Accurate Packet-Parallel Simulation. In2024 USENIX Annual Technical Conference (USENIX ATC 24). 731–747
2024
-
[27]
Jared Fernandez, Luca Wehrstedt, Leonid Shamis, Mostafa Elhoushi, Kalyan Saladi, Yonatan Bisk, Emma Strubell, and Jacob Kahn. 2025. Efficient Hardware Scaling and Diminishing Returns in Large-Scale Training of Language Models.Transactions on Machine Learning Re- search(2025)
2025
-
[28]
Christopher J. Glass and Lionel M. Ni. 1992. The Turn Model for Adap- tive Routing. InProceedings of the 19th Annual International Symposium on Computer Architecture (ISCA ’92). Association for Computing Ma- chinery, New York, NY, USA, 278–287. https://doi.org/10.1145/139669. 140384
-
[29]
Conor James Green and Mithuna Thottethodi. 2024. NetSmith: An Op- timization Framework for Machine-Discovered Network Topologies. InProceedings of the 53rd International Conference on Parallel Processing (ICPP ’24). Association for Computing Machinery, New York, NY, USA, 421–432. https://doi.org/10.1145/3673038.3673060
-
[30]
Hamilton, Navendu Jain, Srikanth Kandula, Changhoon Kim, Parantap Lahiri, David A
Albert Greenberg, James R. Hamilton, Navendu Jain, Srikanth Kandula, Changhoon Kim, Parantap Lahiri, David A. Maltz, Parveen Patel, and Sudipta Sengupta. 2009. VL2: A Scalable and Flexible Data Center Network. InProceedings of the ACM SIGCOMM 2009 Conference on Data Communication (SIGCOMM ’09). Association for Computing Ma- chinery, New York, NY, USA, 51–...
-
[31]
Chen Griner, Johannes Zerwas, Andreas Blenk, Manya Ghobadi, Stefan Schmid, and Chen Avin. 2021. Cerberus: The power of choices in datacenter topology design-a throughput perspective.Proceedings of the ACM on Measurement and Analysis of Computing Systems5, 3 (2021), 1–33
2021
-
[32]
Chuanxiong Guo, Guohan Lu, Dan Li, Haitao Wu, Xuan Zhang, Yun- feng Shi, Chen Tian, Yongguang Zhang, and Songwu Lu. 2009. BCube: a high performance, server-centric network architecture for modular data centers. InProceedings of the ACM SIGCOMM 2009 conference on Data communication. 63–74
2009
-
[33]
Chuanxiong Guo, Haitao Wu, Kun Tan, Lei Shi, Yongguang Zhang, and Songwu Lu. 2008. Dcell: a scalable and fault-tolerant network structure for data centers. InProceedings of the ACM SIGCOMM 2008 conference on Data communication. 75–86
2008
-
[34]
Gurobi Optimization, LLC. 2023. Gurobi Optimizer Reference Manual. (2023). https://www.gurobi.com
2023
-
[35]
László Gyarmati and Tuan Anh Trinh. 2010. Scafida: A scale-free network inspired data center architecture.ACM SIGCOMM Computer Communication Review40, 5 (2010), 4–12
2010
-
[36]
Juris Hartmanis. 1982. Computers and Intractability: A Guide to the Theory of NP-Completeness (Michael R. Garey and David S. Johnson). SIAM Rev.24, 1 (1982), 90–91. https://doi.org/10.1137/1024022
-
[37]
Joel Hestness and Stephen W Keckler. 2011. Netrace: Dependency- tracking traces for efficient network-on-chip experimentation.The University of Texas at Austin, Dept. of Computer Science, Tech. Rep (2011)
2011
-
[38]
Yuanfang Hu, Yi Zhu, Hongyu Chen, Ronald Graham, and Chung-Kuan Cheng. 2006. Communication latency aware low power NoC synthesis. InProceedings of the 43rd annual Design Automation Conference. 574– 579
2006
-
[39]
Jiayi Huang, Pritam Majumder, Sungkeun Kim, Abdullah Muzahid, Ki Hwan Yum, and Eun Jung Kim. 2021. Communication Algorithm- Architecture Co-Design for Distributed Deep Learning. In2021 ACM/IEEE 48th Annual International Symposium on Computer Archi- tecture (ISCA). 181–194. https://doi.org/10.1109/ISCA52012.2021.00023
-
[40]
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Dehao Chen, Mia Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V Le, Yonghui Wu, et al. 2019. Gpipe: Efficient training of giant neural networks using pipeline parallelism.Advances in neural information processing systems32 (2019)
2019
-
[41]
Imase and Itoh. 1983. A design for directed graphs with minimum diameter.IEEE Trans. Comput.100, 8 (1983), 782–784
1983
-
[42]
Chenyu Jiang, Ye Tian, Zhen Jia, Shuai Zheng, Chuan Wu, and Yida Wang. 2024. Lancet: Accelerating mixture-of-experts training via whole graph computation-communication overlapping.Proceedings of Machine Learning and Systems6 (2024), 74–86
2024
-
[43]
Becker, George Michelogiannakis, James Balfour, Brian Towles, D
Nan Jiang, Daniel U. Becker, George Michelogiannakis, James Balfour, Brian Towles, D. E. Shaw, John Kim, and William J. Dally. 2013. A detailed and flexible cycle-accurate Network-on-Chip simulator. In 2013 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS). 86–96. https://doi.org/10.1109/ISPASS.2013. 6557149
-
[44]
Yimin Jiang, Yibo Zhu, Chang Lan, Bairen Yi, Yong Cui, and Chuanx- iong Guo. 2020. A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20). USENIX Association, 463–479. https://www.usenix.org/conference/ osdi20/presentation/jiang
2020
-
[45]
Ziheng Jiang, Haibin Lin, Yinmin Zhong, Qi Huang, Yangrui Chen, Zhi Zhang, Yanghua Peng, Xiang Li, Cong Xie, Shibiao Nong, et al
-
[46]
In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24)
{MegaScale}: Scaling large language model training to more than 10,000 {GPUs }. In21st USENIX Symposium on Networked Systems Design and Implementation (NSDI 24). 745–760
-
[47]
Norm Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian 18 Towles, et al. 2023. Tpu v4: An optically reconfigurable supercom- puter for machine learning with hardware support for embeddings. In Proceedings of the 50th annual international symposium on computer architecture. 1–14
2023
-
[48]
Michael Jünger, Gerhard Reinelt, and Stefan Thienel. 1995. Practi- cal problem solving with cutting plane algorithms in combinatorial optimization.DIMACS series in discrete mathematics and theoretical computer science20, 1995 (1995), 111–152
1995
-
[49]
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Ben- jamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361(2020)
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[50]
W Kautz. 1968. Bounds on directed (d, k) graphs.Theory of cellular logic networks and machines, Final Report(1968), 20–28
1968
-
[51]
Tom Leighton and Satish Rao. 1999. Multicommodity max-flow min- cut theorems and their use in designing approximation algorithms.J. ACM46, 6 (Nov. 1999), 787–832. https://doi.org/10.1145/331524.331526
-
[52]
Hong Liu, Ryohei Urata, Kevin Yasumura, Xiang Zhou, Roy Bannon, Jill Berger, Pedram Dashti, Norm Jouppi, Cedric Lam, Sheng Li, et al. 2023. Lightwave fabrics: at-scale optical circuit switching for datacenter and machine learning systems. InProceedings of the ACM SIGCOMM 2023 Conference. 499–515
2023
-
[53]
Hong Liu, Ryohei Urata, Kevin Yasumura, Xiang Zhou, Roy Bannon, Jill Berger, Pedram Dashti, Norm Jouppi, Cedric Lam, Sheng Li, et al
-
[54]
In 2024 Optical Fiber Communications Conference and Exhibition (OFC)
Reconfigurable Lightwave Fabrics for ML Supercomputers. In 2024 Optical Fiber Communications Conference and Exhibition (OFC). IEEE, 1–3
2024
-
[55]
O. Lysne, T. Skeie, S.-A. Reinemo, and I. Theiss. 2006. Layered routing in irregular networks.IEEE Transactions on Parallel and Distributed Systems17, 1 (2006), 51–65. https://doi.org/10.1109/TPDS.2006.12
-
[56]
Ben Mann, Nick Ryder, Melanie Subbiah, J Kaplan, P Dhariwal, A Neelakantan, P Shyam, G Sastry, A Askell, S Agarwal, et al . 2020. Language models are few-shot learners.arXiv preprint arXiv:2005.14165 1, 3 (2020), 3
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[57]
Matula and Farhad Shahrokhi
David W. Matula and Farhad Shahrokhi. 1990. Sparsest cuts and bottlenecks in graphs.Discrete Applied Mathematics27, 1 (1990), 113–
1990
-
[58]
https://doi.org/10.1016/0166-218X(90)90133-W
-
[59]
William M Mellette, Rob McGuinness, Arjun Roy, Alex Forencich, George Papen, Alex C Snoeren, and George Porter. 2017. Rotornet: A scalable, low-complexity, optical datacenter network. InProceedings of the Conference of the ACM Special Interest Group on Data Communica- tion. 267–280
2017
-
[60]
AI Meta. 2025. The llama 4 herd: The beginning of a new era of natively multimodal ai innovation.https://ai. meta. com/blog/llama-4- multimodal-intelligence/, checked on4, 7 (2025), 2025
2025
-
[61]
Jayaram Mudigonda, Praveen Yalagandula, and Jeffrey C Mogul. 2011. Taming the flying cable monster: A topology design and optimiza- tion framework for {Data-Center} networks. In2011 USENIX Annual Technical Conference (USENIX ATC 11)
2011
-
[62]
Deepak Narayanan, Aaron Harlap, Amar Phanishayee, Vivek Seshadri, Nikhil R Devanur, Gregory R Ganger, Phillip B Gibbons, and Matei Zaharia. 2019. PipeDream: Generalized pipeline parallelism for DNN training. InProceedings of the 27th ACM symposium on operating sys- tems principles. 1–15
2019
-
[63]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGres- ley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, et al. 2021. Efficient large-scale language model training on gpu clusters using megatron- lm. InProceedings of the international conference for high performance computing, netwo...
2021
-
[64]
C St JA Nash-Williams. 1961. Edge-disjoint spanning trees of finite graphs.Journal of the London Mathematical Society1, 1 (1961), 445– 450
1961
-
[65]
Viet Hung Nguyen and Michel Minoux. 2021. Linear size MIP formu- lation of Max-Cut: new properties, links with cycle inequalities and computational results.Optimization Letters15, 4 (2021), 1041–1060
2021
-
[66]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ah- mad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[67]
Leon Poutievski, Omid Mashayekhi, Joon Ong, Arjun Singh, Mukar- ram Tariq, Rui Wang, Jianan Zhang, Virginia Beauregard, Patrick Con- ner, Steve Gribble, Rishi Kapoor, Stephen Kratzer, Nanfang Li, Hong Liu, Karthik Nagaraj, Jason Ornstein, Samir Sawhney, Ryohei Urata, Lorenzo Vicisano, Kevin Yasumura, Shidong Zhang, Junlan Zhou, and Amin Vahdat. 2022. Jupi...
-
[68]
Ragheb Rahmaniani, Teodor Gabriel Crainic, Michel Gendreau, and Walter Rei. 2017. The Benders decomposition algorithm: A literature review.European Journal of Operational Research259, 3 (2017), 801– 817
2017
-
[69]
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He
-
[70]
ZeRO: Memory Optimizations Toward Training Trillion Param- eter Models. (2020). arXiv:cs.LG/1910.02054 https://arxiv.org/abs/1910. 02054
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[71]
Graham, Paul Hilfinger, Dan Bonachea, Amir Kamil, Kaushik Datta, and J
Yves Robert, Sameer Shende, Allen Malony, Alan Morris, Wyatt Spear, Scott Biersdorff, Burton Smith, Dali Wang, Daniel Ricciuto, Wilfred Post, Michael Berry, François Irigoin, Katherine Yelick, S.L. Graham, Paul Hilfinger, Dan Bonachea, Amir Kamil, Kaushik Datta, and J. Moss. 2011.Encyclopedia of Parallel Computing. 2025–2029. https://doi.org/ 10.1007/978-...
-
[72]
Brandon Schlinker, Radhika Niranjan Mysore, Sean Smith, Jeffrey C Mogul, Amin Vahdat, Minlan Yu, Ethan Katz-Bassett, and Michael Rubin. 2015. Condor: Better topologies through declarative design. In Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication. 449–463
2015
-
[73]
1998.Theory of linear and integer programming
Alexander Schrijver. 1998.Theory of linear and integer programming. John Wiley & Sons
1998
-
[74]
Alexander Sergeev and Mike Del Balso. 2018. Horovod: fast and easy distributed deep learning in TensorFlow. (2018). arXiv:cs.LG/1802.05799 https://arxiv.org/abs/1802.05799
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[75]
Aashaka Shah, Vijay Chidambaram, Meghan Cowan, Saeed Maleki, Madan Musuvathi, Todd Mytkowicz, Jacob Nelson, Olli Saarikivi, and Rachee Singh. 2023. TACCL : Guiding Collective Algorithm Synthe- sis using Communication Sketches. In20th USENIX Symposium on Networked Systems Design and Implementation (NSDI 23). 593–612
2023
- [76]
-
[77]
Ji-Yong Shin, Bernard Wong, and Emin Gün Sirer. 2011. Small-world datacenters. InProceedings of the 2nd ACM Symposium on Cloud Com- puting (SOCC ’11). Association for Computing Machinery, New York, NY, USA, Article 2, 13 pages. https://doi.org/10.1145/2038916.2038918
-
[78]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. (2020). arXiv:cs.CL/1909.08053 https://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [79]
-
[80]
Arjun Singh, Joon Ong, Amit Agarwal, Glen Anderson, Ashby Armis- tead, Roy Bannon, Seb Boving, Gaurav Desai, Bob Felderman, Paulie Germano, et al. 2015. Jupiter rising: A decade of clos topologies and centralized control in google’s datacenter network.ACM SIGCOMM computer communication review45, 4 (2015), 183–197
2015
-
[81]
Brighten Godfrey, and Alexandra Kolla
Ankit Singla, P. Brighten Godfrey, and Alexandra Kolla. 2014. High Throughput Data Center Topology Design. In11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14). USENIX Association, Seattle, WA, 29–41. https://www.usenix.org/conference/ nsdi14/technical-sessions/presentation/singla
2014
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.