VoiceGiraffe: A Benchmark for Extreme Long-Context Audio-Language Understanding
Pith reviewed 2026-06-29 10:32 UTC · model grok-4.3
The pith
Audio language models struggle with persistent memory over hour-long real audio, especially tracking sparse events.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
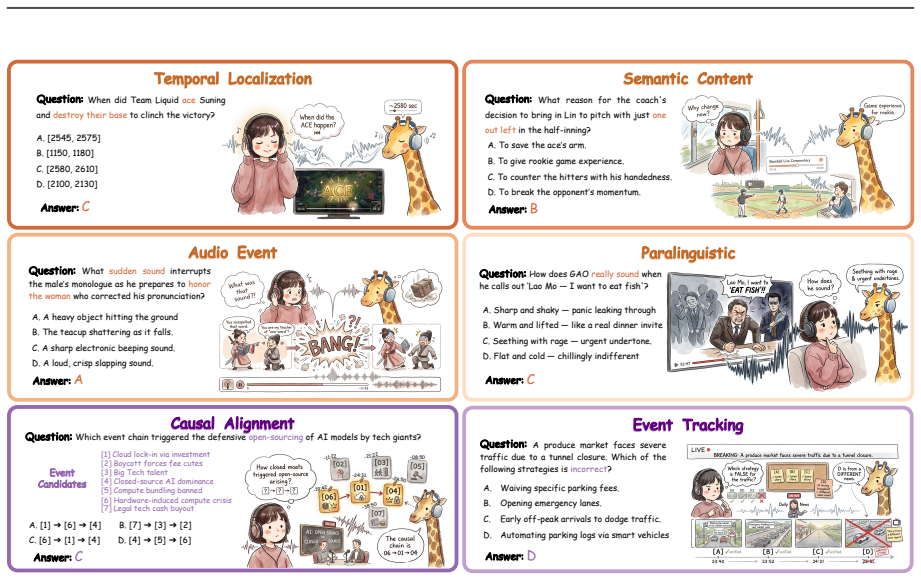
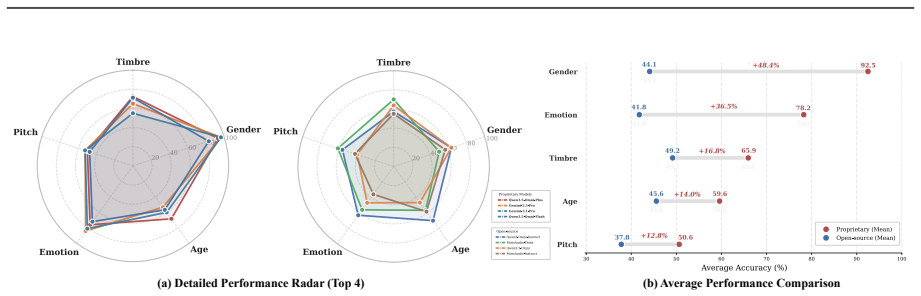
VoiceGiraffe is a benchmark of 1500 real-world audio triplets in a dual-level taxonomy of single-hop perception and multi-hop reasoning. It establishes that current LALMs are far from saturation on hour-scale understanding, that no inference paradigm dominates universally, and that long-range memory persistence forms the primary bottleneck because models connect salient causal cues more successfully than they sustain tracking of sparse events, a pattern opposite to human performance.
What carries the argument
VoiceGiraffe benchmark of 1500 curated triplets structured in a dual-level taxonomy of single-hop perception and multi-hop reasoning.
If this is right
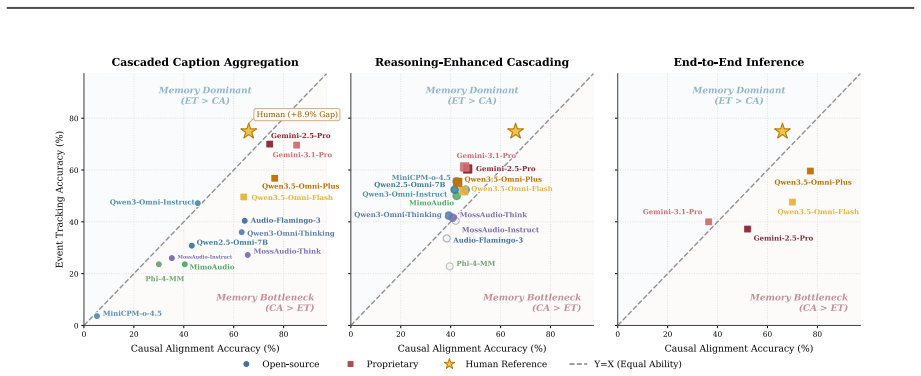
- No single inference method, whether end-to-end, cascaded caption aggregation, or reasoning-enhanced cascading, works best for every model size and type.
- LALMs need specific improvements in persistent memory to handle sparse events over long durations.
- Models currently perform better at connecting salient causal cues than at sustained tracking of sparse events.
- Human performance exhibits the opposite pattern from current models on these memory demands.
- The benchmark serves as a diagnostic testbed that can guide development of more capable long-form audio models.
Where Pith is reading between the lines
- Architectures that explicitly model event persistence rather than relying on general attention scaling could address the identified gap.
- Extending the dual-level taxonomy approach to video or multimodal long-context benchmarks would test whether the same memory pattern appears elsewhere.
- If the benchmark remains unsaturated after further model scaling, targeted memory mechanisms rather than scale alone would be required.
Load-bearing premise
The 1500 curated triplets faithfully assess LALM capacity for long-range information comprehension in real-world scenarios without artificial concatenation artifacts.
What would settle it
An LALM reaching or exceeding human accuracy on the multi-hop tasks that require sustained tracking of sparse events across full-length audio would show the memory persistence bottleneck has been resolved.
Figures


read the original abstract
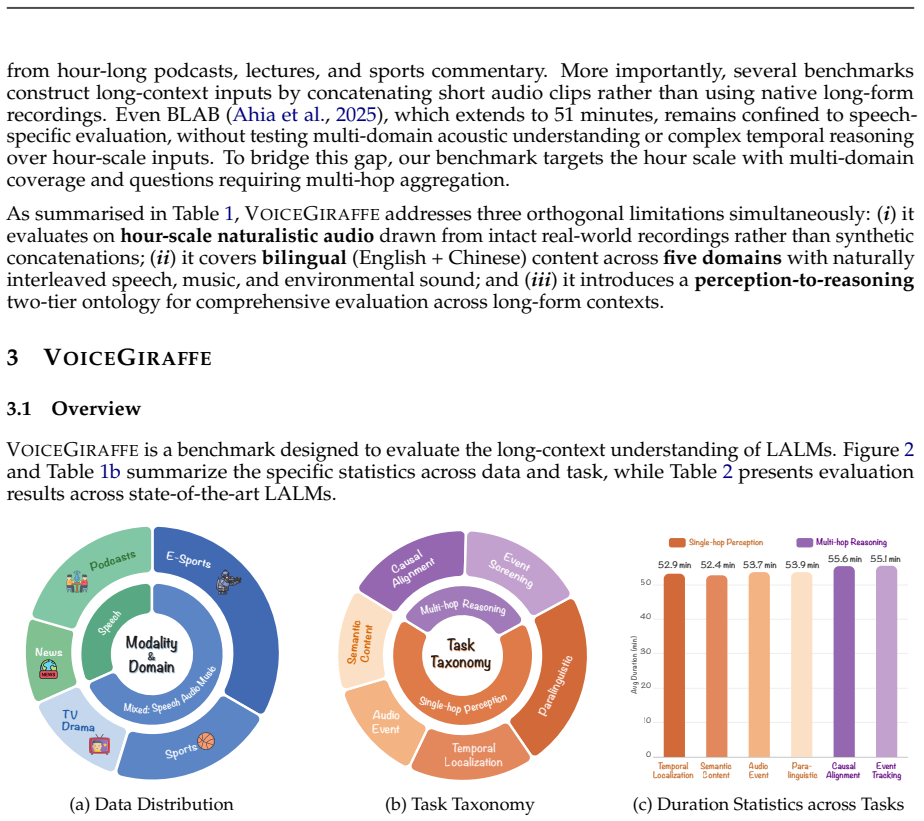
While large audio language models (LALMs) have achieved remarkable progress in audio processing at the second- or minute-level scale, understanding hour-level audio remains a fundamental bottleneck. Existing benchmarks predominantly rely on short clips or artificially concatenated segments, failing to faithfully assess LALM capacity for long-range information comprehension in real-world scenarios such as podcasts and lengthy speeches. To address this gap, we introduce VoiceGiraffe, a novel benchmark designed to rigorously evaluate LALMs across diverse real-world scenarios, modalities, and languages under long-context settings. It comprises 1500 curated triplets structured into a dual-level taxonomy of single-hop perception and multi-hop reasoning. We evaluate a broad suite of open-source and proprietary LALMs against human performance. Results underscore three fundamental findings. First, VoiceGiraffe remains highly challenging and far from saturation. Second, we show that no single inference paradigm universally dominates. The E2E inference benefits models with native long-context audio understanding, cascaded caption aggregation stabilizes small models overwhelmed by hour-scale audio, and reasoning-enhanced cascading with external LLM helps weaker models but can bottleneck stronger proprietary systems. Third, we reveal long-range memory persistence as a key bottleneck. LALMs are better at answering questions that require connecting salient causal cues than those requiring sustained tracking of sparse events across long audio, whereas humans show the opposite pattern. These findings position VoiceGiraffe as a challenging and diagnostic testbed for long-form audio understanding, highlighting the need for LALMs with persistent memory and robust long-range aggregation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VoiceGiraffe, a benchmark consisting of 1500 curated triplets drawn from real-world long-form audio (podcasts, speeches) and organized under a dual-level taxonomy of single-hop perception and multi-hop reasoning tasks. It evaluates a range of open-source and proprietary large audio-language models (LALMs) under multiple inference paradigms (E2E, cascaded caption aggregation, reasoning-enhanced cascading) against human performance, reporting that the benchmark remains challenging, that no inference paradigm dominates, and that long-range memory persistence is the primary bottleneck, with models performing better on salient causal cues than on sustained tracking of sparse events (the reverse of human patterns).
Significance. If the triplet curation and question design can be shown to enforce genuinely distributed long-range dependencies without artifacts, the benchmark would provide a valuable diagnostic resource for long-context audio understanding, moving beyond short-clip or concatenated-segment evaluations. The inclusion of human baselines and systematic comparison of inference strategies across model scales is a constructive contribution that could guide future LALM development toward persistent memory mechanisms.
major comments (3)
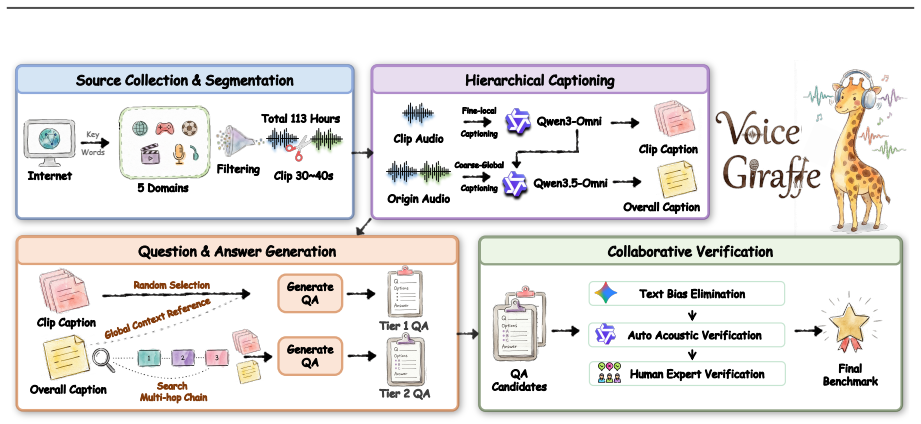
- [§3] §3 (Benchmark Construction / Triplet Curation): The manuscript provides insufficient detail on the curation pipeline for the 1500 triplets, including how questions were validated to require information distributed across full hour-scale durations rather than localized segments or concatenation artifacts. This is load-bearing for the central claim (abstract and §5) that long-range memory persistence is the key bottleneck and that models exhibit the opposite pattern from humans on sparse-event tracking versus salient cues.
- [§4, §5] §4 (Evaluation Setup) and §5 (Findings): The reported performance differences across inference paradigms and between models and humans lack statistical significance tests, confidence intervals, or inter-annotator agreement metrics for the human baseline. Without these, the conclusion that "no single inference paradigm universally dominates" and the diagnostic interpretation of the memory bottleneck cannot be rigorously assessed.
- [§3.2, §5.3] §3.2 and §5.3 (Taxonomy and Sparse-Event Analysis): The dual-level taxonomy does not supply explicit, reproducible criteria or annotated examples demonstrating that multi-hop questions enforce sustained tracking of sparse events across the entire audio rather than permitting solutions via salient local cues. This directly undermines the claim that observed model-human divergence reflects long-range memory deficits.
minor comments (2)
- [Abstract] Abstract: The phrase "dual-level taxonomy of single-hop perception and multi-hop reasoning" would benefit from a single concrete triplet example to clarify the distinction for readers.
- [Figure 1] Figure 1 / Table 1: Axis labels and legend entries for the inference-paradigm comparisons could be enlarged for readability in print.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. We agree that additional details and statistical rigor will strengthen the manuscript and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction / Triplet Curation): The manuscript provides insufficient detail on the curation pipeline for the 1500 triplets, including how questions were validated to require information distributed across full hour-scale durations rather than localized segments or concatenation artifacts. This is load-bearing for the central claim (abstract and §5) that long-range memory persistence is the key bottleneck and that models exhibit the opposite pattern from humans on sparse-event tracking versus salient cues.
Authors: We agree that the current description in §3 provides only high-level information on triplet curation and does not include sufficient explicit validation steps or examples to demonstrate that questions require truly distributed long-range dependencies. This is a valid concern for supporting the central claims. In the revised manuscript, we will expand §3 with a detailed curation pipeline description, including the specific criteria and procedures used to validate that questions necessitate information from across the full hour-scale audio (rather than local segments), along with several annotated examples of the validation process. revision: yes
-
Referee: [§4, §5] §4 (Evaluation Setup) and §5 (Findings): The reported performance differences across inference paradigms and between models and humans lack statistical significance tests, confidence intervals, or inter-annotator agreement metrics for the human baseline. Without these, the conclusion that "no single inference paradigm universally dominates" and the diagnostic interpretation of the memory bottleneck cannot be rigorously assessed.
Authors: We acknowledge that the manuscript reports performance numbers without accompanying statistical tests, confidence intervals, or inter-annotator agreement for the human baseline. This limits the rigor of the conclusions. We will revise §4 and §5 to include statistical significance tests (such as paired tests for paradigm and model comparisons), 95% confidence intervals, and inter-annotator agreement metrics (e.g., Fleiss' kappa) for the human evaluations. These additions will allow readers to better assess the reliability of the reported differences and the memory bottleneck interpretation. revision: yes
-
Referee: [§3.2, §5.3] §3.2 and §5.3 (Taxonomy and Sparse-Event Analysis): The dual-level taxonomy does not supply explicit, reproducible criteria or annotated examples demonstrating that multi-hop questions enforce sustained tracking of sparse events across the entire audio rather than permitting solutions via salient local cues. This directly undermines the claim that observed model-human divergence reflects long-range memory deficits.
Authors: We agree that §3.2 outlines the dual-level taxonomy at a high level but does not provide explicit, reproducible criteria or annotated examples to distinguish questions requiring sustained sparse-event tracking from those solvable via salient local cues. This weakens the interpretation of the model-human divergence. In the revision, we will add explicit classification criteria and multiple annotated examples (in §3.2 or an appendix) showing how specific multi-hop questions enforce long-range sparse-event tracking across the full audio duration. revision: yes
Circularity Check
No significant circularity; benchmark paper with empirical evaluations only
full rationale
The paper introduces VoiceGiraffe as a benchmark comprising 1500 curated triplets and reports empirical results from evaluating LALMs against human performance. No derivation chain, equations, fitted parameters presented as predictions, or self-citation load-bearing uniqueness theorems exist. Claims about bottlenecks (e.g., long-range memory persistence) are direct observations from the evaluation data rather than reductions to inputs by construction. The work is self-contained as a diagnostic testbed with external human comparisons.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras
Abdelrahman Abouelenin, Atabak Ashfaq, Adam Atkinson, Hany Awadalla, et al. Phi-4-mini technical report: Compact yet powerful multimodal language models via mixture-of-loras. CoRR, 2025
2025
-
[2]
BLAB: brutally long audio bench
Orevaoghene Ahia, Martijn Bartelds, Kabir Ahuja, Hila Gonen, Valentin Hofmann, et al. BLAB: brutally long audio bench. CoRR, 2025
2025
-
[3]
Pyannote.audio: Neural building blocks for speaker diarization
Herv \' e Bredin, Ruiqing Yin, Juan Manuel Coria, Gregory Gelly, Pavel Korshunov, Marvin Lavechin, Diego Fustes, Hadrien Titeux, Wassim Bouaziz, and Marie - Philippe Gill. Pyannote.audio: Neural building blocks for speaker diarization. In 2020 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2020, Barcelona, Spain, May 4-8,...
2020
-
[4]
Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models
Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shiliang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou. Qwen-audio: Advancing universal audio understanding via unified large-scale audio-language models. CoRR, 2023
2023
-
[5]
Qwen2-audio technical report
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuanjun Lv, Jinzheng He, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen2-audio technical report. CoRR, 2024
2024
-
[6]
Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha
Sreyan Ghosh, Sonal Kumar, Ashish Seth, Chandra Kiran Reddy Evuru, Utkarsh Tyagi, S. Sakshi, Oriol Nieto, Ramani Duraiswami, and Dinesh Manocha. GAMA: A large audio-language model with advanced audio understanding and complex reasoning abilities. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, EMNLP 2024, Miami, ...
2024
-
[7]
Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S. Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities. In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 , Proceedings...
2025
-
[8]
Audio flamingo 3: Advancing audio intelligence with fully open large audio language models
Arushi Goel, Sreyan Ghosh, Jaehyeon Kim, Sonal Kumar, Zhifeng Kong, Sang - gil Lee, Chao - Han Huck Yang, Ramani Duraiswami, Dinesh Manocha, Rafael Valle, and Bryan Catanzaro. Audio flamingo 3: Advancing audio intelligence with fully open large audio language models. CoRR, 2025
2025
-
[9]
Audiomarathon: A comprehensive benchmark for long-context audio understanding and efficiency in audio llms
Peize He, Zichen Wen, Yubo Wang, Yuxuan Wang, Xiaoqian Liu, Jiajie Huang, Zehui Lei, Zhuangcheng Gu, Xiangqi Jin, Jiabing Yang, Kai Li, Zhifei Liu, Weijia Li, Cunxiang Wang, Conghui He, and Linfeng Zhang. Audiomarathon: A comprehensive benchmark for long-context audio understanding and efficiency in audio llms. CoRR, 2025
2025
-
[10]
Baichuan-omni-1.5 technical report
Baichuan Inc. Baichuan-omni-1.5 technical report. CoRR, abs/2501.15368, 2025
-
[11]
Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities
Zhifeng Kong, Arushi Goel, Rohan Badlani, Wei Ping, Rafael Valle, and Bryan Catanzaro. Audio flamingo: A novel audio language model with few-shot learning and dialogue abilities. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 , Proceedings of Machine Learning Research, pages 25125--25148, 2024
2024
-
[12]
Chronosaudio: A comprehensive long-audio benchmark for evaluating audio-large language models
Kaiwen Luo, Liang Lin, Yibo Zhang, Moayad Aloqaily, Dexian Wang, Zhenhong Zhou, Junwei Zhang, Kun Wang, Li Sun, and Qingsong Wen. Chronosaudio: A comprehensive long-audio benchmark for evaluating audio-large language models. CoRR, 2026
2026
-
[13]
MMAR: A challenging benchmark for deep reasoning in speech, audio, music, and their mix
Ziyang Ma, Yinghao Ma, Yanqiao Zhu, Chen Yang, Yi - Wen Chao, et al. MMAR: A challenging benchmark for deep reasoning in speech, audio, music, and their mix. CoRR, 2025
2025
-
[14]
OpenAI. Gpt-4o system card. CoRR, abs/2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
OpenAI . Gpt-5.2. https://deploymentsafety.openai.com/gpt-5-2/introduction, 2025
2025
-
[16]
Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha
S. Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. MMAU: A massive multi-task audio understanding and reasoning benchmark. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 , 2025
2025
-
[17]
SALMONN: towards generic hearing abilities for large language models
Changli Tang, Wenyi Yu, Guangzhi Sun, Xianzhao Chen, Tian Tan, Wei Li, Lu Lu, Zejun Ma, and Chao Zhang. SALMONN: towards generic hearing abilities for large language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 , 2024
2024
-
[18]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities
Gemini Team. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. CoRR, 2025 a
2025
-
[19]
Moss-audio technical report
OpenMOSS Team. Moss-audio technical report. https://github.com/OpenMOSS/MOSS-Audio, 2026. GitHub repository
2026
-
[20]
Qwen3.5-omni technical report
Qwen Team. Qwen3.5-omni technical report. CoRR, 2025 b
2025
-
[21]
Qwen3-omni technical report
Qwen Team. Qwen3-omni technical report. CoRR, 2025 c
2025
-
[22]
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy F. Chen. Audiobench: A universal benchmark for audio large language models. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2025 - Volume 1:...
2025
-
[23]
Mimo-audio: Audio language models are few-shot learners
LLM - Core Xiaomi. Mimo-audio: Audio language models are few-shot learners. CoRR, 2025
2025
-
[24]
Qwen2.5-omni technical report
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report. CoRR, 2025
2025
-
[25]
Longspeech: A scalable benchmark for transcription, translation and understanding in long speech
Fei Yang, Xuanfan Ni, Renyi Yang, Jiahui Geng, Qing Li, Chenyang Lyu, Yichao Du, Longyue Wang, Weihua Luo, and Kaifu Zhang. Longspeech: A scalable benchmark for transcription, translation and understanding in long speech. CoRR, 2026
2026
-
[26]
Air-bench: Benchmarking large audio-language models via generative comprehension
Qian Yang, Jin Xu, Wenrui Liu, Yunfei Chu, Ziyue Jiang, et al. Air-bench: Benchmarking large audio-language models via generative comprehension. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024 , pages 1979--1998, 2024
2024
-
[27]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Salmonn-omni: A standalone speech LLM without codec injection for full-duplex conversation
Wenyi Yu, Siyin Wang, Xiaoyu Yang, Xianzhao Chen, Xiaohai Tian, Jun Zhang, Guangzhi Sun, Lu Lu, Yuxuan Wang, and Chao Zhang. Salmonn-omni: A standalone speech LLM without codec injection for full-duplex conversation. CoRR, 2025
2025
-
[29]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[30]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[31]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.