Efficient Shapley-Based Influence Attribution in Social Networks
Pith reviewed 2026-06-29 09:41 UTC · model grok-4.3
The pith
Shapley values allow fair ex-ante attribution of each seed's marginal contribution to expected influence spread in a social network.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adapting Shapley values to the influence propagation game yields a principled way to compute each seed's expected marginal contribution to the spread under a known diffusion model, with polynomial-time algorithms for single-step activation, #P-hardness for multi-step cases, and approximation algorithms for the independent cascade model.
What carries the argument
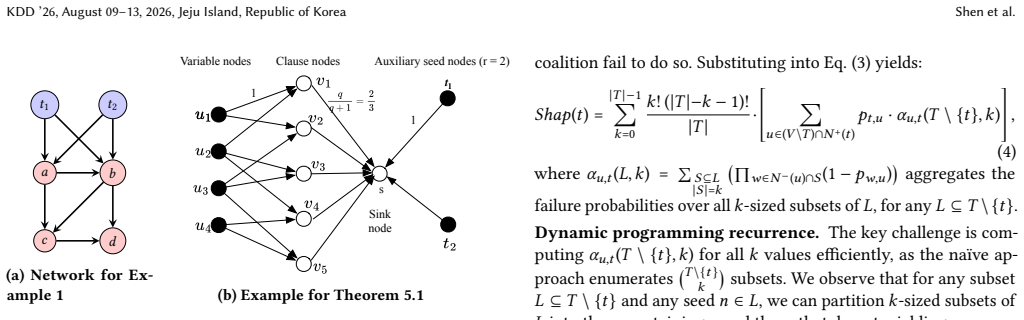
Shapley value computation in the cooperative game defined by seeds as players and the value function as the expected number of activated nodes under the diffusion model.
If this is right
- Budget allocation among potential influencers can be done fairly based on their expected contributions prior to any campaign launch.
- Credit distribution for influence can occur without sharing or observing private cascade data from actual runs.
- Algorithms exist that run in polynomial time when activation happens in one step, providing exact values.
- Approximation schemes with provable guarantees apply to standard independent cascade diffusion on general networks.
Where Pith is reading between the lines
- If the underlying diffusion probabilities are accurately estimated from data, the attributions should correlate with observed contributions in repeated simulations.
- This framework could extend to other stochastic processes where marginal contributions need to be attributed fairly without full observation.
- Combining with influence maximization techniques might allow selecting seeds while also planning their compensation in one optimization step.
Load-bearing premise
The exact probabilities governing how influence spreads along edges are known in advance and can be used to calculate expected spreads.
What would settle it
Simulate many diffusions from different seed subsets and check whether the average marginal contributions match the computed Shapley values; a systematic mismatch would indicate the method does not capture true marginal impacts.
Figures

read the original abstract
The ubiquity of social platforms has reshaped the way information, behaviors, and advertisements diffuse across networks, with influence propagation often initiated by a small set of ``seed'' users. While much of the literature emphasizes optimizing seed selection to maximize spread, a critical yet underexplored question remains: how to fairly estimate the contributions of individual seeds ``ex-ante'', i.e., before the diffusion process occurs? This capability is essential for budget allocation, influencer pricing, and fair, privacy-preserving credit distribution under uncertainty, without relying on ex-post cascade logs that capture only a single execution of influence propagation. We introduce a framework for ex-ante influence attribution based on Shapley values from cooperative game theory, which capture each seed's marginal impact in a principled and equitable manner. Adapting Shapley values to influence propagation raises unique computational challenges due to the stochastic nature of diffusion and the intricate dependencies across network structures. To address these challenges, we design polynomial-time algorithms for the special case of single-step activation that is of independent practical interest, establish a sharp tractability boundary by proving $\#P$-hardness for any propagation beyond one step, and develop approximation algorithms with provable guarantees for the standard IC model as well as time-bounded variants. Empirical evaluation on real-world and synthetic networks demonstrates that our methods are both efficient and effective, offering a practical mechanism for ex-ante influence attribution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a framework for ex-ante influence attribution in social networks based on Shapley values from cooperative game theory applied to an expected marginal-contribution game under a known diffusion model (e.g., Independent Cascade). It claims polynomial-time exact algorithms for the single-step activation case, a sharp #P-hardness result for any multi-step propagation, approximation algorithms with provable guarantees for the general IC model and time-bounded variants, and empirical validation showing efficiency and effectiveness on real-world and synthetic networks.
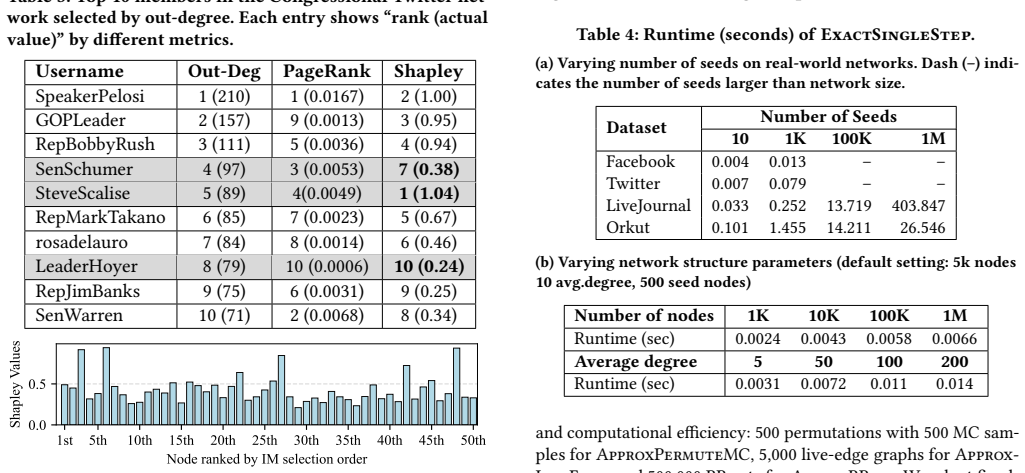
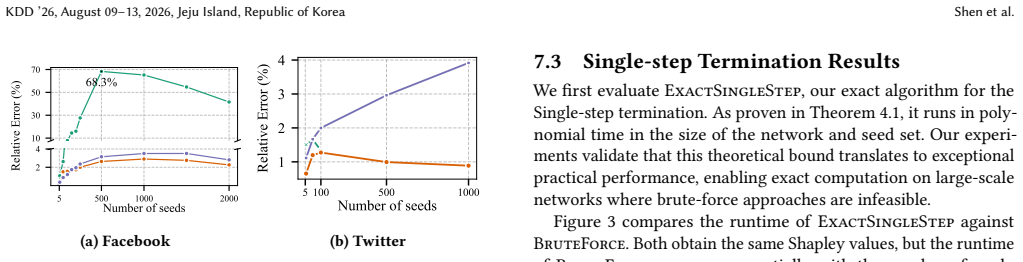
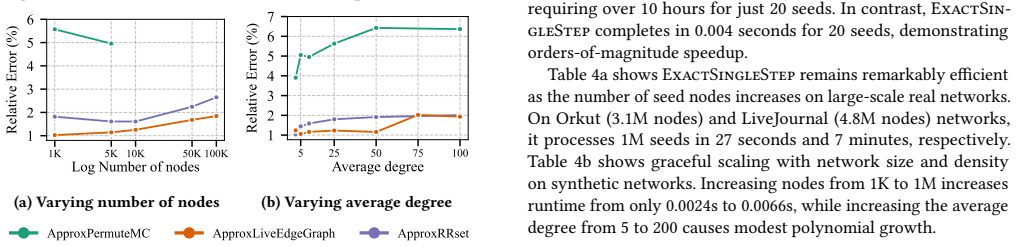
Significance. If the algorithmic claims and hardness boundary hold, the work supplies a principled, equitable method for attributing influence before any diffusion occurs. This directly supports applications in budget allocation, influencer pricing, and privacy-preserving credit assignment without requiring observed cascades. The explicit statement that edge probabilities are known a priori removes the circularity risk noted in the stress-test; the tractability boundary and approximation guarantees would be notable contributions to the influence maximization literature.
minor comments (1)
- [Abstract] Abstract: the phrase 'approximation algorithms with provable guarantees' would be more informative if the specific ratios or conditions (e.g., for the IC model) were stated explicitly rather than left at a high level.
Simulated Author's Rebuttal
We thank the referee for the positive review and the recommendation to accept. The summary accurately captures the paper's contributions on ex-ante Shapley-based influence attribution, the polynomial algorithms for single-step activation, the #P-hardness result, and the approximation algorithms for the IC model.
Circularity Check
No significant circularity identified
full rationale
The paper applies the standard definition of Shapley values to a cooperative game whose characteristic function is the expected influence spread under a known diffusion model (IC or similar). This is a direct, non-reductive use of the marginal-contribution definition on an externally specified game; the algorithmic results (poly-time for single-step activation, #P-hardness for multi-step, and approximation algorithms) are derived from network and stochastic-process properties rather than from any fitted parameter, self-referential equation, or self-citation chain. No load-bearing step reduces to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Shapley value is the unique fair allocation satisfying the standard axioms of cooperative games
- domain assumption The diffusion model (edge probabilities) is known and fixed before attribution
Reference graph
Works this paper leans on
-
[1]
Selahattin Akkas and Ariful Azad. 2024. Gnnshap: Scalable and accurate gnn explanation using shapley values. InProceedings of the ACM Web Conference 2024. 827–838
2024
-
[2]
Marcelo Arenas, Pablo Barceló, Leopoldo Bertossi, and Mikaël Monet. 2021. The tractability of SHAP-score-based explanations for classification over deterministic and decomposable boolean circuits. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 6670–6678
2021
-
[3]
Roland Bacher. 2002. Determinants of matrices related to the Pascal triangle. Journal de théorie des nombres de Bordeaux14, 1 (2002), 19–41
2002
-
[4]
Lars Backstrom, Dan Huttenlocher, Jon Kleinberg, and Xiangyang Lan. 2006. Group formation in large social networks: membership, growth, and evolution. InProceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. 44–54
2006
-
[5]
Phillip Bonacich. 1972. Factoring and weighting approaches to status scores and clique identification.Journal of mathematical sociology2, 1 (1972), 113–120
1972
-
[6]
Christian Borgs, Michael Brautbar, Jennifer Chayes, and Brendan Lucier. 2014. Maximizing social influence in nearly optimal time. InProceedings of the twenty- fifth annual ACM-SIAM symposium on Discrete algorithms. SIAM, 946–957
2014
-
[7]
Sergey Brin and Lawrence Page. 1998. The anatomy of a large-scale hypertextual web search engine.Computer networks and ISDN systems30, 1-7 (1998), 107–117
1998
-
[8]
Mark Alexander Burgess and Archie C Chapman. 2021. Approximating the Shapley Value Using Stratified Empirical Bernstein Sampling.. InIJCAI. 73–81
2021
-
[9]
Javier Castro, Daniel Gómez, and Juan Tejada. 2009. Polynomial calculation of the Shapley value based on sampling.Computers & Operations Research36, 5 (2009), 1726–1730
2009
-
[10]
Wei Chen and Shang-Hua Teng. 2017. Interplay between social influence and network centrality: A comparative study on shapley centrality and single-node- influence centrality. InProceedings of the 26th international conference on world wide web. 967–976
2017
-
[11]
Wei Chen, Chi Wang, and Yajun Wang. 2010. Scalable influence maximization for prevalent viral marketing in large-scale social networks. InProceedings of KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Shen et al. the 16th ACM SIGKDD international conference on Knowledge discovery and data mining. 1029–1038
2010
-
[12]
Xiaolong Chen, Yifan Song, and Jing Tang. 2024. Link recommendation to augment influence diffusion with provable guarantees. InProceedings of the ACM Web Conference 2024. 2509–2518
2024
-
[13]
Fan Chung and Linyuan Lu. 2006. Concentration inequalities and martingale inequalities: a survey.Internet mathematics3, 1 (2006), 79–127
2006
-
[14]
dblp Team. 2025. dblp computer science bibliography – Monthly Snapshot XML Release of April 2025. doi:10.4230/dblp.xml.2025-04-01
-
[15]
Erik D Demaine, MohammadTaghi Hajiaghayi, Hamid Mahini, David L Malec, S Raghavan, Anshul Sawant, and Morteza Zadimoghadam. 2014. How to influence people with partial incentives. InProceedings of the 23rd international conference on World wide web. 937–948
2014
-
[16]
Daniel Deutch, Nave Frost, Amir Gilad, and Oren Sheffer. 2021. Explanations for data repair through shapley values. InProceedings of the 30th ACM International Conference on Information & Knowledge Management. 362–371
2021
-
[17]
Daniel Deutch, Nave Frost, Benny Kimelfeld, and Mikaël Monet. 2022. Comput- ing the Shapley Value of Facts in Query Answering. InProceedings of the 2022 International Conference on Management of Data. 1570–1583
2022
-
[18]
Pedro Domingos and Matt Richardson. 2001. Mining the network value of customers. InProceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining. 57–66
2001
-
[19]
P ERDdS and A R&wi. 1959. On random graphs I.Publ. math. debrecen6, 290-297 (1959), 18
1959
-
[20]
Christian G Fink, Kelly Fullin, Guillermo Gutierrez, Nathan Omodt, Sydney Zinnecker, Gina Sprint, and Sean McCulloch. 2023. A centrality measure for quantifying spread on weighted, directed networks.Physica A: Statistical Me- chanics and its Applications626 (2023), 129083
2023
-
[21]
Christian G Fink, Nathan Omodt, Sydney Zinnecker, and Gina Sprint. 2023. A Congressional Twitter network dataset quantifying pairwise probability of influence.Data in Brief50 (2023), 109521
2023
-
[22]
Linton C Freeman. 1978. Centrality in social networks conceptual clarification. Social networks1, 3 (1978), 215–239
1978
-
[23]
Daniel Fryer, Inga Strümke, and Hien Nguyen. 2021. Shapley values for feature selection: The good, the bad, and the axioms.Ieee Access9 (2021), 144352–144360
2021
-
[24]
Noemi Gasko, Tamás Képes, Rodica Ioana Lung, and Mihai Suciu. 2023. Iden- tification of influential nodes with shapley influence maximization extremal optimization algorithm.Applied Soft Computing146 (2023), 110653
2023
-
[25]
Amirata Ghorbani and James Zou. 2019. Data shapley: Equitable valuation of data for machine learning. InInternational conference on machine learning. PMLR, 2242–2251
2019
-
[26]
Rumi Ghosh, Shang-hua Teng, Kristina Lerman, and Xiaoran Yan. 2014. The interplay between dynamics and networks: centrality, communities, and cheeger inequality. InProceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 1406–1415
2014
-
[27]
Wassily Hoeffding. 1963. Probability inequalities for sums of bounded random variables.Journal of the American statistical association58, 301 (1963), 13–30
1963
-
[28]
Ruoxi Jia, David Dao, Boxin Wang, Frances Ann Hubis, Nick Hynes, Nezihe Merve Gürel, Bo Li, Ce Zhang, Dawn Song, and Costas J Spanos. 2019. Towards efficient data valuation based on the shapley value. InThe 22nd International Conference on Artificial Intelligence and Statistics. PMLR, 1167–1176
2019
-
[29]
Ahmet Kara, Dan Olteanu, and Dan Suciu. 2024. From Shapley Value to Model Counting and Back.Proceedings of the ACM on Management of Data2, 2 (2024), 1–23
2024
-
[30]
David Kempe, Jon Kleinberg, and Éva Tardos. 2003. Maximizing the spread of influence through a social network. InProceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining. 137–146
2003
-
[31]
Jinha Kim, Seung-Keol Kim, and Hwanjo Yu. 2013. Scalable and parallelizable processing of influence maximization for large-scale social networks?. In2013 IEEE 29th international conference on data engineering (ICDE). IEEE, 266–277
2013
-
[32]
Masahiro Kimura and Kazumi Saito. 2006. Tractable models for information diffusion in social networks. InEuropean conference on principles of data mining and knowledge discovery. Springer, 259–271
2006
-
[33]
Jure Leskovec, Andreas Krause, Carlos Guestrin, Christos Faloutsos, Jeanne Van- Briesen, and Natalie Glance. 2007. Cost-effective outbreak detection in networks. InProceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD). ACM, 420–429
2007
-
[34]
Jure Leskovec, Kevin J Lang, Anirban Dasgupta, and Michael W Mahoney. 2009. Community structure in large networks: Natural cluster sizes and the absence of large well-defined clusters.Internet Mathematics6, 1 (2009), 29–123
2009
-
[35]
Jure Leskovec and Julian Mcauley. 2012. Learning to discover social circles in ego networks.Advances in neural information processing systems25 (2012)
2012
-
[36]
Ester Livshits, Leopoldo Bertossi, Benny Kimelfeld, and Moshe Sebag. 2021. The Shapley value of tuples in query answering.Logical Methods in Computer Science 17 (2021)
2021
-
[37]
Ester Livshits and Benny Kimelfeld. 2022. The Shapley value of inconsistency measures for functional dependencies.Logical Methods in Computer Science18 (2022)
2022
-
[38]
Scott M Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions.Advances in neural information processing systems30 (2017)
2017
-
[39]
Tomasz P Michalak, Karthik V Aadithya, Piotr L Szczepanski, Balaraman Ravin- dran, and Nicholas R Jennings. 2013. Efficient computation of the Shapley value for game-theoretic network centrality.Journal of Artificial Intelligence Research 46 (2013), 607–650
2013
-
[40]
Rory Mitchell, Joshua Cooper, Eibe Frank, and Geoffrey Holmes. 2022. Sampling permutations for shapley value estimation.Journal of Machine Learning Research 23, 43 (2022), 1–46
2022
-
[41]
Ramasuri Narayanam and Yadati Narahari. 2011. A Shapley Value-Based Ap- proach to Discover Influential Nodes in Social Networks.IEEE Transactions on Automation Science and Engineering8, 1 (2011), 130–147. doi:10.1109/TASE.2010. 2052042
-
[42]
Junyuan Pang, Jian Pei, Haocheng Xia, Xiang Li, and Jinfei Liu. 2025. Shap- ley Value Estimation based on Differential Matrix.Proceedings of the ACM on Management of Data3, 1 (2025), 1–28
2025
-
[43]
Alon Reshef, Benny Kimelfeld, and Ester Livshits. 2020. The impact of negation on the complexity of the Shapley value in conjunctive queries. InProceedings of the 39th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems. 285–297
2020
-
[44]
Lloyd S Shapley et al. 1953. A value for n-person games. (1953)
1953
-
[45]
Raghav Singal, Omar Besbes, Antoine Desir, Vineet Goyal, and Garud Iyengar
-
[46]
InThe world wide web conference
Shapley meets uniform: An axiomatic framework for attribution in online advertising. InThe world wide web conference. 1713–1723
-
[47]
Youze Tang, Yanchen Shi, and Xiaokui Xiao. 2015. Influence maximization in near-linear time: A martingale approach. InProceedings of the 2015 ACM SIGMOD international conference on management of data. 1539–1554
2015
-
[48]
Youze Tang, Xiaokui Xiao, and Yanchen Shi. 2014. Influence maximization: Near- optimal time complexity meets practical efficiency. InProceedings of the 2014 ACM SIGMOD international conference on Management of data. 75–86
2014
-
[49]
Leslie G. Valiant. 1979. The Complexity of Enumeration and Reliability Problems. SIAM J. Comput.8 (Aug. 1979), 410–421. doi:10.1137/0208032
-
[50]
Guy Van den Broeck, Anton Lykov, Maximilian Schleich, and Dan Suciu. 2022. On the tractability of SHAP explanations.Journal of Artificial Intelligence Research 74 (2022), 851–886
2022
-
[51]
Jaewon Yang and Jure Leskovec. 2012. Defining and evaluating network commu- nities based on ground-truth. InProceedings of the ACM SIGKDD workshop on mining data semantics. 1–8
2012
-
[52]
Jiayao Zhang, Qiheng Sun, Jinfei Liu, Li Xiong, Jian Pei, and Kui Ren. 2023. Efficient sampling approaches to shapley value approximation.Proceedings of the ACM on Management of Data1, 1 (2023), 1–24
2023
-
[53]
Yuqing Zhu, Jing Tang, Xueyan Tang, and Lei Chen. 2021. Analysis of influence contribution in social advertising.Proceedings of the VLDB Endowment15, 2 (2021), 348–360. A Details From Section 3 Shapley Values.Given a set of players 𝑁 and a value (or utility) function 𝑈 : 2𝑁 →R with 𝑈 (∅) = 0, where 𝑈 (𝑆)denotes the value raised by the subset 𝑆 of players,...
2021
-
[54]
𝜽 ′∑︁ 𝑗=1 𝜔(𝑹 (1) 𝑗 ) # −E[𝜽 ′]·𝐸𝑃𝑇= 0(159) KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Shen et al. Rearranging: E
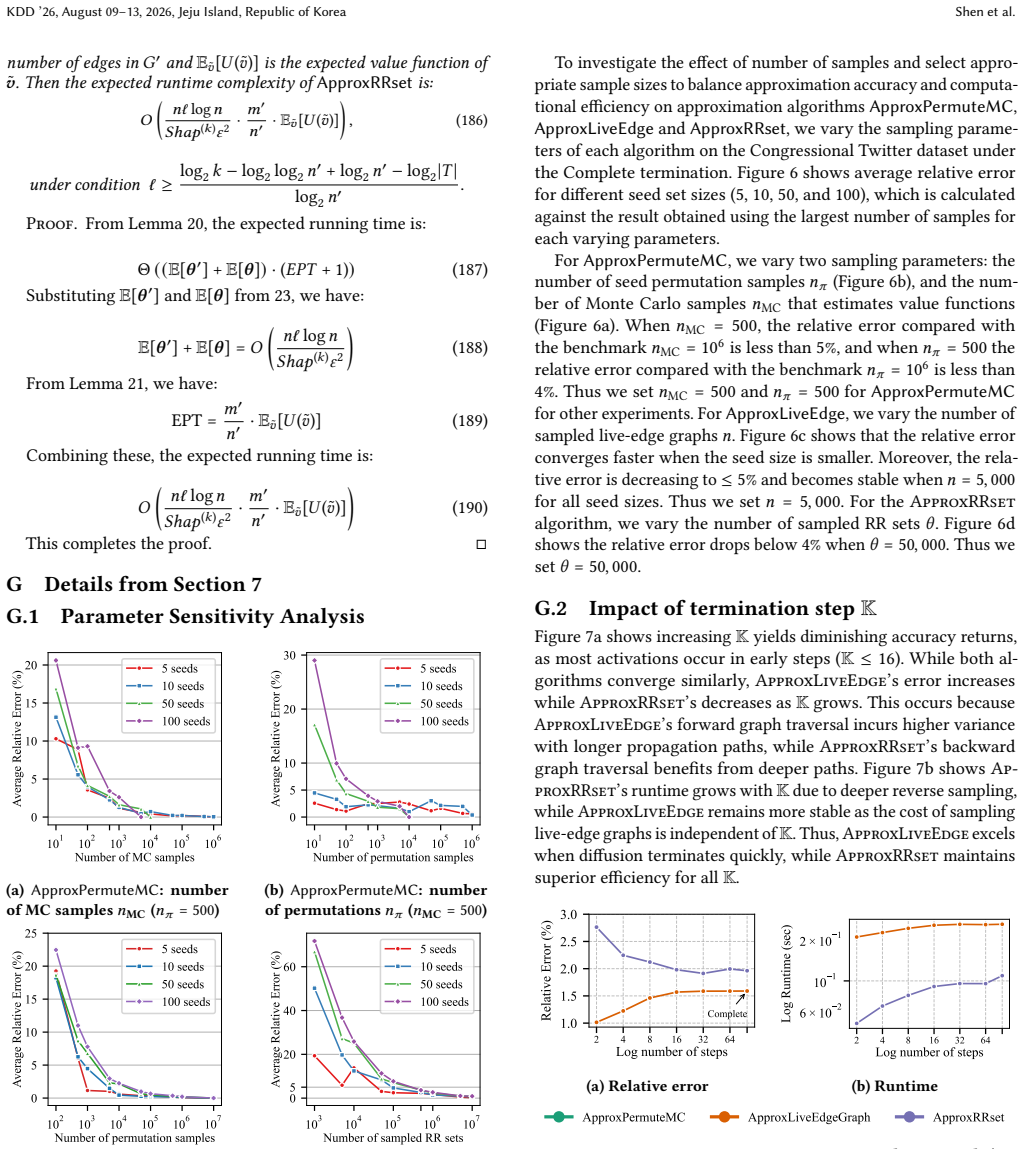
but with adjustment to our problem setting. Lemma 12.For any 𝑆⊆𝑇 and any 𝑣∈𝑉\𝑇 , denote 𝑹𝑣 as an RR set for 𝑣 in 𝐺 ′. The probability that 𝑹𝑣 intersects 𝑆 equals to the probability that 𝑆 activates 𝑣 in an influence propagation process on 𝐺: Pr[𝑆∩𝑹 𝑣 ̸=∅] = Pr[𝑆activates𝑣in𝐺](97) Proof. Let 𝑔 be a live-edge graph obtained by removing each edge 𝑒 with1 −𝑝 ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.