Resource Allocation in HyperX Networks
Pith reviewed 2026-06-29 09:55 UTC · model grok-4.3
The pith
The non-convex diagonal allocation strategy outperforms traditional resource allocations in HyperX networks by improving partition bandwidth and switch locality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
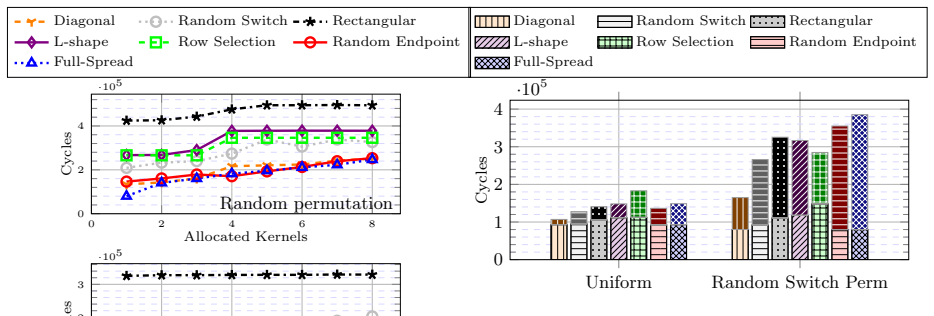
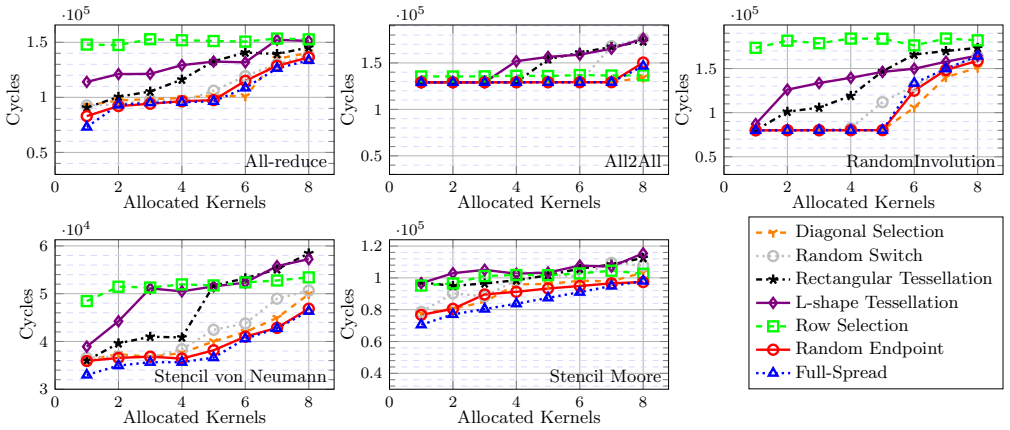
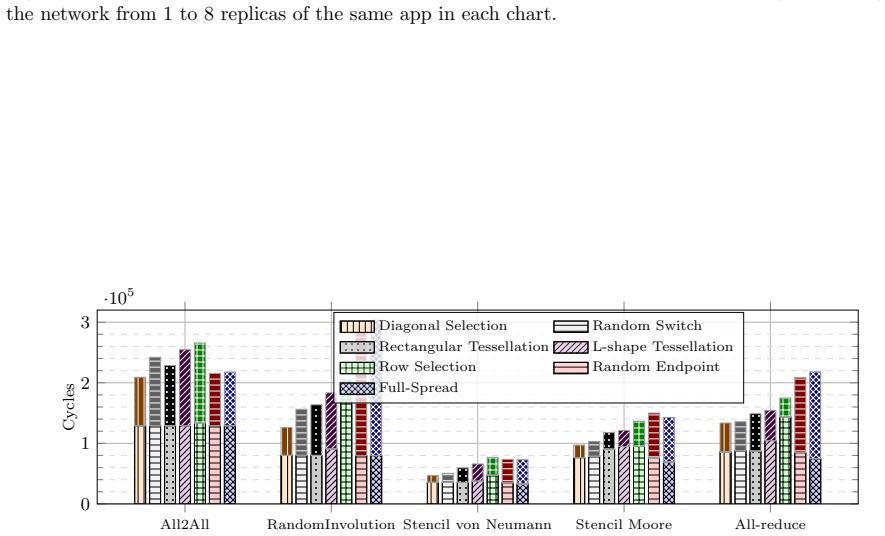
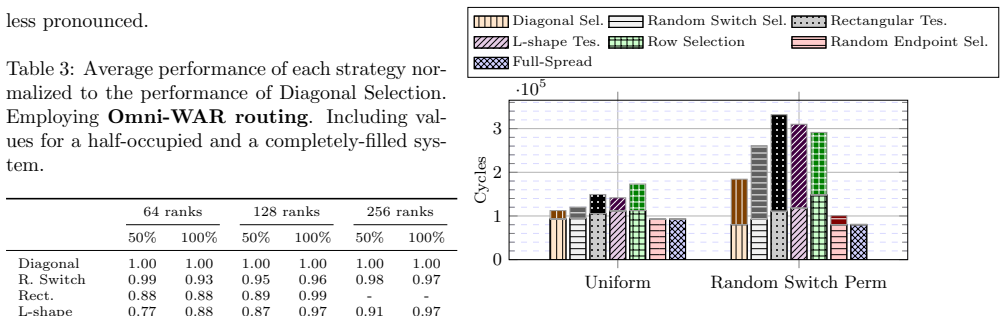
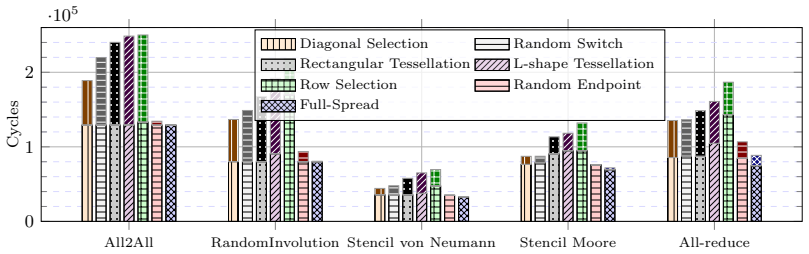
Resource allocation strategies for HyperX networks are categorized into linear, geometric, and stochastic functions. Theoretical characterization of their topological properties shows that the diagonal allocation, which is not convex, yields higher partition bandwidth and better switch locality than convex alternatives. Exhaustive evaluation under synthetic traffic and application kernels confirms that these properties reduce interference and improve performance for multiple routing algorithms.
What carries the argument
The diagonal allocation strategy, a geometric mapping function that places processes along network diagonals to increase locality.
If this is right
- Partition bandwidth is a decisive factor that mitigates interferences more effectively than convexity alone.
- Switch locality influences performance outcomes under different routing algorithms.
- A set of lessons learned can guide the design of resource allocation policies for HyperX-based HPC systems.
- Geometric strategies can be superior to linear or stochastic ones when evaluated on realistic kernels.
Where Pith is reading between the lines
- The same diagonal mapping idea could be tested on other richly connected low-diameter topologies to check whether non-convexity is broadly beneficial.
- If the diagonal strategy scales with network size, it may reduce the need for custom routing optimizations in future HyperX deployments.
- Production schedulers could incorporate a quick diagonal pre-mapping step before launching jobs to gain immediate locality benefits.
Load-bearing premise
The synthetic traffic patterns and application communication kernels used in the evaluation represent the workloads that arise in actual HyperX deployments.
What would settle it
A direct measurement of communication time or throughput on a real HyperX system running production applications, comparing the diagonal strategy against linear and convex geometric baselines under the same routing algorithm.
Figures


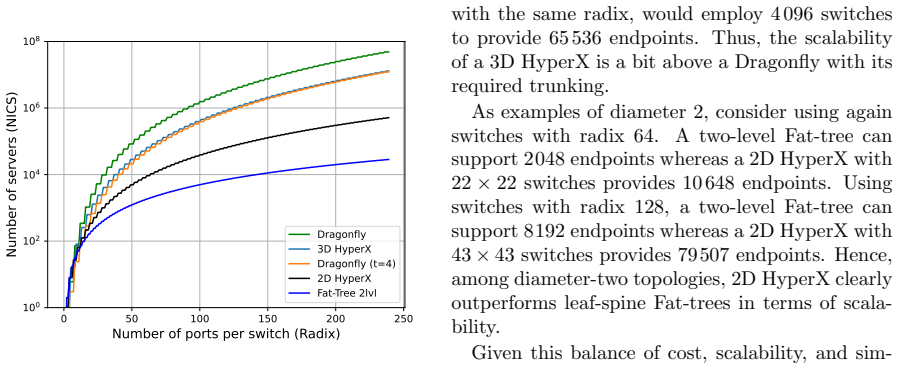
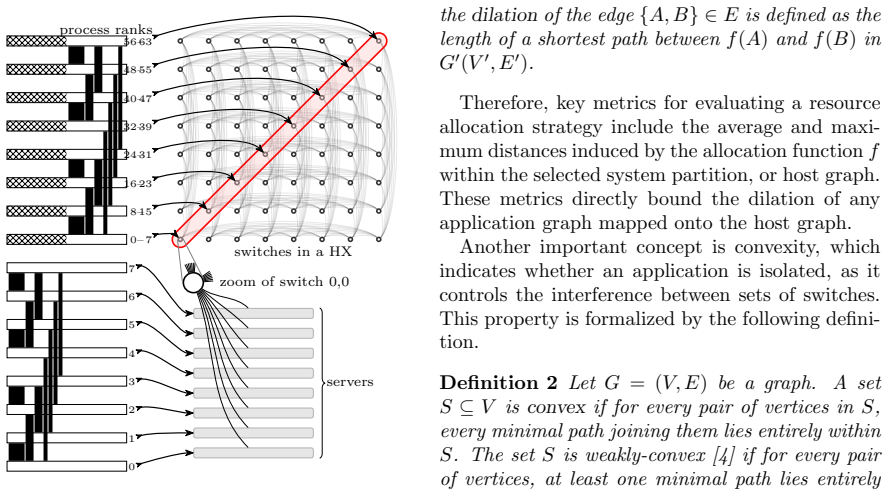
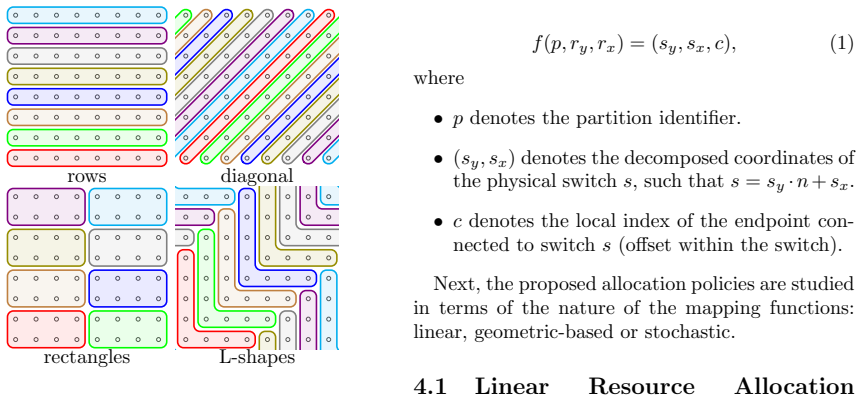
read the original abstract
As high-performance computing systems scale in size and complexity, efficient resource management is essential to minimize communication overhead. The HyperX is a richly connected, low-diameter network that offers a scalable and cost-effective alternative to traditional topologies. However, resource allocation in HyperX remains underexplored, and strategies designed for networks like Torus, Fat-tree, or Dragonfly do not directly transfer. In this work, we propose and formalize several resource allocation strategies for HyperX networks, categorized into linear, geometric, and stochastic functions. We characterize these strategies theoretically by analyzing their topological properties, including dilation, convexity, and partition bandwidth.Furthermore, we conduct an exhaustive experimental evaluation using synthetic traffic and application communication kernels to assess the impact of these strategies on performance under different routing algorithms. Our results indicate that partition bandwidth and switch locality are decisive factors in mitigating interferences. Notably, the Diagonal allocation strategy, which is not convex, consistently outperforms traditional approaches in most scenarios. Finally, we provide a set of lessons learned to guide the implementation of resource allocation policies in HPC systems based on HyperX networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes and formalizes resource allocation strategies for HyperX networks, categorized into linear, geometric, and stochastic functions. It characterizes these strategies theoretically via topological properties including dilation, convexity, and partition bandwidth. An exhaustive experimental evaluation using synthetic traffic patterns and application communication kernels under different routing algorithms finds that partition bandwidth and switch locality are decisive in mitigating interference, and that the non-convex Diagonal strategy consistently outperforms traditional approaches in most scenarios. Lessons learned for HPC implementations are provided.
Significance. If the empirical ranking holds, the work fills a gap in HyperX resource allocation by showing that convexity is not required for strong performance and by identifying partition bandwidth as a key factor. The combination of theoretical analysis and evaluation across routing algorithms could inform allocation policies in large-scale systems. Credit is due for the exhaustive experimental design and the explicit categorization of strategies.
major comments (1)
- [Experimental Evaluation] Experimental Evaluation section: The central claim that the Diagonal allocation strategy 'consistently outperforms traditional approaches in most scenarios' (abstract) is demonstrated exclusively on synthetic traffic patterns and application kernels. No argument, mapping, or sensitivity analysis is provided to establish that these patterns produce interference behaviors representative of production HyperX deployments; this directly affects whether the reported superiority and the decisiveness of partition bandwidth/switch locality generalize.
minor comments (2)
- [Abstract] Abstract: Reports experimental outcomes but provides no quantitative metrics, error bars, number of runs, or exclusion criteria, reducing the ability to assess result robustness from the summary alone.
- Notation for the three categories (linear, geometric, stochastic) and the specific Diagonal strategy is introduced without early formal definitions or pseudocode, which would aid readability before the theoretical analysis.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the exhaustive experimental design. We address the single major comment point by point below.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation section: The central claim that the Diagonal allocation strategy 'consistently outperforms traditional approaches in most scenarios' (abstract) is demonstrated exclusively on synthetic traffic patterns and application kernels. No argument, mapping, or sensitivity analysis is provided to establish that these patterns produce interference behaviors representative of production HyperX deployments; this directly affects whether the reported superiority and the decisiveness of partition bandwidth/switch locality generalize.
Authors: We agree that the manuscript provides no explicit argument, mapping, or sensitivity analysis connecting the chosen synthetic patterns and kernels to interference behaviors in actual production HyperX deployments. The evaluation relies on standard HPC traffic models (uniform random, bit-reversal, and application kernels) that are widely used to isolate partition-bandwidth and locality effects. To address the concern, we will revise the Experimental Evaluation section by adding a dedicated paragraph that (1) cites prior literature validating these patterns for high-radix network studies and (2) reports a limited sensitivity sweep over traffic intensity and locality parameters. This addition will clarify the intended scope of generalization while leaving the reported rankings and the identified importance of partition bandwidth unchanged. revision: partial
Circularity Check
No circularity detected; claims rest on independent theoretical analysis and experiments
full rationale
The paper proposes and formalizes allocation strategies, then characterizes them via topological properties (dilation, convexity, partition bandwidth) and evaluates performance experimentally on synthetic traffic and kernels. No equations, fitted parameters, or self-citations are shown that reduce any reported result or prediction to the inputs by construction. The Diagonal strategy outperformance is presented as an empirical observation from the evaluation suite, not a fitted or self-defined quantity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The intel programmable and integrated unified memory architecture graph analytics processor.IEEE Micro, 43(5):78–87, 2023
Sriram Aananthakrishnan, Shamsul Abe- din, Vincent Cav´ e, Fabio Checconi, Kristof Du Bois, Stijn Eyerman, Joshua B Fryman, Wim Heirman, Jason Howard, Ibrahim Hur, et al. The intel programmable and integrated unified memory architecture graph analytics processor.IEEE Micro, 43(5):78–87, 2023
2023
-
[2]
Schreiber
Jung Ho Ahn, Nathan Binkert, Al Davis, Moray McLaren, and Robert S. Schreiber. Hy- perX: Topology, routing, and packaging of ef- ficient large-scale networks. InProceedings of the Conference on High Performance Comput- ing Networking, Storage and Analysis, SC ’09, pages 1–11, New York, NY, USA, 2009. ACM
2009
-
[3]
Aleliunas and A.L
R. Aleliunas and A.L. Rosenberg. On embed- ding rectangular grids in square grids.IEEE Transactions on Computers, 31(09):907–913, September 1982
1982
-
[4]
Revisiting the outer-weakly convex domination number in graph products
Bijo S Anand, Jonecis A Dayap, Leomarich F Casinillo, Karen Luz P Yap, et al. Re- visiting the outer-weakly convex domination number in graph products.arXiv preprint arXiv:2501.15524, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Bhuyan and Dharma P
Laxmi N. Bhuyan and Dharma P. Agrawal. Generalized hypercube and hyperbus struc- tures for a computer network.Computers, IEEE Transactions on, C-33(4):323–333, April 1984
1984
-
[6]
Cam- bridge university press, 1993
Norman Biggs.Algebraic graph theory. Cam- bridge university press, 1993
1993
-
[7]
Achiev- ing high-performance fault-tolerant routing in HyperX interconnection networks
Crist´ obal Camarero, Alejandro Cano, Car- men Mart´ ınez, and Ram´ on Beivide. Achiev- ing high-performance fault-tolerant routing in HyperX interconnection networks. InSC24- W: Workshops of the International Confer- ence for High Performance Computing, Net- working, Storage and Analysis, pages 472–483, 2024
2024
-
[8]
Polarized routing: an effi- cient and versatile algorithm for large direct networks
Crist´ obal Camarero, Carmen Mart´ ınez, and Ram´ on Beivide. Polarized routing: an effi- cient and versatile algorithm for large direct networks. In2021 IEEE Symposium on High- Performance Interconnects (HOTI), pages 52– 59, 2021
2021
-
[9]
The CAMINOS interconnec- tion networks simulator.Journal of Parallel and Distributed Computing, 204:105136, 2025
Crist´ obal Camarero, Daniel Postigo, and Pablo Fuentes. The CAMINOS interconnec- tion networks simulator.Journal of Parallel and Distributed Computing, 204:105136, 2025
2025
-
[10]
CAMINOS.https://crates.io/crates/ caminos
-
[11]
Exploiting geometric parti- tioning in task mapping for parallel computers
Mehmet Deveci, Sivasankaran Rajamanickam, Vitus J Leung, Kevin Pedretti, Stephen L Olivier, David P Bunde, Umit V Cataly¨ urek, and Karen Devine. Exploiting geometric parti- tioning in task mapping for parallel computers. In2014 IEEE 28th international parallel and distributed processing symposium, pages 27–36. IEEE, 2014
2014
-
[12]
Ivanov, Yuki Tsushima, Tomoya Yuki, Aki- hiro Nomura, Shin’ichi Miura, Nic McDonald, Dennis L
Jens Domke, Satoshi Matsuoka, Ivan R. Ivanov, Yuki Tsushima, Tomoya Yuki, Aki- hiro Nomura, Shin’ichi Miura, Nic McDonald, Dennis L. Floyd, and Nicolas Dub´ e. HyperX topology: First at-scale implementation and comparison to the fat-tree. InProceedings of the International Conference for High Perfor- mance Computing, Networking, Storage and Analysis, SC ’...
2019
-
[13]
Cray Cascade: a scal- able HPC system based on a dragonfly net- work
Greg Faanes, Abdulla Bataineh, Duncan Roweth, Tom Court, Edwin Froese, Bob Alver- son, Tim Johnson, Joe Kopnick, Mike Higgins, and James Reinhard. Cray Cascade: a scal- able HPC system based on a dragonfly net- work. InProceedings of the International Con- ference on High Performance Computing, Net- working, Storage and Analysis, SC ’12, pages 1–9, Los Al...
2012
-
[14]
Overview of the Blue Gene/L system archi- tecture.IBM Journal of research and devel- opment, 49(2.3):195–212, 2005
Alan Gara, Matthias A Blumrich, Dong Chen, GL-T Chiu, Paul Coteus, Mark E Gi- ampapa, Ruud A Haring, Philip Heidelberger, Dirk Hoenicke, Gerard V Kopcsay, et al. Overview of the Blue Gene/L system archi- tecture.IBM Journal of research and devel- opment, 49(2.3):195–212, 2005
2005
-
[15]
On the automor- phism group of a composite graph.Studia Sci
F Harary and EM Palmer. On the automor- phism group of a composite graph.Studia Sci. Math. Hungar, 3:439–441, 1968
1968
-
[16]
Quiet neighborhoods: Key to protect job performance predictabil- ity
Ana Jokanovic, Jose Carlos Sancho, German Rodriguez, Alejandro Lucero, Cyriel Minken- berg, and Jesus Labarta. Quiet neighborhoods: Key to protect job performance predictabil- ity. In2015 IEEE International Parallel and Distributed Processing Symposium, pages 449– 459, 2015
2015
-
[17]
TPU v4: An optically re- configurable supercomputer for machine learn- ing with hardware support for embeddings
Norm Jouppi, George Kurian, Sheng Li, Pe- ter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, 19 Brian Towles, et al. TPU v4: An optically re- configurable supercomputer for machine learn- ing with hardware support for embeddings. In Proceedings of the 50th annual international symposium on computer architecture, pages 1– 14, 2023
2023
-
[18]
Dally, and Dennis Abts
John Kim, William J. Dally, and Dennis Abts. Flattened butterfly: a cost-efficient topology for high-radix networks. InProceedings of the 34th annual international symposium on Com- puter architecture, ISCA ’07, pages 126–137, New York, NY, USA, 2007. ACM
2007
-
[19]
Dally, Steve Scott, and Dennis Abts
John Kim, William J. Dally, Steve Scott, and Dennis Abts. Technology-driven, highly- scalable dragonfly topology. InProceedings of the 35th Annual International Symposium on Computer Architecture, pages 77–88. IEEE Computer Society, 2008
2008
-
[20]
LaForge, Kirk F
Laurence E. LaForge, Kirk F. Korver, and M. Sami Fadali. What designers of bus and network architectures should know about hy- percubes.Computers, IEEE Transactions on, 52(4):525–544, April 2003
2003
-
[21]
Fugaku and A64FX: the first exascale supercomputer and its innovative Arm CPU
Satoshi Matsuoka. Fugaku and A64FX: the first exascale supercomputer and its innovative Arm CPU. In2021 Symposium on VLSI Cir- cuits, pages 1–3. IEEE, 2021
2021
-
[22]
Practical and efficient incremental adaptive routing for Hy- perX networks
Nic McDonald, Mikhail Isaev, Adriana Flo- res, Al Davis, and John Kim. Practical and efficient incremental adaptive routing for Hy- perX networks. InProceedings of the Interna- tional Conference for High Performance Com- puting, Networking, Storage and Analysis, SC ’19, New York, NY, USA, 2019. Association for Computing Machinery
2019
-
[23]
Interval-regular graphs.Discrete Mathematics, 41(3):253–269, 1982
Henry Martyn Mulder. Interval-regular graphs.Discrete Mathematics, 41(3):253–269, 1982
1982
-
[24]
Optimization of collec- tive reduction operations
Rolf Rabenseifner. Optimization of collec- tive reduction operations. InComputational Science-ICCS 2004: 4th International Confer- ence, Krak´ ow, Poland, June 6-9, 2004, Pro- ceedings, Part I 4, pages 1–9. Springer, 2004
2004
-
[25]
Dragonfly+: Low cost topol- ogy for scaling datacenters
Alexander Shpiner, Zachy Haramaty, Saar Eliad, Vladimir Zdornov, Barak Gafni, and Eitan Zahavi. Dragonfly+: Low cost topol- ogy for scaling datacenters. In2017 IEEE 3rd International Workshop on High-Performance Interconnection Networks in the Exascale and Big-Data Era (HiPINEB), pages 1–8. IEEE, 2017
2017
-
[26]
TOP500 list of su- percomputer sites, November 2025
Erich Strohmaier, Jack Dongarra, Horst Si- mon, and Martin Meuer. TOP500 list of su- percomputer sites, November 2025
2025
-
[27]
Hao Yu, I-Hsin Chung, and Jos´ e E. Moreira. Topology mapping for Blue Gene/L supercom- puter. InSC 2006 Conference, Proceedings of the ACM/IEEE, November 2006
2006
-
[28]
Level-spread: A new job alloca- tion policy for dragonfly networks
Yijia Zhang, Ozan Tuncer, Fulya Kaplan, Katzalin Olcoz, Vitus J Leung, and Ayse K Coskun. Level-spread: A new job alloca- tion policy for dragonfly networks. In2018 IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 1123–
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.