Towards Cost-effective LLMs Routing with Batch Prompting
Pith reviewed 2026-06-29 09:37 UTC · model grok-4.3
The pith
RoBatch jointly chooses the model and batch size for each query to reach a better cost-performance frontier than routing or batching alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
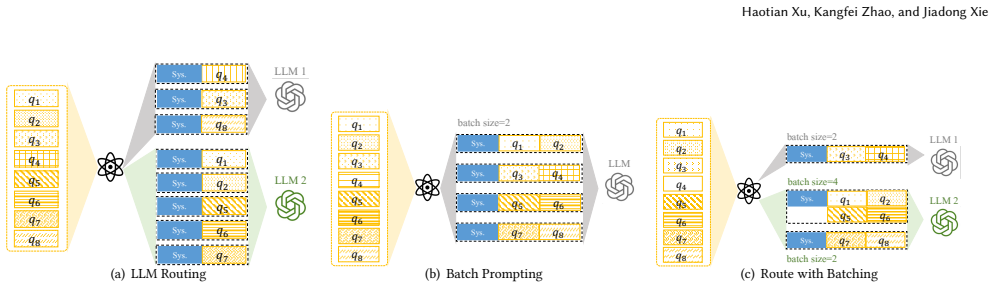
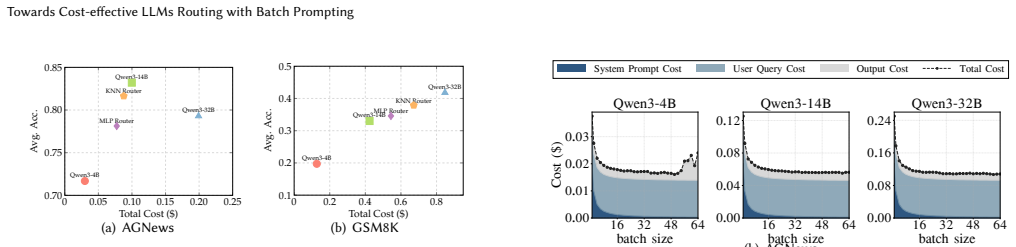
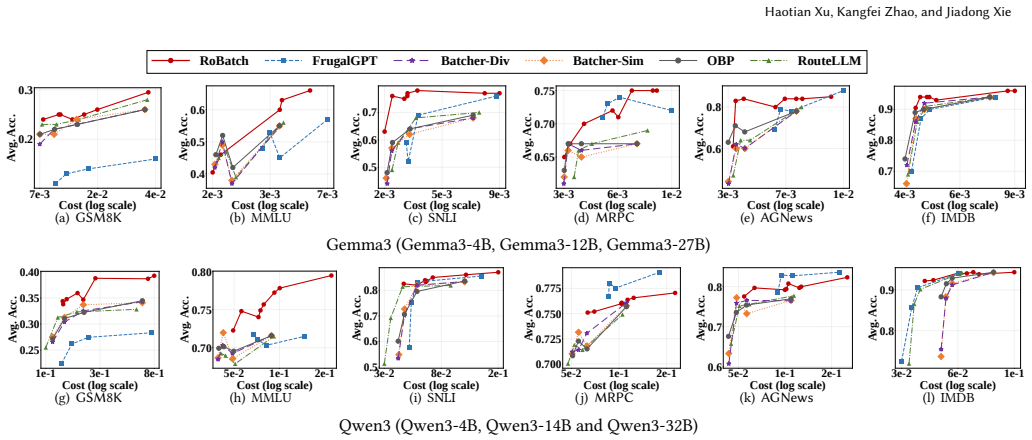
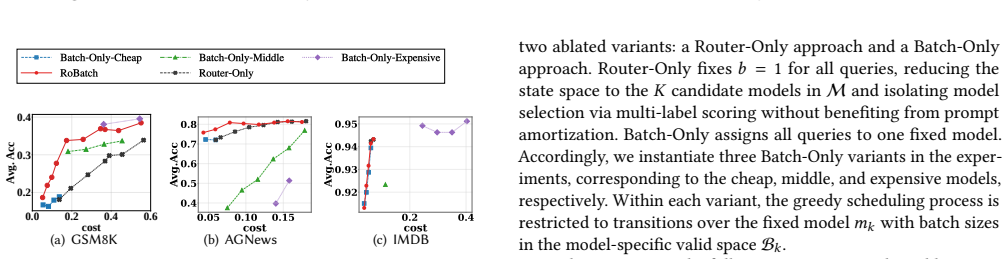
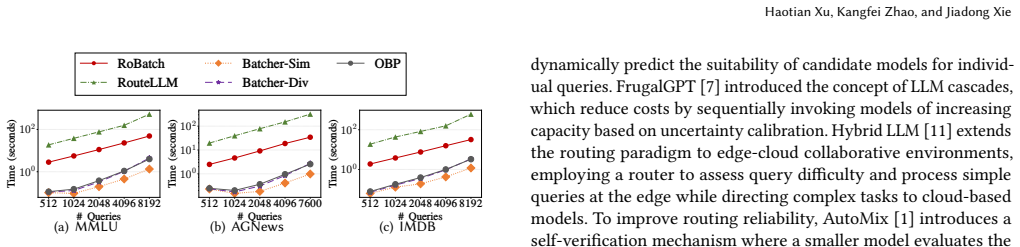
RoBatch solves the Route with Batching Problem by first building a batch-aware proxy utility model that decomposes utility into a no-batching estimate plus a model-specific degradation recalibration term, then running a greedy scheduling algorithm that progressively upgrades each query's model and batch size assignment along the cost-utility Pareto frontier until the budget is exhausted; this produces a superior cost-performance frontier compared with pure routing or pure batch-prompting baselines across six benchmarks and two LLM families.
What carries the argument
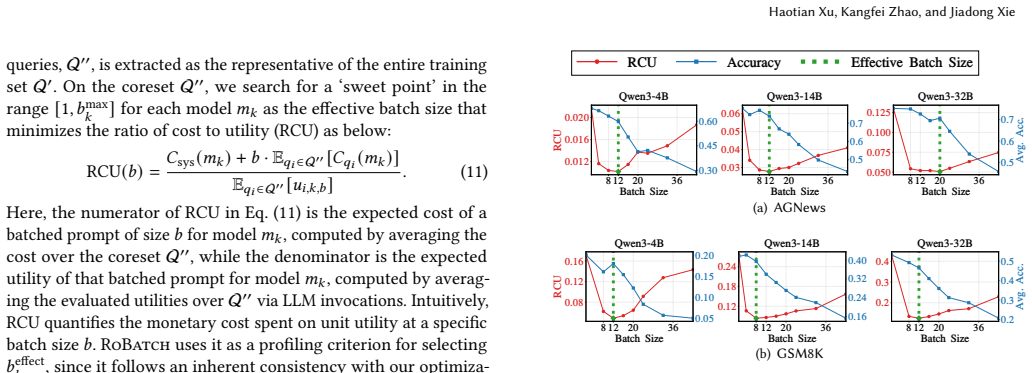
The batch-aware proxy utility model that decomposes utility estimation into a no-batching term plus a model-specific degradation recalibration.
If this is right
- Jointly optimizing model assignment and batch size produces a strictly better cost-utility Pareto frontier than optimizing either dimension separately.
- The greedy scheduler can exhaust any given cost budget while remaining on the frontier defined by the proxy model.
- The same two-stage structure works across different LLM families without requiring family-specific redesign.
- The formulation shows that the Route with Batching Problem is NP-hard yet admits a practical greedy approximation that outperforms the independent baselines.
Where Pith is reading between the lines
- The proxy decomposition could be reused as a building block when adding other serving techniques such as quantization or prefix caching.
- If the recalibration term proves stable across query domains, the same modeling stage might support online adaptation without retraining the utility estimator.
- Extending the scheduler to handle dynamic arrival of queries would turn the static budget allocation into a streaming decision process.
Load-bearing premise
The batch-aware proxy utility model accurately predicts the actual utility loss that occurs when multiple queries are batched together.
What would settle it
A controlled experiment on held-out queries where the measured performance drop after batching deviates significantly from the proxy model's predicted degradation term for one or more models.
Figures



read the original abstract
Large Language Model (LLM) serving systems must balance task performance against monetary cost. Two prominent optimization techniques have emerged independently: LLM routing, which directs each query to the most cost-effective model in a model pool, and batch prompting, which packs multiple queries into a single invocation to amortize the fixed cost of the shared system prompt. These two techniques are logically complementary; i.e., routing optimizes the model assignment dimension while batching optimizes the query aggregation dimension, jointly reshaping the landscape of model utility and monetary cost. However, existing approaches explore only one side of this decision space. On the basis of empirical studies on their impacts, we are motivated to jointly optimize these two dimensions in this paper. We formulate the Route with Batching Problem, which jointly determines the target model and batch size for each query under a total cost budget, and prove it NP-hard. To solve this challenging problem, we propose RoBatch, a unified two-stage framework. In the modeling stage, RoBatch constructs a batch-aware proxy utility model that decomposes combinatorial utility estimation into utility estimation without batching and recalibration of model-specific utility degradation with batching. In the routing stage, RoBatch employs a greedy scheduling algorithm that progressively upgrades the assignment of the target model and batch size for queries along the cost-utility Pareto frontier until the budget is exhausted. Extensive experiments on six benchmarks across two LLM families (Qwen3 and Gemma3) demonstrate that RoBatch consistently achieves a superior cost-performance Pareto frontier compared with LLM routing and batch prompting baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Route with Batching Problem, proves it NP-hard, and proposes RoBatch, a two-stage framework. The modeling stage builds a batch-aware proxy utility model that decomposes utility estimation into a no-batching term and a model-specific recalibration for batch-induced degradation. The routing stage uses a greedy algorithm to assign models and batch sizes along the cost-utility Pareto frontier under a budget. Experiments across six benchmarks and two LLM families (Qwen3, Gemma3) claim RoBatch achieves a superior Pareto frontier compared to separate routing and batch-prompting baselines.
Significance. If the proxy model accurately captures real utility degradation under batching, this work would meaningfully advance cost-effective LLM serving by unifying routing and batching optimizations. Strengths include the NP-hardness proof, the greedy scheduler, and evaluation on multiple benchmarks across LLM families. The approach addresses a practical gap in jointly optimizing model assignment and query aggregation.
major comments (1)
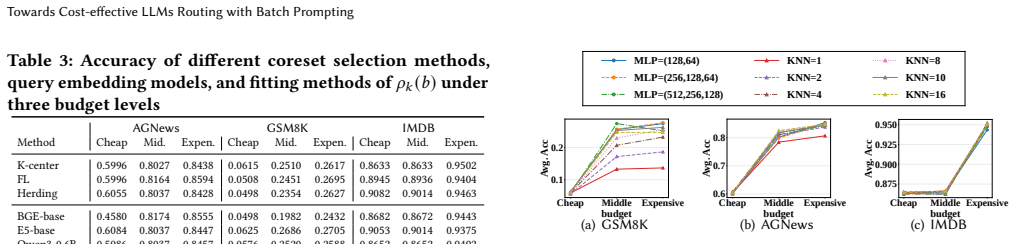
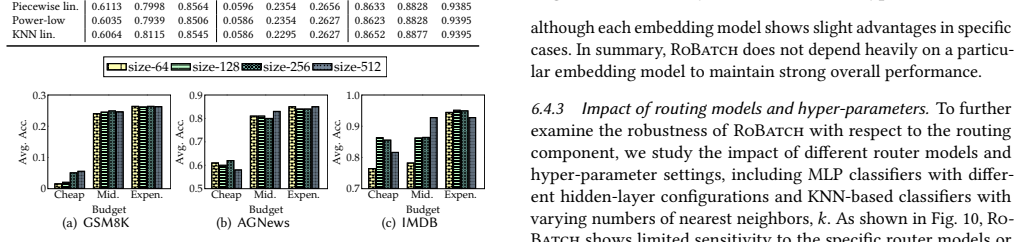
- [Modeling stage] The description of the batch-aware proxy utility model (decomposing into no-batching utility plus recalibration term) lacks any quantitative validation, such as correlation coefficients, mean absolute error, or error bars, between the proxy predictions and empirically measured utilities on batched query sets. This is load-bearing for the central empirical claim, as the greedy scheduler in the routing stage relies directly on these proxy values to trace the Pareto frontier.
minor comments (1)
- [Abstract] The abstract refers to 'empirical studies on their impacts' motivating the work but does not provide specific citations to those studies.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the NP-hardness proof, the greedy scheduler, and the practical value of jointly optimizing routing and batching. We address the single major comment below and will strengthen the manuscript accordingly.
read point-by-point responses
-
Referee: [Modeling stage] The description of the batch-aware proxy utility model (decomposing into no-batching utility plus recalibration term) lacks any quantitative validation, such as correlation coefficients, mean absolute error, or error bars, between the proxy predictions and empirically measured utilities on batched query sets. This is load-bearing for the central empirical claim, as the greedy scheduler in the routing stage relies directly on these proxy values to trace the Pareto frontier.
Authors: We agree that the absence of direct quantitative validation for the batch-aware proxy utility model is a gap. While the manuscript demonstrates end-to-end Pareto improvements, it does not report correlation coefficients, MAE, or error bars comparing proxy predictions against measured utilities on batched query sets. In the revised version we will add a dedicated validation subsection (under the modeling stage) that computes and reports these metrics—Pearson/Spearman correlations, MAE with error bars—across the six benchmarks and both LLM families (Qwen3, Gemma3). The validation will use held-out batched query sets to confirm that the decomposition (no-batching term + model-specific recalibration) accurately tracks observed utility degradation. This addition will directly support the scheduler’s use of the proxy values. revision: yes
Circularity Check
No significant circularity detected
full rationale
The derivation proceeds from an NP-hard formulation of the Route with Batching Problem, through an empirical-motivated decomposition in the modeling stage that produces a proxy utility model, to a greedy scheduler in the routing stage, with final claims resting on separate benchmark experiments across Qwen3 and Gemma3. No quoted equation or step equates a claimed prediction or result to its own fitted inputs by construction, nor does any load-bearing premise reduce to a self-citation chain or imported uniqueness theorem. The proxy decomposition is presented as a modeling choice whose accuracy is assessed via external validation rather than assumed tautologically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The utility degradation from batching can be captured by a model-specific recalibration factor independent of the specific query mix.
Reference graph
Works this paper leans on
-
[1]
Pranjal Aggarwal, Aman Madaan, Ankit Anand, Srividya Pranavi Potharaju, Swaroop Mishra, Pei Zhou, Aditya Gupta, Dheeraj Rajagopal, Karthik Kappa- ganthu, Yiming Yang, Shyam Upadhyay, Manaal Faruqui, and Mausam. 2024. AutoMix: Automatically Mixing Language Models. InAdvances in Neural Infor- mation Processing Systems 38: Annual Conference on Neural Informa...
2024
- [2]
-
[3]
Bowman, Gabor Angeli, Christopher Potts, and Christopher D
Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Man- ning. 2015. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Pro- cessing, EMNLP 2015. The Association for Computational Linguistics, 632–642
2015
-
[4]
Chang and Longling Geng
Edward Y. Chang and Longling Geng. 2025. SagaLLM: Context Management, Validation, and Transaction Guarantees for Multi-Agent LLM Planning.Proc. VLDB Endow.18, 12 (2025), 4874–4886
2025
-
[5]
Huamin Chen, Xunzhuo Liu, Bowei He, Fuyuan Lyu, Yankai Chen, Xue Liu, Yuhan Liu, and Junchen Jiang. 2026. The Workload-Router-Pool Architecture for LLM Inference Optimization: A Vision Paper from the vLLM Semantic Router Project.arXiv preprint arXiv:2603.21354(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation.CoRRabs/2402.03216 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.Trans. Mach. Learn. Res.2024 (2024)
2024
-
[8]
Zhoujun Cheng, Jungo Kasai, and Tao Yu. 2023. Batch Prompting: Efficient Inference with Large Language Model APIs. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing: EMNLP 2023 - Industry Track, Mingxuan Wang and Imed Zitouni (Eds.). Association for Computational Linguistics, 792–810
2023
-
[9]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training Verifiers to Solve Math Word Problems.CoRRabs/2110.14168 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Volume 1 (Long and Short Papers). Associ...
2019
-
[11]
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Rühle, Laks V. S. Lakshmanan, and Ahmed Hassan Awadallah. 2024. Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing. InThe Twelfth International Conference on Learning Representations, ICLR 2024, May 7-11, 2024. OpenReview.net
2024
-
[12]
Dolan and Chris Brockett
William B. Dolan and Chris Brockett. 2005. Automatically Constructing a Corpus of Sentential Paraphrases. InProceedings of the Third International Workshop on Paraphrasing, IWP@IJCNLP 2005. Asian Federation of Natural Language Processing
2005
-
[13]
Meihao Fan, Xiaoyue Han, Ju Fan, Chengliang Chai, Nan Tang, Guoliang Li, and Xiaoyong Du. 2024. Cost-Effective In-Context Learning for Entity Resolu- tion: A Design Space Exploration. In40th IEEE International Conference on Data Engineering, ICDE 2024, May 13-16, 2024. IEEE, 3696–3709
2024
-
[14]
Gonzalez
Teofilo F. Gonzalez. 1985. Clustering to Minimize the Maximum Intercluster Distance.Theor. Comput. Sci.38 (1985), 293–306
1985
-
[15]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2021. Measuring Massive Multitask Language Un- derstanding. In9th International Conference on Learning Representations, ICLR
2021
-
[16]
Zhongzhan Huang, Guoming Ling, Yupei Lin, Yandong Chen, Shanshan Zhong, Hefeng Wu, and Liang Lin. 2025. RouterEval: A Comprehensive Benchmark for Routing LLMs to Explore Model-level Scaling Up in LLMs. InFindings of the Association for Computational Linguistics: EMNLP 2025. Association for Compu- tational Linguistics, 3860–3887
2025
-
[17]
Zhaoxuan Ji, Xinlu Wang, Zhaojing Luo, Zhongle Xie, and Meihui Zhang. 2025. Optimized Batch Prompting for Cost-effective LLMs.Proc. VLDB Endow.18, 7 (2025), 2172–2184
2025
-
[18]
Richard M. Karp. 1972. Reducibility Among Combinatorial Problems. InPro- ceedings of a symposium on the Complexity of Computer Computations (The IBM Research Symposia Series). Plenum Press, New York, 85–103
1972
-
[19]
Guoliang Li, Jiayi Wang, Chenyang Zhang, and Jiannan Wang. 2025. Data+AI: LLM4Data and Data4LLM. InCompanion of the 2025 International Conference on Management of Data, SIGMOD/PODS 2025. ACM, 837–843
2025
-
[20]
Hui Lin and Jeff A. Bilmes. 2009. How to select a good training-data subset for transcription: submodular active selection for sequences. In10th Annual Conference of the International Speech Communication Association, INTERSPEECH
2009
-
[21]
Jianzhe Lin, Maurice Diesendruck, Liang Du, and Robin Abraham. 2024. Batch- Prompt: Accomplish more with less. InThe Twelfth International Conference on Learning Representations, ICLR 2024. OpenReview.net
2024
-
[22]
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. RoBERTa: A Robustly Optimized BERT Pretraining Approach.CoRRabs/1907.11692 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Maas, Raymond E
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts. 2011. Learning Word Vectors for Sentiment Analysis. InThe 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Proceedings of the Conference. The Association for Computer Linguistics, 142–150
2011
-
[24]
Gonzalez, M
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M. Waleed Kadous, and Ion Stoica. 2025. RouteLLM: Learning to Route LLMs from Preference Data. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, April 24-28, 2025. OpenReview.net
2025
-
[25]
Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia
Liana Patel, Siddharth Jha, Melissa Z. Pan, Harshit Gupta, Parth Asawa, Carlos Guestrin, and Matei Zaharia. 2025. Semantic Operators and Their Optimization: Towards AI-Based Data Analytics with Accuracy Guarantees.Proc. VLDB Endow. 18, 11 (2025), 4171–4184
2025
- [26]
-
[27]
Parameswaran, and Eugene Wu
Shreya Shankar, Tristan Chambers, Tarak Shah, Aditya G. Parameswaran, and Eugene Wu. 2025. DocETL: Agentic Query Rewriting and Evaluation for Complex Document Processing.Proc. VLDB Endow.18, 9 (2025), 3035–3048
2025
-
[28]
Shreya Shankar, Sepanta Zeighami, and Aditya G. Parameswaran. 2026. Task Cascades for Efficient Unstructured Data Processing.CoRRabs/2601.05536 (2026)
-
[29]
Gemma Team. 2025. Gemma 3 Technical Report.CoRRabs/2503.19786 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Qwen Team. 2025. Qwen3 Technical Report.CoRRabs/2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. 2022. Text Embeddings by Weakly-Supervised Contrastive Pre-training.CoRRabs/2212.03533 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Joty, and Steven C
Yue Wang, Weishi Wang, Shafiq R. Joty, and Steven C. H. Hoi. 2021. CodeT5: Identifier-aware Unified Pre-trained Encoder-Decoder Models for Code Under- standing and Generation. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021. Association for Computa- tional Linguistics, 8696–8708
2021
-
[33]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. InAdvances in Neural Informa- tion Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022
2022
-
[34]
Max Welling. 2009. Herding dynamical weights to learn. InProceedings of the 26th Annual International Conference on Machine Learning, ICML 2009 (ACM International Conference Proceeding Series), Andrea Pohoreckyj Danyluk, Léon Bottou, and Michael L. Littman (Eds.). ACM, 1121–1128
2009
-
[35]
Narasimhan, and Yuan Cao
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Represen- tations, ICLR 2023. OpenReview.net
2023
-
[36]
Parameswaran
Sepanta Zeighami, Shreya Shankar, and Aditya G. Parameswaran. 2025. Cut Costs, Not Accuracy: LLM-Powered Data Processing with Guarantees.Proc. ACM Manag. Data3, 6 (2025), 1–26
2025
-
[37]
Xiang Zhang, Junbo Jake Zhao, and Yann LeCun. 2015. Character-level Con- volutional Networks for Text Classification. InAdvances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Sys- tems 2015. 649–657
2015
-
[38]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou
-
[39]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models.CoRRabs/2506.05176 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Zihuai Zhao, Wenqi Fan, Jiatong Li, Yunqing Liu, Xiaowei Mei, Yiqi Wang, Zhen Wen, Fei Wang, Xiangyu Zhao, Jiliang Tang, and Qing Li. 2024. Recommender Systems in the Era of Large Language Models (LLMs).IEEE Trans. Knowl. Data Eng.36, 11 (2024), 6889–6907
2024
-
[41]
Jun-Peng Zhu, Peng Cai, Kai Xu, Li Li, Yishen Sun, Shuai Zhou, Haihuang Su, Liu Tang, and Qi Liu. 2024. AutoTQA: Towards Autonomous Tabular Question Answering through Multi-Agent Large Language Models.Proc. VLDB Endow.17, 12 (2024), 3920–3933
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.