Comprehensive Benchmarking of Long-Form Speech Generation in Diverse Scenarios
Pith reviewed 2026-06-29 09:52 UTC · model grok-4.3
The pith
Current speech generation models struggle in highly expressive scenarios and show gaps in consistency and hierarchy compared to real recordings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
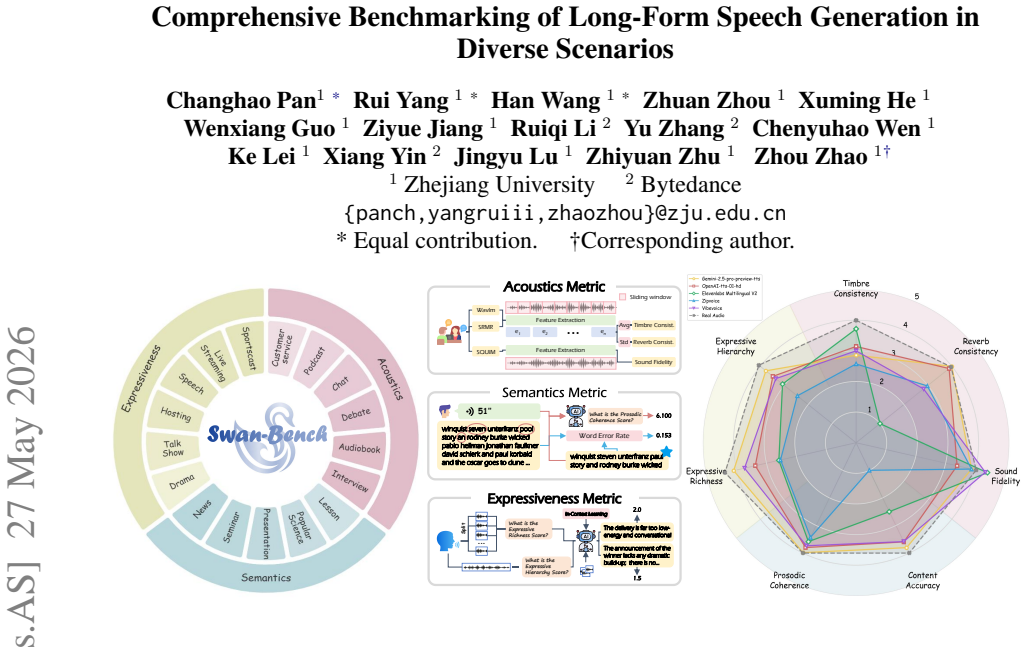
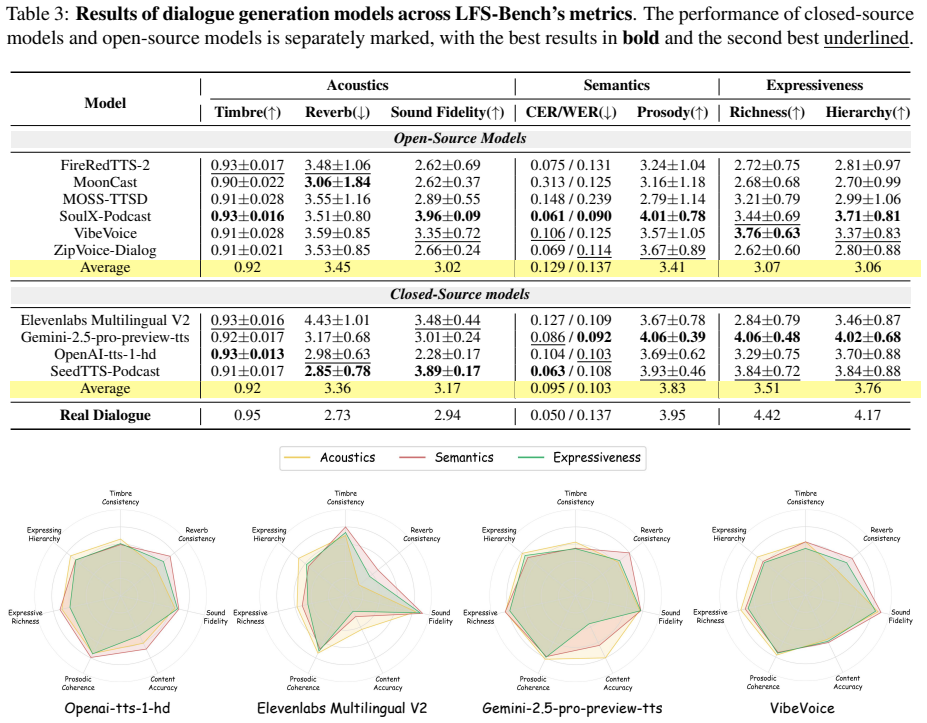
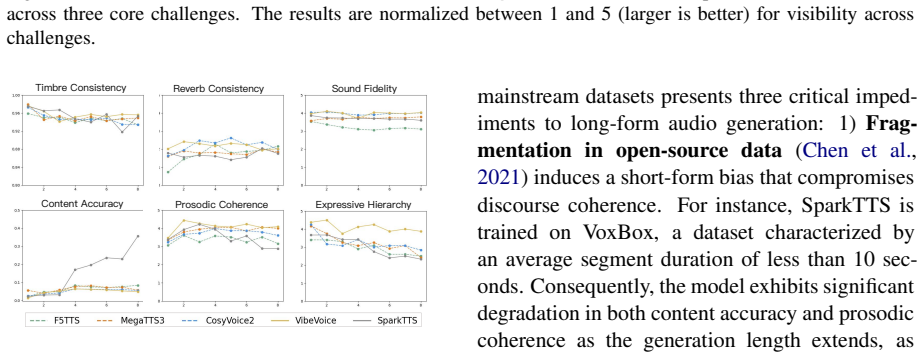
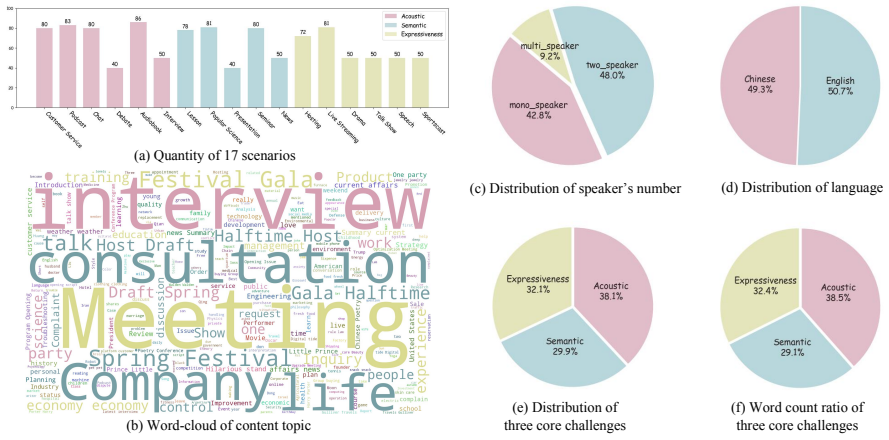
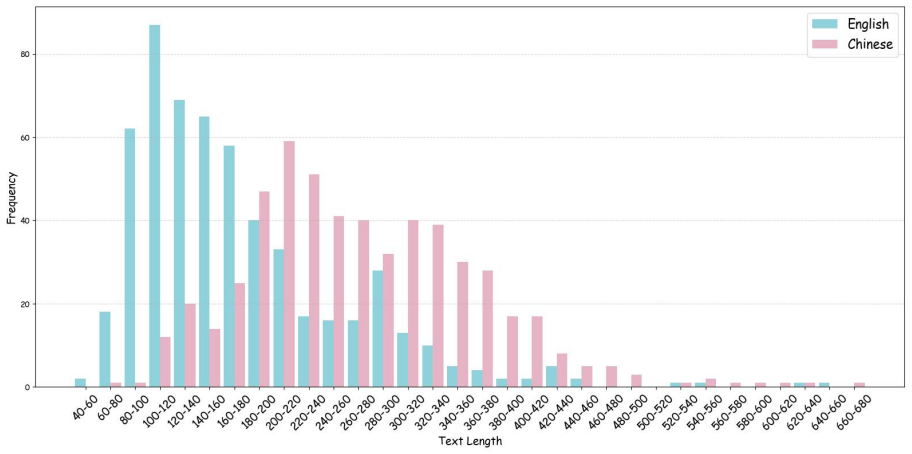
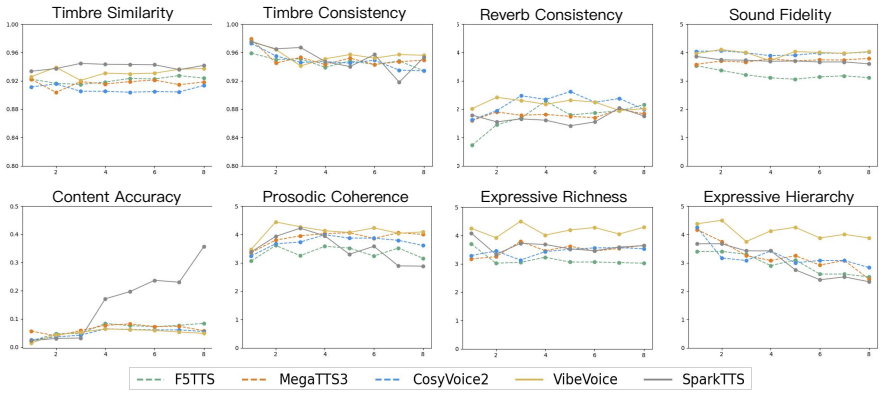
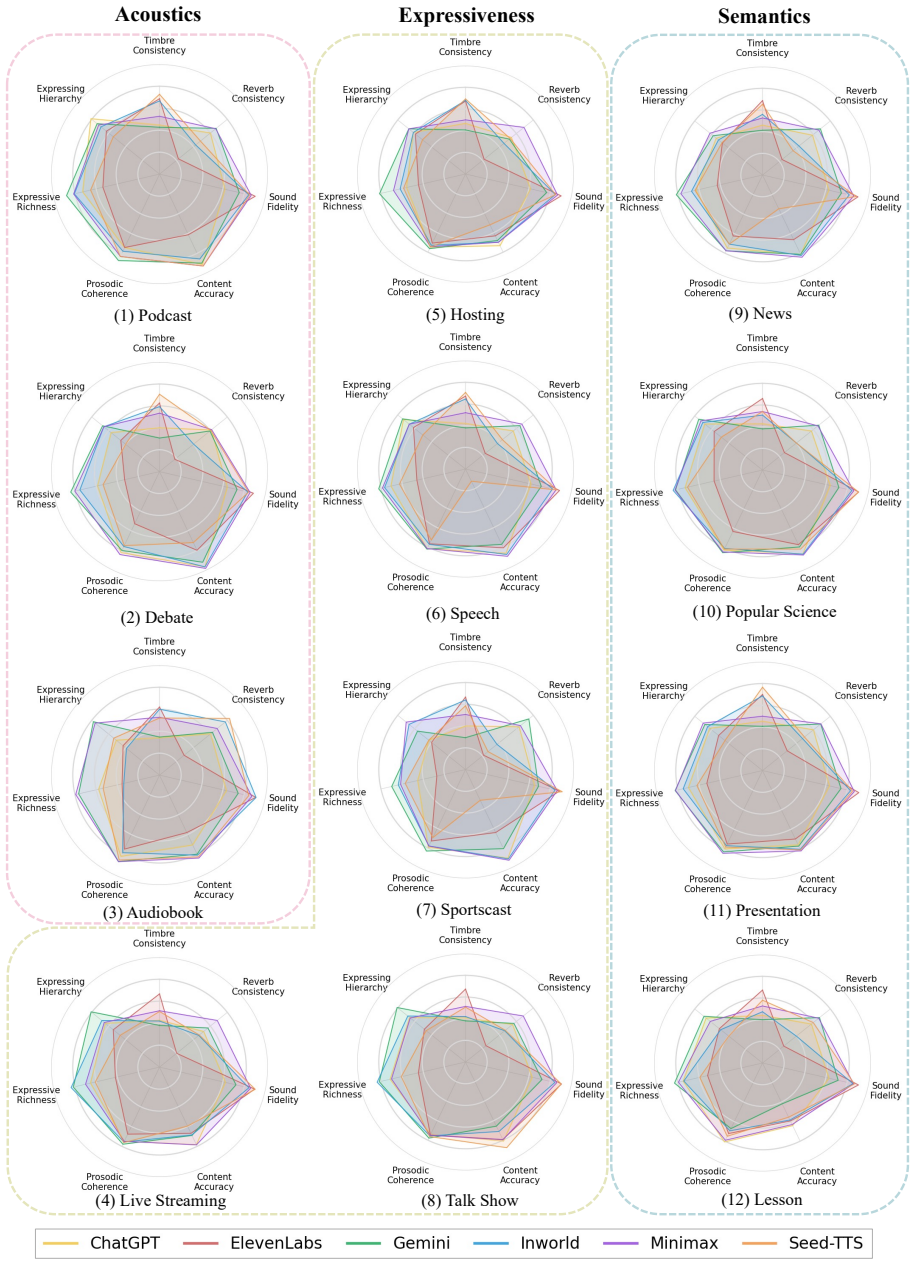
SwanBench-Speech covers acoustics, semantics, and expressiveness challenges through 1,101 samples in 17 common speech scenarios and defines an automated evaluation protocol with seven metrics to deliver a comprehensive assessment, revealing through extensive experiments that current models still struggle in highly expressive scenarios and exhibit a notable gap in consistency and hierarchy compared to real recordings.
What carries the argument
SwanBench-Speech benchmark, which decomposes long-form speech quality into specific disentangled dimensions using 17 scenarios and seven metrics along acoustics, semantics, and expressiveness axes.
If this is right
- Targeted improvements in model design will be required to close the observed gaps in expressiveness and long-range consistency.
- Future evaluation of speech systems should incorporate separate checks for hierarchy and coherence rather than relying on single overall scores.
- Dialog generation applications will need additional training or architectural changes to reach the consistency levels of recorded speech.
- Standardized benchmarks of this form can supply concrete targets that accelerate progress across different generation approaches.
Where Pith is reading between the lines
- The identified shortfalls in long-context handling point toward a possible need for mechanisms that explicitly track discourse structure across extended outputs.
- The benchmark could be used to test whether scaling data or model size alone reduces the reported gaps or whether new inductive biases are necessary.
- Developers building production speech tools for extended content may want to run their systems against these 17 scenarios before release.
Load-bearing premise
The seven metrics and 17 scenarios together supply a comprehensive, accurate, and standardized assessment that holds beyond the test set chosen for the benchmark.
What would settle it
A controlled listening study in which models that score highest on the seven metrics are nevertheless rated by listeners as less consistent or hierarchical than real recordings over long expressive passages would undermine the claim that the benchmark captures the relevant qualities.
Figures






read the original abstract
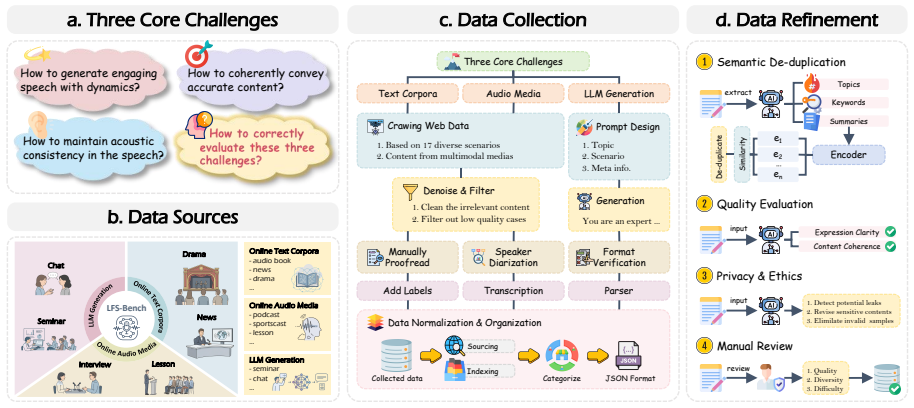
Recent advances in speech generation have enabled high-fidelity synthesis, yet systematic evaluation of models under long-context conditions remains largely underexplored. A comprehensive evaluation benchmark for long-form speech is indispensable for two reasons: 1) existing test scenarios are often confined to limited domains, creating a significant gap with the diverse downstream applications; 2) existing metrics overlook critical long-text factors such as consistency and coherence, failing to generalize reliably. To this end, we propose Swanbench-Speech, a comprehensive benchmark that decomposes long-form speech quality into specific, disentangled dimensions. SwanBench-Speech has three key properties. 1) Rich speech scenarios: Focusing on long-form speech generation and dialog generation, SwanBench-Speech covers acoustics, semantics, and expressiveness challenges, and consists of 1,101 samples spanning 17 common speech scenarios; 2) Comprehensive evaluation dimensions: Along the acoustics, semantics, and expressiveness axes, SwanBench-Speech defines an automated evaluation protocol with seven metrics to provide a comprehensive, accurate, and standardized assessment; 3) Valuable Insights: Through extensive experiments, we reveal that current models still struggle in highly expressive scenarios and exhibit a notable gap in consistency and hierarchy compared to real recordings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SwanBench-Speech, a benchmark for long-form speech generation and dialog that covers 1,101 samples across 17 scenarios spanning acoustics, semantics, and expressiveness. It defines seven automated metrics for disentangled evaluation and reports that current models struggle in highly expressive scenarios while exhibiting notable gaps in consistency and hierarchy relative to real recordings.
Significance. If the metrics are shown to be reliable proxies, the benchmark could address documented limitations in existing speech evaluations by providing standardized, multi-dimensional assessment for long-context conditions that better match downstream applications.
major comments (2)
- [Abstract] Abstract: the assertion that the seven metrics deliver a 'comprehensive, accurate, and standardized assessment' is unsupported because the manuscript provides no details on metric computation, no correlation coefficients with human ratings on consistency/hierarchy/expressiveness, and no ablation showing improvement over prior metrics for long-form coherence.
- [Abstract] Abstract / experimental findings: the claim of 'notable gap in consistency and hierarchy' and struggles in expressive scenarios rests entirely on the unvalidated automated scores; without reported statistical significance tests or inter-metric correlation analysis, the gaps cannot be distinguished from implementation artifacts or reference biases.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the seven metrics and briefly indicated how each targets one of the three axes.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract and experimental claims. We address each point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the seven metrics deliver a 'comprehensive, accurate, and standardized assessment' is unsupported because the manuscript provides no details on metric computation, no correlation coefficients with human ratings on consistency/hierarchy/expressiveness, and no ablation showing improvement over prior metrics for long-form coherence.
Authors: The full manuscript provides explicit formulas and implementation details for all seven metrics in Section 3.2. We agree the abstract overstates the claim without supporting evidence for human correlations or ablations. We will revise the abstract to read 'comprehensive and standardized automated assessment' and add a limitations paragraph noting the absence of human validation studies and direct ablations against prior long-form metrics. revision: partial
-
Referee: [Abstract] Abstract / experimental findings: the claim of 'notable gap in consistency and hierarchy' and struggles in expressive scenarios rests entirely on the unvalidated automated scores; without reported statistical significance tests or inter-metric correlation analysis, the gaps cannot be distinguished from implementation artifacts or reference biases.
Authors: We will add statistical significance tests (paired t-tests and Wilcoxon signed-rank) to the results tables and include an inter-metric correlation matrix in the revised experiments section or supplementary material. The observed gaps will be qualified as preliminary findings from automated metrics, with explicit caveats about the lack of human ratings. revision: yes
- Human correlation coefficients with the seven metrics on consistency/hierarchy/expressiveness
- Ablation studies showing improvement over prior metrics for long-form coherence
Circularity Check
Benchmark proposal contains no derivation chain or self-referential reductions
full rationale
The paper introduces SwanBench-Speech as a new evaluation benchmark with 17 scenarios and seven metrics along acoustics/semantics/expressiveness axes. No equations, fitted parameters, or predictions are presented; the central claims rest on applying the proposed metrics to existing models and comparing outputs to real recordings. No self-citations are invoked as load-bearing uniqueness theorems, and the metrics are defined directly rather than derived from the experimental results themselves. This is a standard benchmark-construction paper whose evaluation protocol is independent of its own findings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing test scenarios are confined to limited domains and existing metrics overlook critical long-text factors such as consistency and coherence.
Reference graph
Works this paper leans on
-
[1]
Glm-tts technical report.arXiv preprint arXiv:2512.14291, 2025
Glm-tts technical report. arXiv preprint arXiv:2512.14291. Zhihao Du, Changfeng Gao, Y uxuan Wang, Fan Y u, Tianyu Zhao, Hao Wang, Xiang Lv, Hui Wang, Chongjia Ni, Xian Shi, et al. 2025. Cosyvoice 3: To- wards in-the-wild speech generation via scaling-up and post-training. arXiv preprint arXiv:2505.17589. Zhihao Du, Y uxuan Wang, Qian Chen, Xian Shi, Xian...
-
[2]
Advances in neural in- formation processing systems, 36:14005–14034
V oicebox: Text-guided multilingual universal speech generation at scale. Advances in neural in- formation processing systems, 36:14005–14034. Yinghao Aaron Li, Cong Han, Vinay Raghavan, Gavin Mischler, and Nima Mesgarani. 2024. Styletts 2: To- wards human-level text-to-speech through style dif- fusion and adversarial training with large speech lan- guage...
-
[3]
In Interspeech, vol- ume 2017, pages 498–502
Montreal forced aligner: Trainable text- speech alignment using kaldi. In Interspeech, vol- ume 2017, pages 498–502. Christoph Minixhofer, Ond ˇrej Klejch, and Peter Bell
2017
-
[4]
In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 766–773
Ttsds-text-to-speech distribution score. In 2024 IEEE Spoken Language Technology Workshop (SLT), pages 766–773. Christoph Minixhofer, Ondrej Klejch, and Peter Bell
2024
-
[5]
Ttsds2: Resources and benchmark for evalu- ating human-quality text to speech systems. arXiv preprint arXiv:2506.19441. Y uto Nishimura, Takumi Hirose, Masanari Ohi, Hideki Nakayama, and Nakamasa Inoue. 2024. Hall-e: hi- erarchical neural codec language model for minute- long zero-shot text-to-speech synthesis. arXiv preprint arXiv:2410.04380. OpenAI. 202...
-
[6]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Dnsmos: A non-intrusive perceptual objec- tive speech quality metric to evaluate noise suppres- sors. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 6493–6497. Nils Reimers and Iryna Gurevych. 2019. Sentence- bert: Sentence embeddings using siamese bert- networks. arXiv preprint arXiv:1908.10...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
Selective PII Anonymization : The model is instructed to specifically identify and anonymize the names of private individu- als (non-public figures). While the names of celebrities or public entities are retained to preserve contextual integrity, the names of ordinary citizens are replaced with generic placeholders or synthetic alternatives
-
[8]
content": [ {
Ethical Risk Assessment : The model then scrutinizes the content for social and ethical 12https://huggingface.co/sentence-transformers/ all-MiniLM-L6-v2 Prompt for generating structured presentation data Y ou are an expert computer science professor and content creator. Y our task is to generate a high-quality, long-form presentation script on the topic: ...
-
[9]
This step ensures the text re- mains natural and grammatically fluid while strictly maintaining the harmlessness and anonymity
Harmless Placeholder Infilling : For sam- ples that underwent privacy anonymization, the automated generic tags (e.g., [NAME], [LOC]) are replaced with specific but ficti- tious entities. This step ensures the text re- mains natural and grammatically fluid while strictly maintaining the harmlessness and anonymity
-
[10]
Samples deemed substan- dard or unnatural are strictly discarded
Residual Error Purging : Annotators then scrutinize the dataset to identify subtle logi- cal inconsistencies, formatting errors, or con- text mismatches that might have evaded the automated filters. Samples deemed substan- dard or unnatural are strictly discarded
-
[11]
These re- plenished samples undergo the same process before being added to the final pool
Dataset Replenishment: To compensate for the discarded samples and maintain the vol- ume, new instances are constructed. These re- plenished samples undergo the same process before being added to the final pool. Five undergraduate students are enlisted for this manual review, receiving a compensation of $0.30 per instance. The cumulative expenditure for th...
-
[12]
Is the language vivid and rhythmically suitable for long-duration speech synthesis?
Textual Expressiveness: Assess the fluency, naturalness, and rhetorical quality of the text. Is the language vivid and rhythmically suitable for long-duration speech synthesis?
-
[13]
reasoning
Content Consistency: Assess the logical coherence and semantic stability of the text. Is the narrative or argument consistent throughout without contradictions or abrupt topic shifts? Rate each criterion on a scale of 1 to 5 (1 = Poor, 5 = Excellent). Based on these, provide an Overall Score (1-5) representing your recommendation for retaining this sample...
-
[14]
• If the name belongs to a public figure (celebrity, politician, historical figure), retain it to preserve context
PII Detection (Selective): Identify all person names. • If the name belongs to a public figure (celebrity, politician, historical figure), retain it to preserve context. • If the name belongs to a private individual (ordinary citizen), anonymize it using a placeholder (e.g., [NAME])
-
[15]
reasoning
Ethical Risk Assessment: Check for hate speech, explicit violence, sexual content, or severe bias. • If the risk is severe and cannot be mitigated, mark as invalid. • If the risk is minor or related to PII, provide a revised version. Output Format: Output the result in a strict JSON format with the following keys: • "reasoning": A brief explanation of you...
2024
-
[16]
Timbre Maintenance
Character Normalization : converting Tradi- tional Chinese to Simplified using zhconv21 while filtering non-ASCII characters in English text via clean-text22. Finally, following the methodol- ogy of F5-TTS ( Chen et al. , 2024c), we calculate the WER and CER using the JiWER library23. It is worth noting that our selected transcrip- tion system, FunASR-Nano,...
2025
-
[17]
In multi-speaker scenarios, this may also suggest inaccurate speaker transitions
Score < 0.85: Indicates significant timbre drift. In multi-speaker scenarios, this may also suggest inaccurate speaker transitions
-
[18]
Score < 0.93: Demonstrates superior timbre maintenance, with performance comparable to ground truth recordings
-
[19]
Clarity and Fidelity
Score ∈ [0.85, 0.90] : Represents generally acceptable performance, typically character- ized by minor local timbre mutations or arti- facts. Besides, the robustness of this metric presents room for improvement. Potential misclassifica- tions may arise in specific edge cases, such as audio exhibiting periodic timbre variations (e.g., looping patterns). Sinc...
2002
-
[20]
Score Divergence > 1: A difference of more than 1 points indicates a substantial and per- ceptually obvious gap in prosodic quality be- tween audio samples
-
[21]
Score ≥ 4: Audio samples achieving this threshold demonstrate competent basic prosody and rhythmic structure
-
[22]
alloy”, “echo
Score ≥ 4.5: Performance at this level is considered virtually indistinguishable from ground truth recordings. D.4 Validation of Expressiveness In this experiment, we curate a diverse set of 200 samples spanning all models and tasks for subjec- tive evaluation. Listeners are tasked with rating the audio strictly adhering to the same prompt cri- teria prov...
2022
-
[23]
Core Task: Evaluate the audio’s naturalness by analyzing its prosodic structure and coherence against the target text, rather than just audio quality
-
[24]
Check for unnatural pauses, abrupt disjoints between words/phrases, and the logical flow of intonation across sentence boundaries
Dimension 1 - Prosody Coherence & Flow : Assess the smoothness of the speech stream. Check for unnatural pauses, abrupt disjoints between words/phrases, and the logical flow of intonation across sentence boundaries
-
[25]
Does the speaker correctly emphasize content words while de-emphasizing function words? Is there a natural "melody" (intonation contour) rather than a flat or repetitive beat?
Dimension 2 - Rhythmic Hierarchy & Layering : Evaluate the structural stress patterns. Does the speaker correctly emphasize content words while de-emphasizing function words? Is there a natural "melody" (intonation contour) rather than a flat or repetitive beat?
-
[26]
Dimension 3 - Overall Naturalness : Check for presence of human-like micro-prosody (e.g., breathiness, slight pitch variations)
-
[27]
Overall_Impression
Format: Strictly output a valid JSON object. No other text. Scoring Guidelines (1.0–5.0, step of 0.5): • 5.0 (Human-Parity): Indistinguishable from a professional human speaker; perfect coherence and rich prosodic hierarchy. • 4.0 (Natural): V ery smooth and pleasant; minor prosodic flaws only noticeable to experts; good structural layering. • 3.0 (Accepta...
-
[28]
Layering and Hierarchy
Core Task: Analyze how the performance evolves over time, focusing on "Layering and Hierarchy"
-
[29]
one-note
Dimension 1 - Emotional Variation & Arc : Evaluate progression from beginning to end, distinction between climax and exposition, and avoidance of "one-note" acting
-
[30]
Dimension 2 - V ocal Dynamics: Check for macro/micro dynamics (volume/tempo shifts)
-
[31]
Dimension 3 - Scene Appropriateness & Structural Fit : Assess contextual adaptation to content structure and long-term engagement
-
[32]
looping prosody
Format: Strictly output a valid JSON object. No other text. Scoring Guidelines (1.0–5.0, step of 0.5): • 5.0 (Masterful): A journey with rich variety; no repetitive patterns; perfect for long listening. • 4.0 (Strong): Good dynamics and clear emotional shifts; avoids obvious monotony. • 3.0 (Acceptable but Static): Pleasant but lacks progression; risks bo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.