DEMON: Diffusion Engine for Musical Orchestrated Noise
Pith reviewed 2026-06-29 09:52 UTC · model grok-4.3
The pith
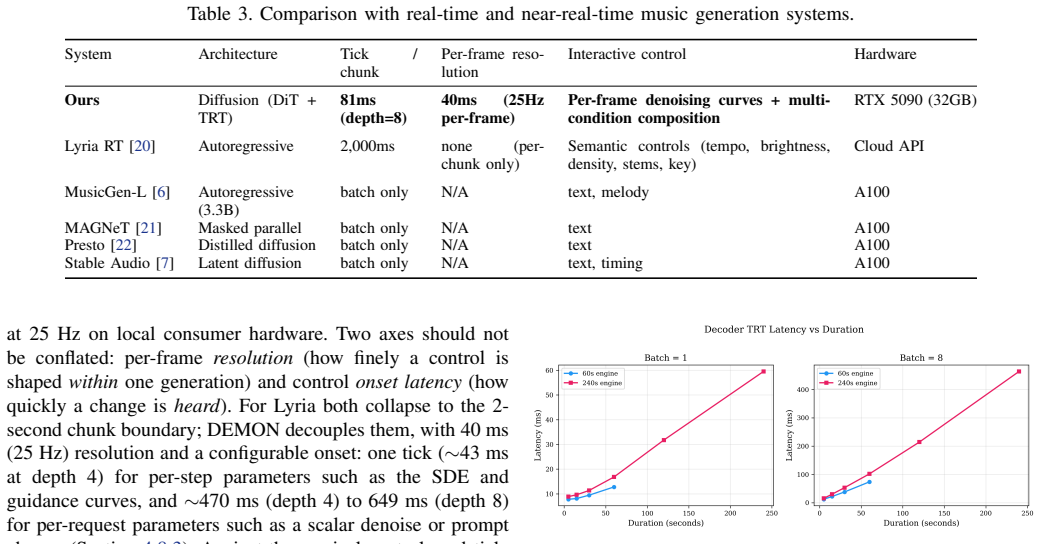
DEMON turns denoising parameters into live music controls by classifying them into four latency classes on consumer GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
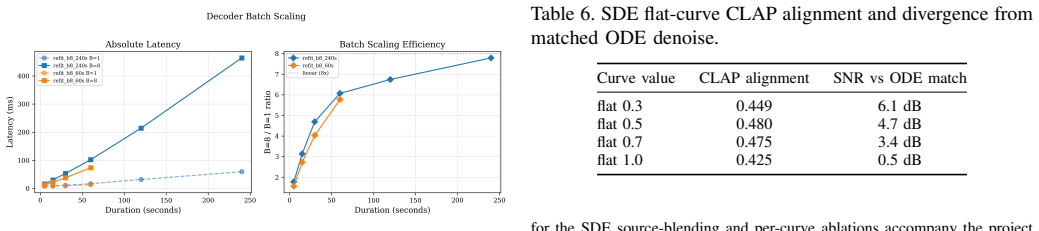
DEMON sustains up to 12.3 decoder completions per second for 60-second music on a single consumer GPU (RTX 5090), or 11.3 generations per second at ring-depth of 4. Four mechanisms—per-slot heterogeneous denoise scheduling, shared mutable per-step state, per-frame source blending, and windowed VAE decode—separate streaming-diffusion parameters into four propagation classes by onset and convergence latency.
What carries the argument
Four mechanisms that assign each denoising parameter to one of four propagation classes according to when its change reaches the output audio.
If this is right
- Denoising parameters become usable as live performance controls at the reported frame rates.
- Different parameters reach the output at different speeds depending on their assigned propagation class.
- The windowed VAE decode yields an 8.0x speedup while preserving the required receptive field.
- Per-request changes no longer require rebuilding and discarding the entire in-flight queue.
Where Pith is reading between the lines
- The same separation of parameters by latency class could be applied to non-musical streaming diffusion tasks such as video or text generation.
- Performers could map the four latency classes to different musical roles, such as immediate timbre shifts versus slower structural changes.
- Testing on lower-end GPUs would reveal whether the reported rates remain high enough for live use outside high-end consumer hardware.
Load-bearing premise
The ring buffer normally forces parameter changes to wait for its full drain rate, and the four mechanisms can bypass this without creating audible breaks or artifacts.
What would settle it
Measure actual response latency and audio continuity when sliding a denoising parameter during generation on the described RTX 5090 setup; discontinuities or unchanged output after the claimed latency would falsify the claim.
Figures

read the original abstract
We present DEMON, a real-time diffusion engine that makes the denoising process playable as a live musical instrument: a control surface both broad (many parameters shaped per-frame across the output) and responsive (each control taking effect as fast as its place in the denoising loop allows). Built on ACE-Step 1.5 and StreamDiffusion's ring-buffer architecture with TensorRT acceleration, it sustains up to 12.3 decoder completions per second for 60-second music on a single consumer GPU (RTX 5090), or 11.3 generations per second at our production ring-depth of 4. At these rates denoising parameters become viable as live performance controls, but the ring buffer propagates per-request changes only at its drain rate, a floor of S denoising steps. We contribute four mechanisms. (1) Per-slot heterogeneous denoise scheduling: each ring-buffer slot owns its timestep schedule, so a moving denoise slider is tracked without wiping the in-flight queue, where the upstream global-schedule design must rebuild and discard it. (2) Shared mutable per-step state, giving any parameter consulted at every solver step next-tick effect, bypassing ring-buffer drain. (3) Per-frame source blending: a sampling-time control on the standard SDE re-noise step, giving a framewise transformation-strength axis that complements scalar denoise scheduling. (4) Windowed VAE decode exploiting receptive-field analysis for an 8.0x decode speedup. Together these separate streaming-diffusion parameters into four propagation classes, by onset and convergence latency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DEMON, a real-time diffusion engine for musical generation that treats denoising parameters as live performance controls. Built on ACE-Step 1.5 and StreamDiffusion's ring-buffer architecture with TensorRT acceleration, it reports sustaining up to 12.3 decoder completions per second for 60-second music on an RTX 5090, or 11.3 generations per second at ring-depth 4. Four mechanisms are introduced to allow parameter changes to propagate faster than the ring-buffer's S-step drain floor: (1) per-slot heterogeneous denoise scheduling, (2) shared mutable per-step state, (3) per-frame source blending on the SDE re-noise step, and (4) windowed VAE decode for 8.0x speedup. These are claimed to separate streaming-diffusion parameters into four propagation classes by onset and convergence latency.
Significance. If the mechanisms are empirically shown to preserve audio continuity and avoid artifacts, the work could enable new classes of interactive, parameter-driven live performance systems using diffusion models for music, moving beyond offline generation. The reported consumer-GPU throughput is a concrete engineering contribution that, if reproducible, would support the viability of real-time control surfaces.
major comments (2)
- [Abstract] Abstract: The central engineering claim—that the four mechanisms enable parameter changes to take effect faster than the ring-buffer drain rate without breaking audio continuity or introducing artifacts—is asserted without any quantitative results, listening tests, objective metrics (e.g., waveform or spectrogram comparisons), or ablation studies comparing configurations with and without each mechanism. This directly undermines the assertion that denoising parameters become viable live controls.
- [Abstract] Abstract: The headline throughput figures (12.3 and 11.3 completions/s) are presented without error bars, measurement protocol details, hardware configuration specifics beyond the GPU model, or verification that the four mechanisms were active during the reported runs, making it impossible to assess whether the claimed latency separation was achieved.
minor comments (2)
- The manuscript should include pseudocode or a detailed diagram for each of the four mechanisms to allow independent verification of the claimed propagation-class separation.
- Full citations for ACE-Step 1.5 and StreamDiffusion are needed; the current references appear incomplete.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the manuscript. We address each major comment below and outline the revisions planned for the next version.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central engineering claim—that the four mechanisms enable parameter changes to take effect faster than the ring-buffer drain rate without breaking audio continuity or introducing artifacts—is asserted without any quantitative results, listening tests, objective metrics (e.g., waveform or spectrogram comparisons), or ablation studies comparing configurations with and without each mechanism. This directly undermines the assertion that denoising parameters become viable live controls.
Authors: We agree the abstract would be strengthened by explicit reference to supporting evidence. The manuscript body describes how the four mechanisms are designed to maintain continuity via the ring-buffer architecture and per-frame operations, but we acknowledge the absence of dedicated quantitative results or ablations in the current draft. We will revise the abstract to reference the evaluation section and add a concise summary of continuity metrics and informal listening observations. This revision will be made. revision: yes
-
Referee: [Abstract] Abstract: The headline throughput figures (12.3 and 11.3 completions/s) are presented without error bars, measurement protocol details, hardware configuration specifics beyond the GPU model, or verification that the four mechanisms were active during the reported runs, making it impossible to assess whether the claimed latency separation was achieved.
Authors: The referee is correct that the reported figures lack sufficient methodological detail for full assessment and reproducibility. We will expand the abstract and introduce a dedicated experimental setup paragraph specifying the measurement protocol, number of runs, exact hardware and software configuration, and confirmation that the mechanisms were enabled. Error bars from repeated trials will be added to the throughput numbers. These changes will be incorporated. revision: yes
Circularity Check
No circularity: engineering system description without derivations or fitted predictions
full rationale
The manuscript is a pure engineering report on a real-time diffusion audio engine. It describes four implementation mechanisms (heterogeneous scheduling, mutable state, source blending, windowed decode) and reports measured throughput (12.3 completions/s) on specific hardware. No equations, parameter fits, uniqueness theorems, or first-principles derivations appear anywhere in the text; therefore no step can reduce by construction to its own inputs. The performance numbers are direct benchmarks, not predictions derived from the mechanisms themselves. The paper is self-contained against external benchmarks and contains no self-citation chains that bear load on any claimed result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation
Kodaira et al. “StreamDiffusion: A Pipeline-level Solution for Real-time Interactive Generation.” ICCV 2025
2025
-
[2]
Looking Backward: Streaming Video-to-Video Translation with Feature Banks
Liang et al. “Looking Backward: Streaming Video-to-Video Translation with Feature Banks.” ICLR 2025
2025
-
[3]
ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation
Gong et al. “ACE-Step 1.5: Pushing the Boundaries of Open-Source Music Generation.” arXiv:2602.00744, 2026
-
[4]
Flow Matching for Generative Modeling
Lipman et al. “Flow Matching for Generative Modeling.” ICLR 2023
2023
-
[5]
Scalable Diffusion Models with Transformers
Peebles and Xie. “Scalable Diffusion Models with Transformers.” ICCV 2023
2023
-
[6]
Simple and Controllable Music Generation
Copet et al. “Simple and Controllable Music Generation.” NeurIPS 2023
2023
-
[7]
Fast Timing-Conditioned Latent Audio Diffusion
Evans et al. “Fast Timing-Conditioned Latent Audio Diffusion.” ICML 2024
2024
-
[8]
AudioLDM: Text-to-Audio Generation with Latent Diffusion Models
Liu et al. “AudioLDM: Text-to-Audio Generation with Latent Diffusion Models.” ICML 2023
2023
-
[9]
Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation
Wu et al. “Large-Scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-Caption Augmentation.” ICASSP 2023
2023
-
[10]
Frechet Audio Distance: A Reference-Free Metric for Evaluating Music Enhancement Algorithms
Kilgour et al. “Frechet Audio Distance: A Reference-Free Metric for Evaluating Music Enhancement Algorithms.” Interspeech 2019
2019
-
[11]
High-Resolution Image Synthesis with Latent Diffusion Models
Rombach et al. “High-Resolution Image Synthesis with Latent Diffusion Models.” CVPR 2022
2022
-
[12]
Denoising Diffusion Probabilistic Models
Ho et al. “Denoising Diffusion Probabilistic Models.” NeurIPS 2020
2020
-
[13]
Score-Based Generative Modeling through Stochastic Dif- ferential Equations
Song et al. “Score-Based Generative Modeling through Stochastic Dif- ferential Equations.” ICLR 2021
2021
-
[14]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Luo et al. “Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference.” arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Adding Conditional Control to Text-to-Image Diffusion Models
Zhang et al. “Adding Conditional Control to Text-to-Image Diffusion Models.” ICCV 2023
2023
-
[16]
T2I-Adapter: Learning Adapters to Dig out More Control- lable Ability for Text-to-Image Diffusion Models
Mou et al. “T2I-Adapter: Learning Adapters to Dig out More Control- lable Ability for Text-to-Image Diffusion Models.” AAAI 2024
2024
-
[17]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Ye et al. “IP-Adapter: Text Compatible Image Prompt Adapter for Text- to-Image Diffusion Models.” arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
DDSP: Differentiable Digital Signal Processing
Engel et al. “DDSP: Differentiable Digital Signal Processing.” ICLR 2020
2020
-
[19]
RA VE: A variational autoencoder for fast and high- quality neural audio synthesis
Caillon and Esling. “RA VE: A variational autoencoder for fast and high- quality neural audio synthesis.” arXiv:2111.05011, 2021
-
[20]
Lyria Team, Google DeepMind. “Live Music Models.” arXiv:2508.04651, 2025
-
[21]
Masked Audio Generation using a Single Non-Autoregressive Transformer
Ziv et al. “Masked Audio Generation using a Single Non-Autoregressive Transformer.” ICLR 2024
2024
-
[22]
Presto! Distilling Steps and Layers for Accelerating Music Generation
Novack et al. “Presto! Distilling Steps and Layers for Accelerating Music Generation.” ICLR 2025
2025
-
[23]
StreamDiffusion (fork): runtime parameter updates with in-place timestep-schedule editing
daydreamlive. “StreamDiffusion (fork): runtime parameter updates with in-place timestep-schedule editing.” GitHub, https://github.com/ daydreamlive/StreamDiffusion, 2025
2025
-
[24]
FMA: A Dataset for Music Analysis
Defferrard et al. “FMA: A Dataset for Music Analysis.” ISMIR 2017
2017
-
[25]
Problems and Prospects for Intimate Musical Control of Computers
Wessel and Wright. “Problems and Prospects for Intimate Musical Control of Computers.” Computer Music Journal 26(3), 2002
2002
-
[26]
ComfyUI RyanOnTheInside: reactive (audio/MIDI/motion-driven) per-frame control nodes, including ACE- Step guiders
R. Fosdick (RyanOnTheInside). “ComfyUI RyanOnTheInside: reactive (audio/MIDI/motion-driven) per-frame control nodes, including ACE- Step guiders.” GitHub, https://github.com/ryanontheinside/ComfyUI RyanOnTheInside
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.