ScanTwin: Simulating Performance Regressions Without Access to Tenant Data
Pith reviewed 2026-06-29 09:06 UTC · model grok-4.3
The pith
ScanTwin extracts privacy-protected Parquet row-group sketches to reproduce scan pruning and timing without tenant data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
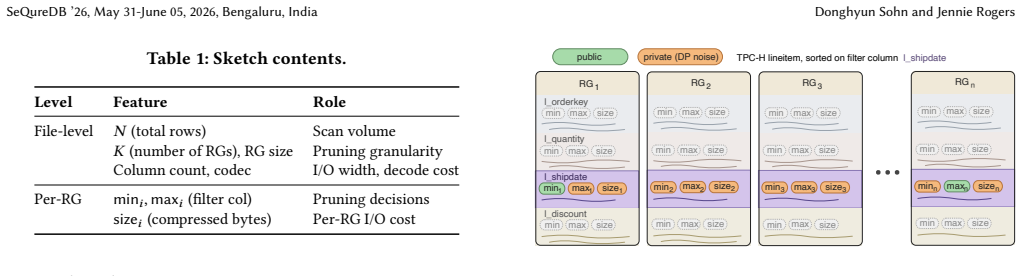
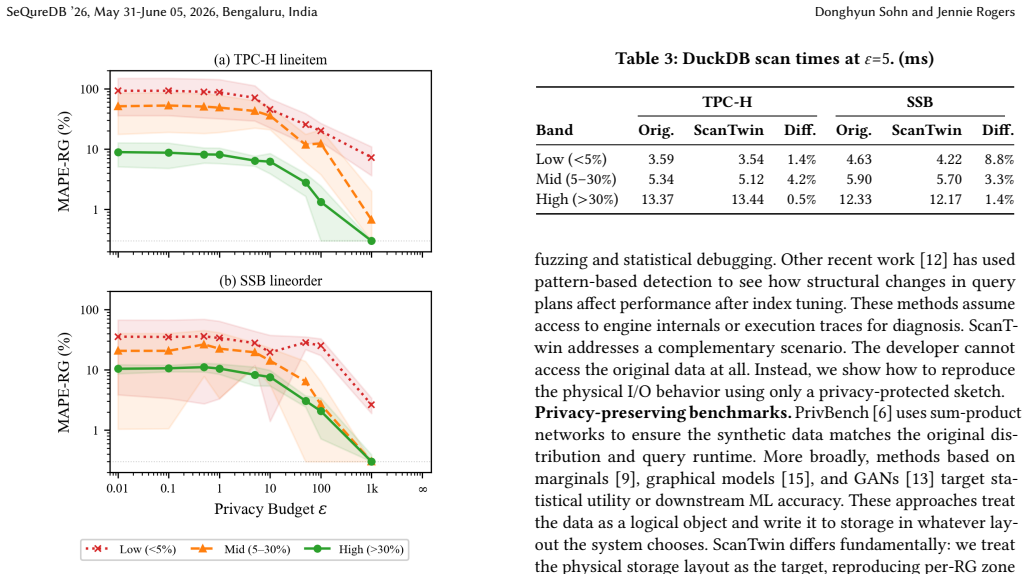
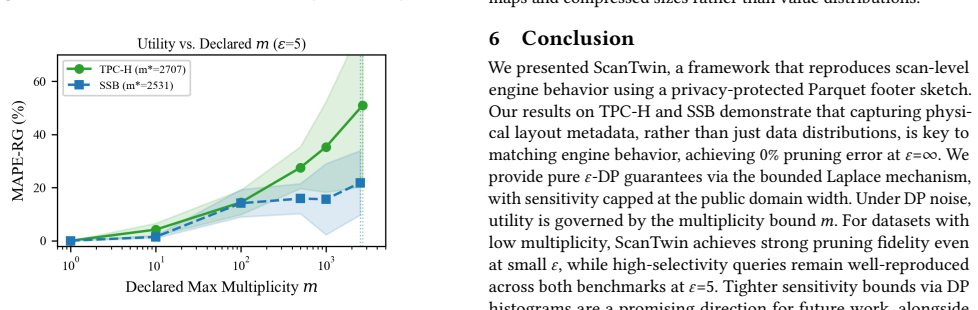
ScanTwin extracts a per-row-group sketch containing boundary values and compressed sizes from the Parquet footer and releases it under ε-differential privacy using boundary parameterization. This sketch is sufficient to drive row-group pruning decisions and scan timing behavior in an engine such as DuckDB, producing 0 percent pruning error and less than 1 percent byte error at ε=∞, and below 8.5 percent pruning error for queries with selectivity above 30 percent at ε=5 on both TPC-H and SSB.
What carries the argument
Per-row-group sketches of boundary values and compressed sizes, released under ε-differential privacy via boundary parameterization, that preserve the layout properties used for pruning and timing.
If this is right
- Developers can reproduce tenant-specific scan regressions locally without any access to the tenant data.
- High-selectivity queries retain usable pruning accuracy under moderate privacy budgets on standard benchmarks.
- DuckDB scan timing on the released sketches closely follows the timing observed on the original files.
- The approach works for both TPC-H and SSB at the reported row counts and privacy levels.
Where Pith is reading between the lines
- The same sketch format could be applied to other columnar formats that store row-group metadata.
- Varying the privacy parameter ε across a range would let teams choose the accuracy-privacy tradeoff for different debugging tasks.
- If the sketches also captured column statistics beyond boundaries, pruning simulation for more complex predicates might improve.
Load-bearing premise
The noisy boundary values and sizes from the Parquet footer still produce the same pruning decisions and scan costs as the original data.
What would settle it
Run the same queries on DuckDB using both the original Parquet files and the ScanTwin sketches at ε=5; if per-query scan times diverge by more than a few percent even when pruning error stays low, the claim fails.
Figures
read the original abstract
In cloud data platforms, developers often encounter performance regressions that occur in specific tenant datasets. However, due to confidentiality constraints, they cannot access the original data, which makes it difficult to reproduce these regressions locally. Current methods for synthetic data usually focus on statistical properties, such as matching data distributions or improving query accuracy. However, they overlook the physical properties that control how the engine behaves during scans, including row-group pruning. We propose ScanTwin, a lightweight framework that extracts a per-row-group sketch from the Parquet footer, including boundary values and compressed sizes, and releases them under $\varepsilon$-differential privacy using a boundary parameterization. On TPC-H and SSB (6M rows), ScanTwin achieves 0% pruning error and less than 1% byte error at $\varepsilon{=}\infty$. Under $\varepsilon{=}5$, high-selectivity queries ($>$30%) incur below 8.5% pruning error on both datasets, and per-query scan timing on DuckDB closely tracks the original.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ScanTwin, a framework that extracts per-row-group sketches (boundary values and compressed sizes) from Parquet footers and releases them under ε-differential privacy using a boundary parameterization. The goal is to simulate scan performance regressions on tenant data without direct access. On TPC-H and SSB (6M rows), it reports 0% pruning error and <1% byte error at ε=∞; under ε=5, high-selectivity queries (>30%) incur <8.5% pruning error on both datasets, with per-query DuckDB scan timings closely tracking the original.
Significance. If the timing fidelity claim holds, the work addresses a practical need in multi-tenant cloud databases by enabling local reproduction of regressions from privacy-preserving metadata alone. The evaluation on independent public benchmarks (TPC-H, SSB) is a positive for reproducibility.
major comments (3)
- [Abstract/Evaluation] Abstract and Evaluation: The central claim that DuckDB scan timings closely track the original under ε=5 rests on pruning decisions, yet only aggregate pruning error (<8.5% for >30% selectivity queries) is reported; no per-query set-overlap, exact-match rate for scanned row-groups, or byte-error at ε=5 is provided. These metrics are required to confirm that I/O volumes and thus timings are preserved, as independent Laplace noise on boundaries can flip individual pruning decisions near predicates even when aggregate error remains small.
- [Evaluation] Evaluation methodology: The reported error percentages lack error bars, full details on how the >30% selectivity threshold was chosen, or sensitivity analysis for boundary noise application; without these, the concrete performance claims cannot be assessed for robustness.
- [Boundary parameterization] Boundary parameterization section: The assumption that min/max plus compressed sizes released under ε-DP suffice to preserve physical pruning and scan-cost properties needs direct validation (e.g., via per-row-group decision fidelity), as the paper's aggregate metric does not rule out timing divergence from flipped pruning decisions.
minor comments (1)
- Clarify the exact sensitivity used for Laplace noise on boundary values and how compressed sizes are handled under DP.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and agree to incorporate additional metrics and analyses to strengthen the evaluation.
read point-by-point responses
-
Referee: [Abstract/Evaluation] Abstract and Evaluation: The central claim that DuckDB scan timings closely track the original under ε=5 rests on pruning decisions, yet only aggregate pruning error (<8.5% for >30% selectivity queries) is reported; no per-query set-overlap, exact-match rate for scanned row-groups, or byte-error at ε=5 is provided. These metrics are required to confirm that I/O volumes and thus timings are preserved, as independent Laplace noise on boundaries can flip individual pruning decisions near predicates even when aggregate error remains small.
Authors: We agree that per-query metrics would strengthen the evidence. While the reported per-query DuckDB timings already indicate that I/O volumes are preserved in practice, we will add set-overlap, exact-match rates for scanned row-groups, and byte-error at ε=5 to the revised evaluation section. revision: yes
-
Referee: [Evaluation] Evaluation methodology: The reported error percentages lack error bars, full details on how the >30% selectivity threshold was chosen, or sensitivity analysis for boundary noise application; without these, the concrete performance claims cannot be assessed for robustness.
Authors: We will revise the evaluation to include error bars on the reported percentages, explain the rationale for the >30% selectivity threshold (focusing on queries where row-group pruning has the largest impact on scan cost), and add a sensitivity analysis for boundary noise. revision: yes
-
Referee: [Boundary parameterization] Boundary parameterization section: The assumption that min/max plus compressed sizes released under ε-DP suffice to preserve physical pruning and scan-cost properties needs direct validation (e.g., via per-row-group decision fidelity), as the paper's aggregate metric does not rule out timing divergence from flipped pruning decisions.
Authors: The close tracking of per-query DuckDB timings provides empirical support that scan-cost properties are preserved overall. Nevertheless, we will add explicit per-row-group decision fidelity metrics in the revision to directly validate the boundary parameterization as requested. revision: yes
Circularity Check
No circularity; claims rest on independent empirical evaluation
full rationale
The paper introduces ScanTwin as a DP release mechanism for Parquet row-group sketches and evaluates it directly on external public benchmarks (TPC-H, SSB). Reported metrics (pruning error, byte error, DuckDB scan timing) are measured outcomes on those datasets rather than quantities derived from the method's own parameters or equations. No self-definitional relations, fitted inputs renamed as predictions, or load-bearing self-citations appear in the provided text; the central results do not reduce to the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- epsilon
axioms (1)
- domain assumption Parquet footer boundary values and compressed sizes determine row-group pruning decisions during scans
Reference graph
Works this paper leans on
-
[1]
Clustering Keys & Clustered Tables
2024. Clustering Keys & Clustered Tables. https://docs.snowflake.com/en/user- guide/tables-clustering-keys
2024
-
[2]
File Formats — DuckDB Documentation
2024. File Formats — DuckDB Documentation. https://duckdb.org/docs/stable/ guides/performance/file_formats
2024
-
[3]
When to partition tables on Databricks
2024. When to partition tables on Databricks. https://docs.databricks.com/aws/ en/tables/partitions
2024
-
[4]
Cynthia Dwork, Frank McSherry, Kobbi Nissim, and Adam Smith. 2006. Calibrat- ing Noise to Sensitivity in Private Data Analysis. InTheory of Cryptography
2006
-
[5]
Cynthia Dwork and Aaron Roth. 2014. The Algorithmic Foundations of Differen- tial Privacy.Foundations and Trends in Theoretical Computer Science9, 3–4 (2014), 211–407
2014
-
[6]
Yunqing Ge, Jianbin Qin, Shuyuan Zheng, Yongrui Zhong, Bo Tang, Yu-Xuan Qiu, Rui Mao, Ye Yuan, Makoto Onizuka, and Chuan Xiao. 2024. Privacy-Enhanced 4 ScanTwin: Simulating Performance Regressions Without Access to Tenant Data SeQureDB ’26, May 31-June 05, 2026, Bengaluru, India Database Synthesis for Benchmark Publishing.Proceedings of the VLDB Endow- me...
-
[7]
Naoise Holohan, Spiros Antonatos, Stefano Braghin, and Pól Mac Aonghusa
-
[8]
The Bounded Laplace Mechanism in Differential Privacy.Journal of Privacy and Confidentiality10, 1 (2019). doi:10.29012/jpc.715
-
[9]
Jinho Jung, Hong Hu, Joy Arulraj, Taesoo Kim, and Woonhak Kang. 2020. APOLLO: Automatic detection and diagnosis of performance regressions in database systems.Proceedings of the VLDB Endowment13, 1 (2020), 57–70
2020
-
[10]
Ryan McKenna, Brendan Sheldon, and Gerome Miklau. 2022. AIM: An Adaptive and Iterative Mechanism for Differentially Private Synthetic Data. InProceedings of the 39th International Conference on Machine Learning (ICML)
2022
-
[11]
2009.Star Schema Benchmark
Pat O’Neil, Betty O’Neil, and Xuedong Chen. 2009.Star Schema Benchmark. Technical Report Revision 3. University of Massachusetts at Boston
2009
-
[12]
Transaction Processing Performance Council. 2023. TPC-H benchmark specifica- tion.Published at http://www.tpc.org(2023)
2023
-
[13]
Wentao Wu, Anshuman Dutt, Gaoxiang Xu, Vivek Narasayya, and Surajit Chaud- huri. 2026. Understanding and Detecting Query Performance Regression in Practical Index Tuning.Proceedings of the ACM on Management of Data (SIG- MOD)3, 6 (2026)
2026
-
[14]
Liyang Xie, Kexin Lin, Shu Wang, Fei Wang, and Jiayu Zhou. 2018. Differentially Private Generative Adversarial Network.arXiv preprint arXiv:1802.06739(2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
Jia Xu, Zhenjie Zhang, Xiaokui Xiao, Yin Yang, Ge Yu, and Marianne Winslett
-
[16]
Differentially Private Histogram Publication.The VLDB Journal22, 6 (2013), 797–822. doi:10.1007/s00778-013-0309-y
-
[17]
Procopiuc, Divesh Srivastava, and Xiaokui Xiao
Jun Zhang, Graham Cormode, Cecilia M. Procopiuc, Divesh Srivastava, and Xiaokui Xiao. 2017. PrivBayes: Private Data Release via Bayesian Networks. ACM Transactions on Database Systems42, 4 (2017). 5
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.