One Ring to Shuffle Them All: Scalable Intra-Process Data Redistribution with Ring-Buffer Shuffle in Redpanda Oxla
Pith reviewed 2026-06-29 08:59 UTC · model grok-4.3
The pith
A ring-buffer shuffle design scales intra-process data redistribution to hundreds of cores with amortized O(1) synchronization per batch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ring-buffer streaming shuffle addresses scaling failures in data redistribution by using lock-free atomic slot acquisition into fixed-size batch groups, achieving amortized O(1) synchronization cost per batch and O(M) memory independent of input size, with measured gains on 72-core and 192-core systems.
What carries the argument
Ring-buffer streaming shuffle design with lock-free atomic slot acquisition into fixed-size batch groups.
If this is right
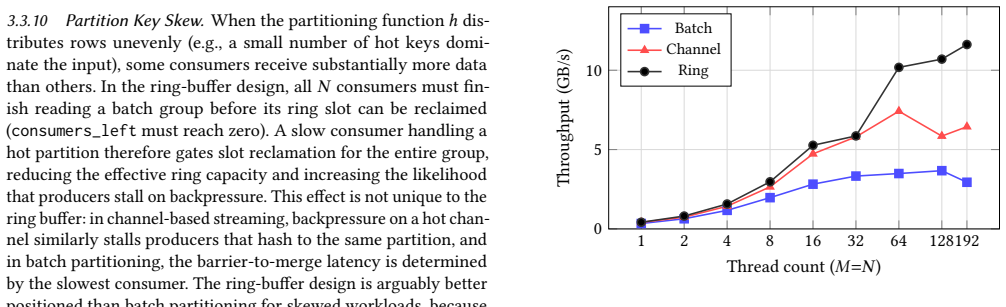
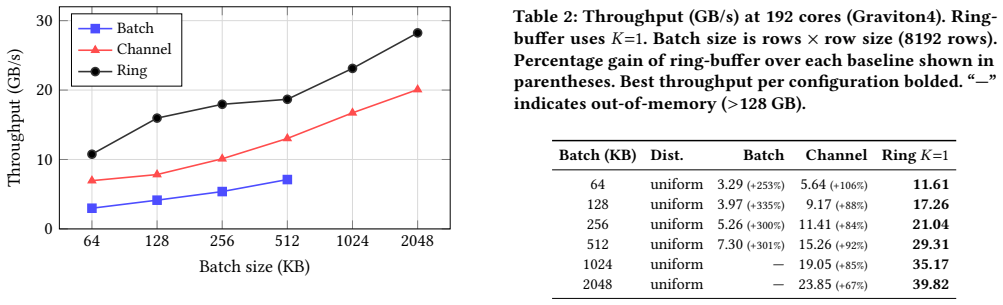
- On 72-core single-socket systems, ring buffer outperforms channel streaming by up to 44% and batch partitioning by up to 79%.
- At 192 cores, the advantage grows to over 100% over channel streaming and over 300% versus batch partitioning.
- The design uses O(M) memory independent of input size.
- It has been implemented and used in production in Redpanda's Oxla query engine for two years.
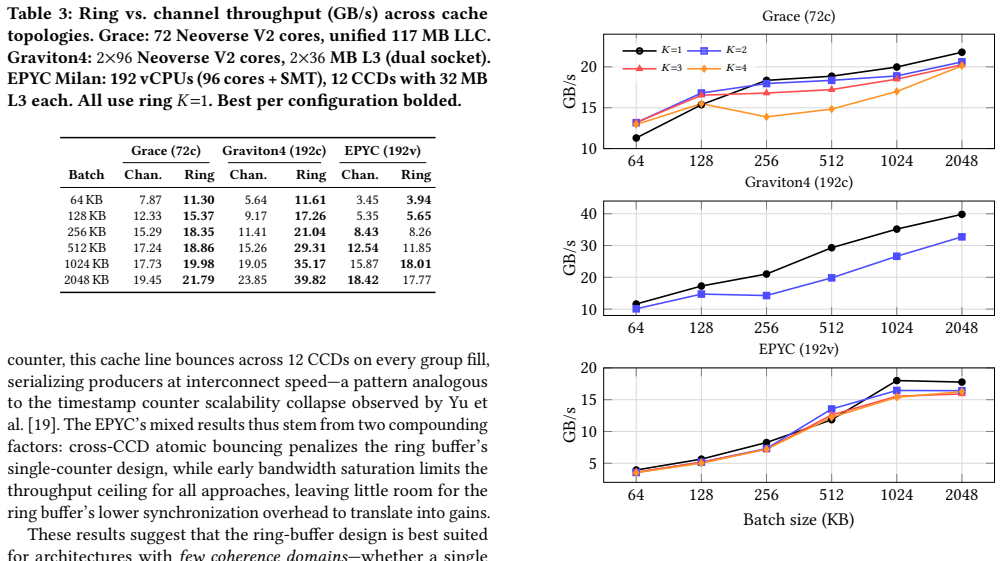
- On chiplet architectures, the shared atomic counter can become a bottleneck, making channel streaming competitive.
Where Pith is reading between the lines
- This approach may extend to other many-core systems where synchronization overhead limits parallel query performance.
- Adaptive selection between ring-buffer and channel methods based on detected architecture could optimize across workloads.
- Improvements in chip interconnects could further enhance the ring-buffer's advantages on future hardware.
Load-bearing premise
The shared atomic counter for slot acquisition maintains amortized O(1) cost without becoming a cross-die bottleneck on target architectures.
What would settle it
Performance measurements on a high-core-count non-chiplet system where the ring buffer does not show the reported speedups, or direct profiling showing the atomic counter as a dominant cost on chiplet designs.
Figures


read the original abstract
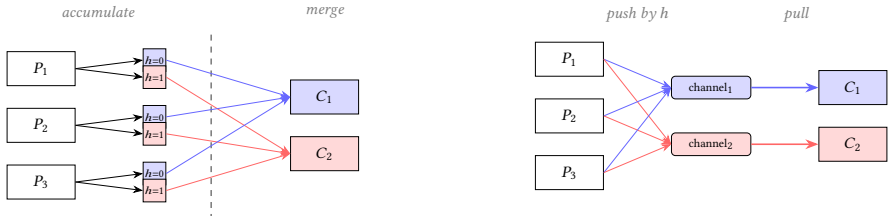
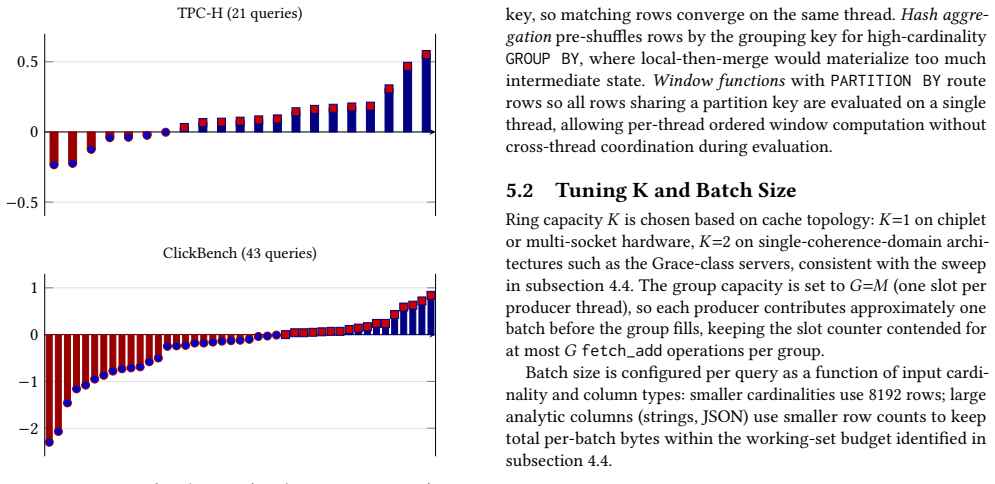
As server CPUs scale to dozens and now hundreds of cores per socket, parallel query engines must rethink how they redistribute data between threads. Partitioned operators such as hash joins and aggregations require frequent data redistribution across threads, yet existing intra-process shuffle designs fundamentally fail to scale with core count: batch partitioning avoids cross-thread synchronization in the hot path but materializes all intermediate data, introduces a global producer/consumer barrier, and requires a consumption approach with low cache locality, while channel-based streaming avoids materialization but incurs per-channel synchronization that scales poorly with core count. As core counts rise, these architectural tradeoffs increasingly prevent engines from fully utilizing modern hardware. We present a ring-buffer streaming shuffle design that addresses these shortcomings through lock-free atomic slot acquisition into fixed-size batch groups, achieving amortized O(1) synchronization cost per batch and O(M) memory independent of input size. Ring-buffer shuffle has been implemented in Redpanda's Oxla query engine for two years, where it currently powers production queries for Redpanda SQL users. We evaluate all three approaches on a 72-core NVIDIA GraceHopper, a 192-core dual-socket AWS Graviton4, and a 96-core (192-thread) AMD EPYC. On a 72-core single-socket system the ring buffer outperforms channel streaming by up to 44% and batch partitioning by up to 79%; at 192 cores the advantage over channel grows to over 100% and over 300% versus batch partitioning. Even so, on chiplet architectures with many partitioned L3 caches, the shared atomic counter becomes a cross-die bottleneck and channel-based streaming remains competitive. End-to-end Graviton4 evaluation on TPC-H (21 queries) and ClickBench (43 queries) shows the advantage is workload-shape-dependent.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that existing intra-process shuffle methods (batch partitioning and channel streaming) fail to scale with rising core counts in parallel query engines, and introduces a ring-buffer shuffle design using lock-free atomic slot acquisition into fixed-size batches. This achieves amortized O(1) synchronization cost per batch and O(M) memory independent of input size. The design has been implemented and used in production for two years in Redpanda's Oxla engine. Evaluations on 72-core GraceHopper, 192-core Graviton4, and 96-core EPYC systems report speedups of up to 44%/79% on 72 cores and >100%/>300% at 192 cores versus the baselines, with end-to-end TPC-H (21 queries) and ClickBench (43 queries) results on Graviton4 showing workload-shape dependence; the abstract notes that the shared atomic counter becomes a cross-die bottleneck on chiplet architectures.
Significance. If the central claims hold after addressing the noted limitations, this represents a practical engineering contribution to scaling intra-process data movement in many-core database systems. Strengths include the production deployment, the explicit O(1) sync and O(M) memory bounds, and the multi-architecture evaluation with real workloads. The architecture-specific caveat on chiplets is a positive sign of realism, though it tempers the universality of the scalability claims.
major comments (1)
- [Abstract] Abstract: The performance claims for the 192-core Graviton4 (>100% over channel, >300% over batch) and 96-core EPYC systems rest on the amortized O(1) cost of the shared atomic counter for slot acquisition. However, the abstract states that this counter becomes a cross-die bottleneck on chiplet architectures with partitioned L3 caches (directly applicable to Graviton4 and EPYC), making channel streaming competitive. This tension is load-bearing for the scalability claims and requires explicit resolution in the evaluation, such as per-architecture breakdowns or conditions under which the O(1) bound holds.
minor comments (1)
- [Abstract] Abstract: The reported speedups lack any mention of error bars, number of repetitions, or benchmark methodology details (e.g., input cardinalities, data distributions, or thread pinning), which should be provided in the evaluation section to support reproducibility and assessment of the results.
Simulated Author's Rebuttal
We thank the referee for identifying the tension between the reported speedups on 192-core Graviton4 and 96-core EPYC systems and the abstract's own caveat about the shared atomic counter becoming a cross-die bottleneck on chiplet architectures. We agree this requires explicit clarification to avoid overstatement of universality. We will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The performance claims for the 192-core Graviton4 (>100% over channel, >300% over batch) and 96-core EPYC systems rest on the amortized O(1) cost of the shared atomic counter for slot acquisition. However, the abstract states that this counter becomes a cross-die bottleneck on chiplet architectures with partitioned L3 caches (directly applicable to Graviton4 and EPYC), making channel streaming competitive. This tension is load-bearing for the scalability claims and requires explicit resolution in the evaluation, such as per-architecture breakdowns or conditions under which the O(1) bound holds.
Authors: We acknowledge the valid point. The abstract already notes the chiplet caveat, but the presentation of the >100%/>300% figures for the 192-core Graviton4 (a dual-socket chiplet design) and 96-core EPYC without accompanying per-architecture qualification creates the tension identified. In revision we will (1) add a dedicated subsection in the evaluation that reports per-architecture microbenchmark results with explicit call-outs for when the ring-buffer's O(1) amortized bound holds versus when cross-die traffic makes channel streaming competitive, and (2) qualify the abstract numbers with a parenthetical reference to the conditions (single-socket vs. multi-socket chiplet) under which each speedup was measured. This directly resolves the load-bearing issue for the scalability claims. revision: yes
Circularity Check
No circularity: engineering design with external benchmarks and acknowledged limitations
full rationale
The paper presents a ring-buffer shuffle design and reports empirical speedups on specific hardware. No derivation chain, fitted parameters, predictions, or first-principles results exist that could reduce to inputs by construction. The O(1) amortized synchronization claim is an engineering assertion evaluated via benchmarks; the abstract explicitly flags its failure mode on chiplet architectures rather than smuggling it in via self-citation or definition. No self-citation is load-bearing for the central claim, and no ansatz or renaming of known results occurs. This is a standard non-circular engineering contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cagri Balkesen, Jens Teubner, Gustavo Alonso, and M. Tamer Özsu. 2013. Main- Memory Hash Joins on Multi-Core CPUs: Tuning to the Underlying Hardware. 12 InProceedings of the 29th IEEE International Conference on Data Engineering. 362–373. https://doi.org/10.1109/ICDE.2013.6544839
-
[2]
Maximilian Bandle and Jana Giceva. 2021. Database Technology for the Masses: Sub-Operators as First-Class Entities.Proceedings of the VLDB Endowment14, 11 (2021), 2483–2490. https://doi.org/10.14778/3476249.3476296
-
[3]
Maximilian Bandle, Jana Giceva, and Thomas Neumann. 2021. To Partition, or Not to Partition, That is the Join Question in a Real System. InProceedings of the 2021 International Conference on Management of Data. 168–180. https: //doi.org/10.1145/3448016.3452831
-
[4]
Alexander Baumstark and Constantin Pohl. 2019. Lock-free Data Structures for Data Stream Processing—A Closer Look.Datenbank-Spektrum19, 3 (2019), 209–218. https://doi.org/10.1007/s13222-019-00329-4
-
[5]
Alessandro Fogli, Bo Zhao, Peter Pietzuch, and Jana Giceva. 2025. ARCAS: Adaptive Runtime System for Chiplet-Aware Scheduling. (2025). https://doi. org/10.48550/arXiv.2503.11460 arXiv:2503.11460 [cs.DC]
-
[6]
Goetz Graefe. 1990. Encapsulation of Parallelism in the Volcano Query Processing System. InProceedings of the 1990 ACM SIGMOD International Conference on Management of Data. 102–111. https://doi.org/10.1145/93597.98720
-
[7]
Goetz Graefe. 1994. Volcano—An Extensible and Parallel Query Evaluation System.IEEE Transactions on Knowledge and Data Engineering6, 1 (1994), 120–
1994
-
[8]
https://doi.org/10.1109/69.273032
-
[9]
Laurens Kuiper, Mark Raasveldt, Hannes Mühleisen, and Peter Boncz. 2025. Saving Private Hash Join.Proceedings of the VLDB Endowment18, 10 (2025), 2748–2761. https://doi.org/10.14778/3742728.3742762
-
[10]
Andrew Lamb, Yijie Shen, Daniël Heres, Jayjeet Chakraborty, Mehmet Ozan Kabak, Liang-Chi Hsieh, and Chao Sun. 2024. Apache Arrow DataFusion: A Fast, Embeddable, Modular Analytic Query Engine. InCompanion of the 2024 International Conference on Management of Data. https://doi.org/10.1145/3626246. 3653368
-
[11]
Viktor Leis, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2014. Morsel- Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many- Core Age. InProceedings of the 2014 ACM SIGMOD International Conference on Management of Data. 743–754. https://doi.org/10.1145/2588555.2610507
-
[12]
Pedro Pedreira, Orri Erling, Masha Basmanova, Kevin Wilfong, Laith Sakka, Krishna Pai, Wei He, and Biswapesh Chattopadhyay. 2022. Velox: Meta’s Unified Execution Engine.Proceedings of the VLDB Endowment15, 12 (2022), 3372–3384. https://doi.org/10.14778/3554821.3554829
-
[13]
Orestis Polychroniou and Kenneth A. Ross. 2014. A Comprehensive Study of Main-Memory Partitioning and Its Application to Large-Scale Comparison- and Radix-Sort. InProceedings of the 2014 ACM SIGMOD International Conference on Management of Data. 755–766. https://doi.org/10.1145/2588555.2610522
-
[14]
Wolf Rödiger, Tobias Mühlbauer, Alfons Kemper, and Thomas Neumann. 2016. High-Speed Query Processing over High-Speed Networks.Proceedings of the VLDB Endowment9, 4 (2016), 228–239. https://doi.org/10.14778/2856318.2856319
-
[15]
Raghav Sethi, Masha Basmanova, Andrii Rosa, et al. 2023. Presto: A Decade of SQL Analytics at Meta. InProceedings of the 2023 ACM SIGMOD International Conference on Management of Data. https://doi.org/10.1145/3589769
-
[16]
StarRocks Contributors. 2025. StarRocks: A High-Performance Analytical Data- base. https://github.com/StarRocks/starrocks A Linux Foundation project
2025
-
[17]
2018.Parallel Hash
The PostgreSQL Global Development Group. 2018.Parallel Hash. https://wiki. postgresql.org/wiki/Parallel_Hash Introduced in PostgreSQL 11
2018
-
[18]
Martin Thompson, Dave Farley, Michael Barker, Patricia Gee, and Andrew Stew- art. 2011. Disruptor: High Performance Alternative to Bounded Queues for Exchanging Data Between Concurrent Threads. https://lmax-exchange.github. io/disruptor/disruptor.html
2011
-
[19]
Daniel Xue and Ryan Marcus. 2025. Global Hash Tables Strike Back! An Analysis of Parallel GROUP BY Aggregation.arXiv preprint arXiv:2505.04153(2025). https://doi.org/10.48550/arXiv.2505.04153
-
[20]
Xiangyao Yu, George Bezerra, Andrew Pavlo, Srinivas Devadas, and Michael Stonebraker. 2014. Staring into the Abyss: An Evaluation of Concurrency Control with One Thousand Cores.Proceedings of the VLDB Endowment8, 3 (2014), 209–
2014
-
[21]
https://doi.org/10.14778/2735508.2735511 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.