On the Practice of Scaling Search Conversion Rate Prediction
Pith reviewed 2026-06-29 06:01 UTC · model grok-4.3
The pith
The effects of scaling model backbone, embedding size, and training data on search CVR prediction are largely independent and additive.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that scaling backbone computation, embedding parameter size, and training data volume produce largely independent and additive quality gains for search CVR models. On a large production dataset the authors find that choosing the right backbone and scaling factors matters most, that a streamlined warm-start strategy accelerates training iterations, and that inference optimizations such as decoupled graph execution and dynamic batching permit low-latency GPU serving. These steps together allow deployment of a model trained on 2.5 times more data with 8 times more inference compute while keeping latency nearly unchanged, delivering a combined 2.6 percent lift in conversion
What carries the argument
The independence and additivity of scaling effects across backbone, embeddings, and data volume, which supports modular and efficient scaling decisions.
If this is right
- Scaling exploration becomes more efficient because the three factors can be varied separately rather than jointly.
- A warm-start strategy accelerates training iterations and simplifies deployment of model updates.
- Decoupled graph execution and dynamic batching enable low-latency GPU serving for high-capacity models.
- Models trained on 2.5 times more data with 8 times more inference compute can be deployed with minimal latency impact.
- Online A/B tests show a combined 2.6 percent gain in search conversion rate from the scaled models.
Where Pith is reading between the lines
- The same additive scaling pattern may appear in other ranking or recommendation tasks that rely on similar embedding-plus-backbone architectures.
- Production teams could reduce exhaustive grid searches by treating the three scaling axes as roughly orthogonal.
- Testing whether the pattern persists after the next architecture refresh would be a direct next experiment.
- Data scaling may become the highest-leverage lever once inference optimizations are in place.
Load-bearing premise
The observed independence and additivity of scaling effects will hold for the production dataset and architectures tested and will generalize to future updates.
What would settle it
Running the same scaling sweeps on a new high-traffic dataset or architecture and measuring large non-additive interactions between the three factors would falsify the central claim.
Figures
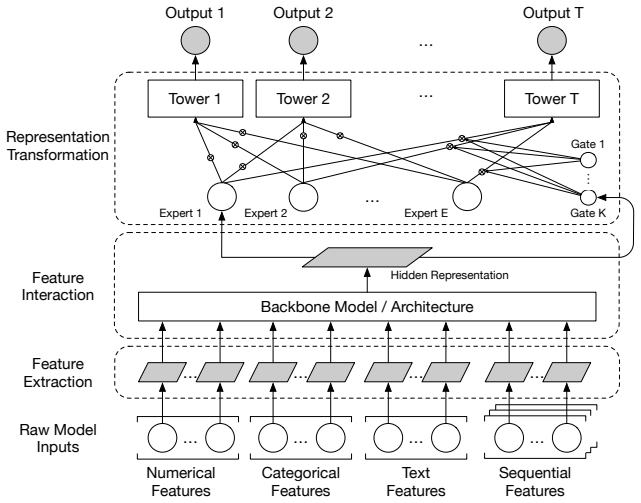
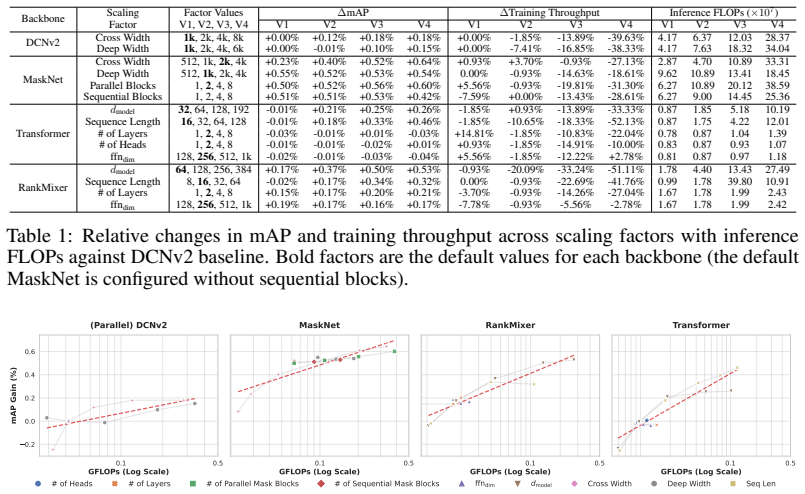
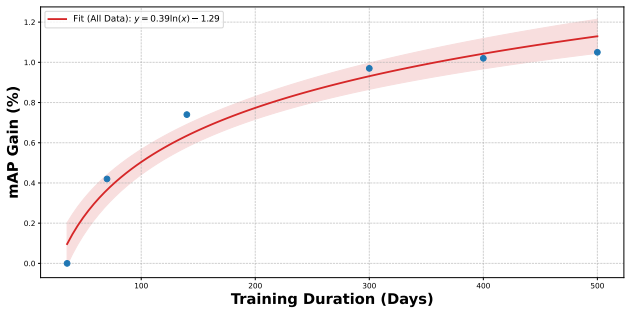

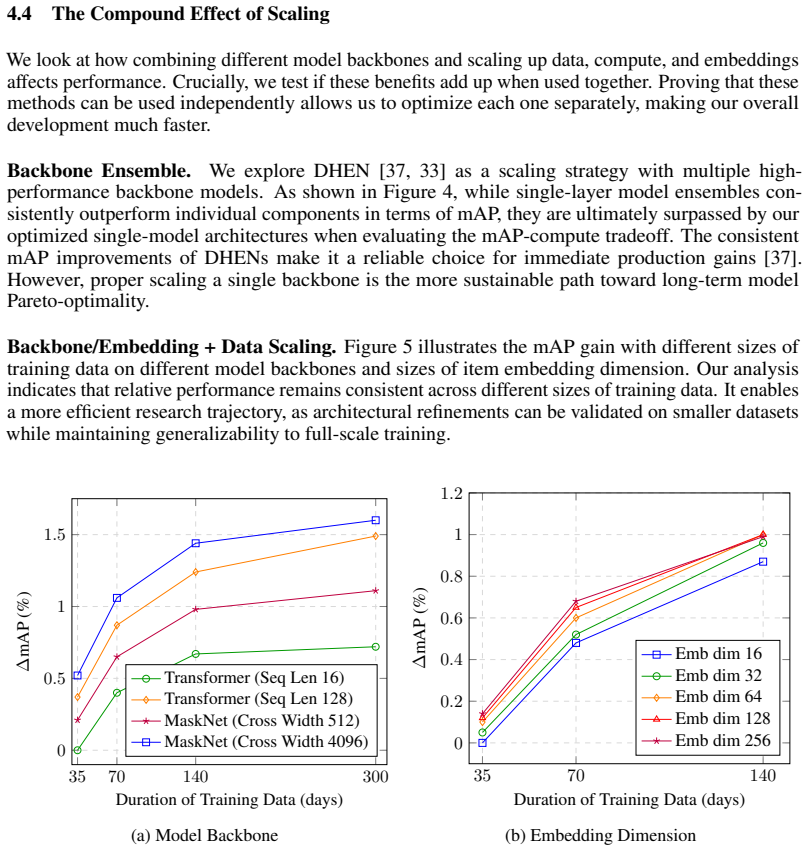
read the original abstract
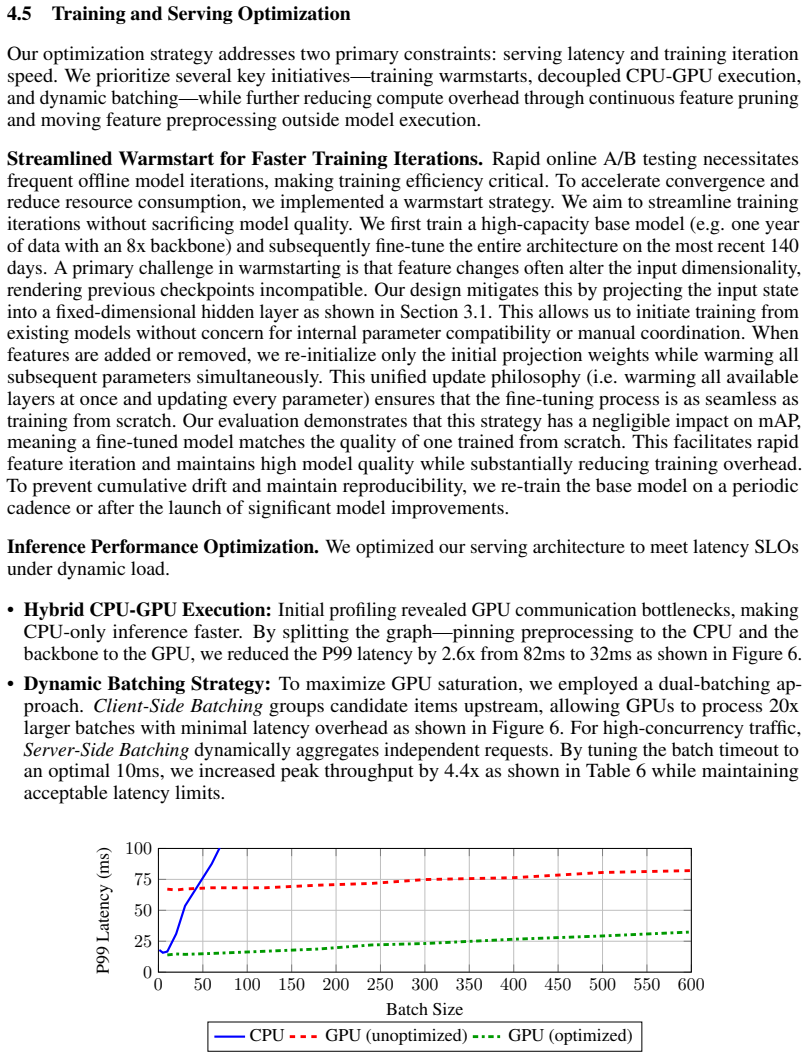
Scaling a Search Conversion Rate (CVR) prediction model, especially in high-traffic environments, presents a challenge: superior model quality needs to be balanced with strict constraints on training cost and serving latency. This paper details an effective approach for scaling modern search CVR prediction models. We begin with an empirical study to understand the scaling performance of search CVR models, analyzing how quality improves as we scale three key factors of model backbone computation, the size of embedding parameters, and the volume of training data. We use a large-scale production dataset, comprising over a year of customer interaction logs from a high-traffic e-commerce platform, to evaluate the scalability of several state-of-the-art architectures and their ensembles. Our key findings are: (1) selecting the right backbone and scaling factors is crucial; (2) the impact of scaling backbone, embedding, and data is largely independent and additive, which has implications for more efficient scaling exploration; (3) a streamlined warmstart strategy can accelerate training iterations while simplifying new updates; (4) inference optimization strategies such as decoupled graph execution and dynamic batching can enable low-latency GPU serving even for high-capacity models. Compared to a baseline of a pre-scaling production model, we ultimately deployed a model trained on 2.5x larger training data with 8x more inference compute while having minimal latency impact. Online A/B tests also demonstrate that our launches achieved a combined +2.6% gain in a key metric of search conversion rate.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts an empirical study on scaling search CVR prediction models by varying backbone computation, embedding size, and training data volume on a large production e-commerce dataset spanning over a year of logs. It evaluates several SOTA architectures and ensembles, reports that the scaling effects are largely independent and additive, describes a warm-start training strategy and inference optimizations (decoupled graph execution, dynamic batching), and validates a final deployed model (2.5x data, 8x inference compute) via online A/B tests showing a combined +2.6% gain in search conversion rate.
Significance. If the reported independence and additivity hold, the result would allow more efficient scaling exploration in production recommender systems by avoiding exhaustive joint searches over the three factors. The manuscript supplies direct production evidence via live A/B tests on the final deployed model, which is a strength.
major comments (1)
- [Abstract] Abstract: the claim that online A/B tests demonstrate a combined +2.6% gain supplies no details on experimental controls, statistical testing procedures, sample sizes, data exclusion rules, or quantification of independence, leaving the central scaling claims only partially supported.
minor comments (1)
- The manuscript would benefit from an explicit table or figure summarizing the scaling curves (backbone, embedding, data) across the tested architectures to make the additivity claim easier to verify.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that online A/B tests demonstrate a combined +2.6% gain supplies no details on experimental controls, statistical testing procedures, sample sizes, data exclusion rules, or quantification of independence, leaving the central scaling claims only partially supported.
Authors: We agree that the abstract would benefit from additional context on the A/B test methodology to better support the claims. In the revised manuscript we will update the abstract to briefly note that the tests used standard randomized traffic splitting on live search traffic, assessed significance via appropriate statistical tests at p<0.05, operated on sample sizes of tens of millions of impressions per arm, applied conventional exclusion rules for bots and anomalous sessions, and that independence/additivity of the three scaling factors was quantified via the controlled offline experiments (one-factor-at-a-time ablations) reported in Section 4. Full experimental controls, procedures, and per-factor results remain in Sections 4–5. We believe these concise additions will address the concern while respecting abstract length limits. revision: yes
Circularity Check
No significant circularity; claims rest on direct empirical measurements
full rationale
The paper reports an empirical scaling study on production logs and live A/B tests for search CVR models. The central finding—that backbone, embedding, and data scaling effects are largely independent and additive—is obtained by measuring quality changes across multiple SOTA architectures and ensembles on a fixed large dataset. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains are invoked to establish this; the result is a direct observation from the experiments described. The deployment and +2.6% A/B gain are likewise validated externally to any internal model. This is self-contained empirical work with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Que2search: fast and accurate query and document understanding for search at Facebook
Andrés Abeliuk, Behrooz Lari, Anthony Sun, Xinyu Liu, Shobana Jameel, and Wei Chang. Que2search: fast and accurate query and document understanding for search at Facebook. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 2455–2465. ACM, 2020
2020
-
[2]
An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance
Sebastian Bruch, Xuanhui Wang, Michael Bendersky, and Marc Najork. An analysis of the softmax cross entropy loss for learning-to-rank with binary relevance. InProceedings of the 2019 ACM SIGIR international conference on theory of information retrieval, pages 75–78, 2019
2019
-
[3]
Wide & deep learning for recommender systems
Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. Wide & deep learning for recommender systems. InProceedings of the 1st workshop on deep learning for recommender systems, pages 7–10, 2016
2016
-
[4]
BERT: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 Confer- ence of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapoli...
2019
-
[5]
CLD3: Google’s compact language detector 3, 2019
Daniel Gillick, David Ryan, Shankar Kumar, Andrew Kunchukuttan, and Colin Cherry. CLD3: Google’s compact language detector 3, 2019. 13
2019
-
[6]
DeepFM: A Factorization-Machine based Neural Network for CTR Prediction
Huifeng Guo, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: a factorization-machine based neural network for ctr prediction.arXiv preprint arXiv:1703.04247, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[7]
Practical lessons from predicting clicks on ads at facebook
Xinran He, Junfeng Pan, Ou Jin, Tianbing Xu, Bo Liu, Tao Xu, Yanxin Shi, Antoine Atallah, Ralf Herbrich, Stuart Bowers, et al. Practical lessons from predicting clicks on ads at facebook. InProceedings of the eighth international workshop on data mining for online advertising, pages 1–9, 2014
2014
-
[8]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[9]
Hyformer: Revisiting the roles of sequence modeling and feature interaction in ctr prediction, 2026
Yunwen Huang, Shiyong Hong, Xijun Xiao, Jinqiu Jin, Xuanyuan Luo, Zhe Wang, Zheng Chai, Shikang Wu, Yuchao Zheng, and Jingjian Lin. Hyformer: Revisiting the roles of sequence modeling and feature interaction in ctr prediction, 2026
2026
-
[10]
Wang-Cheng Kang, Derek Zhiyuan Cheng, Tiansheng Yao, Xinyang Yi, Ting Chen, Lichan Hong, and Ed H. Chi. Deep hash embeddings for efficient registry-free recommendation. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 798–808, New York, NY , USA, 2021. ACM
2021
-
[11]
Learning to embed categorical features without embedding tables for recommendation
Wang-Cheng Kang, Derek Zhiyuan Cheng, Tiansheng Yao, Xinyang Yi, Ting Chen, Lichan Hong, and Ed H Chi. Learning to embed categorical features without embedding tables for recommendation. InProceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, pages 840–850, 2021
2021
-
[12]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[13]
Adam: A Method for Stochastic Optimization
Diederik P Kingma. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[14]
Jiaqi Ma, Zhe Zhao, Xinyang Yi, Jilin Chen, Lichan Hong, and Ed H. Chi. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1930–1939. Association for Computing Machinery (ACM), 2018
1930
-
[15]
Ad click prediction: a view from the trenches
H Brendan McMahan, Gary Holt, David Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, et al. Ad click prediction: a view from the trenches. InProceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 1222–1230, 2013
2013
-
[17]
Deep Learning Recommendation Model for Personalization and Recommendation Systems
Maxim Naumov, Dheevatsa Mudigere, Hao-Jun Michael Shi, Jianyu Huang, Narayanan Sun- daraman, Jongsoo Park, Xiaodong Wang, Udit Gupta, Carole-Jean Wu, Alisson G Azzolini, et al. Deep learning recommendation model for personalization and recommendation systems. arXiv preprint arXiv:1906.00091, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[18]
Contrastive learning for conversion rate prediction
Wentao Ouyang, Rui Dong, Xiuwu Zhang, Chaofeng Guo, Jinmei Luo, Xiangzheng Liu, and Yanlong Du. Contrastive learning for conversion rate prediction. InProceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1909–1913, 2023. 14
1909
-
[19]
Metacvr: Conversion rate prediction via meta learning in small-scale recommendation scenarios
Xiaofeng Pan, Ming Li, Jing Zhang, Keren Yu, Hong Wen, Luping Wang, Chengjun Mao, and Bo Cao. Metacvr: Conversion rate prediction via meta learning in small-scale recommendation scenarios. InProceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2110–2114, 2022
2022
-
[20]
Are neural rankers still outperformed by gradient boosted decision trees? InInternational Conference on Learning Representations, 2021
Zhen Qin, Le Yan, Honglei Zhuang, Yi Tay, Rama Kumar Pasumarthi, Xuanhui Wang, Michael Bendersky, and Marc Najork. Are neural rankers still outperformed by gradient boosted decision trees? InInternational Conference on Learning Representations, 2021
2021
-
[21]
Compositional embeddings using complementary partitions for memory-efficient recommendation systems
Hao-Jun Michael Shi, Dheevatsa Mudigere, Maxim Naumov, and Jiyan Yang. Compositional embeddings using complementary partitions for memory-efficient recommendation systems. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 165–175, New York, NY , USA, 2020. ACM
2020
-
[22]
Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer. InPro- ceedings of the 28th ACM international conference on information and knowledge management, pages 1441–1450, 2019
2019
-
[23]
The bitter lesson.Incomplete Ideas (blog), 13(1):38, 2019
Richard Sutton. The bitter lesson.Incomplete Ideas (blog), 13(1):38, 2019
2019
-
[24]
Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations
Hongyan Tang, Junning Liu, Ming Zhao, and Xudong Gong. Progressive layered extraction (ple): A novel multi-task learning (mtl) model for personalized recommendations. InProceedings of the 14th ACM Conference on Recommender Systems, pages 269–278, New York, NY , USA,
-
[25]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[26]
Deep & cross network for ad click predictions
Ruoxi Wang, Bin Fu, Gang Fu, and Mingliang Wang. Deep & cross network for ad click predictions. InProceedings of the ADKDD’17, pages 1–7. 2017
2017
-
[27]
DCN V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems
Ruoxi Wang, Rakesh Shivanna, Derek Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed Chi. DCN V2: Improved deep & cross network and practical lessons for web-scale learning to rank systems. InProceedings of The Web Conference 2021, pages 1785–1797, 2021
2021
-
[28]
Zhiqiang Wang, Qingyun She, and Junlin Zhang. Masknet: Introducing feature-wise multi- plication to ctr ranking models by instance-guided mask.arXiv preprint arXiv:2102.07619, 2021
-
[29]
Songpei Xu, Shuo Wang, Daning Guo, Xinxin Guo, Qiang Xiao, Bi Huang, Guohao Wu, and Chen Luo. Climber: Toward efficient scaling laws for large recommendation models.arXiv preprint arXiv:2502.09888, 2025
-
[30]
From Scaling to Structured Expressivity: Rethinking Transformers for CTR Prediction
Bencheng Yan, Yuejie Lei, Zhiyuan Zeng, Di Wang, Kaiyi Lin, Pengjie Wang, Jian Xu, and Bo Zheng. From scaling to structured expressivity: Rethinking transformers for ctr prediction. arXiv preprint arXiv:2511.12081, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Jiaqi Zhai, Lucy Liao, Xing Liu, Yueming Wang, Rui Li, Xuan Cao, Leon Gao, Zhaojie Gong, Fangda Gu, Michael He, et al. Actions speak louder than words: Trillion-parameter sequential transducers for generative recommendations.arXiv preprint arXiv:2402.17152, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Wukong: Towards a scaling law for large-scale recommendation, 2024
Buyun Zhang, Liang Luo, Yuxin Chen, Jade Nie, Xi Liu, Daifeng Guo, Yanli Zhao, Shen Li, Yuchen Hao, Yantao Yao, Guna Lakshminarayanan, Ellie Dingqiao Wen, Jongsoo Park, Maxim Naumov, and Wenlin Chen. Wukong: Towards a scaling law for large-scale recommendation, 2024
2024
-
[33]
Dhen: A deep and hierarchical ensemble network for large-scale click-through rate prediction
Buyun Zhang, Liang Luo, Xi Liu, Jay Li, Zeliang Chen, Weilin Zhang, Xiaohan Wei, Yuchen Hao, Michael Tsang, Wenjun Wang, et al. Dhen: A deep and hierarchical ensemble network for large-scale click-through rate prediction.arXiv preprint arXiv:2203.11014, 2022. 15
-
[34]
Deep interest evolution network for click-through rate prediction
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 5941–5948, 2019
2019
-
[35]
Jie Zhu, Zhifang Fan, Xiaoxie Zhu, Yuchen Jiang, Hangyu Wang, Xintian Han, Haoran Ding, Xinmin Wang, Wenlin Zhao, Zhen Gong, et al. Rankmixer: Scaling up ranking models in industrial recommenders.arXiv preprint arXiv:2507.15551, 2025
-
[36]
Open benchmarking for click-through rate prediction
Jieming Zhu, Jinyang Liu, Shuai Yang, Qi Zhang, and Xiuqiang He. Open benchmarking for click-through rate prediction. InProceedings of the 30th ACM international conference on information & knowledge management, pages 2759–2769, 2021
2021
-
[37]
On the practice of deep hierarchical ensemble network for ad conversion rate prediction
Jinfeng Zhuang, Yinrui Li, Runze Su, Ke Xu, Zhixuan Shao, Kungang Li, Ling Leng, Han Sun, Meng Qi, Yixiong Meng, et al. On the practice of deep hierarchical ensemble network for ad conversion rate prediction. InCompanion Proceedings of the ACM on Web Conference 2025, pages 671–680, 2025. 16
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.