LLM-ALSO: LLM-Driven Adaptive Learning-Signal Optimization for Multi-Agent Reinforcement Learning
Pith reviewed 2026-06-29 00:26 UTC · model grok-4.3
The pith
LLM-ALSO decomposes reward adaptation in multi-agent RL into LLM diagnosis, proposal, and short-horizon validation to handle sparse rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
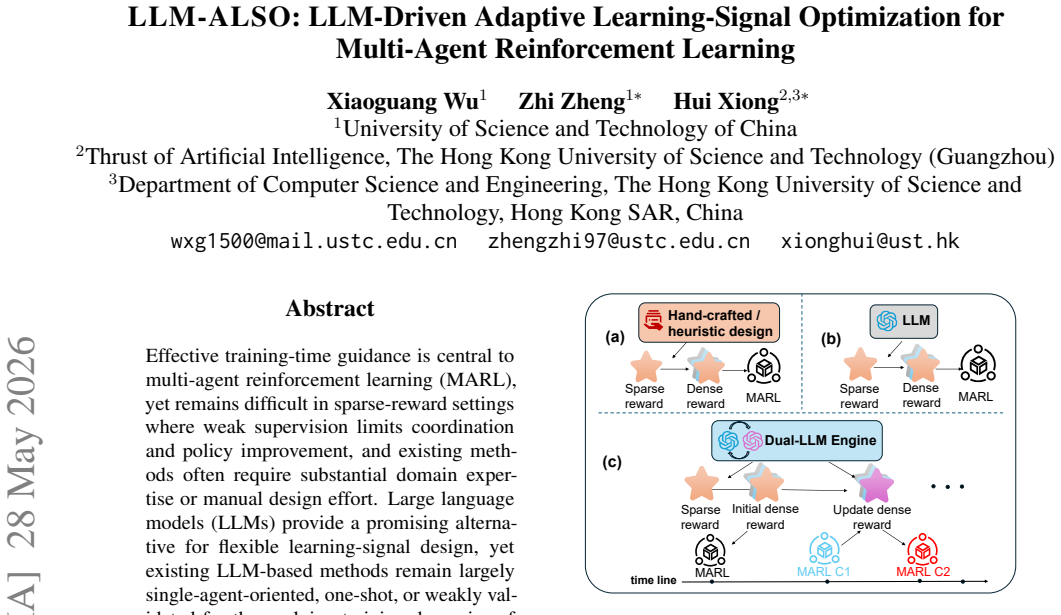
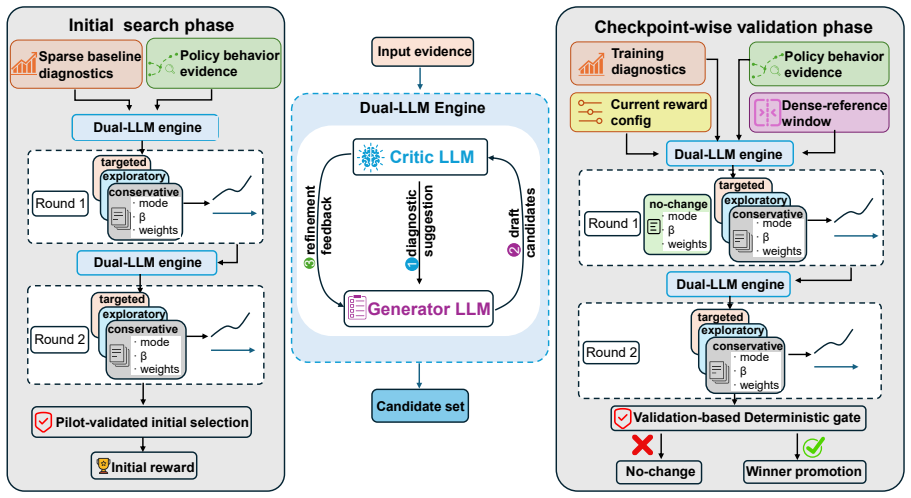
LLM-ALSO is an iterative framework that decomposes learning-signal adaptation into Critic LLM diagnosis of stage-specific failures from sparse returns and behavior summaries, Generator LLM proposals of reward-shaping configurations, and branch-validation that accepts only changes shown to help on short-horizon rollouts before they enter the main trajectory.
What carries the argument
The LLM-ALSO loop of Critic diagnosis, Generator proposal, and short-horizon branch validation that filters LLM outputs before they affect main training.
If this is right
- Only proposals that pass short-horizon validation enter training, limiting exposure to unreliable LLM outputs.
- Stage-aware adaptation produces reward changes that track evolving coordination needs during a single training run.
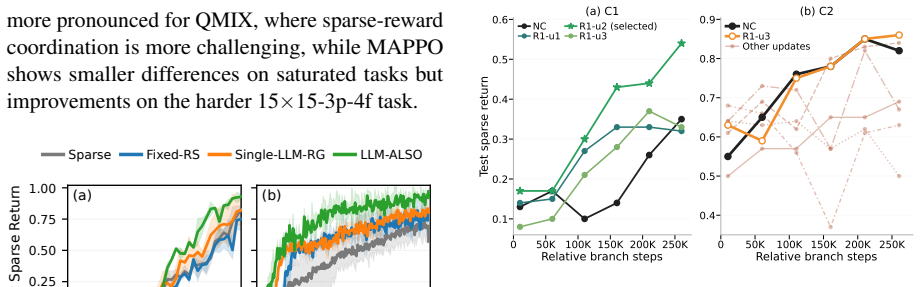
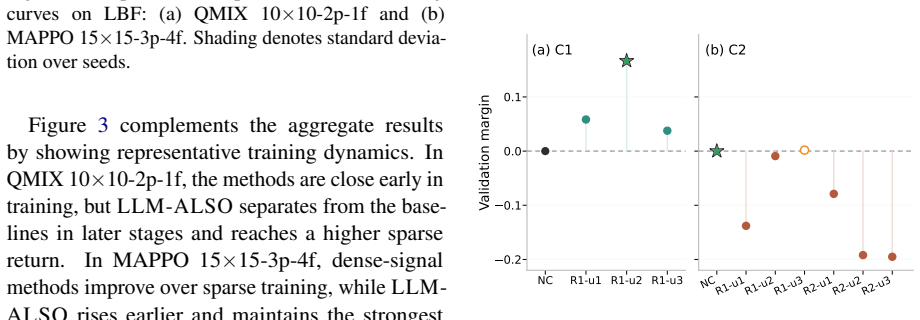
- Performance and sample efficiency rise on sparse-reward cooperative tasks without additional domain-specific reward design.
- The same diagnosis-proposal-validation structure can be applied to other base MARL algorithms that already use reward shaping.
Where Pith is reading between the lines
- The validation step could be extended to longer or more diverse test branches to catch failures that appear only after many episodes.
- Similar diagnosis-plus-validation loops might reduce the cost of incorporating LLMs into single-agent RL or non-cooperative settings.
- The method implies that compact behavior summaries are sufficient evidence for an LLM to produce actionable training advice.
Load-bearing premise
A Critic LLM can reliably identify stage-specific learning and coordination failures from sparse-return metrics and compact behavior evidence.
What would settle it
A controlled run on the same MARL benchmarks in which the branch-validation step accepts proposals that later degrade final sparse-evaluation scores or slow learning relative to the unassisted baseline.
Figures

read the original abstract
Effective training-time guidance is central to multi-agent reinforcement learning (MARL), yet remains difficult in sparse-reward settings where weak supervision limits coordination and policy improvement, and existing methods often require substantial domain expertise or manual design effort. Large language models (LLMs) provide a promising alternative for flexible learning-signal design, yet existing LLM-based methods remain largely single-agent-oriented, one-shot, or weakly validated for the evolving training dynamics of cooperative MARL. To address these limitations, we propose LLM-ALSO, an iterative LLM-driven adaptive learning-signal optimization framework for MARL. Rather than directly deploying LLM-generated rewards, LLM-ALSO decomposes adaptation into iterative diagnosis, proposal, and validation: a Critic LLM diagnoses stage-specific learning and coordination failures from sparse-return metrics and compact behavior evidence, a Generator LLM proposes candidate reward-shaping configurations conditioned on the diagnosis, and branch-validation feedback refines candidates before they affect the main training trajectory. Through short-horizon validation and stage-aware adaptation, LLM-ALSO promotes only validated updates into training, reducing the risk of unreliable LLM-generated modifications. Experiments on sparse-reward cooperative MARL tasks show that LLM-ALSO improves sparse-evaluation performance and learning efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes LLM-ALSO, an iterative LLM-driven adaptive learning-signal optimization framework for cooperative multi-agent reinforcement learning. It decomposes adaptation into diagnosis of stage-specific failures by a Critic LLM (using sparse-return metrics and compact behavior evidence), proposal of reward-shaping configurations by a Generator LLM, and short-horizon branch validation to filter updates before they affect the main training trajectory. The paper claims that this yields improved sparse-evaluation performance and learning efficiency on sparse-reward cooperative MARL tasks.
Significance. If the reported empirical gains are reproducible and the validation mechanism proves reliable, the framework could reduce reliance on manual reward engineering in MARL by providing an automated, stage-aware alternative for learning-signal design, with relevance to coordination challenges in sparse settings.
major comments (1)
- [Abstract] Abstract: the central empirical claim that 'LLM-ALSO improves sparse-evaluation performance and learning efficiency' is presented without any quantitative metrics, baselines, statistical tests, number of runs, or description of the validation procedure. This renders the primary contribution uninspectable from the supplied text and is load-bearing for the paper's assertion of practical utility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract. We agree that greater specificity is needed to make the central empirical claims inspectable and will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim that 'LLM-ALSO improves sparse-evaluation performance and learning efficiency' is presented without any quantitative metrics, baselines, statistical tests, number of runs, or description of the validation procedure. This renders the primary contribution uninspectable from the supplied text and is load-bearing for the paper's assertion of practical utility.
Authors: We agree that the abstract as written does not include the requested quantitative details. The body of the manuscript (Section 4) reports these results with baselines, multiple runs, and validation details, but the abstract summarizes them only qualitatively. In the revised version we will expand the final sentence of the abstract to include representative quantitative findings (performance deltas, number of seeds, and a concise note on the short-horizon validation filter) drawn directly from the experimental results, while preserving length constraints. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical framework (LLM-ALSO) that decomposes adaptation into diagnosis, proposal, and short-horizon validation steps performed by external LLM calls. No equations, fitted parameters, or mathematical derivations appear in the provided text. The central claim is an observed improvement on sparse-reward MARL tasks; this rests on external LLM behavior and experimental outcomes rather than any self-definitional loop, renamed prediction, or self-citation chain that reduces the result to its own inputs. The method is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
-
[3]
Tianshu Chu, Jie Wang, Lara Codec \`a , and Zhaojian Li. 2019. https://arxiv.org/abs/1903.04527 Multi-agent deep reinforcement learning for large-scale traffic signal control . arXiv preprint arXiv:1903.04527
Pith/arXiv arXiv 2019
-
[4]
Yali Du, Lei Han, Meng Fang, Ji Liu, Tianhong Dai, and Dacheng Tao. 2019. https://proceedings.neurips.cc/paper/2019/hash/07a9d3fed4c5ea6b17e80258dee231fa-Abstract.html LIIR : Learning individual intrinsic reward in multi-agent reinforcement learning . In Advances in Neural Information Processing Systems, volume 32
2019
-
[5]
Toby Godfrey, William Hunt, and Mohammad D. Soorati. 2024. https://arxiv.org/abs/2410.14383 MARLIN : Multi-agent reinforcement learning guided by language-based inter-robot negotiation . arXiv preprint arXiv:2410.14383
Pith/arXiv arXiv 2024
-
[6]
Jifeng Hu, Yanchao Sun, Hechang Chen, Sili Huang, Haiyin Piao, Yi Chang, and Lichao Sun. 2022. https://proceedings.neurips.cc/paper_files/paper/2022/hash/520425a5a4c2fb7f7fc345078b188201-Abstract-Conference.html Distributional reward estimation for effective multi-agent deep reinforcement learning . In Advances in Neural Information Processing Systems, volume 35
2022
-
[7]
Jeewon Jeon, Woojun Kim, Whiyoung Jung, and Youngchul Sung. 2022. https://proceedings.mlr.press/v162/jeon22a.html MASER : Multi-agent reinforcement learning with subgoals generated from experience replay buffer . In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research, pages 10041--10...
2022
-
[8]
a fer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter B \
Aleksandar Krnjaic, Raul D. Steleac, Jonathan D. Thomas, Georgios Papoudakis, Lukas Sch \"a fer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter B \"o rsting, and Stefano V. Albrecht. 2024. https://doi.org/10.1109/IROS58592.2024.10802813 Scalable multi-agent reinforcement learning for warehouse logistics with robotic and human co-...
-
[9]
Minae Kwon, Sang Michael Xie, Kalesha Bullard, and Dorsa Sadigh. 2023. https://openreview.net/forum?id=10uNUgI5Kl Reward design with language models . In International Conference on Learning Representations
2023
-
[10]
Huao Li, Hossein Nourkhiz Mahjoub, Behdad Chalaki, Vaishnav Tadiparthi, Kwonjoon Lee, Ehsan Moradi-Pari, Charles Michael Lewis, and Katia P. Sycara. 2024. https://proceedings.neurips.cc/paper_files/paper/2024/hash/a06e129e01e0d2ef853e9ff67b911360-Abstract-Conference.html Language grounded multi-agent reinforcement learning with human-interpretable communi...
2024
-
[11]
Zhemin Li, Ruobing Zhang, Zhengming Wang, Zheng Xie, and Yiping Song. 2025. https://doi.org/10.1016/j.neucom.2025.130105 LLM -guided decision-making toolkit for multi-agent reinforcement learning . Neurocomputing, 638:130105
-
[12]
Boyin Liu, Zhiqiang Pu, Yi Pan, Jianqiang Yi, Yanyan Liang, and Du Zhang. 2023. https://proceedings.mlr.press/v202/liu23ac.html Lazy agents: A new perspective on solving sparse reward problem in multi-agent reinforcement learning . In Proceedings of the 40th International Conference on Machine Learning, volume 202 of Proceedings of Machine Learning Resear...
2023
-
[13]
Yecheng Jason Ma, William Liang, Guanzhi Wang, De-An Huang, Osbert Bastani, Dinesh Jayaraman, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2024. https://openreview.net/forum?id=IEduRUO55F Eureka: Human-level reward design via coding large language models . In International Conference on Learning Representations
2024
-
[14]
David Henry Mguni, Taher Jafferjee, Jianhong Wang, Oliver Slumbers, Nicolas Perez-Nieves, Feifei Tong, Yang Li, Jiangcheng Zhu, Yaodong Yang, and Jun Wang. 2022. https://openreview.net/forum?id=CpTuR2ECuW LIGS : Learnable intrinsic-reward generation selection for multi-agent learning . In International Conference on Learning Representations
2022
-
[15]
Ng, Daishi Harada, and Stuart Russell
Andrew Y. Ng, Daishi Harada, and Stuart Russell. 1999. Policy invariance under reward transformations: Theory and application to reward shaping. In Proceedings of the Sixteenth International Conference on Machine Learning, pages 278--287
1999
-
[16]
Albrecht
Georgios Papoudakis, Filippos Christianos, Lukas Sch \"a fer, and Stefano V. Albrecht. 2021. https://openreview.net/forum?id=cIrPX-Sn5n Benchmarking multi-agent deep reinforcement learning algorithms in cooperative tasks . In Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks
2021
-
[17]
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. 2018. https://proceedings.mlr.press/v80/rashid18a.html QMIX : Monotonic value function factorisation for deep multi-agent reinforcement learning . In Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of...
2018
-
[18]
Juan Rocamonde, Victoriano Montesinos, Elvis Nava, Ethan Perez, and David Lindner. 2024. https://openreview.net/forum?id=N0I2RtD8je Vision-language models are zero-shot reward models for reinforcement learning . In International Conference on Learning Representations
2024
-
[19]
Philipp D. Siedler and Ian Gemp. 2025. https://arxiv.org/abs/2503.13553 LLM -mediated guidance of MARL systems . arXiv preprint arXiv:2503.13553
arXiv 2025
-
[20]
Li Wang, Yupeng Zhang, Yujing Hu, Weixun Wang, Chongjie Zhang, Yang Gao, Jianye Hao, Tangjie Lv, and Changjie Fan. 2022. https://proceedings.mlr.press/v162/wang22ao.html Individual reward assisted multi-agent reinforcement learning . In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Rese...
2022
-
[21]
Ziyan Wang, Zhicheng Zhang, Fei Fang, and Yali Du. 2025. https://proceedings.mlr.press/v267/wang25el.html M3HF : Multi-agent reinforcement learning from multi-phase human feedback of mixed quality . In Proceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 65429--65448. PMLR
2025
-
[22]
Tianbao Xie, Siheng Zhao, Chen Henry Wu, Yitao Liu, Qian Luo, Victor Zhong, Yanchao Yang, and Tao Yu. 2024. https://openreview.net/forum?id=tUM39YTRxH Text2reward: Reward shaping with language models for reinforcement learning . In International Conference on Learning Representations
2024
-
[23]
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. 2022. https://openreview.net/forum?id=YVXaxB6L2Pl The surprising effectiveness of PPO in cooperative multi-agent games . In Advances in Neural Information Processing Systems, volume 35
2022
-
[24]
Guobin Zhu, Rui Zhou, Wenkang Ji, and Shiyu Zhao. 2025. https://doi.org/10.1109/LRA.2025.3577527 LAMARL : LLM -aided multi-agent reinforcement learning for cooperative policy generation . IEEE Robotics and Automation Letters, 10(7):7476--7483
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.