EvoGM: Learning to Merge LLMs via Evolutionary Generative Optimization
Pith reviewed 2026-06-29 00:19 UTC · model grok-4.3
The pith
EvoGM replaces hand-crafted operators in evolutionary LLM merging with a learnable dual-generator architecture trained on winner-loser pairs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
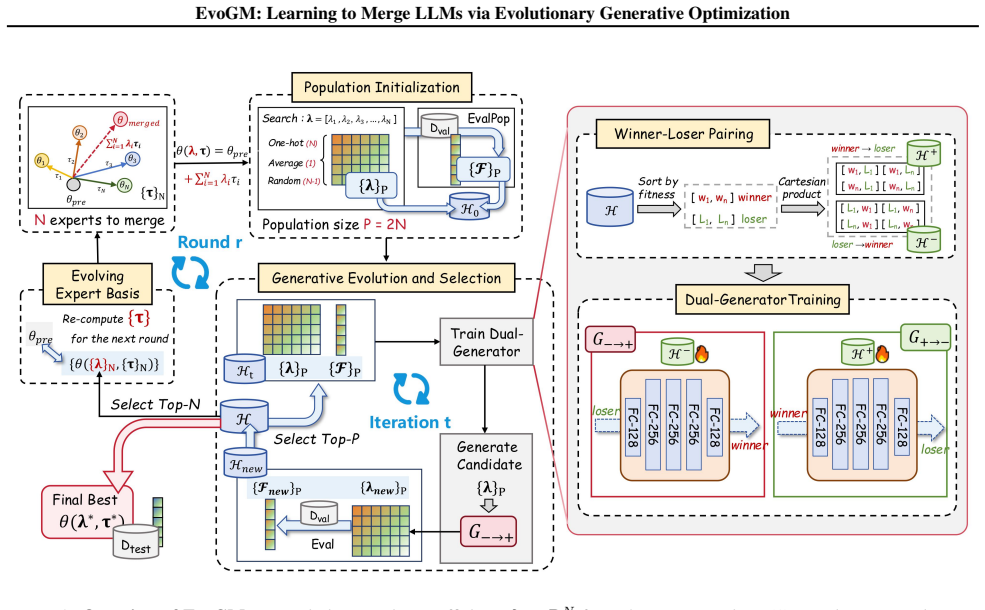
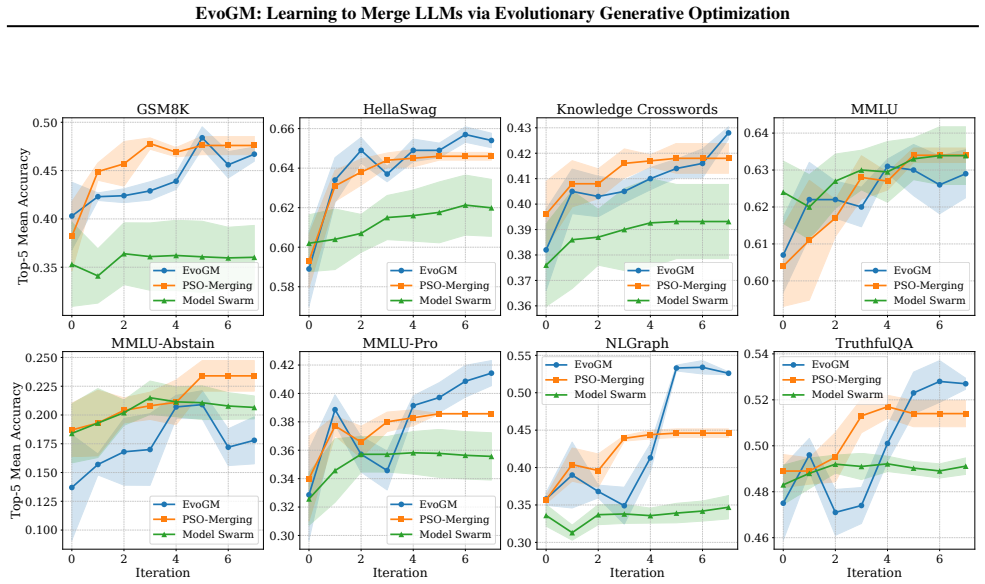
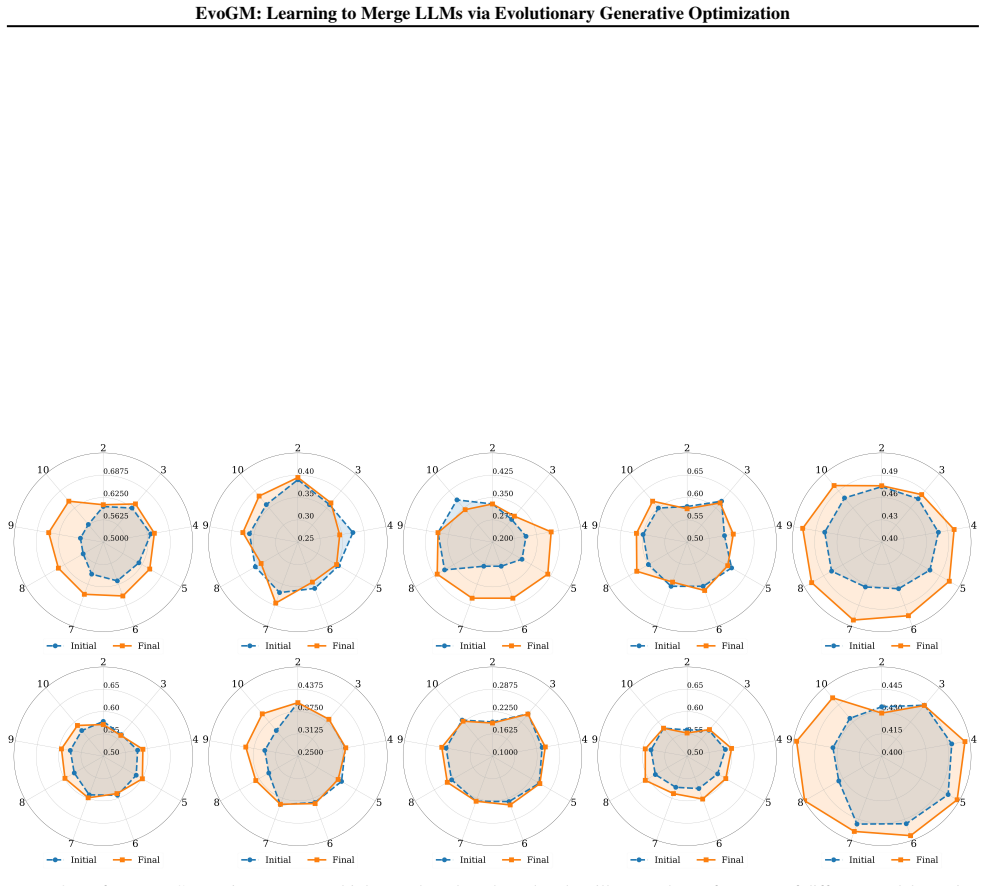
EvoGM features a dual-generator architecture with cycle-consistent learning to adaptively sample and refine promising merging candidates. By constructing winner-loser pairs from historical search trajectories, the framework captures high-performance parameter distributions and maximizes data efficiency. This generative process is integrated into a multi-round evolutionary pipeline where elite merged models iteratively serve as new expert foundations.
What carries the argument
Dual-generator architecture with cycle-consistent learning on winner-loser pairs drawn from search trajectories
If this is right
- Merging coefficients can be proposed by learned generators rather than hand-crafted stochastic operators.
- Historical search data alone suffices to train the system without extra labeled validation merges.
- Elite merged models can be reused as expert bases in subsequent evolutionary rounds.
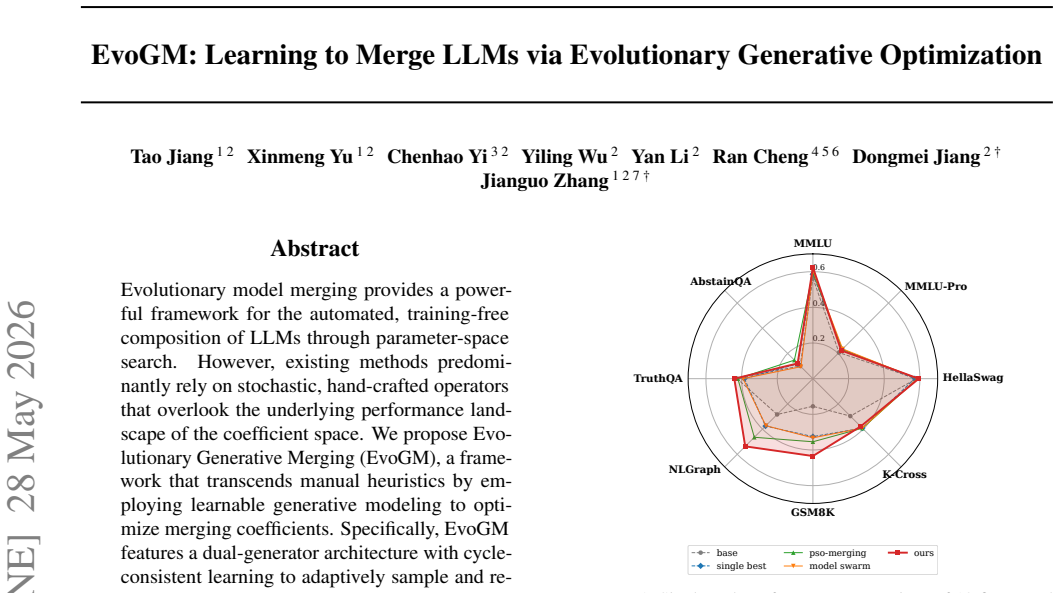
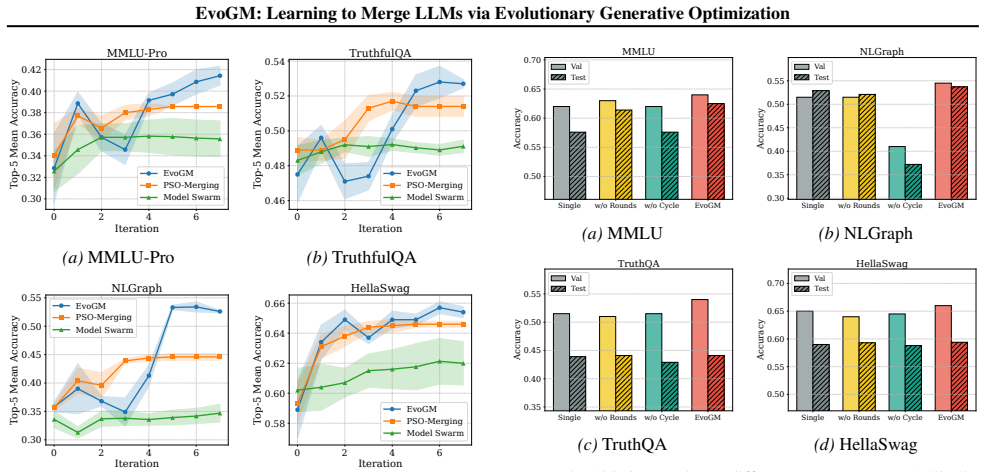
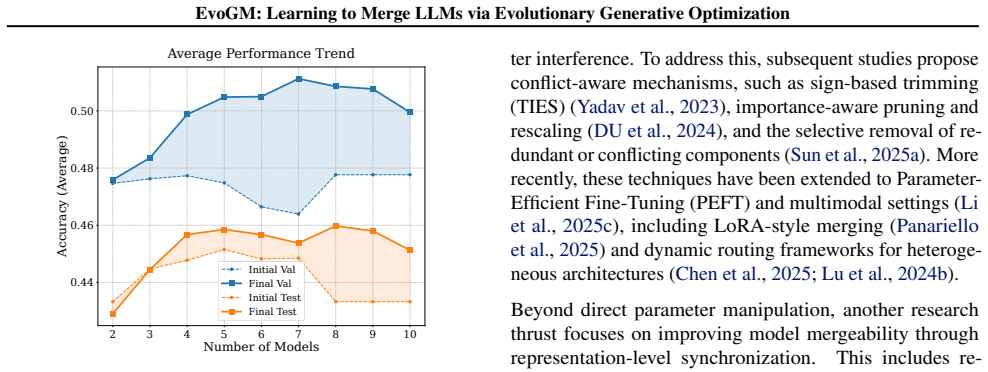
- The approach yields higher performance than prior evolutionary merging methods on both seen and unseen benchmarks.
Where Pith is reading between the lines
- The same winner-loser training pattern could be tested on other evolutionary search problems that optimize continuous coefficients.
- Cycle-consistent generators might reduce data requirements in other generative modeling settings where only relative rankings are available.
- Repeated application of the pipeline could compound improvements when merging models drawn from increasingly diverse sources.
Load-bearing premise
Winner-loser pairs from past trajectories supply enough information for the generators to learn useful coefficient distributions without overfitting or separate validation sets.
What would settle it
A direct comparison on an unseen task suite where EvoGM no longer beats the strongest baseline, or an ablation removing cycle consistency that eliminates the reported gains, would falsify the claim.
Figures
read the original abstract
Evolutionary model merging provides a powerful framework for the automated, training-free composition of LLMs through parameter-space search. However, existing methods predominantly rely on stochastic, hand-crafted operators that overlook the underlying performance landscape of the coefficient space. We propose Evolutionary Generative Merging (EvoGM), a framework that transcends manual heuristics by employing learnable generative modeling to optimize merging coefficients. Specifically, EvoGM features a dual-generator architecture with cycle-consistent learning to adaptively sample and refine promising merging candidates. By constructing winner-loser pairs from historical search trajectories, our framework effectively captures high-performance parameter distributions and maximizes data efficiency. This generative process is seamlessly integrated into a multi-round evolutionary pipeline, where elite merged models iteratively serve as new expert foundations. Extensive experiments across diverse benchmarks demonstrate that EvoGM significantly outperforms state-of-the-art baselines, exhibiting robust performance on both seen and unseen tasks. Code and data are available at https://github.com/JiangTao97/evogm.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes EvoGM, a framework for evolutionary model merging of LLMs that replaces hand-crafted stochastic operators with a dual-generator architecture trained via cycle-consistent learning on winner-loser pairs extracted from historical search trajectories. These generators are embedded in a multi-round evolutionary pipeline that iteratively uses elite merged models as new foundations, with the central claim being significant outperformance over state-of-the-art baselines together with robust generalization to both seen and unseen tasks.
Significance. If the empirical claims are substantiated with proper controls, the work would offer a data-efficient, learnable alternative to manual heuristics in parameter-space model merging, potentially improving automation and performance in LLM composition without additional fine-tuning.
major comments (3)
- [Abstract] Abstract: the assertion of significant outperformance and robust performance on unseen tasks supplies no quantitative metrics, error bars, ablation studies, or experimental details, so the central empirical claim cannot be evaluated from the provided information.
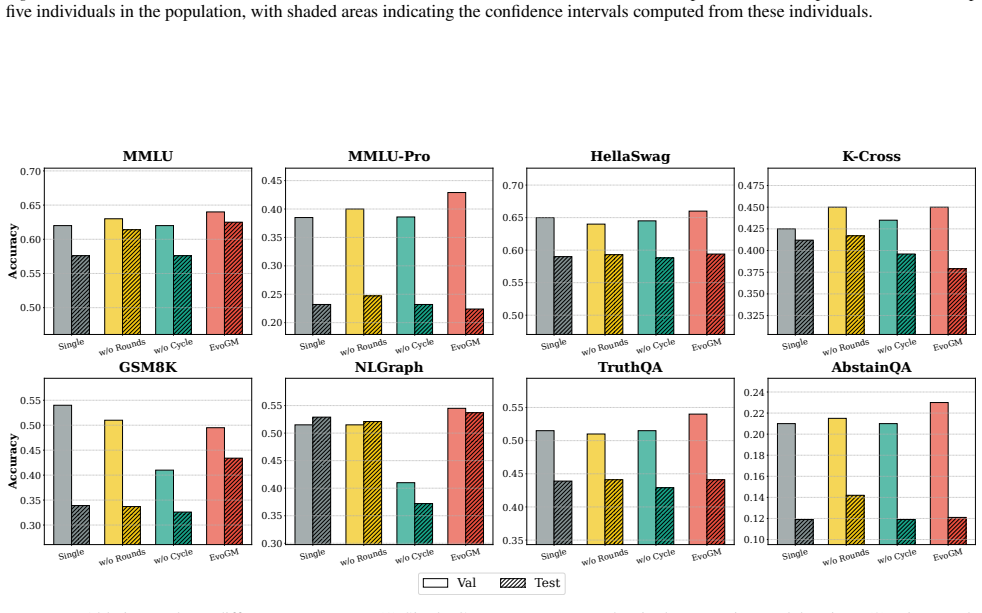
- [Method] Method description (dual-generator with cycle-consistent learning): training the generators exclusively on winner-loser pairs drawn from the same evolutionary trajectories they subsequently guide creates an unaddressed self-referential dependency; without explicit regularization, held-out validation splits for the generators, or documented separation between trajectory-collection tasks and evaluation tasks, the reported generalization to unseen tasks risks being an artifact of memorization rather than distribution learning.
- [Experiments] Experiments section: the manuscript must demonstrate that the multi-round pipeline does not leak information from evaluation tasks into the historical trajectories used for generator training; absent such controls, the robustness claim on unseen tasks remains unverified.
minor comments (2)
- The GitHub link is provided, which supports reproducibility; however, the repository should include the exact scripts and seeds used for the reported runs.
- [Method] Notation for the cycle-consistency loss and the dual-generator sampling procedure should be defined more explicitly with equations to aid readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will make revisions to improve clarity and substantiation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion of significant outperformance and robust performance on unseen tasks supplies no quantitative metrics, error bars, ablation studies, or experimental details, so the central empirical claim cannot be evaluated from the provided information.
Authors: We agree that the abstract would benefit from more quantitative detail. In the revised manuscript we will update the abstract to include specific metrics such as average improvements over baselines on seen and unseen tasks, along with references to error bars from repeated runs and key ablation results. revision: yes
-
Referee: [Method] Method description (dual-generator with cycle-consistent learning): training the generators exclusively on winner-loser pairs drawn from the same evolutionary trajectories they subsequently guide creates an unaddressed self-referential dependency; without explicit regularization, held-out validation splits for the generators, or documented separation between trajectory-collection tasks and evaluation tasks, the reported generalization to unseen tasks risks being an artifact of memorization rather than distribution learning.
Authors: This concern is valid. Our framework collects trajectories from initial rounds on base models before generator training begins, and unseen tasks are excluded from all trajectory collection. We will add a dedicated subsection clarifying task separation, held-out validation for the generators, and regularization in the cycle-consistent objective, plus ablations confirming generalization is not due to memorization. revision: yes
-
Referee: [Experiments] Experiments section: the manuscript must demonstrate that the multi-round pipeline does not leak information from evaluation tasks into the historical trajectories used for generator training; absent such controls, the robustness claim on unseen tasks remains unverified.
Authors: We acknowledge the need for explicit verification. The revised Experiments section will include a new subsection documenting that historical trajectories are collected exclusively from seen tasks with no access to unseen tasks. We will add controlled experiments under strict separation and report results confirming the unseen-task robustness holds without leakage. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical method
full rationale
The paper describes an iterative evolutionary pipeline that trains a dual-generator on winner-loser pairs extracted from prior search trajectories and then uses the generator to propose new merges. This is a standard data-driven enhancement to evolutionary search rather than a closed self-definition or fitted-input-renamed-as-prediction. No equations are presented that reduce a claimed result to its own inputs by construction, no uniqueness theorem is invoked via self-citation, and the central performance claims rest on external benchmark comparisons rather than internal re-labeling of the training data. The method therefore remains falsifiable against held-out tasks and does not meet the criteria for any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://openreview.net/forum? id=H1osvc7tMP. Bai, J., Bai, S., Chu, Y ., Cui, Z., Dang, K., Deng, X., Fan, Y ., Ge, W., Han, Y ., Huang, F., et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023. Bar-Haim, R., Dagan, I., Dolan, B., Ferro, L., Giampiccolo, D., Magnini, B., and Szpektor, I. The second PASCAL recognising textual entailment c...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/s17-2001 2023
-
[2]
Training Verifiers to Solve Math Word Problems
URL https://openreview.net/forum? id=D7qRwx6BOS. Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y ., Fe- dus, W., Li, Y ., Wang, X., Dehghani, M., Brahma, S., et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024. Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M.,...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11617 2024
-
[3]
CoLLaVO: Crayon large language and vision mOdel
URL https://doi.org/10.18653/v1/ 2024.findings-acl.154. Dolan, W. B. and Brockett, C. Automatically construct- ing a corpus of sentential paraphrases. InProceedings of the Third International Workshop on Paraphrasing (IWP2005), 2005. URL https://aclanthology. org/I05-5002/. DU, G., Lee, J., Li, J., Jiang, R., Guo, Y ., Yu, S., Liu, H., Goh, S. K., Tang, H...
-
[4]
Gehman, S., Gururangan, S., Sap, M., Choi, Y ., and Smith, N
doi: 10.1038/s41467-024-53165-w. Gehman, S., Gururangan, S., Sap, M., Choi, Y ., and Smith, N. A. RealToxicityPrompts: Evaluating neural toxic degeneration in language models. In Cohn, T., He, Y ., and Liu, Y . (eds.),Findings of the Association for Com- putational Linguistics: EMNLP 2020, pp. 3356–3369, 10 EvoGM: Learning to Merge LLMs via Evolutionary G...
-
[5]
findings-emnlp.301/
URL https://aclanthology.org/2020. findings-emnlp.301/. Giampiccolo, D., Magnini, B., Dagan, I., and Dolan, B. The third PASCAL recognizing textual entailment chal- lenge. In Sekine, S., Inui, K., Dagan, I., Dolan, B., Giampiccolo, D., and Magnini, B. (eds.),Proceedings of the ACL-PASCAL Workshop on Textual Entailment and Paraphrasing, pp. 1–9, Prague, Ju...
2020
-
[6]
URL https://api.semanticscholar. org/CorpusID:284648786. Ivison, H., Wang, Y ., Pyatkin, V ., Lambert, N., Peters, M., Dasigi, P., Jang, J., Wadden, D., Smith, N. A., Beltagy, I., et al. Camels in a changing climate: Enhancing LM adap- tation with TULU 2.arXiv preprint arXiv:2311.10702, 2023. Jiang, H., Wang, R., Liang, W., Sun, Q., Zhang, X., and Liu, Y ...
-
[7]
Jin, X., Ren, X., Preotiuc-Pietro, D., and Cheng, P
URL https://openreview.net/forum? id=dj0TktJcVI. Jin, X., Ren, X., Preotiuc-Pietro, D., and Cheng, P. Data- less knowledge fusion by merging weights of language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https:// openreview.net/forum?id=FCnohuR6AnM. K¨opf, A., Kilcher, Y ., V on R ¨utte, D., Anagnostidis, S., Ta...
-
[8]
URL https://api.semanticscholar. org/CorpusID:15710851. Li, B., Di, Z., Yang, Y ., Qian, H., Yang, P., Hao, H., Tang, K., and Zhou, A. It’s morphing time: Unleashing the po- tential of multiple LLMs via multi-objective optimization. IEEE Transactions on Evolutionary Computation, 2025a. doi: 10.1109/TEVC.2025.3613937. Li, L., Zhang, T., Bu, Z., Wang, S., H...
-
[9]
TruthfulQA: Measuring How Models Mimic Human Falsehoods
URL https://api.semanticscholar. org/CorpusID:230433941. Li, Y ., Lan, X., Chen, H., Lu, K., and Jiang, D. Multi- modal pear chain-of-thought reasoning for multimodal sentiment analysis.ACM Transactions on Multimedia Computing, Communications and Applications, 20(9): 1–23, 2025c. Lian, W., Goodson, B., Pentland, E., Cook, A., V ong, C., and ”Teknium”. Ope...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024.acl-long.445 2023
-
[10]
PivotMerge: Bridging Heterogeneous Multimodal Pre-training via Post-Alignment Model Merging
URL https://openreview.net/forum? id=y1z7SAS8q8. Perin, G., Chen, X., Liu, S., Kailkhura, B., Wang, Z., and Gallagher, B. RankMean: Module-level importance score for merging fine-tuned LLM models. In Ku, L.-W., Mar- tins, A., and Srikumar, V . (eds.),Findings of the Associa- tion for Computational Linguistics: ACL 2024, pp. 1776– 1782, Bangkok, Thailand, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024 2024
-
[11]
Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., Lin, Q., and Jiang, D
URL https://proceedings.mlr.press/ v162/wortsman22a.html. Xu, C., Sun, Q., Zheng, K., Geng, X., Zhao, P., Feng, J., Tao, C., Lin, Q., and Jiang, D. WizardLM: Empower- ing large pre-trained language models to follow com- plex instructions. InThe Twelfth International Confer- ence on Learning Representations, 2024a. URL https: //openreview.net/forum?id=CfXh...
-
[12]
Curran Associates, Inc., 2023. 13 EvoGM: Learning to Merge LLMs via Evolutionary Generative Optimization Yang, E., Wang, Z., Shen, L., Liu, S., Guo, G., Wang, X., and Tao, D. AdaMerging: Adaptive model merging for multi-task learning. InThe Twelfth International Confer- ence on Learning Representations, 2024. URL https: //openreview.net/forum?id=nZP6NgD3Q...
-
[13]
URL https://aclanthology.org/2024. findings-emnlp.127. Zheng, H., Shen, L., Tang, A., Luo, Y ., Hu, H., Du, B., Wen, Y ., and Tao, D. Learning from models be- yond fine-tuning.Nature Machine Intelligence, 7(1): 6–17, 01 2025. ISSN 2522-5839. doi: 10.1038/ s42256-024-00961-0. URL https://doi.org/10. 1038/s42256-024-00961-0. Zhou, C., Liu, P., Xu, P., Iyer,...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.