Phase-Conditioned Imitation Learning with Autonomous Failure Recovery for Robust Deformable Object Manipulation
Pith reviewed 2026-06-29 07:11 UTC · model grok-4.3
The pith
Phase-conditioned imitation learning with multi-modal feedback enables autonomous recovery from failures in deformable object tasks, raising hanging success from 56% to 87%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
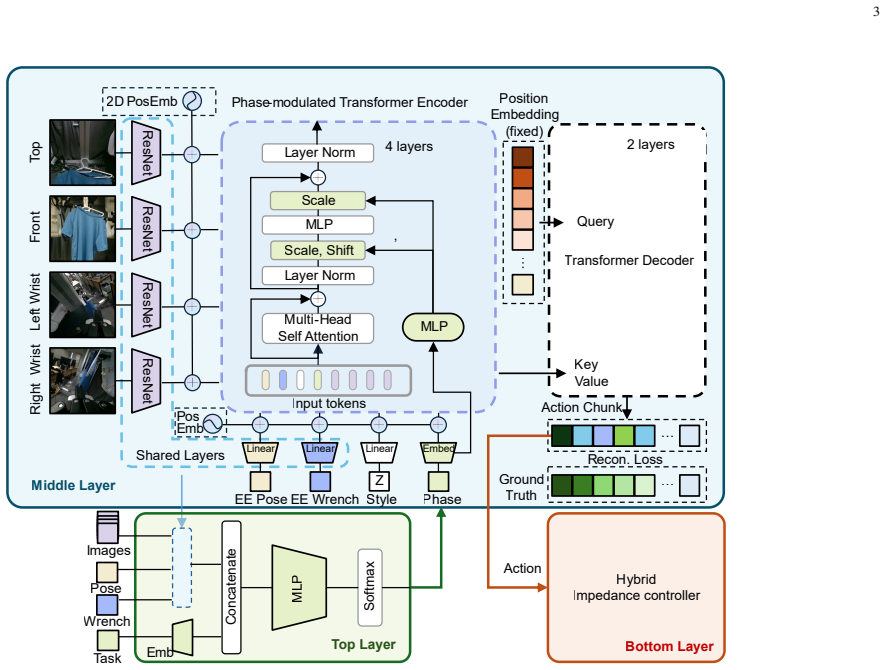
The authors claim that conditioning an Action Chunking with Transformers policy on estimated task phase via FiLM, combined with real-time multi-modal phase prediction from vision, force, and pose, produces a single policy that executes phase-specific actions and recovers autonomously from execution failures that vision alone cannot detect.
What carries the argument
FiLM-conditioned ACT encoder modulated by a multi-modal phase predictor that fuses visual, force, and pose feedback to estimate current task phase and trigger recovery.
If this is right
- A single policy can produce phase-specific behaviors while sharing action dynamics across phases.
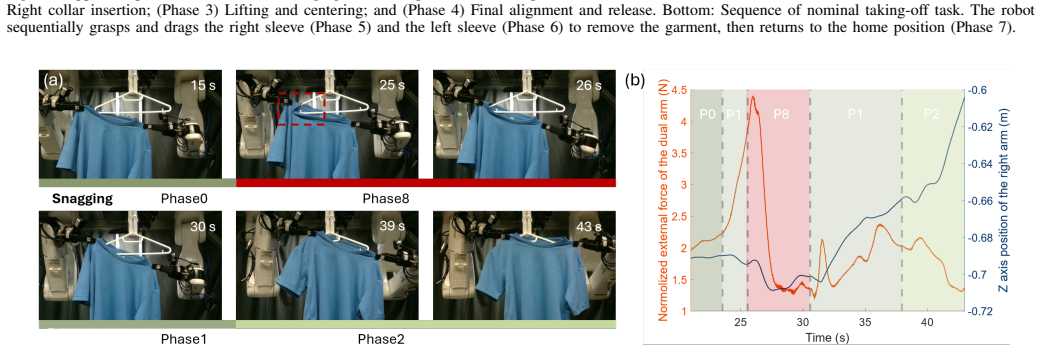
- Contact failures invisible to vision can be detected and trigger autonomous recovery trajectories.
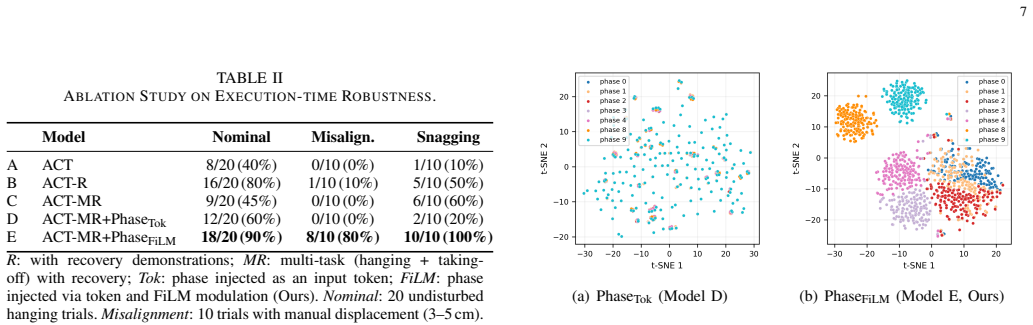
- FiLM modulation yields well-separated phase-specific feature representations confirmed by t-SNE.
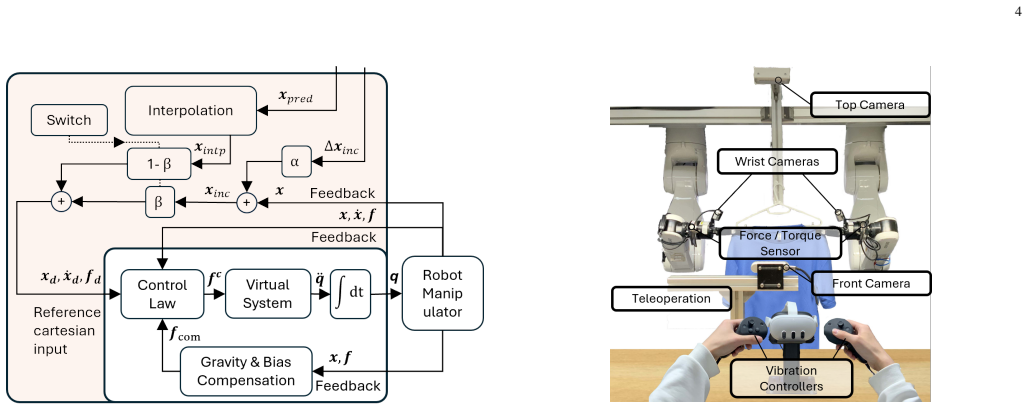
- Hybrid impedance control supports compliant execution during both normal and recovery actions.
Where Pith is reading between the lines
- The approach could reduce the need for separate policies per phase in other multi-stage robotic tasks.
- Force and pose feedback may help in environments where visual occlusion is common.
- Similar phase conditioning might address state aliasing in other imitation learning methods beyond ACT.
Load-bearing premise
The multi-modal phase predictor can accurately estimate the current task phase in real time and reliably detect contact failures that are invisible to vision alone.
What would settle it
An experiment that disables or degrades the multi-modal phase predictor while keeping the rest of the system fixed and measures whether the hanging success rate falls back near 56%.
Figures



read the original abstract
This paper presents a phase-conditioned, force-aware framework for robust deformable object manipulation. Standard imitation learning policies such as Action Chunking with Transformers (ACT) rely on a Markovian assumption at inference, causing state aliasing when visually similar observations require contradictory actions and preventing autonomous recovery from execution failures. We address this with a closed-loop hierarchical architecture. A FiLM-conditioned ACT encoder modulates feature extraction based on the current task phase, enabling a single unified policy to produce phase-specific behaviors while sharing action dynamics across phases. A multi-modal phase predictor fusing visual, force, and pose feedback estimates the phase in real time, detecting contact failures that are invisible to vision alone and autonomously triggering recovery trajectories. The system is completed by a hybrid impedance controller for compliant execution and a haptic teleoperation interface for force-aware data collection. Ablation studies show that FiLM-based modulation significantly outperforms both unconditioned and token-level conditioned baselines, and t-SNE analysis confirms that FiLM induces well-separated, phase-specific feature representations. Validated on hanging and removing a T-shirt with dual arms, the closed-loop system improves the hanging success rate from 56\% to 87\% through autonomous error recovery. Code and videos: https://leledeyuan00.github.io/phaser/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a closed-loop hierarchical framework for deformable object manipulation that augments Action Chunking with Transformers (ACT) via FiLM conditioning on task phase, a multi-modal phase predictor fusing vision/force/pose to detect failures invisible to vision, a hybrid impedance controller, and haptic teleoperation. It claims this mitigates Markovian state aliasing in standard imitation learning and enables autonomous recovery, with the central empirical result being an increase in dual-arm T-shirt hanging success from 56% to 87%.
Significance. If the success-rate gain can be rigorously attributed to the phase predictor's failure detection rather than the FiLM policy or impedance controller, the work would provide a concrete mechanism for closed-loop recovery in contact-rich deformable manipulation without requiring explicit failure-mode engineering.
major comments (2)
- [Abstract] Abstract: The 56% to 87% hanging success improvement is explicitly attributed to autonomous recovery triggered by the multi-modal phase predictor detecting contact failures invisible to vision, yet the manuscript supplies no phase-classification accuracy, confusion matrix, precision/recall, or real-time failure-detection metrics on held-out sequences or during the dual-arm task. Without these, it is impossible to confirm that the predictor (rather than FiLM conditioning or the hybrid controller) drives the reported gain.
- [Ablation studies / t-SNE analysis] Ablation studies and t-SNE analysis: These demonstrate that FiLM induces better-separated phase-specific features than unconditioned or token-level baselines, but they do not isolate or quantify the phase predictor's contribution to failure recovery under the exact conditions of the T-shirt hanging task.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We respond to each major comment below, indicating where the manuscript will be revised for clarification while maintaining the integrity of the reported results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The 56% to 87% hanging success improvement is explicitly attributed to autonomous recovery triggered by the multi-modal phase predictor detecting contact failures invisible to vision, yet the manuscript supplies no phase-classification accuracy, confusion matrix, precision/recall, or real-time failure-detection metrics on held-out sequences or during the dual-arm task. Without these, it is impossible to confirm that the predictor (rather than FiLM conditioning or the hybrid controller) drives the reported gain.
Authors: We acknowledge that the manuscript does not include direct quantitative metrics (accuracy, confusion matrix, precision/recall) for the phase predictor on held-out data. The 56% baseline reflects the standard ACT policy without phase conditioning or the multi-modal predictor, while the 87% result is achieved only with the full closed-loop system that uses the predictor to detect vision-invisible contact failures and trigger recovery. The multi-modal fusion (vision/force/pose) is specifically motivated by the need to resolve state aliasing in contact-rich phases. In revision we will rephrase the abstract to attribute the gain to the integrated closed-loop framework rather than the predictor in isolation, and we will add a limitations paragraph noting the absence of isolated predictor metrics. revision: partial
-
Referee: [Ablation studies / t-SNE analysis] Ablation studies and t-SNE analysis: These demonstrate that FiLM induces better-separated phase-specific features than unconditioned or token-level baselines, but they do not isolate or quantify the phase predictor's contribution to failure recovery under the exact conditions of the T-shirt hanging task.
Authors: The ablation studies and t-SNE visualizations evaluate the benefit of FiLM conditioning on policy feature separation and phase-specific behavior. The predictor's contribution to failure recovery is evidenced indirectly through the end-to-end task results: the 31% absolute improvement occurs only when the multi-modal predictor is active and able to trigger recovery trajectories. No separate ablation that disables only the predictor (while retaining FiLM and the impedance controller) was performed. In the revised manuscript we will add an explicit discussion clarifying that the ablations target the policy encoder while the predictor's role is demonstrated via the recovery mechanism in the full dual-arm task. revision: partial
- Phase-classification accuracy, confusion matrix, precision/recall, or real-time failure-detection metrics for the multi-modal phase predictor on held-out sequences
Circularity Check
No circularity: empirical performance metrics from physical experiments.
full rationale
The paper describes a hierarchical control architecture (FiLM-conditioned ACT, multi-modal phase predictor, hybrid impedance controller) and reports measured success rates (56% to 87%) on physical dual-arm T-shirt tasks. No derivation chain, equations, or first-principles predictions are present that could reduce to fitted parameters or self-referential definitions. Ablations and t-SNE visualizations are post-hoc analyses of learned representations, not load-bearing derivations. Self-citation is absent from the provided text; external baselines (ACT) are cited as standard methods. The central claim is an observed performance delta under closed-loop execution, which is falsifiable via experiment and does not collapse by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard imitation learning policies rely on a Markovian assumption that leads to state aliasing in phase-dependent tasks.
Reference graph
Works this paper leans on
-
[1]
Multi-critic reinforcement learning for garment handling: Addressing unpredictability in temporal-phase con- tinuous contact tasks,
Y . Zhang, D. Chen, W. He, A. El ´ıas Petrilli Barcel ´o, J. Victorio Salazar Luces, and Y . Hirata, “Multi-critic reinforcement learning for garment handling: Addressing unpredictability in temporal-phase con- tinuous contact tasks,”IEEE Trans. on Automat. Sci. and Eng., vol. 22, pp. 10 741–10 752, 2025
2025
-
[2]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware,” inProc. of Robot.: Sci. and Syst., Daegu, Republic of Korea, July 2023
2023
-
[3]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The Int. J. of Robot. Res., 2024
2024
-
[4]
RT-1: Robot. Transformer for Real-World Control at Scale,
A. Brohan, N. Brown, and J. C. et al., “RT-1: Robot. Transformer for Real-World Control at Scale,” inProc. of Robot.: Sci. and Syst., Daegu, Republic of Korea, July 2023
2023
- [5]
-
[6]
Film: visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville, “Film: visual reasoning with a general conditioning layer,” inProceedings of the Thirty-Second AAAI Conf. on Artificial Intelligence and Thirtieth Innovative Applications of Artificial Intelligence Conf. and Eighth AAAI Symposium on Educational Advances in Artificial Intelligence, ser. AAAI’...
2018
-
[7]
Scil: Stage- Conditioned Imitation Learning for Multi-Stage Manipulation,
Z. Ouyang, K. Wang, J. Liu, H. Lu, and W. Zhang, “Scil: Stage- Conditioned Imitation Learning for Multi-Stage Manipulation,”IEEE Control Syst. Letters, vol. 9, pp. 913–918, 2025
2025
-
[8]
An incremental hybrid impedance algorithm for stable force-position control of elastic materials,
Y . Zhang, D. Chen, W. He, A. E. P. Barcel´o, J. V . S. Luces, and Y . Hirata, “An incremental hybrid impedance algorithm for stable force-position control of elastic materials,”IEEE Trans. on Automat. Sci. and Eng., pp. 1–1, 2025
2025
-
[9]
Goal-conditioned model simpli- fication for 1-d and 2-d deformable object manipulation,
S. Wang, M. Leonetti, and M. Dogar, “Goal-conditioned model simpli- fication for 1-d and 2-d deformable object manipulation,”IEEE Trans. on Robot., vol. 41, pp. 4023–4040, 2025
2025
-
[10]
Sis: Seam-informed strategy for t-shirt unfolding,
X. Huang, A. Seino, F. Tokuda, A. Kobayashi, D. Chen, Y . Hirata, N. C. Tien, and K. Kosuge, “Sis: Seam-informed strategy for t-shirt unfolding,” IEEE Robot. and Automat. Letters, vol. 10, no. 7, pp. 7342–7349, 2025
2025
-
[11]
RTFF: Random-to-Target Fabric Flattening Policy using Dual-Arm Manipulator
K. Tang, D. Bhattacharya, H. Xu, F. Tokuda, N. C. Tien, and K. Ko- suge, “Rtff: Random-to-target fabric flattening policy using dual-arm manipulator,” https://arxiv.org/abs/2510.00814, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Graph- garment: Learning garment dynamics for bimanual cloth manipulation tasks,
W. Chen, K. Li, D. Lee, X. Chen, R. Zong, and P. Kormushev, “Graph- garment: Learning garment dynamics for bimanual cloth manipulation tasks,” https://arxiv.org/abs/2503.05817, 2025
-
[13]
Bimanual deformable bag manipulation using a structure-of-interest based neural dynamics model,
P. Zhou, P. Zheng, J. Qi, C. Li, H.-Y . Lee, Y . Pan, C. Yang, D. Navarro- Alarcon, and J. Pan, “Bimanual deformable bag manipulation using a structure-of-interest based neural dynamics model,”IEEE/ASME Trans. on Mechatronics, vol. 30, no. 5, pp. 3254–3265, 2025
2025
-
[14]
Deformpam: Data- Efficient Learning for Long-Horizon Deformable Object Manipulation Via Preference-Based Action Alignment,
W. Chen, H. Xue, F. Zhou, Y . Fang, and C. Lu, “Deformpam: Data- Efficient Learning for Long-Horizon Deformable Object Manipulation Via Preference-Based Action Alignment,” in2025 IEEE Int. Conf. on Robot. and Automat. (ICRA). IEEE, may 19 2025, pp. 6896–6903
2025
-
[15]
Learning human-inspired force strategies for robotic assembly,
S. Scherzinger, A. Roennau, and R. Dillmann, “Learning human-inspired force strategies for robotic assembly,” in2023 IEEE 19th Int. Conf. on Automat. Sci. and Eng. (CASE), 2023, pp. 1–8
2023
-
[16]
A system for imitation learning of contact-rich bimanual manipulation policies,
S. Stepputtis, M. Bandari, S. Schaal, and H. B. Amor, “A system for imitation learning of contact-rich bimanual manipulation policies,” in 2022 IEEE/RSJ Int. Conf. on Itell. Robots and Syst. (IROS), 2022, pp. 11 810–11 817
2022
-
[17]
H. Ge, Y . Jia, Z. Li, Y . Li, Z. Chen, R. Huang, and G. Zhou, “Filic: Dual- loop force-guided imitation learning with impedance torque control for contact-rich manipulation tasks,” https://arxiv.org/abs/2509.17053, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, ser. Proceedings of Machine Learning Research, G. Gordon, D. Dunson, and M. Dud ´ık, Eds., vol. 15. Fort Lauderdale, FL, USA: PML...
2011
-
[19]
Rac: Robot learning for long-horizon tasks by scaling recovery and correction,
Z. Hu, R. Wu, N. Enock, J. Li, R. Kadakia, Z. Erickson, and A. Kumar, “Rac: Robot learning for long-horizon tasks by scaling recovery and correction,” 2025
2025
-
[20]
On the continuity of rotation representations in neural networks,
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li, “On the continuity of rotation representations in neural networks,” https://arxiv.org/abs/1812. 07035, 2020
2020
-
[21]
Simplified offset and gravity compensation for wrist- mounted force/torque sensor with a garment manipulation application,
D. Chen, Y . Zhang, W. He, A. E. Petrilli Barcel ´o, J. V . Salazar Luces, and Y . Hirata, “Simplified offset and gravity compensation for wrist- mounted force/torque sensor with a garment manipulation application,” in2025 IEEE Int. Conf. on Robot. and Biomimetics (ROBIO), 2025
2025
-
[22]
Forward dynamics compliance control (fdcc): A new approach to cartesian compliance for robotic manipulators,
S. Scherzinger, A. Roennau, and R. Dillmann, “Forward dynamics compliance control (fdcc): A new approach to cartesian compliance for robotic manipulators,” inIEEE/RSJ Int. Conf. on Intell. Robots and Syst. (IROS), 2017, pp. 4568–4575
2017
-
[23]
Oculus reader: Robotic teleoperation interface,
F. E. Jedrzej Orbik, “Oculus reader: Robotic teleoperation interface,” https://github.com/rail-berkeley/oculus reader, 2021
2021
-
[24]
Coordinated motion control of dual manipulators for handling a rigid object with non-negligible deformation,
K. Kosuge, K. Kamei, and T. Nammoto, “Coordinated motion control of dual manipulators for handling a rigid object with non-negligible deformation,” in2014 IEEE Int. Conf. on Robot. and Automat. (ICRA), 2014, pp. 5145–5151
2014
-
[25]
Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,
R. Cadene, S. Alibert, A. Soare, Q. Gallouedec, A. Zouitine, S. Palma, P. Kooijmans, M. Aractingi, M. Shukor, D. Aubakirova, M. Russi, F. Capuano, C. Pascal, J. Choghari, J. Moss, and T. Wolf, “Lerobot: State-of-the-art machine learning for real-world robotics in pytorch,” https://github.com/huggingface/lerobot, 2024. 9 Dayuan Chen(Graduate Student Member...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.