Towards Reliable Agentic Progressive Text-to-Visualization with Verification Rules
Pith reviewed 2026-06-29 00:20 UTC · model grok-4.3
The pith
Progressive multi-turn interactions with a validation agent improve text-to-visualization accuracy over one-shot methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
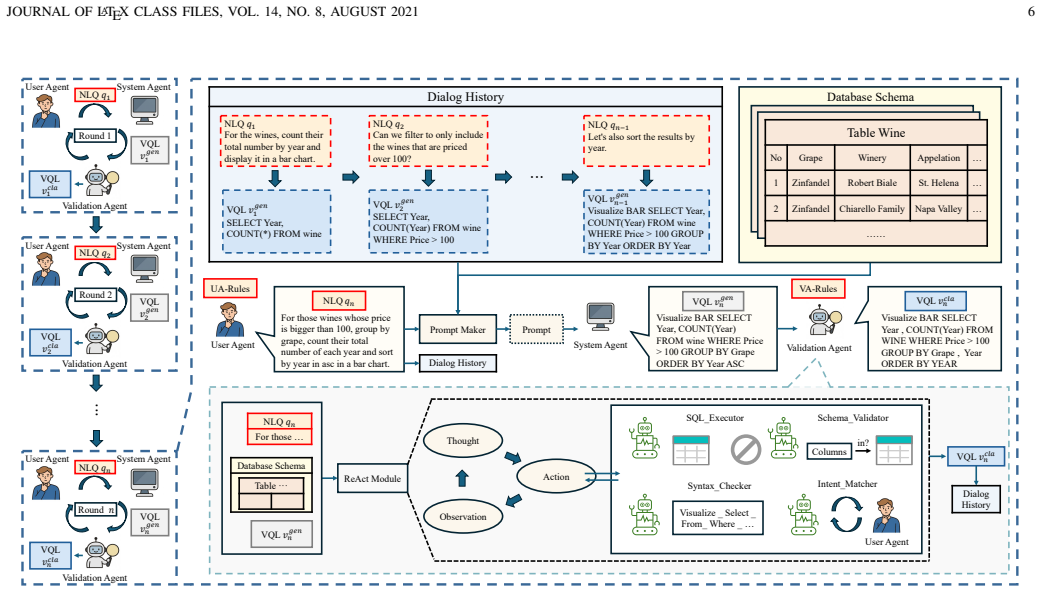
PMVisAgent, built on the progressive PMVis paradigm and the PMVisBench dataset, uses a User agent, a System agent, and a Validation Agent that applies verification and repair through a ReAct-style tool-use loop with explicit interaction and verification rules; this setup produces up to 17.57 percent and 23.21 percent gains in execution accuracy for single-table and multi-table settings respectively.
What carries the argument
The Validation Agent that performs verification and repair via a ReAct-style tool-use loop with explicit interaction and verification rules.
If this is right
- Users can refine visualization requirements across multiple turns instead of specifying everything upfront.
- Verification rules keep every intermediate visualization query valid and meaningful.
- Error accumulation is reduced by the validation agent's repair loop across dialogue rounds.
- Both single-table and multi-table scenarios benefit from the combined progressive interaction and clarification steps.
Where Pith is reading between the lines
- The multi-agent verification pattern could transfer to other iterative generation tasks such as text-to-SQL or code synthesis.
- The dataset construction method of rule-constrained simplification and reconstruction offers a template for building progressive benchmarks in additional domains.
- Deployment in interactive data tools might allow non-experts to explore datasets through natural back-and-forth dialogue rather than precise single queries.
Load-bearing premise
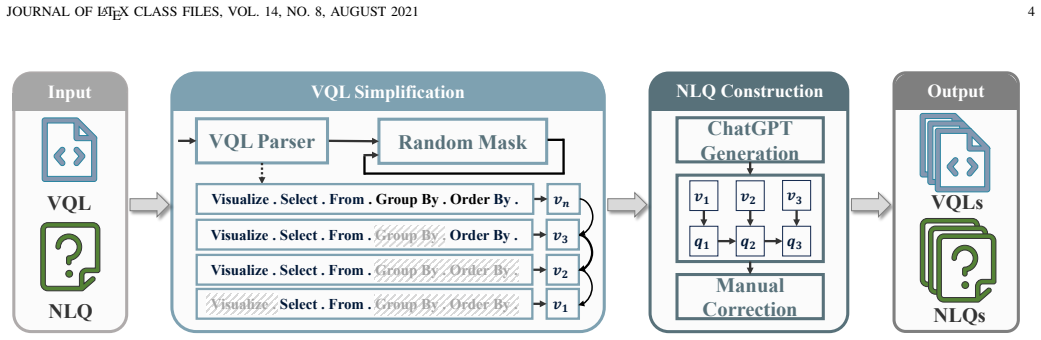
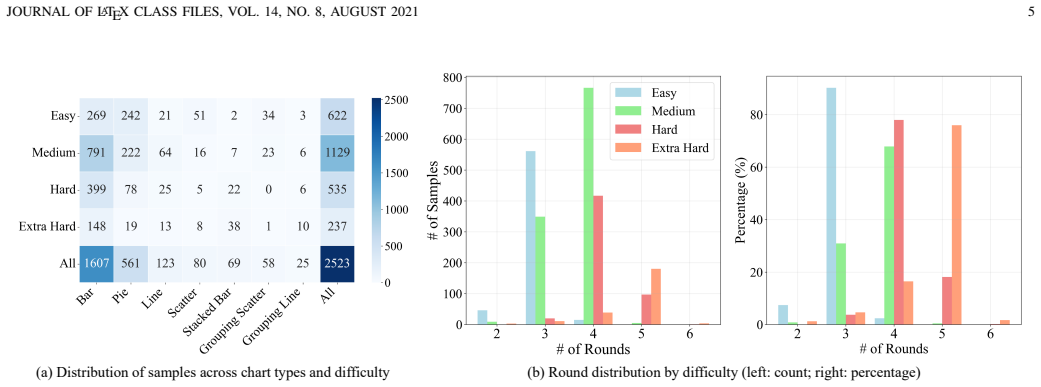
The PMVisBench dataset, built through VQL simplification and NLQ reconstruction with explicit rule constraints, accurately captures the progressive and iterative nature of real-world user queries.
What would settle it
Running the same evaluation protocol on logs of actual non-expert users issuing iterative visualization requests and finding no accuracy gain or a drop relative to one-shot baselines.
Figures

read the original abstract
Text-to-Visualization (Text-to-Vis) translates natural language queries into visualization query languages, enabling non-expert users to perform data analysis. However, most existing methods follow a one-shot paradigm that requires users to specify all visualization details in a single round, often leading to cognitive overload and incorrect visualizations. In this paper, we propose PMVis, a progressive multi-turn paradigm for text-to-vis, where users' intents are refined through multi-turn interactions. To support research in this paradigm, we construct PMVisBench, the first dataset designed to capture the progressive and iterative nature of real-world user queries. It is built through VQL simplification and NLQ reconstruction, with explicit rule constraints to ensure each intermediate VQL remains valid and meaningful. Building upon PMVis, we further introduce PMVisAgent, an agent-based framework that simulates realistic user-system dialogues. PMVisAgent consists of a User, a System, and a Validation Agent that performs verification and repair via a ReAct-style tool-use loop to mitigate error accumulation across rounds, with explicit interaction and verification rules to ensure reliability of the multi-agent system. Extensive experiments on PMVisBench demonstrate that PMVisAgent significantly outperforms state-of-the-art text-to-vis baselines. It achieves up to 17.57\% and 23.21\% improvements in execution accuracy in single-table and multi-table settings, respectively, while ablation studies confirm the importance of combining progressive interaction with clarification. The code is available at https://github.com/wxxv/PMVis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PMVis, a progressive multi-turn paradigm for text-to-visualization that refines user intents iteratively, constructs PMVisBench as the first dataset for this setting via VQL simplification and NLQ reconstruction under explicit validity rule constraints, and introduces PMVisAgent, a multi-agent framework (User, System, Validation Agent) that uses a ReAct-style tool-use loop with verification and repair rules to mitigate error accumulation. Experiments on PMVisBench report that PMVisAgent outperforms state-of-the-art one-shot text-to-vis baselines by up to 17.57% and 23.21% execution accuracy in single-table and multi-table settings, with ablations confirming the value of progressive interaction plus clarification; code is released.
Significance. If the results hold under fair evaluation, the work is significant for shifting text-to-vis research from one-shot to realistic progressive interactions, providing the first benchmark capturing iterative query refinement, and demonstrating a reliable agentic architecture with explicit verification rules. The open-sourced code is a clear strength for reproducibility.
major comments (1)
- [PMVisBench construction] PMVisBench construction (abstract and dataset section): the process of simplifying existing VQLs and reconstructing NLQs under explicit rule constraints that keep every intermediate VQL valid risks systematically producing query sequences whose error patterns match exactly those targeted by the Validation Agent's repair rules. This raises the possibility that the reported 17.57%/23.21% gains reflect benchmark engineering rather than intrinsic superiority of the progressive + ReAct design over one-shot baselines.
minor comments (1)
- [Abstract] Abstract: the headline percentage improvements are stated without naming the baselines, reporting statistical significance, error bars, or the number of runs; the full experimental section should make these details explicit.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for raising this important concern about potential benchmark construction artifacts. We address the comment directly below.
read point-by-point responses
-
Referee: [PMVisBench construction] PMVisBench construction (abstract and dataset section): the process of simplifying existing VQLs and reconstructing NLQs under explicit rule constraints that keep every intermediate VQL valid risks systematically producing query sequences whose error patterns match exactly those targeted by the Validation Agent's repair rules. This raises the possibility that the reported 17.57%/23.21% gains reflect benchmark engineering rather than intrinsic superiority of the progressive + ReAct design over one-shot baselines.
Authors: The PMVisBench construction starts from real VQL queries drawn from existing datasets and applies simplification to derive multi-turn sequences. The explicit rule constraints are general VQL validity rules (schema compliance, valid column references, executable aggregations, etc.) whose sole purpose is to guarantee that every intermediate ground-truth VQL is meaningful and executable; they do not encode or inject particular error types. The Validation Agent’s ReAct-style verification and repair rules, by contrast, operate on the agent’s own reasoning trace and tool calls to detect and correct generation-time mistakes (e.g., incomplete intent, wrong tool parameters). These two rule sets address orthogonal concerns: one ensures benchmark ground truth is valid, the other mitigates error accumulation inside the agent loop. Because one-shot baselines are evaluated on the final NLQ alone, they receive no benefit from the progressive structure. Ablation results further isolate the contribution of progressive interaction and the validation component. We will add an explicit subsection clarifying the distinction between construction-time validity rules and agent-time repair rules. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's claims rest on empirical execution-accuracy gains of PMVisAgent versus baselines when evaluated on the newly constructed PMVisBench. Benchmark construction (VQL simplification + NLQ reconstruction under rule constraints) and the agent's ReAct-style verification rules are presented as separate design elements intended to model progressive queries; no equations, fitted parameters, or self-citation chains are shown that reduce the reported deltas to the inputs by construction. The evaluation is therefore self-contained against the stated baselines and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Synthesizing natural language to visualization (nl2vis) benchmarks from nl2sql benchmarks,
Y . Luo, N. Tang, G. Li, C. Chai, W. Li, and X. Qin, “Synthesizing natural language to visualization (nl2vis) benchmarks from nl2sql benchmarks,” inProceedings of the 2021 ACM SIGMOD International Conference on Management of Data, 2021, pp. 1235–1247
2021
-
[2]
Aurora: Data-driven construction of visual graph query interfaces for graph databases,
S. S. Bhowmick, K. Huang, H. E. Chua, Z. Yuan, B. Choi, and S. Zhou, “Aurora: Data-driven construction of visual graph query interfaces for graph databases,” inProceedings of the 2020 ACM SIGMOD Interna- tional Conference on Management of Data, 2020, pp. 2689–2692
2020
-
[3]
Multivis-agent: A multi- agent framework with logic rules for reliable and comprehensive cross- modal data visualization,
J. Lu, Y . Song, C. Zhang, and R. C.-W. Wong, “Multivis-agent: A multi- agent framework with logic rules for reliable and comprehensive cross- modal data visualization,” vol. 4, no. 1. ACM, feb 2026
2026
-
[4]
Haichart: Human and ai paired visualization system,
Y . Xie, Y . Luo, G. Li, and N. Tang, “Haichart: Human and ai paired visualization system,”Proceedings of the VLDB Endowment, vol. 17, no. 11, pp. 3178–3191, 2024
2024
-
[5]
Navigating data repositories: Utilizing line charts to discover relevant datasets,
D. Ji, H. Luo, Z. Bao, and S. Culpepper, “Navigating data repositories: Utilizing line charts to discover relevant datasets,”Proceedings of the VLDB Endowment, vol. 17, no. 12, pp. 4289–4292, 2024
2024
-
[6]
Seedb: Efficient data-driven visualization recommendations to support visual analytics,
M. Vartak, S. Rahman, S. Madden, A. Parameswaran, and N. Polyzotis, “Seedb: Efficient data-driven visualization recommendations to support visual analytics,” inProceedings of the VLDB Endowment International Conference on Very Large Data Bases, vol. 8, no. 13, 2015, p. 2182
2015
-
[7]
Crowdchart: Crowdsourced data extraction from visualization charts,
C. Chai, G. Li, J. Fan, and Y . Luo, “Crowdchart: Crowdsourced data extraction from visualization charts,”IEEE Transactions on Knowledge and Data Engineering, vol. 33, no. 11, pp. 3537–3549, 2020
2020
-
[8]
Steerable self- driving data visualization,
Y . Luo, X. Qin, C. Chai, N. Tang, G. Li, and W. Li, “Steerable self- driving data visualization,”IEEE Transactions on Knowledge and Data Engineering, vol. 34, no. 1, pp. 475–490, 2020
2020
-
[9]
Natural language interfaces for tabular data querying and visualization: A survey,
W. Zhang, Y . Wang, Y . Song, V . J. Wei, Y . Tian, Y . Qi, J. H. Chan, R. C.- W. Wong, and H. Yang, “Natural language interfaces for tabular data querying and visualization: A survey,”IEEE Transactions on Knowledge and Data Engineering, vol. 36, no. 11, pp. 6699–6718, 2024
2024
-
[10]
Visualization recommendation through visual relation learning and visual preference learning,
D. Ji, H. Luo, and Z. Bao, “Visualization recommendation through visual relation learning and visual preference learning,” in2023 IEEE 39th International Conference on Data Engineering (ICDE). IEEE, 2023, pp. 1860–1873
2023
-
[11]
Towards robustness of text-to-visualization translation against lexical and phrasal variability,
J. Lu, Y . Song, H. Zhang, C. J. Zhang, K. Wu, and R. C.-W. Wong, “Towards robustness of text-to-visualization translation against lexical and phrasal variability,” in2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE Computer Society, 2025, pp. 793–806
2025
-
[12]
Datavist5: A pre-trained language model for jointly understanding text and data visualization,
Z. Wan, Y . Song, S. Li, C. J. Zhang, and R. C.-W. Wong, “Datavist5: A pre-trained language model for jointly understanding text and data visualization,” in2025 IEEE 41st International Conference on Data Engineering (ICDE). IEEE, 2025, pp. 1704–1717
2025
-
[13]
Vega- lite: A grammar of interactive graphics,
A. Satyanarayan, D. Moritz, K. Wongsuphasawat, and J. Heer, “Vega- lite: A grammar of interactive graphics,”IEEE transactions on visual- ization and computer graphics, vol. 23, no. 1, pp. 341–350, 2016
2016
-
[14]
ggplot2: elegant graphics for data analysis,
R. A. M. Villanueva and Z. J. Chen, “ggplot2: elegant graphics for data analysis,” 2019
2019
-
[15]
Natural language to visualization by neural machine translation,
Y . Luo, N. Tang, G. Li, J. Tang, C. Chai, and X. Qin, “Natural language to visualization by neural machine translation,”IEEE Transactions on Visualization and Computer Graphics, vol. 28, no. 1, pp. 217–226, 2021
2021
-
[16]
nvbench 2.0: Resolving ambiguity in text-to-visualization through stepwise reasoning,
T. Luo, C. Huang, L. Shen, B. Li, S. Shen, W. Zeng, N. Tang, and Y . Luo, “nvbench 2.0: Resolving ambiguity in text-to-visualization through stepwise reasoning,”arXiv preprint arXiv:2503.12880, 2025
-
[17]
Viseval: A benchmark for data visualization in the era of large language models,
N. Chen, Y . Zhang, J. Xu, K. Ren, and Y . Yang, “Viseval: A benchmark for data visualization in the era of large language models,”IEEE Transactions on Visualization and Computer Graphics, 2024
2024
-
[18]
Interactive text-to- visualization: Refining visualization outputs through natural language user feedback,
X. Xiong, R. C.-W. Wong, and Y . Song, “Interactive text-to- visualization: Refining visualization outputs through natural language user feedback,” inProceedings of the 34th ACM International Confer- ence on Information and Knowledge Management, 2025, pp. 3571–3581
2025
-
[19]
Marrying dialogue systems with data visualization: Interactive data visualization generation from natural language conversations,
Y . Song, X. Zhao, and R. C.-W. Wong, “Marrying dialogue systems with data visualization: Interactive data visualization generation from natural language conversations,” inProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 2733– 2744
2024
-
[20]
Rgvisnet: A hybrid retrieval-generation neural framework towards automatic data visualiza- tion generation,
Y . Song, X. Zhao, R. C.-W. Wong, and D. Jiang, “Rgvisnet: A hybrid retrieval-generation neural framework towards automatic data visualiza- tion generation,” inProceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 1646–1655
2022
-
[21]
Automated data visualization from natural language via large language models: An exploratory study,
Y . Wu, Y . Wan, H. Zhang, Y . Sui, W. Wei, W. Zhao, G. Xu, and H. Jin, “Automated data visualization from natural language via large language models: An exploratory study,”Proceedings of the ACM on Management of Data, vol. 2, no. 3, pp. 1–28, 2024
2024
-
[22]
nvAgent: Automated data visualization from natural language via collaborative agent workflow,
G. Ouyang, J. Chen, Z. Nie, Y . Gui, Y . Wan, H. Zhang, and D. Chen, “nvAgent: Automated data visualization from natural language via collaborative agent workflow,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2025, pp. 19 534–19 567
2025
-
[23]
Automatic data visualization generation from chinese natural language questions,
Y . Ge, V . J. Wei, Y . Song, J. C. Zhang, and R. C.-W. Wong, “Automatic data visualization generation from chinese natural language questions,” inProceedings of the 2024 Joint International Conference on Computa- tional Linguistics, Language Resources and Evaluation (LREC-COLING 2024), 2024, pp. 1889–1898
2024
-
[24]
Learning to recommend visualizations from data,
X. Qian, R. A. Rossi, F. Du, S. Kim, E. Koh, S. Malik, T. Y . Lee, and J. Chan, “Learning to recommend visualizations from data,” inProceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining, 2021, pp. 1359–1369
2021
-
[25]
Sevi: Speech-to- visualization through neural machine translation,
J. Tang, Y . Luo, M. Ouzzani, G. Li, and H. Chen, “Sevi: Speech-to- visualization through neural machine translation,” inProceedings of the 2022 ACM SIGMOD International Conference on Management of Data, 2022, pp. 2353–2356
2022
-
[26]
Datatone: Managing ambiguity in natural language interfaces for data visual- ization,
T. Gao, M. Dontcheva, E. Adar, Z. Liu, and K. G. Karahalios, “Datatone: Managing ambiguity in natural language interfaces for data visual- ization,” inProceedings of the 28th annual acm symposium on user interface software & technology, 2015, pp. 489–500
2015
-
[27]
Applying pragmatics principles for interaction with visual analytics,
E. Hoque, V . Setlur, M. Tory, and I. Dykeman, “Applying pragmatics principles for interaction with visual analytics,”IEEE transactions on visualization and computer graphics, vol. 24, no. 1, pp. 309–318, 2017. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14
2017
-
[28]
Flowsense: A natural language interface for visual data exploration within a dataflow system,
B. Yu and C. T. Silva, “Flowsense: A natural language interface for visual data exploration within a dataflow system,”IEEE transactions on visualization and computer graphics, vol. 26, no. 1, pp. 1–11, 2019
2019
-
[29]
Data2vis: Automatic generation of data visualizations using sequence-to-sequence recurrent neural networks,
V . Dibia and C ¸ . Demiralp, “Data2vis: Automatic generation of data visualizations using sequence-to-sequence recurrent neural networks,” IEEE computer graphics and applications, vol. 39, no. 5, pp. 33–46, 2019
2019
-
[30]
Chat2vis: Generating data visualizations via natural language using chatgpt, codex and gpt-3 large language models,
P. Maddigan and T. Susnjak, “Chat2vis: Generating data visualizations via natural language using chatgpt, codex and gpt-3 large language models,”Ieee Access, vol. 11, pp. 45 181–45 193, 2023
2023
-
[31]
prompt4vis: prompting large language models with example mining for tabular data visualization,
S. Li, X. Chen, Y . Song, Y . Song, C. J. Zhang, F. Hao, and L. Chen, “prompt4vis: prompting large language models with example mining for tabular data visualization,”The VLDB Journal, vol. 34, no. 4, pp. 1–26, 2025
2025
-
[32]
The design and implementation of xiaoice, an empathetic social chatbot,
L. Zhou, J. Gao, D. Li, and H.-Y . Shum, “The design and implementation of xiaoice, an empathetic social chatbot,”Computational Linguistics, vol. 46, no. 1, pp. 53–93, 2020
2020
-
[33]
2020.Towards a human-like open-domain chatbot
D. Adiwardana, M.-T. Luong, D. R. So, J. Hall, N. Fiedel, R. Thoppilan, Z. Yang, A. Kulshreshtha, G. Nemade, Y . Luet al., “Towards a human- like open-domain chatbot,”arXiv preprint arXiv:2001.09977, 2020
-
[34]
Blenderbot 3: a deployed conversational agent that continually learns to responsibly engage,
K. Shuster, J. Xu, M. Komeili, D. Ju, E. M. Smith, S. Roller, M. Ung, M. Chen, K. Arora, J. Laneet al., “Blenderbot 3: a deployed con- versational agent that continually learns to responsibly engage,”arXiv preprint arXiv:2208.03188, 2022
-
[35]
Dialogue act recognition via crf-attentive structured network,
Z. Chen, R. Yang, Z. Zhao, D. Cai, and X. He, “Dialogue act recognition via crf-attentive structured network,” inThe 41st international acm sigir conference on research & development in information retrieval, 2018, pp. 225–234
2018
-
[36]
Recent advances and challenges in task-oriented dialog systems,
Z. Zhang, R. Takanobu, Q. Zhu, M. Huang, and X. Zhu, “Recent advances and challenges in task-oriented dialog systems,”Science China Technological Sciences, vol. 63, no. 10, pp. 2011–2027, 2020
2011
-
[37]
Recent neural methods on dialogue state tracking for task-oriented dialogue systems: A survey,
V . Balaraman, S. Sheikhalishahi, and B. Magnini, “Recent neural methods on dialogue state tracking for task-oriented dialogue systems: A survey,” inProceedings of the 22nd annual meeting of the special interest group on discourse and dialogue, 2021, pp. 239–251
2021
-
[38]
End-to-end task-completion neural dialogue systems,
X. Li, Y .-N. Chen, L. Li, J. Gao, and A. Celikyilmaz, “End-to-end task-completion neural dialogue systems,” inProceedings of the Eighth International Joint Conference on Natural Language Processing (Volume 1: Long Papers), 2017, pp. 733–743
2017
-
[39]
A network-based end-to-end trainable task-oriented dialogue system,
T.-H. Wen, D. Vandyke, N. Mrk ˇsi´c, M. Gasic, L. M. R. Barahona, P.- H. Su, S. Ultes, and S. Young, “A network-based end-to-end trainable task-oriented dialogue system,” inProceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, 2017, pp. 438–449
2017
-
[40]
Ubar: Towards fully end-to-end task- oriented dialog system with gpt-2,
Y . Yang, Y . Li, and X. Quan, “Ubar: Towards fully end-to-end task- oriented dialog system with gpt-2,” inProceedings of the AAAI confer- ence on artificial intelligence, vol. 35, no. 16, 2021, pp. 14 230–14 238
2021
-
[41]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.