Fairness-Aware Profit Maximization using Deep Reinforcement Learning
Pith reviewed 2026-06-29 00:00 UTC · model grok-4.3
The pith
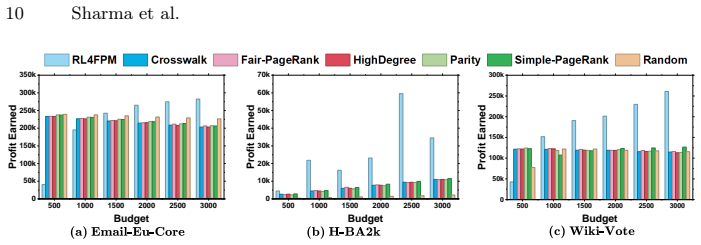
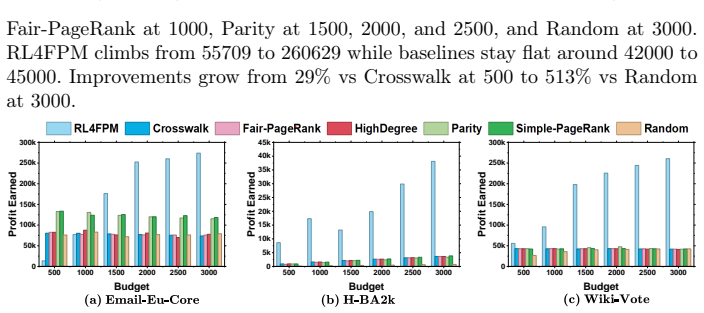
A deep Q-learning algorithm finds seed sets in social networks that produce up to 10 times more profit than baselines while satisfying maximin fairness across communities.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
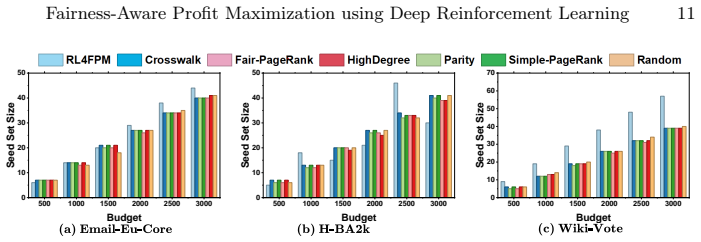
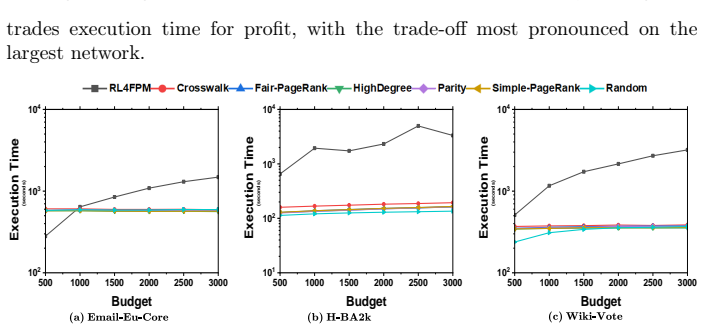
The authors claim that by modeling the Fairness-Aware Profit Maximization Problem as a Markov Decision Process and applying a Deep Q-Learning Algorithm, one can obtain a seed set whose initial activation produces up to 10 times more profit than baseline methods on real-world social network datasets while satisfying the maximin fairness criterion that each community realizes at least a minimum fraction of its total benefit.
What carries the argument
The Deep Q-Learning algorithm trained on an MDP where the state tracks the current seed set and remaining budget, actions add a user to the seed set, and the reward combines the eventual profit with a penalty for violating community fairness thresholds.
If this is right
- The method allows selection of influencers that respect community equity while pursuing profit maximization in budgeted campaigns.
- Experimental results indicate that the DRL approach significantly outperforms traditional optimization techniques in terms of achieved profit under fairness constraints.
- The MDP formulation enables handling of the uncertain spread of influence through repeated simulations or learned value functions.
- Implementation on real datasets demonstrates practical feasibility for networks with community structure.
Where Pith is reading between the lines
- Reinforcement learning techniques may prove useful for other constrained influence problems where both stochastic spread and group fairness must be considered simultaneously.
- If the profit gains hold, this could shift how platforms design recommendation or seeding strategies to include explicit fairness metrics.
- The approach might generalize to settings with multiple budgets or time-varying user benefits, though that remains untested here.
Load-bearing premise
The Markov Decision Process formulation correctly encodes both the stochastic influence propagation process and the maximin fairness constraint so that the learned Q-function produces feasible, high-profit seed sets.
What would settle it
If independent runs of the Deep Q-Learning algorithm on the reported real-world datasets produce seed sets with profit gains much smaller than 10 times the baselines or with some communities receiving less than the required minimum benefit fraction, the performance advantage would be called into question.
Figures
read the original abstract
Given a social network represented as a graph where the nodes are the users and the edges represent the social relations, and a positive integer k, how to select k nodes to maximize the influence in the network remains an active area of research. In this paper, we consider a variant of the problem in which network users are associated with two parameters: a benefit value and a cost. A fixed budget is given, and the network is partitioned into communities. The task is to select a subset of users (the seed set) within the budget so that their initial activation maximizes the earned profit, while ensuring that each community realizes at least a minimum fraction of its total benefit under a maximin fairness criterion. For any seed set, the earned benefit is defined as the sum of the benefit values of the users influenced by the seed set, and the profit is defined as the difference between the earned benefit and the total cost. Formally, we call this the Fairness-Aware Profit Maximization Problem. We propose a Deep Reinforcement Learning-based approach for solving it: we first model the problem as a Markov Decision Process and subsequently propose a Deep Q-Learning Algorithm. The proposed solution has been implemented and tested on real-world social network datasets. From the reported results, we observed that the proposed approach yields a seed set whose initial activation produces up to 10 times more profit than the baseline methods. The implementation of our methodology is available at https://github.com/PoonamSharma-PY/DRL_FPM.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines the Fairness-Aware Profit Maximization Problem: given a social network partitioned into communities, node benefit and cost values, and a budget, select a seed set of size at most k (implicitly constrained by budget) to maximize profit (total benefit of influenced nodes minus total seed cost) while satisfying a maximin fairness criterion that each community receives at least a minimum fraction of its total possible benefit. The problem is modeled as an MDP and solved with a Deep Q-Learning algorithm; experiments on real-world datasets are claimed to produce seed sets yielding up to 10× higher profit than baselines while meeting the fairness constraint. Code is released at a GitHub repository.
Significance. If the empirical claims and MDP encoding are validated, the work would demonstrate a practical DRL method for a constrained combinatorial optimization task that jointly optimizes profit and community fairness, which is relevant to equitable influence maximization in marketing and information dissemination. The public code release supports reproducibility, a strength for an empirical RL paper.
major comments (2)
- [Abstract] Abstract: the central claim that the Deep Q-Learning algorithm 'yields a seed set whose initial activation produces up to 10 times more profit than the baseline methods' supplies no information on network sizes, number of communities, influence model (e.g., Independent Cascade edge probabilities), baseline algorithms and their fairness handling, how the maximin constraint is encoded in the MDP reward or as a constraint, or any measure of statistical significance or variance across runs. This absence prevents assessment of the reported performance gain.
- [Proposed Approach / MDP Formulation] MDP formulation and reward design (section describing the proposed approach): the manuscript does not specify the state representation, action space, transition function that models stochastic propagation, or the precise reward that enforces the maximin fairness criterion. Without these definitions it is impossible to verify whether the learned Q-function produces feasible seed sets that satisfy the fairness constraint by construction or only approximately via reward shaping.
minor comments (2)
- [Abstract] The abstract states that 'a positive integer k' is given yet later refers to selection 'within the budget'; the relationship between k and the budget constraint should be clarified.
- [Abstract] The GitHub link is provided but no mention is made of the exact datasets, random seeds, or hyper-parameters used in the reported runs, which would aid reproducibility even if the full experimental protocol remains underspecified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the Deep Q-Learning algorithm 'yields a seed set whose initial activation produces up to 10 times more profit than the baseline methods' supplies no information on network sizes, number of communities, influence model (e.g., Independent Cascade edge probabilities), baseline algorithms and their fairness handling, how the maximin constraint is encoded in the MDP reward or as a constraint, or any measure of statistical significance or variance across runs. This absence prevents assessment of the reported performance gain.
Authors: We agree that the abstract is insufficiently detailed. In the revised version we will expand it to report network sizes and community counts from the evaluated datasets, specify the Independent Cascade model and edge probabilities, name the baseline algorithms and describe their fairness handling, explain the maximin encoding within the MDP, and include mean profit values with standard deviations across runs. revision: yes
-
Referee: [Proposed Approach / MDP Formulation] MDP formulation and reward design (section describing the proposed approach): the manuscript does not specify the state representation, action space, transition function that models stochastic propagation, or the precise reward that enforces the maximin fairness criterion. Without these definitions it is impossible to verify whether the learned Q-function produces feasible seed sets that satisfy the fairness constraint by construction or only approximately via reward shaping.
Authors: The referee correctly notes that these MDP components are not explicitly defined. We will add a dedicated subsection that specifies the state representation (e.g., current seed set and community benefit vectors), action space (node selection under budget), transition function (stochastic Independent Cascade propagation), and the exact reward function that incorporates the maximin fairness threshold. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes modeling the fairness-aware profit maximization task as an MDP and solving it via a Deep Q-Learning algorithm, with performance evaluated empirically on real-world datasets. No analytic derivation chain, first-principles result, or mathematical prediction is presented that reduces to its own inputs by construction. Claims rest on experimental outcomes rather than self-referential definitions, fitted parameters renamed as predictions, or load-bearing self-citations. The approach is self-contained against external benchmarks in the reported sense, yielding a normal non-finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Technology and Society Perspectives (TACIT)1(1), 1–9 (2023)
Azzaakiyyah, H.K.: The impact of social media use on social interaction in contem- porary society. Technology and Society Perspectives (TACIT)1(1), 1–9 (2023)
2023
-
[2]
Knowledge and Information Systems62(9), 3417–3455 (2020)
Banerjee, S., Jenamani, M., Pratihar, D.K.: A survey on influence maximization in a social network. Knowledge and Information Systems62(9), 3417–3455 (2020)
2020
-
[3]
EBOOK (2024)
Borgatti, S.P., Agneessens, F., Johnson, J.C., Everett, M.G.: Analyzing social net- works. EBOOK (2024)
2024
-
[4]
Theoretical Computer Science803, 36–47 (2020)
Chen, T., Liu, B., Liu, W., Fang, Q., Yuan, J., Wu, W.: A random algorithm for profit maximization in online social networks. Theoretical Computer Science803, 36–47 (2020)
2020
-
[5]
In: International conference on machine learning
Dai, H., Dai, B., Song, L.: Discriminative embeddings of latent variable models for structured data. In: International conference on machine learning. pp. 2702–2711. PMLR (2016)
2016
-
[6]
In: Proceedings of the Ninth ACM SIGKDD International Con- ference on Knowledge Discovery and Data Mining (KDD)
Kempe, D., Kleinberg, J., Tardos, É.: Maximizing the spread of influence through a social network. In: Proceedings of the Ninth ACM SIGKDD International Con- ference on Knowledge Discovery and Data Mining (KDD). pp. 137–146 (2003)
2003
-
[7]
IEEE Transactions on Knowledge and Data Engineering30(10), 1852–1872 (2018)
Li, Y., Fan, J., Wang, Y., Tan, K.L.: Influence maximization on social graphs: A survey. IEEE Transactions on Knowledge and Data Engineering30(10), 1852–1872 (2018)
2018
-
[8]
In: ML Reproducibility Challenge 2022 (2023),https://openreview
Pantea, L., Blahovici, A.E.: [re] crosswalk: Fairness-enhanced node representation learning. In: ML Reproducibility Challenge 2022 (2023),https://openreview. net/forum?id=tpk45Zll8eh
2022
-
[9]
com, and bukalapak (2022)
Rachmad, Y.E.: Social media marketing mediated changes in consumer behavior from e-commerce to s-commerce at tokopedia, lazada, shopee, blibli. com, and bukalapak (2022)
2022
-
[10]
ArXivabs/2512.00545(2025), https://api.semanticscholar.org/CorpusID:283448886
Saxena, A., Yadav, H., Rutten, B., Jha, S.S.: Dq4fairim: Fairness-aware influence maximization using deep reinforcement learning. ArXivabs/2512.00545(2025), https://api.semanticscholar.org/CorpusID:283448886
-
[11]
ACM computing surveys56(8), 1–39 (2024)
Singh, S.S., Muhuri, S., Mishra, S., Srivastava, D., Shakya, H.K., Kumar, N.: Social network analysis: A survey on process, tools, and application. ACM computing surveys56(8), 1–39 (2024)
2024
-
[12]
In: Pro- ceedings of the Conference
Song, L.: Structure2vec: Deep learning for security analytics over graphs. In: Pro- ceedings of the Conference. USENIX Association, Atlanta, GA (May 2018)
2018
-
[13]
In: Proceedings of The Web Conference 2020
Stoica, A.A., Han, J.X., Chaintreau, A.: Seeding network influence in biased net- works and the benefits of diversity. In: Proceedings of The Web Conference 2020. p. 2089–2098. WWW ’20, Association for Computing Machinery, New York, NY, USA(2020).https://doi.org/10.1145/3366423.3380275,https://doi.org/10. 1145/3366423.3380275
-
[14]
IEEE Transactions on Knowledge and Data Engineering30(6), 1095–1108 (2017)
Tang, J., Tang, X., Yuan, J.: Profit maximization for viral marketing in online social networks: Algorithms and analysis. IEEE Transactions on Knowledge and Data Engineering30(6), 1095–1108 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.