ARIADNE: AI-RAN Informed Link Adaptation in Digital Twin Network Environments
Pith reviewed 2026-06-29 00:40 UTC · model grok-4.3
The pith
An online reinforcement learning module for link adaptation in digital twin environments achieves up to 20 percent higher spectral efficiency than state-of-the-art methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
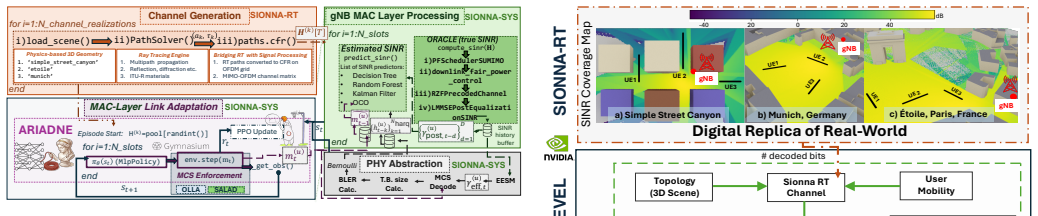
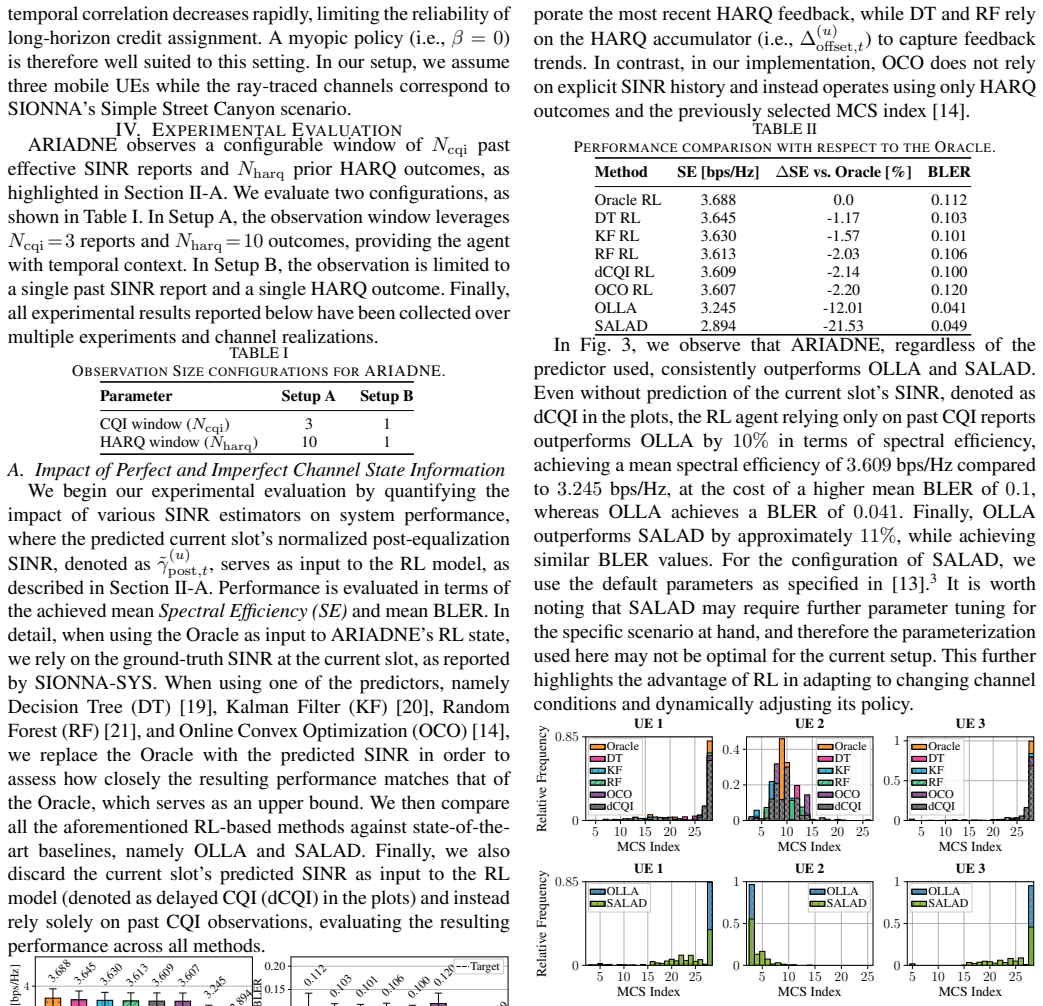
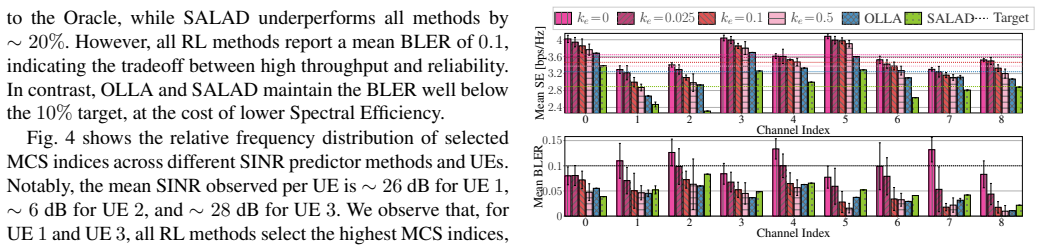
ARIADNE is an online reinforcement learning module tasked with link adaptation that integrates with SIONNA digital twins. When tested in these environments it surpasses industry-standard methods by up to 11 percent and state-of-the-art methods by up to 20 percent in spectral efficiency. The learned modulation and coding scheme selection strategy diverges from outer-loop link adaptation, producing either more conservative or more aggressive behavior depending on configuration, a pattern confirmed when the same reinforcement learning approach is trained offline on real 5G over-the-air measurements.
What carries the argument
The reinforcement learning policy that maps observed channel conditions in the digital twin to modulation and coding scheme choices.
If this is right
- RL policies for modulation selection can be trained and validated entirely inside digital twins before any hardware exposure.
- Spectral efficiency gains of 11 to 20 percent become attainable relative to conventional outer-loop link adaptation.
- The learned policy can adopt either more conservative or more aggressive modulation choices than traditional methods, depending on the chosen training configuration.
- Offline training on real 5G over-the-air measurements produces the same qualitative divergence from outer-loop link adaptation observed in simulation.
Where Pith is reading between the lines
- If the simulation-to-reality gap proves small, operators could iterate on AI-driven radio algorithms at far lower cost than current field-test cycles allow.
- The same reinforcement learning structure could be extended to other radio access tasks such as resource scheduling or transmit power control.
- Hybrid systems that blend the learned policy with conventional outer-loop adjustments might combine the strengths of both approaches.
Load-bearing premise
The digital twin simulation built with SIONNA accurately captures the channel and interference conditions that the RL policy will encounter when deployed on real RAN hardware.
What would settle it
Deploy the trained RL policy on physical 5G base stations, measure the resulting spectral efficiency under live traffic, and check whether the reported gains over outer-loop link adaptation still appear.
Figures




read the original abstract
Artificial Intelligence (AI)-powered Radio Access Network (RAN) networks have attracted significant attention from both industry and academia. Meanwhile, Digital Twins offer a safe playground for experimenting with AI/Machine Learning (ML)-based solutions for advanced AI-RAN research. By enabling the testing of online algorithms before deployment on the RAN, they reduce costs and safety risks associated with physical field testing. In this article, we propose ARIADNE, an online Reinforcement Learning (RL)-based module that seamlessly integrates with SIONNA and is tasked with performing link adaptation. We explore different design choices and demonstrate how ARIADNE can surpass industry-standard and state-of-the-art methods by achieving up to 11% and 20% improvements in Spectral Efficiency, respectively. Finally, we show that RL learns a Modulation and Coding Scheme (MCS) selection strategy that diverges from Outer Loop Link Adaptation (OLLA), exhibiting either more conservative or more aggressive behavior depending on the configuration, a trend further corroborated by training offline on 5th generation (5G) over-the-air (OTA) measurements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ARIADNE, an online RL-based link adaptation module integrated with the SIONNA digital twin for AI-RAN research. It explores RL design choices for MCS selection and reports up to 11% and 20% spectral efficiency gains over industry-standard and state-of-the-art baselines, respectively. The work also shows that the learned policy diverges from OLLA (more conservative or aggressive depending on configuration) and corroborates this divergence via offline training on 5G OTA traces.
Significance. If the SIONNA twin's channel and interference models prove sufficiently faithful, the framework could lower the barrier to safe pre-deployment testing of AI-RAN algorithms and yield measurable efficiency gains. The offline OTA validation of policy divergence is a constructive step toward simulation-to-reality bridging; the manuscript would be strengthened by making this fidelity assumption explicit and testable.
major comments (1)
- [Abstract] Abstract: The headline quantitative claims (up to 11% and 20% SE improvements) are obtained entirely inside the SIONNA digital twin. No end-to-end SE results are shown when the same RL policy is executed on the 5G OTA channel realizations or on live RAN hardware, so the fidelity of the twin to real propagation, mobility, and hardware impairments is load-bearing for the central performance claim.
minor comments (2)
- [Abstract] Abstract and §3–4: No training hyperparameters, dataset sizes, number of episodes, or error bars/statistical tests are reported for the SE gains, making it impossible to assess reproducibility or significance of the 11%/20% figures from the provided text.
- The manuscript would benefit from an explicit limitations subsection discussing the domain gap between SIONNA and real RAN hardware impairments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the scope of our results. We agree that the headline performance claims are simulation-based and will revise the manuscript to clarify the role of the digital twin and the OTA validation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline quantitative claims (up to 11% and 20% SE improvements) are obtained entirely inside the SIONNA digital twin. No end-to-end SE results are shown when the same RL policy is executed on the 5G OTA channel realizations or on live RAN hardware, so the fidelity of the twin to real propagation, mobility, and hardware impairments is load-bearing for the central performance claim.
Authors: We agree that the reported spectral efficiency gains are demonstrated exclusively within the SIONNA digital twin. The 5G OTA traces are used only to corroborate the policy divergence from OLLA (more conservative or aggressive behavior), not to re-evaluate absolute SE improvements. We will revise the abstract to explicitly distinguish these two contributions and add a new subsection discussing the twin's modeling assumptions (channel, interference, mobility) together with the limitations of the current OTA validation. End-to-end execution of the trained policy on live hardware lies outside the scope of this work, which focuses on safe pre-deployment testing in a digital twin. revision: partial
- Providing end-to-end SE results from executing the RL policy on live RAN hardware or full OTA channel realizations, as the study is confined to the SIONNA simulation environment and offline trace analysis.
Circularity Check
No significant circularity; results are empirical simulation outputs, not derived by construction
full rationale
The paper presents ARIADNE as an RL policy trained and evaluated inside the SIONNA digital twin, with reported SE gains (11%/20%) obtained by direct comparison against baselines within the same simulated environment. No equations, fitted parameters renamed as predictions, or self-citation chains are shown in the provided text that would reduce the central claim to its own inputs. The offline OTA training is used only to corroborate policy divergence from OLLA, not to generate the headline performance numbers. The derivation chain is therefore self-contained as standard simulation-based empirical evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
NVIDIA and Nokia to Pioneer the AI Platform for 6G — Powering America’s Return to Telecommunications Leadership,
NVIDIA Corporation, “NVIDIA and Nokia to Pioneer the AI Platform for 6G — Powering America’s Return to Telecommunications Leadership,” NVIDIA Newsroom, Press Release, Oct. 2025, [Available Online]: https: //nvidianews.nvidia.com/news/nvidia-nokia-ai-telecommunications
2025
-
[2]
Nokia launches Nokia RAN Digital Twin to turbo-charge AI-native 6G, powered by NVIDIA Aerial Omniverse Digital Twin,
Nokia, “Nokia launches Nokia RAN Digital Twin to turbo-charge AI-native 6G, powered by NVIDIA Aerial Omniverse Digital Twin,” Nokia Corporate Blog, Feb. 2026, [Available Online]: https: //www.nokia.com/blog/nokia-launches-nokia-ran-digital-twin-to-turbo- charge-ai-native-6g-powered-by-nvidia-aerial-omniverse-digital-twin/
2026
-
[3]
Colosseum: The open RAN digital twin,
M. Polese, L. Bonati, S. D’Oro, P. Johari, D. Villa, S. Velumani, R. Gan- gula, M. Tsampazi, C. P. Robinson, G. Gemmiet al., “Colosseum: The open RAN digital twin,”IEEE Open Journal of the Communications Society, 2024
2024
-
[4]
Sionna: An Open-Source Li- brary for Next-Generation Physical Layer Research,
J. Hoydis, S. Cammerer, F. Ait Aoudia, M. Nimier-David, A. Keller, A. Vem, M. Stark, and T. O’Shea, “Sionna: An Open-Source Li- brary for Next-Generation Physical Layer Research,”arXiv preprint arXiv:2203.11854, 2022
arXiv 2022
-
[5]
Adaptive modulation selection in wireless communications: A comparative study of reinforcement learning, deep learning, deep reinforcement learning, and traditional policies,
N. Khedhri and M. Najar, “Adaptive modulation selection in wireless communications: A comparative study of reinforcement learning, deep learning, deep reinforcement learning, and traditional policies,” inIn- ternational Wireless Communications and Mobile Computing (IWCMC). IEEE, 2025, pp. 1622–1625
2025
-
[6]
Offline reinforcement learn- ing and sequence modeling for downlink link adaptation,
S. Peri, A. Russo, G. Fodor, and P. Soldati, “Offline reinforcement learn- ing and sequence modeling for downlink link adaptation,” inInternational Conference on Machine Learning for Communication and Networking (ICMLCN). IEEE, 2025, pp. 1–7
2025
-
[7]
Reinforcement learning techniques for outer loop link adaptation in 4G/5G systems,
S. K. Pulliyakode and S. Kalyani, “Reinforcement learning techniques for outer loop link adaptation in 4G/5G systems,”arXiv preprint arXiv:1708.00994, 2017
Pith/arXiv arXiv 2017
-
[8]
Contextual multi-armed bandits for link adaptation in cellular networks,
V . Saxena, J. Jald ´en, J. E. Gonzalez, M. Bengtsson, H. Tullberg, and I. Stoica, “Contextual multi-armed bandits for link adaptation in cellular networks,” inWorkshop on Network Meets AI & ML, 2019, pp. 44–49
2019
-
[9]
GrGym: When GNU radio goes to (AI) gym,
A. Zubow, S. R ¨osler, P. Gawłowicz, and F. Dressler, “GrGym: When GNU radio goes to (AI) gym,” inProc. of the 22nd International Workshop on Mobile Computing Systems and Applications, 2021, pp. 8–14
2021
-
[10]
A flexible framework based on reinforcement learning for adaptive modulation and coding in OFDM wireless systems,
J. P. Leite, P. H. P. de Carvalho, and R. D. Vieira, “A flexible framework based on reinforcement learning for adaptive modulation and coding in OFDM wireless systems,” inWireless Communications and Networking Conference (WCNC). IEEE, 2012, pp. 809–814
2012
-
[11]
Frequency domain scheduling for OFDMA with limited and noisy channel feedback,
K. I. Pedersen, G. Monghal, I. Z. Kovacs, T. E. Kolding, A. Pokhariyal, F. Frederiksen, and P. Mogensen, “Frequency domain scheduling for OFDMA with limited and noisy channel feedback,” inIEEE 66th Vehic- ular Technology Conference, 2007, pp. 1792–1796
2007
-
[12]
Reinforcement learning for delay sensitive uplink outer-loop link adaptation,
P. Kela, T. H ¨ohne, T. Veijalainen, and H. Abdulrahman, “Reinforcement learning for delay sensitive uplink outer-loop link adaptation,” inJoint European Conference on Networks and Communications & 6G Summit. IEEE, 2022, pp. 59–64
2022
-
[13]
SALAD: Self-adaptive link adaptation,
R. Wiesmayr, L. Maggi, S. Cammerer, J. Hoydis, F. A. Aoudia, and A. Keller, “SALAD: Self-adaptive link adaptation,”arXiv preprint arXiv:2510.05784, 2025
arXiv 2025
-
[14]
SINR Estimation under Limited Feedback via Online Convex Optimization,
L. Maggi, B. Bonev, R. Wiesmayr, S. Cammerer, and A. Keller, “SINR Estimation under Limited Feedback via Online Convex Optimization,” arXiv preprint arXiv:2603.02061, 2026
arXiv 2026
-
[15]
Nr; physical layer procedures for data (3gpp ts 38.214),
3rd Generation Partnership Project, “Nr; physical layer procedures for data (3gpp ts 38.214),” 2023
2023
-
[16]
Proximal Policy Optimization Algorithms,
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” 2017, [Available Online]: https://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[17]
Stable-Baselines3: Reliable Reinforcement Learning Implemen- tations,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dor- mann, “Stable-Baselines3: Reliable Reinforcement Learning Implemen- tations,” GitHub Repository, 2021, [Available Online]: https://github. com/DLR-RM/stable-baselines3
2021
-
[18]
Gymnasium: A Standard Interface for Reinforce- ment Learning Environments,
Farama Foundation, “Gymnasium: A Standard Interface for Reinforce- ment Learning Environments,” GitHub Repository, 2023, [Available On- line]: https://github.com/Farama-Foundation/Gymnasium
2023
-
[19]
Induction of decision trees,
J. R. Quinlan, “Induction of decision trees,”Machine learning, vol. 1, no. 1, pp. 81–106, 1986
1986
-
[20]
A New Approach to Linear Filtering and Prediction Problems,
R. E. Kalman, “A New Approach to Linear Filtering and Prediction Problems,”Transactions of the ASME–Journal of Basic Engineering, vol. 82, pp. 35–45, 1960
1960
-
[21]
Random Forests,
L. Breiman, “Random Forests,”Machine Learning, vol. 45, 2001
2001
-
[22]
SALAD: Self-Adaptive Link Adaptation — Reference Im- plementation,
NVlabs, “SALAD: Self-Adaptive Link Adaptation — Reference Im- plementation,” GitHub Repository, NVlabs, 2025, [Available Online]: https://github.com/NVlabs/salad/blob/main/notebooks/meet salad.ipynb
2025
-
[23]
Tree-based batch mode reinforce- ment learning,
D. Ernst, P. Geurts, and L. Wehenkel, “Tree-based batch mode reinforce- ment learning,”Journal of Machine Learning Research, vol. 6, 2005
2005
-
[24]
X5G: An open, pro- grammable, multi-vendor, end-to-end, private 5G O-RAN testbed with NVIDIA ARC and OpenAirInterface,
D. Villa, I. Khan, F. Kaltenberger, N. Hedberg, R. S. da Silva, S. Maxenti, L. Bonati, A. Kelkar, C. Dick, E. Baenaet al., “X5G: An open, pro- grammable, multi-vendor, end-to-end, private 5G O-RAN testbed with NVIDIA ARC and OpenAirInterface,”IEEE Transactions on Mobile Computing, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.