RAFI -- A Ray/Work Forwarding Infrastructure for Data Parallel Multi-Node/Multi-GPU Computing
Pith reviewed 2026-06-29 05:22 UTC · model grok-4.3
The pith
RaFI gives CUDA kernels a simple way to forward rays and work items across GPUs while handling all CUDA and MPI details internally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RaFI is a CUDA and MPI based software framework that simplifies the task of building GPU-enabled data-parallel software where rays or similar work items need to migrate between different GPUs. RaFI provides a simple interface for CUDA kernels to forward such work items to other GPUs, while under the hood managing all the CUDA and MPI related work required to make this happen.
What carries the argument
RaFI's kernel-level forwarding interface, which lets CUDA code send work items to remote GPUs and delegates all inter-device CUDA transfers plus MPI messaging to the framework.
If this is right
- Data-parallel codes that move rays or particles across GPUs can be written with far less explicit communication logic.
- Developers can focus kernel logic on the computation rather than on device-to-device data movement.
- Existing multi-GPU ray-tracing and simulation workloads become easier to extend across additional nodes.
Where Pith is reading between the lines
- The same forwarding abstraction could support dynamic load balancing by letting kernels decide at runtime where to send work.
- Adoption would likely require only modest changes to existing CUDA kernels that already contain forwarding logic.
- Performance behavior on very large node counts remains an open question that the provided examples do not address.
Load-bearing premise
The overhead of the added communication layer can be hidden behind the simple interface without large performance penalties or loss of needed flexibility in data-parallel GPU codes.
What would settle it
A side-by-side timing and code-complexity comparison, on a multi-node GPU cluster, between an application written with RaFI and the same application written with direct CUDA and MPI calls.
Figures


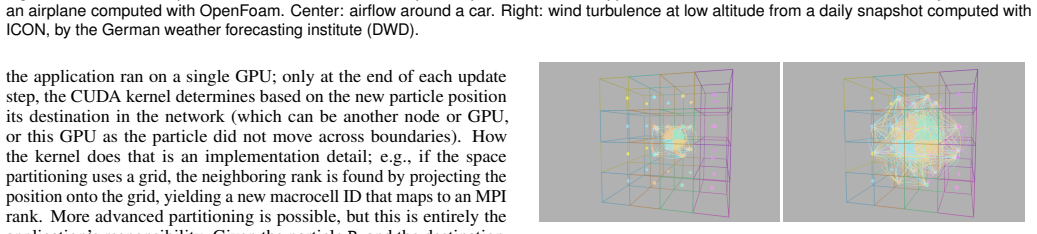
read the original abstract
We present RaFI, a CUDA and MPI based software framework that simplifies the task of building GPU-enabled data-parallel software where rays or similar work items need to migrate between different GPUs. RaFI provides a simple interface for CUDA kernels to forward such work items to other GPUs, while under the hood managing all the CUDA and MPI related work required to make this happen. We describe RaFI's motivation and implementation, and show its potential in several example applications.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents RaFI, a CUDA- and MPI-based software framework for simplifying construction of data-parallel multi-GPU applications in which work items (e.g., rays) must migrate between GPUs. It claims to expose a simple kernel-level forwarding interface while transparently handling all CUDA and MPI details (queues, serialization, transfers, synchronization). The manuscript describes motivation and implementation and illustrates the framework with several example applications.
Significance. If the claimed simplification is achieved without material performance penalty or loss of control relative to hand-written CUDA+MPI code, the framework would be useful for developers of ray-tracing, particle-transport, or similar irregular data-parallel workloads on multi-node GPU systems. The absence of any quantitative evaluation, however, leaves this utility unestablished.
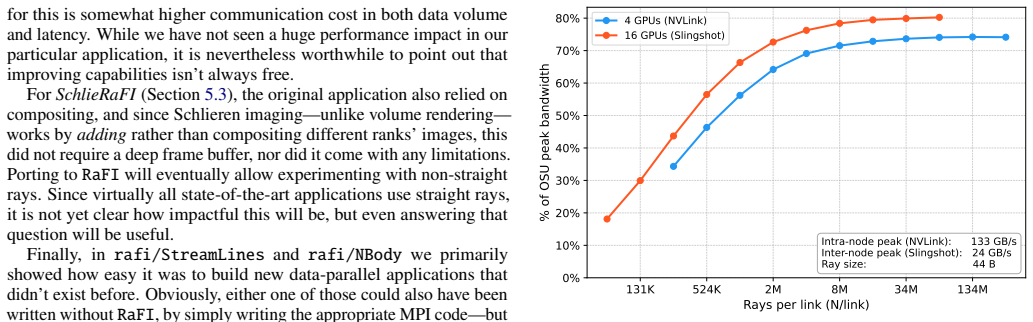
major comments (1)
- [Abstract] Abstract: the central claim that RaFI 'manages all the CUDA and MPI related work' while imposing no significant performance penalties is load-bearing for the framework's value, yet the manuscript supplies no head-to-head timing data, latency measurements, or comparisons against equivalent manual implementations; this omission prevents assessment of whether the added layers (queues, serialization, inter-GPU transfers) are negligible.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that quantitative performance data is required to substantiate the framework's value proposition and will address this in the revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that RaFI 'manages all the CUDA and MPI related work' while imposing no significant performance penalties is load-bearing for the framework's value, yet the manuscript supplies no head-to-head timing data, latency measurements, or comparisons against equivalent manual implementations; this omission prevents assessment of whether the added layers (queues, serialization, inter-GPU transfers) are negligible.
Authors: We acknowledge that the manuscript currently lacks head-to-head timing data and comparisons against manual CUDA+MPI implementations, which is necessary to evaluate any overhead from the framework's queues, serialization, and transfer mechanisms. In the revised version we will add a dedicated evaluation section containing latency and throughput measurements for the example applications, directly comparing RaFI against equivalent hand-written code on the same hardware and workloads. This will allow readers to assess whether the added layers impose material penalties. revision: yes
Circularity Check
No circularity: software framework description with no derivations or fitted predictions
full rationale
The paper presents a CUDA/MPI software infrastructure (RaFI) for forwarding work items across GPUs, describing its interface, implementation, and example applications. No mathematical derivations, first-principles predictions, fitted parameters, or uniqueness theorems appear in the provided text or abstract. Claims reduce directly to the described code and usage rather than to any self-referential inputs, self-citations, or ansatzes. This is a systems/software paper, not a theoretical derivation; the central claim (simple kernel interface hiding CUDA/MPI details) is an engineering assertion evaluated by implementation and examples, not by construction from its own outputs. No load-bearing steps match any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S. Abbott. GPUDirect, CUDA-Aware MPI, and CUDA IPC. Oak Ridge Leadership Facility, Summit Training Workshop, https://www.olcf.ornl.gov/wp-content/uploads/2018/ 12/summit_workshop_CUDA-Aware-MPI.pdf, 2018. 2
2018
-
[2]
Abram, P
G. Abram, P. Navrátil, P. Grossett, D. Rogers, and J. Ahrens. Galaxy: Asynchronous ray tracing for large high-fidelity visualization. InProceed- ings of the IEEE 8th Symposium on Large Data Analysis and Visualization, LDA V ’18, 2018. 1
2018
-
[3]
Available at https: //rocm.docs.amd.com/projects/HIP, Last accessed: 29 March 2026
Introduction to the HIP programming model, 2026. Available at https: //rocm.docs.amd.com/projects/HIP, Last accessed: 29 March 2026. 2
2026
-
[4]
Barnes and P
J. Barnes and P. Hut. A hierarchical O (N log N) force-calculation algo- rithm.Nature, 324(6096), 1986. 7
1986
-
[5]
Bickford, T
N. Bickford, T. Lorach, and C. Hebert. Hands-on class: Introduction to slang: The next generation shading language. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Labs, 2025. SIGGRAPH Labs ’25. 2
2025
-
[6]
Chalmers, E
A. Chalmers, E. Reinhard, and T. Davis.Practical Parallel Rendering. CRC Press, 2002. 1
2002
-
[7]
K. M. Chandy and L. Lamport. Distributed Snapshots: Determining Global States of Distributed Systems.ACM Transactions on Computing Systems, 3(1):63–75, Feb. 1985. doi: 10.1145/214451.214456 3
-
[8]
Childs et al
H. Childs et al. A Terminology for In Situ Visualization and Analysis Systems.The International Journal of High Performance Computing Applications, 34(6), 2020. 1
2020
-
[9]
J. Fong, M. Wrenninge, C. Kulla, and R. Habel. Production V olume Rendering: SIGGRAPH 2017 Course. InACM SIGGRAPH 2017 Courses, SIGGRAPH ’17, 2017. doi: 10.1145/3084873.3084907 5
-
[10]
J. Kim, S. Seo, J. Lee, J. Nah, G. Jo, and J. Lee. OpenCL as a unified programming model for heterogeneous CPU/GPU clusters.SIGPLAN Not., 47(8), 2012. 2
2012
-
[11]
J. Kraus. An Introduction to CUDA-Aware MPI. NVIDIA Technical Blog, https://developer.nvidia.com/blog/ introduction-cuda-aware-mpi/, 2013. 2
2013
-
[12]
CUDA Toolkit
NVIDIA Corporation . CUDA Toolkit. Available at https:// developer.nvidia.com/cuda-toolkit. 2
-
[13]
Molnar, M
S. Molnar, M. Cox, D. Ellsworth, and H. Fuchs. A sorting classification of parallel rendering.IEEE Computer Graphics and Applications, 14(4):23– 32, 1994. 1
1994
-
[14]
Moreland, W
K. Moreland, W. Kendall, T. Peterka, and J. Huang. An Image Composit- ing Solution at Scale. InProceedings of International Conference for High Performance Computing, Networking, Storage and Analysis, 2011. 1
2011
-
[15]
N. Morrical, A. Sahistan, U. Güdükbay, I. Wald, and V . Pascucci. Quick Clusters: A GPU-Parallel Partitioning for Efficient Path Tracing of Un- structured V olumetric Grids.IEEE Transactions on Visualization and Computer Graphics, 29(01), 2023. doi: 10.1109/TVCG.2022.3209418 5
-
[16]
P. A. Navratil.Memory-Efficient, Scalable Ray Tracing. PhD thesis, University of Texas, Austin, 2010. 1
2010
-
[17]
Available at https: //github.com/NVIDIA/cuBQL, Accessed: Feb 26, 2026
cuBQL - The CUDA BVH Build and Query Library. Available at https: //github.com/NVIDIA/cuBQL, Accessed: Feb 26, 2026. 7
2026
-
[18]
Available at https: //github.com/NVIDIA/owl, Accessed: Feb 26, 2026
OWL – A Productivity Library for OptiX, 2026. Available at https: //github.com/NVIDIA/owl, Accessed: Feb 26, 2026. 5
2026
-
[19]
H. Park, D. Fussell, and P. Navrátil. SpRay: speculative ray scheduling for large data visualization. InProceedings of IEEE 8th Symposium on Large Data Analysis and Visualization, LDA V 08, pp. 77–86, 2018. 1
2018
-
[20]
Reinhard.Scheduling and Data Management for Parallel Ray Tracing
E. Reinhard.Scheduling and Data Management for Parallel Ray Tracing. PhD thesis, University of East Anglia, 1995. 1
1995
-
[21]
A. Sahistan, S. Demirci, N. Morrical, S. Zellmann, A. Aman, I. Wald, and U. Güdükbay. Ray-traced Shell Traversal of Tetrahedral Meshes for Direct V olume Visualization. InProceedings of the IEEE Visualization Conference-Short Papers, VIS ’21, 2021. doi: 10.1109/VIS49827.2021. 9623298 5
-
[22]
Sahistan, S
A. Sahistan, S. Demirci, I. Wald, S. Zellmann, J. Barbosa, N. Morrical, and U. Güdükbay. Visualization of Large Non-Trivially Partitioned Un- structured Data with Native Distribution on High-Performance Computing Systems.IEEE Transactions on Visualization and Computer Graphics, 31(9):5000–5014, September 2025. 4, 5
2025
-
[23]
G. S. Settles.Schlieren and Shadowgraph Techniques: Visualizing Phe- nomena in Transparent Media. Springer-Verlag, 2001. 5
2001
-
[24]
Toepler.Beobachtungen nach einer neuen optischen Methode: e
A. Toepler.Beobachtungen nach einer neuen optischen Methode: e. Beitr. zur Experimental-Physik. Max Cohen & Son, Bonn, Germany, 1864. 5
-
[25]
Trott, L
C. Trott, L. Berger-Vergiat, D. Poliakoff, S. Rajamanickam, D. Lebrun- Grandie, J. Madsen, N. Al Awar, M. Gligoric, G. Shipman, and G. Womel- dorff. The Kokkos Ecosystem: Comprehensive Performance Portability for High Performance Computing.Computing in Science Engineering, 23(5), 2021. 2
2021
-
[26]
I. Wald, M. Jaros, and S. Zellmann. Data Parallel Multi-GPU Path Tracing using Ray Queue Cycling.Computer Graphics Forum, 42, 2023. 8
2023
-
[27]
Wald and S
I. Wald and S. G. Parker. Data Parallel Path Tracing with Object Hierar- chies.Proceedings of the ACM on Computer Graphics and Interactive Techniques, 5(3), 2022. (Proceedings of High Performance Graphics). 1, 4
2022
-
[28]
I. Wald, S. Zellmann, and N. Morrical. Data-Parallel V olume Path Tracing (with Ray Forwarding). Available at https://github.com/ingowald/ vopat, Accessed: 2026/03/16. 1, 4
2026
-
[29]
D. W. Walker and J. J. Dongarra. MPI: a standard message passing interface.Supercomputer, 12, 1996. 2
1996
-
[30]
L. A. Yates. Images constructed from computed flowfields.AIAA Journal, 31(10), October 1993. 5 9
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.