Towards Streaming Synchronized Spatial Audio Generation via Autoregressive Diffusion Transformer
Pith reviewed 2026-06-28 21:15 UTC · model grok-4.3
The pith
SwanSphere generates streaming spatial audio from panoramic videos and text using a causal autoregressive diffusion transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SwanSphere is a unified streaming framework for high-fidelity spatial audio generation from panoramic videos and text prompts, built on a causal autoregressive diffusion transformer architecture, enhanced by a Spatial Video-Audio Contrastive learning strategy and a multi-objective online direct preference optimization scheme, and supported by an automated spatial caption annotation pipeline, achieving superior performance in video-to-spatial and text-to-spatial generation tasks.
What carries the argument
The causal autoregressive diffusion transformer architecture that produces streaming output while preserving spatial fidelity, together with the SVAC contrastive alignment and multi-objective ODPO optimization that enforce domain matching and preference-driven refinement.
Load-bearing premise
The SVAC learning strategy and multi-objective ODPO scheme will produce strong spatial perception and robust multimodal synthesis.
What would settle it
A controlled experiment in which SwanSphere audio is rated no better than strong baselines on objective spatial localization accuracy or subjective synchronization scores when conditioned on the same panoramic video or text inputs.
Figures
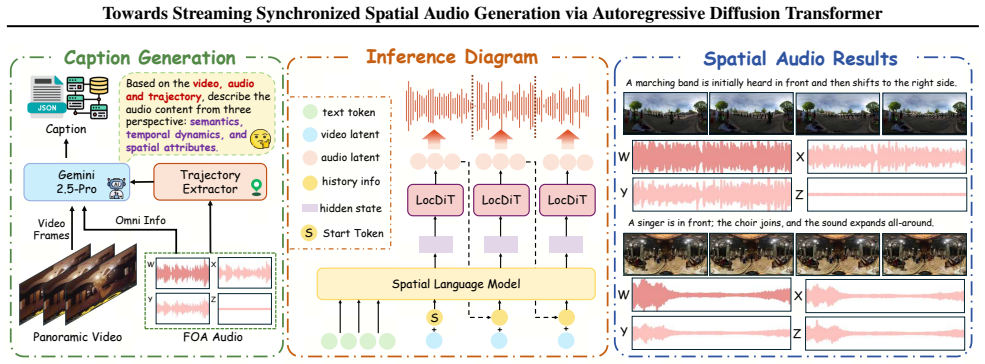
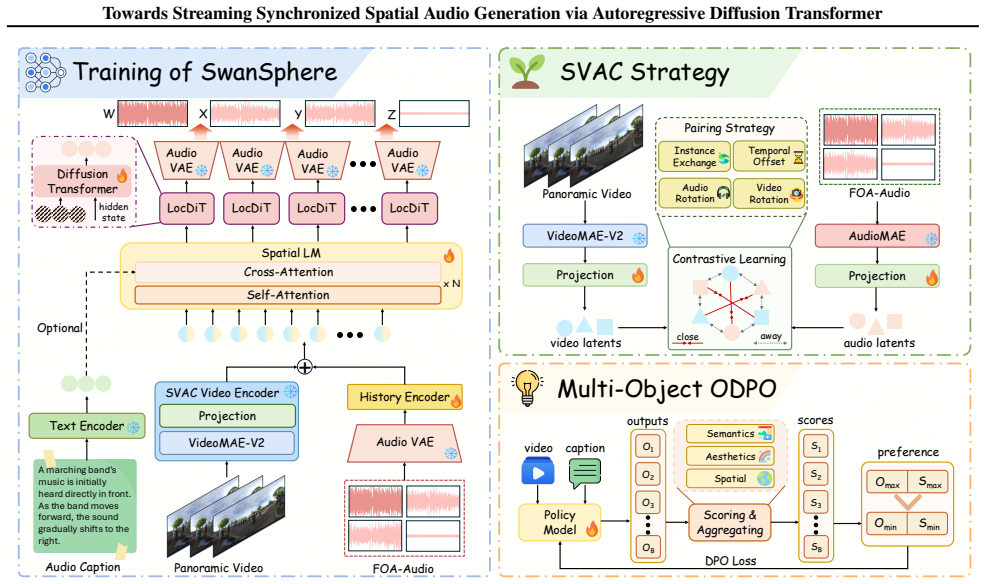
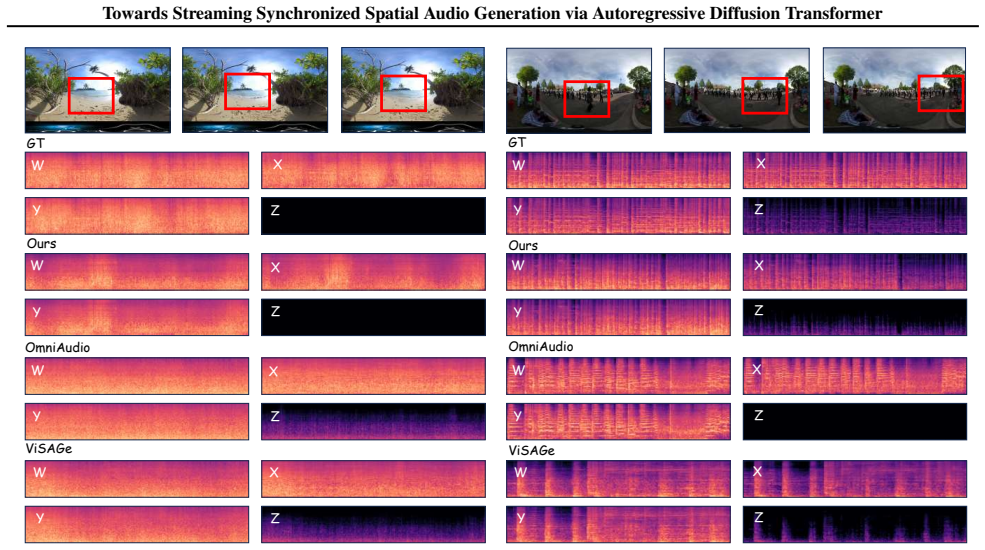
read the original abstract
Real-time and accurate spatial audio generation is pivotal for delivering an immersive experience. However, existing spatial audio synthesis technologies are often encumbered by a tradeoff between generation quality and high inference latency, as well as difficulty in capturing precise spatial information from multimodal inputs. To address these challenges, we propose SwanSphere, a unified streaming framework for high-fidelity spatial audio generation from panoramic videos and text prompts. SwanSphere mainly makes the following contributions: 1) We introduce a causal autoregressive diffusion transformer architecture that enables streaming high-quality spatial audio generation. 2) We design a Spatial Video-Audio Contrastive (SVAC) learning strategy to align the video encoder with the acoustic domain, and further employ a multi-objective online direct preference optimization (ODPO) scheme, resulting in strong spatial perception and robust multimodal spatial audio synthesis. 3) To alleviate the current scarcity of spatial audio datasets, we also develop an automated annotation pipeline for generating detailed spatial captions. Experimental results demonstrate that SwanSphere achieves superior performance in both video-to-spatial and text-to-spatial audio generation tasks. Demos can be found at: https://swanaigc.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SwanSphere, a unified streaming framework for high-fidelity spatial audio generation from panoramic videos and text prompts. It introduces a causal autoregressive diffusion transformer architecture, a Spatial Video-Audio Contrastive (SVAC) learning strategy to align video and acoustic domains, a multi-objective online direct preference optimization (ODPO) scheme, and an automated pipeline for generating spatial captions. The central claim is that these components enable superior performance on video-to-spatial and text-to-spatial audio generation tasks.
Significance. If the superiority claims are substantiated with rigorous experiments, the work could meaningfully advance real-time immersive audio synthesis by addressing latency-quality tradeoffs and multimodal alignment. The introduction of SVAC and ODPO for spatial perception, along with the captioning pipeline to address data scarcity, would represent practical contributions to the field if supported by evidence.
major comments (1)
- Abstract: The statement that 'Experimental results demonstrate that SwanSphere achieves superior performance in both video-to-spatial and text-to-spatial audio generation tasks' is presented without any accompanying metrics, baselines, ablation studies, error bars, test-set descriptions, or spatial-specific evaluation criteria (such as angular error or binaural quality scores). This absence leaves the central empirical claim without visible grounding.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [—] Abstract: The statement that 'Experimental results demonstrate that SwanSphere achieves superior performance in both video-to-spatial and text-to-spatial audio generation tasks' is presented without any accompanying metrics, baselines, ablation studies, error bars, test-set descriptions, or spatial-specific evaluation criteria (such as angular error or binaural quality scores). This absence leaves the central empirical claim without visible grounding.
Authors: We agree that the abstract claim would be stronger with explicit grounding. The full manuscript details the experimental setup, metrics (including angular error and binaural quality scores), baselines, ablations, error bars, and test-set descriptions in the Experiments section. To address the concern, we will revise the abstract to incorporate key quantitative results supporting the superiority claim. revision: yes
Circularity Check
No circularity: paper describes architecture and asserts empirical results without any derivation chain or self-referential predictions
full rationale
The manuscript introduces SwanSphere via high-level component descriptions (causal autoregressive diffusion transformer, SVAC alignment, multi-objective ODPO) and states that experimental results show superiority on video-to-spatial and text-to-spatial tasks. No equations, fitted parameters renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes smuggled via prior work appear in the supplied text. The performance claim is presented as an empirical outcome rather than a derived quantity that reduces to its own inputs by construction; therefore the derivation chain (such as it exists) is self-contained and independent of the circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
MusicLM: Generating Music From Text
Agostinelli, A., Denk, T. I., Borsos, Z., Engel, J., Verzetti, M., Caillon, A., Huang, Q., Jansen, A., Roberts, A., Tagliasacchi, M., et al. Musiclm: Generating music from text. arXiv preprint arXiv:2301.11325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Spatial sound—history, principle, progress and challenge
Bosun, X. Spatial sound—history, principle, progress and challenge. Chinese Journal of Electronics, 29 0 (3): 0 397--416, 2020. doi:10.1049/cje.2020.02.016. URL https://cje.ejournal.org.cn/en/article/doi/10.1049/cje.2020.02.016
-
[4]
Ccstereo: Audio-visual contextual and contrastive learning for binaural audio generation
Chen, Y., Shimada, K., Simon, C., Ikemiya, Y., Shibuya, T., and Mitsufuji, Y. Ccstereo: Audio-visual contextual and contrastive learning for binaural audio generation. In Proceedings of the 33rd ACM International Conference on Multimedia, pp.\ 7510--7518, 2025
2025
-
[5]
K., Ishii, M., Hayakawa, A., Shibuya, T., Schwing, A., and Mitsufuji, Y
Cheng, H. K., Ishii, M., Hayakawa, A., Shibuya, T., Schwing, A., and Mitsufuji, Y. Mmaudio: Taming multimodal joint training for high-quality video-to-audio synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pp.\ 28901--28911, 2025
2025
-
[6]
W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., et al
Chung, H. W., Hou, L., Longpre, S., Zoph, B., Tay, Y., Fedus, W., Li, Y., Wang, X., Dehghani, M., Brahma, S., et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25 0 (70): 0 1--53, 2024
2024
-
[7]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Veo 3, 2025
DeepMind, G. Veo 3, 2025. URL https://deepmind.google/technologies/veo
2025
-
[9]
Scaling rectified flow transformers for high-resolution image synthesis
Esser, P., Kulal, S., Blattmann, A., Entezari, R., M \"u ller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning, 2024
2024
-
[10]
D., Carr, C., Zukowski, Z., Taylor, J., and Pons, J
Evans, Z., Parker, J. D., Carr, C., Zukowski, Z., Taylor, J., and Pons, J. Stable audio open. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5. IEEE, 2025
2025
-
[11]
and Grauman, K
Gao, R. and Grauman, K. 2.5 d visual sound. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 324--333, 2019
2019
-
[12]
Geometry-aware multi-task learning for binaural audio generation from video
Garg, R., Gao, R., and Grauman, K. Geometry-aware multi-task learning for binaural audio generation from video. arXiv preprint arXiv:2111.10882, 2021
-
[13]
Mrsaudio: A large-scale multimodal recorded spatial audio dataset with refined annotations
Guo, W., Pan, C., Zhu, Z., Hu, X., Zhang, Y., Tang, L., Yang, R., Wang, H., Zhang, Z., Wang, Y., Chen, Y., Xu, H., Xu, K., Fan, P., Chen, Z., Yu, Y., Huang, Q., Wu, F., and Zhao, Z. Mrsaudio: A large-scale multimodal recorded spatial audio dataset with refined annotations. arXiv preprint arXiv:2510.10396, 2025 a
-
[14]
TechSinger : Technique controllable multilingual singing voice synthesis via flow matching
Guo, W., Zhang, Y., Pan, C., Huang, R., Tang, L., Li, R., Hong, Z., Wang, Y., and Zhao, Z. TechSinger : Technique controllable multilingual singing voice synthesis via flow matching. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pp.\ 23978--23986, 2025 b . doi:10.1609/aaai.v39i22.34571
-
[15]
STARS : A unified framework for singing transcription, alignment, and refined style annotation
Guo, W., Zhang, Y., Pan, C., Zhu, Z., Li, R., Chen, Z., Xu, W., Wu, F., and Zhao, Z. STARS : A unified framework for singing transcription, alignment, and refined style annotation. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 15081--15093, Vienna, Austria, 2025 c . Association for Computational Linguistics. doi:10.18653/v1/...
-
[16]
Immersediffusion: A generative spatial audio latent diffusion model
Heydari, M., Souden, M., Conejo, B., and Atkins, J. Immersediffusion: A generative spatial audio latent diffusion model. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5. IEEE, 2025
2025
-
[17]
D., and Yang, J
Hu, J., Cao, Y., Wu, M., Kang, F., Yang, F., Wang, W., Plumbley, M. D., and Yang, J. Pseldnets: Pre-trained neural networks on a large-scale synthetic dataset for sound event localization and detection. IEEE Transactions on Audio, Speech and Language Processing, 2025
2025
-
[18]
Impact: Iterative mask-based parallel decoding for text-to-audio generation with diffusion modeling
Huang, K.-P., Yang, S.-w., Phan, H., Lu, B.-R., Kim, B., Macha, S., Tang, Q., Ghosh, S., Lee, H.-y., Kao, C.-C., et al. Impact: Iterative mask-based parallel decoding for text-to-audio generation with diffusion modeling. arXiv preprint arXiv:2506.00736, 2025
-
[19]
Masked autoencoders that listen
Huang, P.-Y., Xu, H., Li, J., Baevski, A., Auli, M., Galuba, W., Metze, F., and Feichtenhofer, C. Masked autoencoders that listen. Advances in Neural Information Processing Systems, 35: 0 28708--28720, 2022
2022
-
[20]
Iashin, V. and Rahtu, E. Taming visually guided sound generation. arXiv preprint arXiv:2110.08791, 2021
-
[21]
Wavtokenizer: An efficient acoustic discrete codec tokenizer for audio language modeling
Ji, S., Jiang, Z., Wang, W., Chen, Y., Fang, M., Zuo, J., Yang, Q., Cheng, X., Wang, Z., Li, R., et al. Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling. arXiv preprint arXiv:2408.16532, 2024
-
[22]
Stereofoley: Object-aware stereo audio generation from video
Karchkhadze, T., Chen, K.-L., Heydari, M., Henzel, R., Toso, A., Souden, M., and Atkins, J. Stereofoley: Object-aware stereo audio generation from video. In ICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 16027--16031. IEEE, 2026
2026
-
[23]
Visage: Video-to-spatial audio generation
Kim, J., Yun, H., and Kim, G. Visage: Video-to-spatial audio generation. arXiv preprint arXiv:2506.12199, 2025
-
[24]
Guiding audio editing with audio language model
Lan, Z., Hao, Y., and Zhao, M. Guiding audio editing with audio language model. arXiv preprint arXiv:2509.21625, 2025
-
[25]
Binauralgrad: A two-stage conditional diffusion probabilistic model for binaural audio synthesis
Leng, Y., Chen, Z., Guo, J., Liu, H., Chen, J., Tan, X., Mandic, D., He, L., Li, X., Qin, T., et al. Binauralgrad: A two-stage conditional diffusion probabilistic model for binaural audio synthesis. Advances in Neural Information Processing Systems, 35: 0 23689--23700, 2022
2022
-
[26]
Robust singing voice transcription serves synthesis
Li, R., Zhang, Y., Wang, Y., Hong, Z., Huang, R., and Zhao, Z. Robust singing voice transcription serves synthesis. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 9751--9766, Bangkok, Thailand, 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.acl-long.526. URL h...
-
[27]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R. T., Ben-Hamu, H., Nickel, M., and Le, M. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[28]
Liu, H., Yuan, Y., Liu, X., Mei, X., Kong, Q., Tian, Q., Wang, Y., Wang, W., Wang, Y., and Plumbley, M. D. Audioldm 2: Learning holistic audio generation with self-supervised pretraining. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 32: 0 2871--2883, 2024
2024
-
[29]
Liu, H., Luo, K., Wang, J., Wang, W., Chen, Q., Zhao, Z., and Xue, W. Thinksound: Chain-of-thought reasoning in multimodal large language models for audio generation and editing. arXiv preprint arXiv:2506.21448, 2025 a
-
[30]
Omniaudio: Generating spatial audio from 360-degree video
Liu, H., Luo, T., Luo, K., Jiang, Q., Sun, P., Wang, J., Huang, R., Chen, Q., Wang, W., Li, X., et al. Omniaudio: Generating spatial audio from 360-degree video. arXiv preprint arXiv:2504.14906, 2025 b
-
[31]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., and Liu, Q. Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models
Luo, S., Yan, C., Hu, C., and Zhao, H. Diff-foley: Synchronized video-to-audio synthesis with latent diffusion models. Advances in Neural Information Processing Systems, 36: 0 48855--48876, 2023
2023
-
[33]
Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization
Majumder, N., Hung, C.-Y., Ghosal, D., Hsu, W.-N., Mihalcea, R., and Poria, S. Tango 2: Aligning diffusion-based text-to-audio generations through direct preference optimization. In Proceedings of the 32nd ACM International Conference on Multimedia, pp.\ 564--572, 2024
2024
-
[34]
Foleygen: Visually-guided audio generation
Mei, X., Nagaraja, V., Le Lan, G., Ni, Z., Chang, E., Shi, Y., and Chandra, V. Foleygen: Visually-guided audio generation. In 2024 IEEE 34th International Workshop on Machine Learning for Signal Processing (MLSP), pp.\ 1--6, 2024
2024
-
[35]
Self-supervised generation of spatial audio for 360 video
Morgado, P., Vasconcelos, N., Langlois, T., and Wang, O. Self-supervised generation of spatial audio for 360 video. Advances in neural information processing systems, 31, 2018
2018
-
[36]
Sora 2: Video generation model, 2025
OpenAI. Sora 2: Video generation model, 2025. URL https://openai.com/sora
2025
-
[37]
Pan, C., Guo, W., Zhang, Y., Zhu, Z., Chen, Z., Wang, H., and Zhao, Z. A multimodal evaluation framework for spatial audio playback systems: From localization to listener preference. In Proceedings of the 33rd ACM International Conference on Multimedia, pp.\ 7006--7015, 2025. doi:10.1145/3746027.3755571
-
[38]
and Xie, S
Peebles, W. and Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision, pp.\ 4195--4205, 2023
2023
-
[39]
Movie Gen: A Cast of Media Foundation Models
Polyak, A., Zohar, A., Brown, A., Tjandra, A., Sinha, A., Lee, A., Vyas, A., Shi, B., Ma, C.-Y., Chuang, C.-Y., et al. Movie gen: A cast of media foundation models. arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pp.\ 8748--8763. PmLR, 2021
2021
-
[41]
High-resolution image synthesis with latent diffusion models
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 10684--10695, 2022
2022
-
[42]
Soundreactor: Frame-level online video-to-audio generation
Saito, K., Tanke, J., Simon, C., Ishii, M., Shimada, K., Novack, Z., Zhong, Z., Hayakawa, A., Shibuya, T., and Mitsufuji, Y. Soundreactor: Frame-level online video-to-audio generation. arXiv preprint arXiv:2510.02110, 2025
-
[43]
Sim \'e oni, O., Vo, H. V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khalidov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Both ears wide open: Towards language-driven spatial audio generation
Sun, P., Cheng, S., Li, X., Ye, Z., Liu, H., Zhang, H., Xue, W., and Guo, Y. Both ears wide open: Towards language-driven spatial audio generation. arXiv preprint arXiv:2410.10676, 2024
-
[45]
Codi-2: In-context interleaved and interactive any-to-any generation
Tang, Z., Yang, Z., Khademi, M., Liu, Y., Zhu, C., and Bansal, M. Codi-2: In-context interleaved and interactive any-to-any generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 27425--27434, 2024
2024
-
[46]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Temporally aligned audio for video with autoregression
Viertola, I., Iashin, V., and Rahtu, E. Temporally aligned audio for video with autoregression. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5. IEEE, 2025
2025
-
[48]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
Videomae v2: Scaling video masked autoencoders with dual masking
Wang, L., Huang, B., Zhao, Z., Tong, Z., He, Y., Wang, Y., Wang, Y., and Qiao, Y. Videomae v2: Scaling video masked autoencoders with dual masking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp.\ 14549--14560, 2023
2023
-
[50]
Wang, L., Wang, J., Qiang, C., Deng, F., Zhang, C., Zhang, D., and Gai, K. Audiogen-omni: A unified multimodal diffusion transformer for video-synchronized audio, speech, and song generation. arXiv preprint arXiv:2508.00733, 2025
-
[51]
Frieren: Efficient video-to-audio generation network with rectified flow matching
Wang, Y., Guo, W., Huang, R., Huang, J., Wang, Z., You, F., Li, R., and Zhao, Z. Frieren: Efficient video-to-audio generation network with rectified flow matching. Advances in Neural Information Processing Systems, 37: 0 128118--128138, 2024
2024
-
[52]
arXiv preprint arXiv:2407.07464 , year=
Xu, M., Li, C., Tu, X., Ren, Y., Chen, R., Gu, Y., Liang, W., and Yu, D. Video-to-audio generation with hidden alignment. arXiv preprint arXiv:2407.07464, 2024
-
[53]
Visually informed binaural audio generation without binaural audios
Xu, X., Zhou, H., Liu, Z., Dai, B., Wang, X., and Lin, D. Visually informed binaural audio generation without binaural audios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp.\ 15485--15494, 2021
2021
-
[54]
Ta-v2a: Textually assisted video-to-audio generation
You, Y., Wu, X., and Qu, T. Ta-v2a: Textually assisted video-to-audio generation. In ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp.\ 1--5, 2025
2025
-
[55]
StyleSinger : Style transfer for out-of-domain singing voice synthesis
Zhang, Y., Huang, R., Li, R., He, J., Xia, Y., Chen, F., Duan, X., Huai, B., and Zhao, Z. StyleSinger : Style transfer for out-of-domain singing voice synthesis. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 19597--19605, 2024 a . doi:10.1609/aaai.v38i17.29932
-
[56]
Tcsinger: Zero-shot singing voice synthesis with style transfer and multi-level style control,
Zhang, Y., Jiang, Z., Li, R., Pan, C., He, J., Huang, R., Wang, C., and Zhao, Z. TCS inger: Zero-shot singing voice synthesis with style transfer and multi-level style control. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pp.\ 1960--1975, Miami, Florida, USA, 2024 b . Association for Computational Linguistics....
-
[57]
GTS inger: A global multi-technique singing corpus with realistic music scores for all singing tasks
Zhang, Y., Pan, C., Guo, W., Li, R., Zhu, Z., Wang, J., Xu, W., Lu, J., Hong, Z., Wang, C., Zhang, L., He, J., Jiang, Z., Chen, Y., Yang, C., Zhou, J., Cheng, X., and Zhao, Z. GTS inger: A global multi-technique singing corpus with realistic music scores for all singing tasks. In Advances in Neural Information Processing Systems, volume 37, 2024 c
2024
-
[58]
TCS inger 2: Customizable multilingual zero-shot singing voice synthesis
Zhang, Y., Guo, W., Pan, C., Yao, D., Zhu, Z., Jiang, Z., Wang, Y., Jin, T., and Zhao, Z. TCS inger 2: Customizable multilingual zero-shot singing voice synthesis. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 13280--13294, Vienna, Austria, 2025 a . Association for Computational Linguistics. doi:10.18653/v1/2025.findings-acl...
-
[59]
Isdrama: Immersive spatial drama generation through multimodal prompting
Zhang, Y., Guo, W., Pan, C., Zhu, Z., Jin, T., and Zhao, Z. Isdrama: Immersive spatial drama generation through multimodal prompting. In Proceedings of the 33rd ACM International Conference on Multimedia, pp.\ 9618--9627, 2025 b
2025
-
[60]
Versatile framework for song generation with prompt-based control
Zhang, Y., Guo, W., Pan, C., Zhu, Z., Li, R., Lu, J., Huang, R., Zhang, R., Hong, Z., Jiang, Z., and Zhao, Z. Versatile framework for song generation with prompt-based control. In Findings of the Association for Computational Linguistics: EMNLP 2025, pp.\ 195--219, Suzhou, China, 2025 c . Association for Computational Linguistics. doi:10.18653/v1/2025.fin...
-
[61]
Conan: A chunkwise online network for zero-shot adaptive voice conversion
Zhang, Y., Tian, B., and Duan, Z. Conan: A chunkwise online network for zero-shot adaptive voice conversion. arXiv preprint arXiv:2507.14534, 2025 d
-
[62]
Asaudio: A survey of advanced spatial audio research
Zhu, Z., Zhang, Y., Guo, W., Pan, C., and Zhao, Z. Asaudio: A survey of advanced spatial audio research. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics, pp.\ 417--442, 2025
2025
-
[63]
and Frank, M
Zotter, F. and Frank, M. Ambisonics: A practical 3D audio theory for recording, studio production, sound reinforcement, and virtual reality. Springer Nature, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.