GP-GOMEA with GPU-Based Fitness Evaluations: Design and Performance Analysis
Pith reviewed 2026-06-28 20:19 UTC · model grok-4.3
The pith
A GPU fitness evaluation scheme for GP-GOMEA increases evaluation throughput enough to regress large Feynman equations in four hours.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
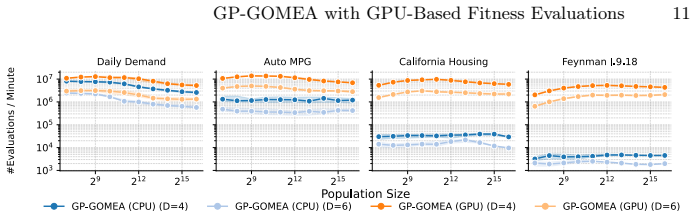
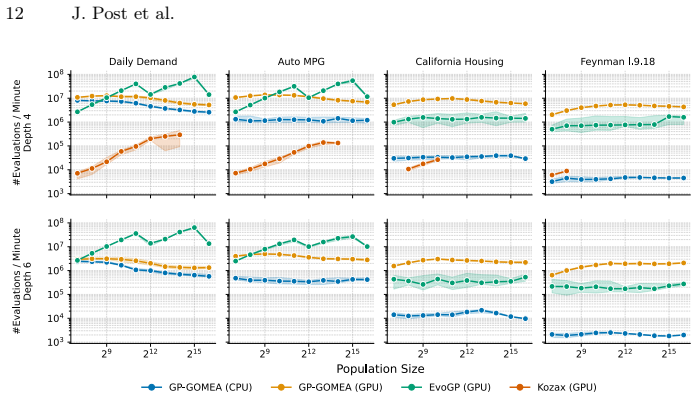
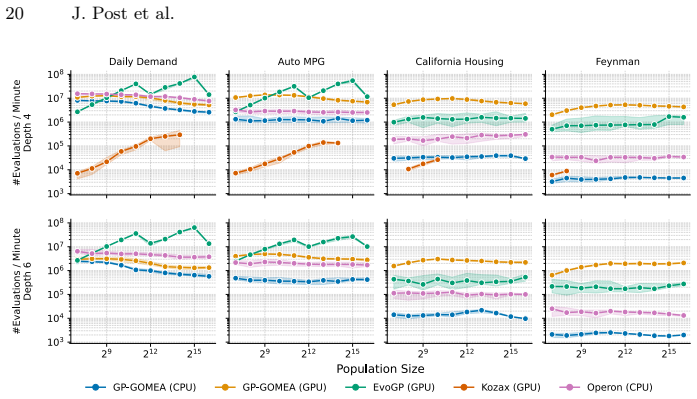
By introducing a GPU-based fitness evaluation scheme that exploits the inherent parallelism of population-based search, the work raises evaluation throughput for GP-GOMEA. The resulting capacity yields performance gains on benchmarks with larger datasets and populations, enables new analyses of how expression structure affects search difficulty, and allows a problem-agnostic evolutionary algorithm to regress one of the largest Feynman equations reliably inside four hours.
What carries the argument
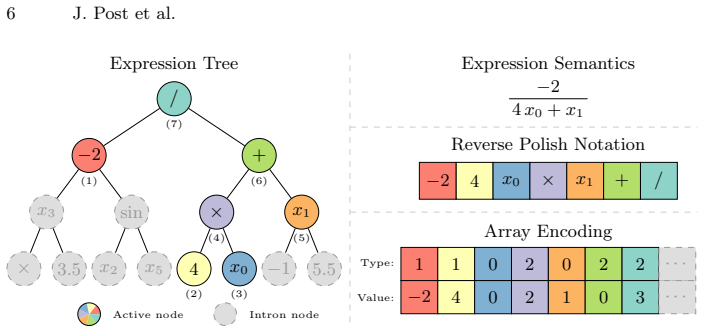
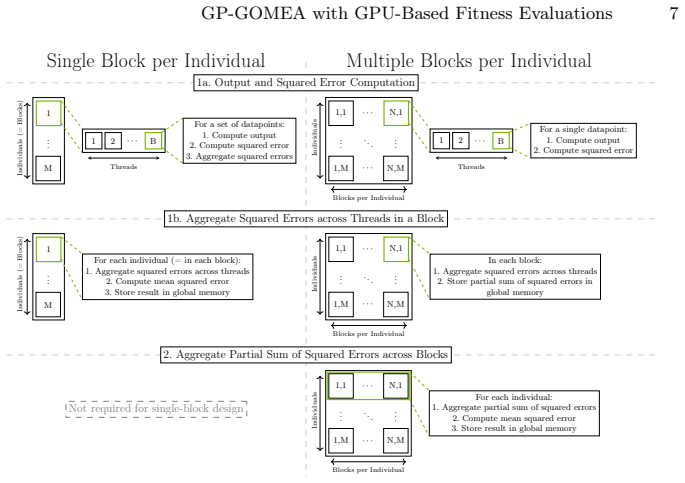
The GPU-based fitness evaluation scheme, which uses a template-based individual representation optimized for parallel GPU computation to replace CPU evaluations.
If this is right
- Performance improves on four standard symbolic regression benchmarks, with larger gains for bigger datasets and populations.
- Systematic study of which expression structures make search harder for GP-GOMEA becomes feasible.
- A problem-agnostic evolutionary algorithm can now reliably regress one of the largest Feynman equations in four hours.
Where Pith is reading between the lines
- The same GPU pattern could be applied to other template-based genetic programming methods to achieve comparable speed-ups.
- The ability to run far more evaluations may narrow the scalability gap between symbolic regression and deep-learning approaches.
- Insights from the new difficulty analyses could be used to design heuristics that prune hard expression structures early.
Load-bearing premise
The GPU implementation must compute fitness values that match the accuracy of the original CPU version while delivering the claimed higher throughput.
What would settle it
A side-by-side run of identical GP-GOMEA individuals on CPU and GPU that produces measurably different model errors or solution qualities on any benchmark would show the accuracy equivalence does not hold.
Figures

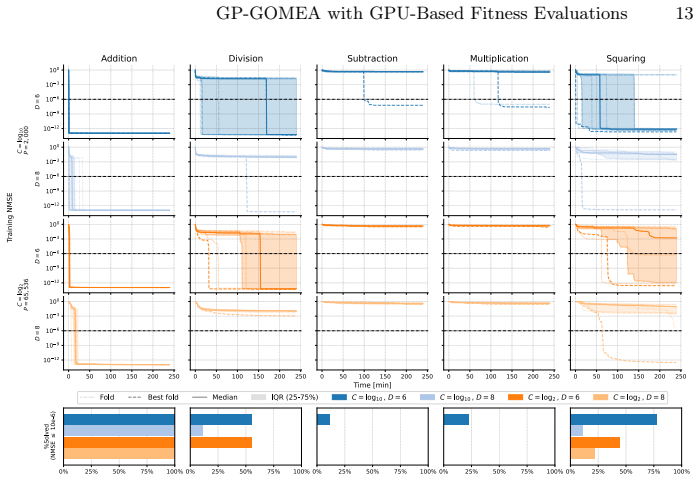
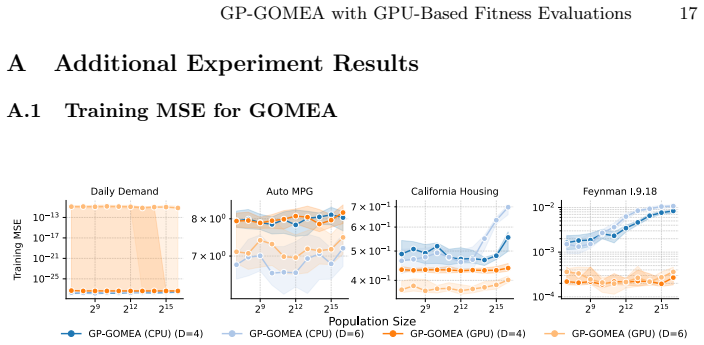
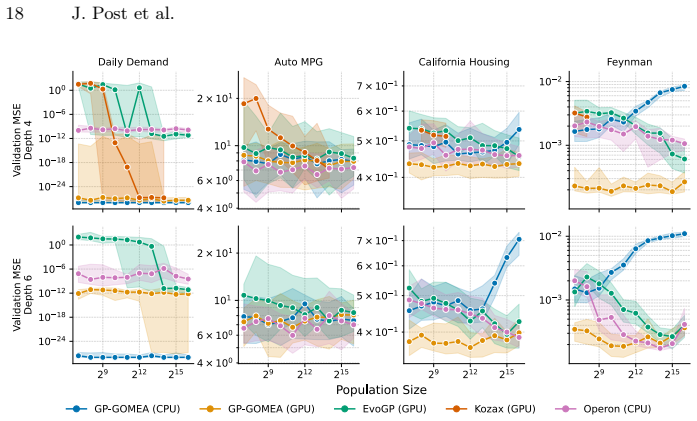
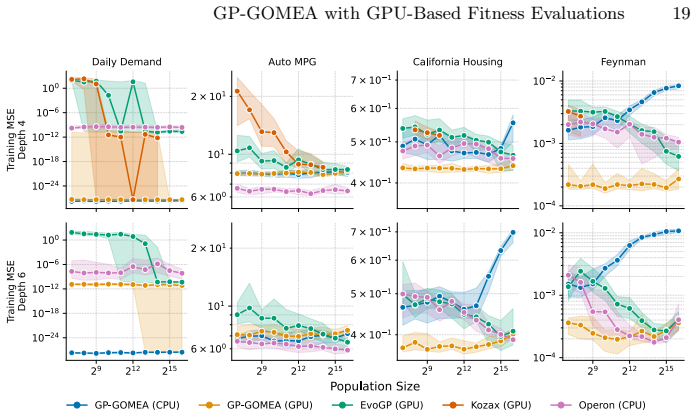
read the original abstract
GP-GOMEA is a state-of-the-art evolutionary algorithm for symbolic regression, known for discovering small and interpretable models. However, its computational cost remains substantial, limiting its applicability to larger datasets and more complex target expressions. In contrast, the rise of modern subsymbolic approaches, particularly deep learning, has been driven largely by the massive parallelism offered by GPUs. In this work, we take the first major step toward a fully GPU-accelerated GP-GOMEA by introducing a GPU-based fitness evaluation scheme. We design a GPU-friendly representation of GP-GOMEA's template-based individuals and a corresponding evaluation strategy that exploits the inherent parallelism of population-based search. This substantially increases evaluation throughput, enabling orders of magnitude more evaluations within the same time budget. Across four standard symbolic regression benchmarks, this increased evaluation capacity yields performance improvements, particularly for larger datasets and larger population sizes. Moreover, the ability to efficiently evaluate much larger datasets and more complex templates enables analyses that were previously infeasible, allowing us to systematically analyze what makes expressions increasingly difficult for GP-GOMEA, providing new insights into how expression structure affects search difficulty. Finally, for the first time, this expanded capability allows a problem-agnostic evolutionary algorithm to reliably regress one of the largest Feynman equations within four hours.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a GPU-friendly representation and evaluation strategy for template-based individuals in GP-GOMEA to accelerate fitness evaluations via parallelism. It reports substantially higher throughput enabling more evaluations within fixed time budgets, yielding performance gains on four symbolic regression benchmarks (especially larger datasets and populations), new analyses of how expression structure affects search difficulty, and the first reliable regression of one of the largest Feynman equations by a problem-agnostic EA within four hours.
Significance. If the GPU scheme produces numerically identical fitness values to the CPU version (preserving evolutionary dynamics), the work meaningfully extends GP-GOMEA's reach to larger-scale problems and provides new empirical insights into search difficulty; the Feynman result would be a notable demonstration of scalability for evolutionary symbolic regression.
major comments (3)
- [Abstract and experimental results] Abstract and experimental results section: The central claim that GPU evaluations enable the Feynman regression 'for the first time' within four hours rests on the unverified assumption that the new scheme yields identical fitness values (and thus identical selection dynamics) to the original CPU implementation. No explicit numerical verification—e.g., side-by-side fitness comparisons or model-quality metrics on identical individuals—is reported, despite the risk that changes in floating-point associativity, reduction order, or constant handling could alter outcomes.
- [Benchmark results] Benchmark results (likely §4): Performance improvements are stated without error bars, multiple independent runs with statistical tests, or direct baseline comparisons to the original CPU GP-GOMEA under identical time budgets; this makes it impossible to quantify whether gains are due to throughput alone or to any unintended changes in search behavior.
- [Methods/design] Methods/design section: The GPU representation and evaluation strategy for template-based individuals is described at a high level, but no pseudocode, kernel details, or handling of subtree reductions/precision is provided to allow assessment of numerical equivalence.
minor comments (2)
- [Design section] Notation for template-based individuals and GPU data structures could be clarified with a small diagram or explicit mapping to the original CPU representation.
- [Experimental setup] The four standard benchmarks should be named explicitly with dataset sizes and target expressions in the main text (not only supplementary).
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract and experimental results] Abstract and experimental results section: The central claim that GPU evaluations enable the Feynman regression 'for the first time' within four hours rests on the unverified assumption that the new scheme yields identical fitness values (and thus identical selection dynamics) to the original CPU implementation. No explicit numerical verification—e.g., side-by-side fitness comparisons or model-quality metrics on identical individuals—is reported, despite the risk that changes in floating-point associativity, reduction order, or constant handling could alter outcomes.
Authors: We agree that explicit verification of numerical equivalence is necessary to substantiate the claim that the GPU scheme preserves evolutionary dynamics and to support the 'for the first time' statement. Although the GPU representation and evaluation strategy were designed to maintain identical semantics and reduction order where possible, the submitted manuscript does not include side-by-side fitness or model-quality comparisons. In the revision we will add such verification experiments on identical individuals across both implementations. revision: yes
-
Referee: [Benchmark results] Benchmark results (likely §4): Performance improvements are stated without error bars, multiple independent runs with statistical tests, or direct baseline comparisons to the original CPU GP-GOMEA under identical time budgets; this makes it impossible to quantify whether gains are due to throughput alone or to any unintended changes in search behavior.
Authors: We accept that the results presentation would be strengthened by error bars, explicit reporting of the number of independent runs, statistical tests, and direct CPU baselines under matched time budgets. The experiments underlying the reported improvements were performed with multiple runs, yet these details and comparisons were not fully documented. We will revise the experimental results section to include error bars, run counts, statistical analysis, and side-by-side CPU comparisons. revision: yes
-
Referee: [Methods/design] Methods/design section: The GPU representation and evaluation strategy for template-based individuals is described at a high level, but no pseudocode, kernel details, or handling of subtree reductions/precision is provided to allow assessment of numerical equivalence.
Authors: We acknowledge that additional low-level details would facilitate independent assessment of numerical equivalence. The current description focuses on the high-level design choices that enable GPU parallelism. In the revised manuscript we will expand the methods section with pseudocode for the core evaluation kernels, explicit handling of subtree reductions, and discussion of floating-point precision and associativity choices. revision: yes
Circularity Check
No circularity: empirical implementation paper with externally verifiable benchmarks
full rationale
The paper describes a GPU implementation of fitness evaluation for the existing GP-GOMEA algorithm and reports empirical throughput and performance gains on symbolic regression benchmarks, including one Feynman equation. No mathematical derivations, parameter fits, or predictions appear. Claims rest on direct runtime measurements and solution quality comparisons that can be reproduced independently. No self-citations are load-bearing for any core result, and no steps reduce by construction to inputs. The equivalence assumption for GPU vs CPU is an implementation detail subject to external verification rather than a circular definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Baeta, F., Correia, J., Martins, T., Machado, P.: TensorGP - Genetic Programming EngineinTensorflow.In:Castillo,P.A.,JiménezLaredo,J.L.(eds.)Applicationsof Evolutionary Computation. pp. 763–778. Springer International Publishing, Cham (2021)
2021
-
[2]
https://doi.org/10.48550/ARXIV.2503.19043, https://arxiv.org/abs/2503.19043
Bruneton, J.P.: Enhancing symbolic regression with quality-diversity and physics-inspired constraints (2025). https://doi.org/10.48550/ARXIV.2503.19043, https://arxiv.org/abs/2503.19043
-
[3]
In: Proceed- ings of the 2020 Genetic and Evolutionary Computation Conference Com- panion
Burlacu, B., Kronberger, G., Kommenda, M.: Operon C++: an Efficient Genetic Programming Framework for Symbolic Regression. In: Proceed- ings of the 2020 Genetic and Evolutionary Computation Conference Com- panion. p. 1562–1570. GECCO ’20, Association for Computing Machin- ery, New York, NY, USA (2020). https://doi.org/10.1145/3377929.3398099, https://doi....
- [4]
-
[5]
Cranmer, M.: Interpretable Machine Learning for Science with PySR and Symbol- icRegression (2023), https://arxiv.org/abs/2305.01582
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Evolutionary computa- tion32(4), 371–397 (2024)
Dushatskiy, A., Virgolin, M., Bouter, A., Thierens, D., Bosman, P.A.: Parameter- less Gene-pool Optimal Mixing Evolutionary Algorithms. Evolutionary computa- tion32(4), 371–397 (2024)
2024
-
[7]
UCI Machine Learning Repository (2016), DOI: https://doi.org/10.24432/C5BC8T
Ferreira, R., Martiniano, A., Ferreira, A., Ferreira, A., Sassi, R.: Daily De- mand Forecasting Orders. UCI Machine Learning Repository (2016), DOI: https://doi.org/10.24432/C5BC8T
-
[8]
The Journal of Machine Learning Research13(1), 2171–2175 (2012)
Fortin, F.A., De Rainville, F.M., Gardner, M.A.G., Parizeau, M., Gagné, C.: DEAP: Evolutionary Algorithms Made Easy. The Journal of Machine Learning Research13(1), 2171–2175 (2012)
2012
- [9]
-
[10]
In: 2013 IEEE Congress on Evolutionary Computation
Janikow, C.Z., Aleshunas, J.: Impact of commutative and non-commutative func- tions on symbolic regression with acgp. In: 2013 IEEE Congress on Evolutionary Computation. pp. 2290–2297 (2013). https://doi.org/10.1109/CEC.2013.6557842
-
[11]
In: Affenzeller, M., Winkler, S.M., Kononova, A.V., Trautmann, H., Tušar, T., Machado, P., Bäck, T
Koch, J., Alderliesten, T., Bosman, P.A.N.: Simultaneous Model-Based Evolution of Constants and Expression Structure in GP-GOMEA for Symbolic Regression. In: Affenzeller, M., Winkler, S.M., Kononova, A.V., Trautmann, H., Tušar, T., Machado, P., Bäck, T. (eds.) Parallel Problem Solving from Nature – PPSN XVIII. pp. 238–255. Springer Nature Switzerland, Cham (2024)
2024
-
[12]
arXiv preprint arXiv:2602.02311 (2026)
Koch, J., Alderliesten, T., Bosman, P.A.: Introns and Templates Matter: Rethink- ing Linkage in GP-GOMEA. arXiv preprint arXiv:2602.02311 (2026)
-
[13]
(ed.) Late Breaking Papers at the Genetic Pro- gramming 1996 Conference Stanford University July 28-31, 1996
Maxwell, S.R.: Why Might Some Problems Be Difficult for Genetic Programming to Find Solutions? In: Koza, J.R. (ed.) Late Breaking Papers at the Genetic Pro- gramming 1996 Conference Stanford University July 28-31, 1996. pp. 125–128. Stanford Bookstore, Stanford University, CA, USA (28–31 Jul 1996)
1996
-
[14]
Meurer, A., Smith, C.P., Paprocki, M., Čertík, O., Kirpichev, S.B., Rocklin, M., Kumar, A., Ivanov, S., Moore, J.K., Singh, S., Rathnayake, T., Vig, S., Granger, B.E., Muller, R.P., Bonazzi, F., Gupta, H., Vats, S., Johansson, F., Pedregosa, F., Curry, M.J., Terrel, A.R., Roučka, v., Saboo, A., Fernando, I., Kulal, S., Cimrman, R., Scopatz, A.: SymPy: sym...
-
[15]
Journal of Machine Learning Research12, 2825–2830 (2011)
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., Duchesnay, E.: Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research12, 2825–2830 (2011)
2011
-
[16]
UCI Machine Learning Repository (1993), DOI: https://doi.org/10.24432/C5859H
Quinlan, R.: Auto MPG. UCI Machine Learning Repository (1993), DOI: https://doi.org/10.24432/C5859H
-
[17]
arXiv preprint arXiv:2012.00058v2 (2021)
Romano, J.D., Le, T.T., La Cava, W., Gregg, J.T., Goldberg, D.J., Chakraborty, P., Ray, N.L., Himmelstein, D., Fu, W., Moore, J.H.: PMLB v1.0: an open source dataset collection for benchmarking machine learning methods. arXiv preprint arXiv:2012.00058v2 (2021)
-
[18]
In: Pro- ceedings of the Genetic and Evolutionary Computation Conference
Schlender, T., Malafaia, M., Alderliesten, T., Bosman, P.: Improv- ing the efficiency of GP-GOMEA for higher-arity operators. In: Pro- ceedings of the Genetic and Evolutionary Computation Conference. p. 971–979. GECCO ’24, Association for Computing Machinery, New York, NY, USA (2024). https://doi.org/10.1145/3638529.3654118, https://doi.org/10.1145/363852...
-
[19]
Shojaee, P., Meidani, K., Gupta, S., Farimani, A.B., Reddy, C.K.: Llm-sr: Sci- entific equation discovery via programming with large language models (2024). https://doi.org/10.48550/ARXIV.2404.18400, https://arxiv.org/abs/2404.18400
-
[20]
URL https://github
Stephens, T.: gplearn: Genetic programming in Python, with a scikit-learn inspired API. URL https://github. com/trevorstephens/gplearn. Accessed pp. 05–22 (2024)
2024
-
[21]
Science Advances 6(16), eaay2631 (2020)
Udrescu, S.M., Tegmark, M.: AI Feynman: A physics- inspired method for symbolic regression. Science Advances 6(16), eaay2631 (2020). https://doi.org/10.1126/sciadv.aay2631, https://www.science.org/doi/abs/10.1126/sciadv.aay2631
-
[22]
In: Proceedings of the Genetic and Evolutionary Com- putation Conference
Virgolin, M., Alderliesten, T., Witteveen, C., Bosman, P.A.N.: Scalable Genetic Programming by Gene-Pool Optimal Mixing and Input-Space Entropy-Based Building-Block Learning. In: Proceedings of the Genetic and Evolutionary Com- putation Conference. p. 1041–1048. GECCO ’17, Association for Computing Ma- chinery, New York, NY, USA (2017). https://doi.org/10...
-
[23]
In: Proceedings of the Genetic and Evolutionary Computation Conference Companion
de Vries, S., Keemink, S.W., van Gerven, M.A.J.: Kozax: Flexible and Scalable Genetic Programming in JAX. In: Proceedings of the Genetic and Evolutionary Computation Conference Companion. p. 603–606. GECCO ’25 Companion, Association for Computing Machin- ery, New York, NY, USA (2025). https://doi.org/10.1145/3712255.3726681, https://doi.org/10.1145/371225...
- [24]
-
[25]
Zhang, R., Lensen, A., Sun, Y.: Speeding up Genetic Programming Based Sym- bolic Regression using GPUs. In: PRICAI 2022: Trends in Artificial Intelligence: 19th Pacific Rim International Conference on Artificial Intelligence, PRICAI 2022, Shanghai, China, November 10–13, 2022, Proceedings, Part I. p. 519–533. Springer- Verlag, Berlin, Heidelberg (2022). h...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.