AIM: A practical approach to automated index management for SQL databases
Pith reviewed 2026-06-28 19:52 UTC · model grok-4.3
The pith
AIM automatically recommends secondary indexes for SQL databases that adapt to workload changes with a no-regression guarantee.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
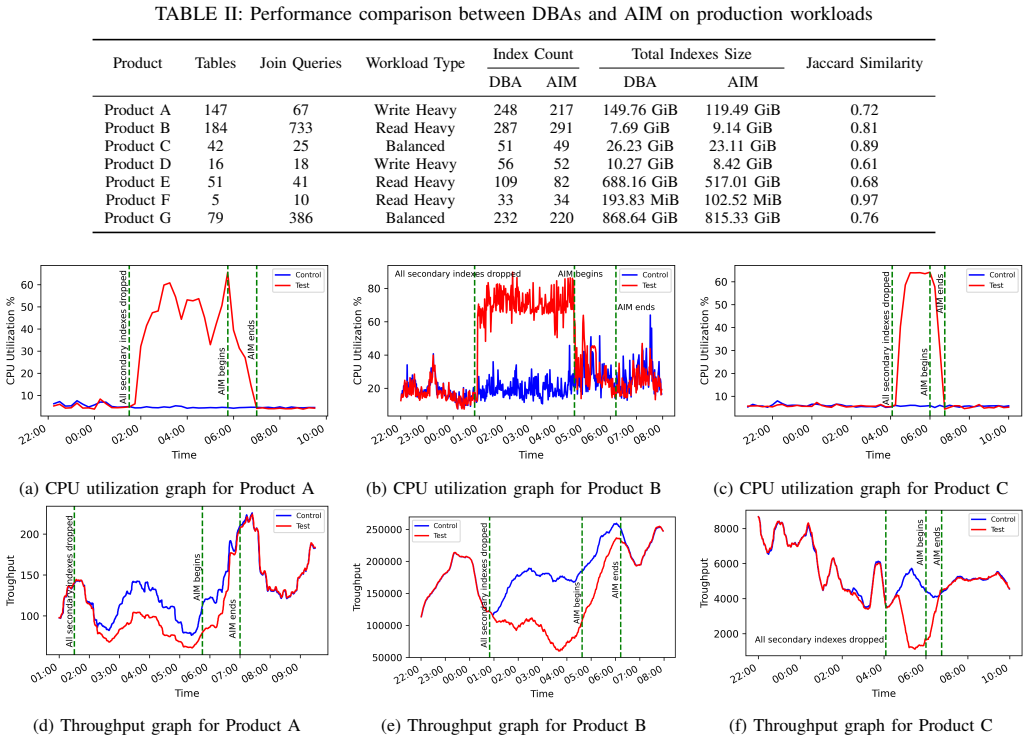
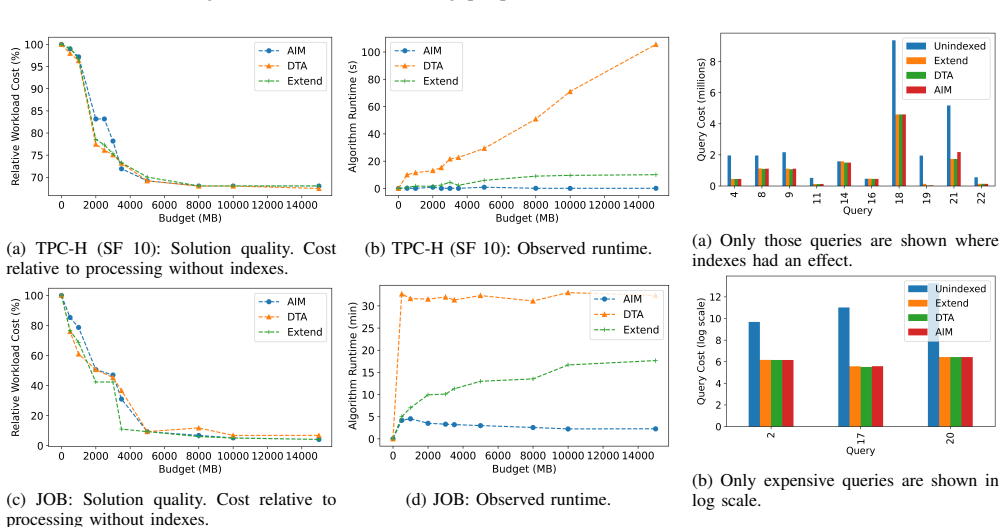
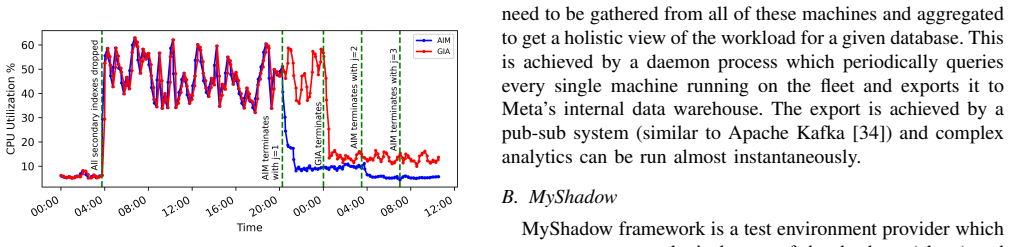
AIM is an industrial-strength index recommendation engine deployed at large scale that identifies impactful secondary indexes, converges quickly even on wide indexes, reduces optimizer reliance, and provides a no-regression guarantee, with the resulting physical design close to optimal on thousands of production databases.
What carries the argument
The AIM system, which combines workload monitoring with design choices for fast convergence on composite indexes and metrics-driven explanations for each recommendation.
If this is right
- Database physical design adapts automatically to workload changes.
- Index recommendations include metrics-driven explanations for easier verification.
- The system scales to thousands of production databases.
- Resulting designs are close to optimal while avoiding regressions.
Where Pith is reading between the lines
- Manual index tuning by administrators could become less necessary if the system maintains its guarantees across diverse workloads.
- The approach of pairing recommendations with explanations might extend to other automated database tuning tasks.
- Large-scale validation suggests the system handles variability in real environments, though edge cases in query patterns could still require monitoring.
Load-bearing premise
That the described design choices can deliver fast convergence, reduced optimizer reliance, and no hidden regressions on real production workloads without extensive manual oversight.
What would settle it
A production workload where AIM-recommended indexes produce a measurable performance regression on at least one key query despite the no-regression claim.
Figures


read the original abstract
This paper describes AIM (Automatic Index Manager), a configurable index management system, which identifies impactful secondary indexes for SQL databases to efficiently use available resources such as CPU, I/O and storage. It has been validated on thousands of databases which support production systems. With AIM, the physical design of the database adapts itself to the changes in the workload.We lay out the end to end design of AIM while calling out the guarantees and tradeoffs associated with our design choices. Some of the salient features of AIM include fast convergence even while recommending wide composite indexes, reduced reliance on the query optimizer and a "no regression" guarantee for production workloads. Each index recommendation from AIM is accompanied with a metrics driven explanation, making it easier to verify machine driven changes.AIM is one of the few industrial strength index recommendation engines that is deployed on production databases at a large scale. The experimental results show that AIM is quick in identifying the most effective indexes and the resulting physical design is close to optimal.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents AIM (Automatic Index Manager), a configurable system for identifying impactful secondary indexes in SQL databases to optimize CPU, I/O, and storage usage. It claims validation on thousands of production databases, with the physical design adapting to workload changes. Key features include fast convergence on wide composite indexes, reduced reliance on the query optimizer, a no-regression guarantee, and metrics-driven explanations for each recommendation. The experimental results demonstrate that AIM quickly identifies effective indexes and achieves physical designs close to optimal.
Significance. If the claims hold, this is a significant contribution as it describes a deployed, industrial-strength automated index management system at large scale, which is uncommon. The explicit discussion of guarantees, trade-offs, and explainability makes it particularly useful for practitioners. The validation on real production workloads strengthens the practical impact.
minor comments (2)
- [Abstract] The abstract claims validation on thousands of databases and closeness to optimality without referencing the specific experimental setup or metrics; while the full paper provides this in the experimental section, a brief pointer would improve standalone readability.
- [Experimental Results] Ensure that all performance metrics in the experimental results include error bars or statistical significance tests to support the claims of near-optimality and quick identification.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of our work on AIM and the recommendation for minor revision. The report does not raise any specific major comments or concerns about the manuscript content, claims, or experiments.
Circularity Check
No significant circularity detected
full rationale
The manuscript is a systems paper describing an end-to-end index recommendation engine. It contains no equations, fitted parameters, predictions derived from subsets of data, or mathematical derivations. Claims rest on explicit design choices with stated trade-offs plus separate experimental metrics on production workloads. No self-citation chain, ansatz smuggling, or renaming of known results is load-bearing. The argument is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Database tuning advisor for Microsoft SQL Server 2005,
S. Agrawal, S. Chaudhuri, L. Kollar, A. Marathe, V . Narasayya, and M. Syamala, “Database tuning advisor for Microsoft SQL Server 2005,” inProceedings of the 2005 ACM SIGMOD International Conference on Management of Data, pp. 930–932, 2005
2005
-
[2]
An online approach to physical design tun- ing,
N. Bruno and S. Chaudhuri, “An online approach to physical design tun- ing,” in2007 IEEE 23rd International Conference on Data Engineering (ICDE), pp. 826–835, IEEE, 2007
2007
-
[3]
An Efficient Cost-Driven Index Selection Tool for Microsoft SQL Server,
S. Chaudhuri and V . R. Narasayya, “An Efficient Cost-Driven Index Selection Tool for Microsoft SQL Server,” inProceedings of the 23rd International Conference on Very Large Databases (VLDB), p. 146–155, 1997
1997
-
[4]
AutoAdmin “What-If
S. Chaudhuri and V . Narasayya, “AutoAdmin “What-If” Index Analysis Utility,” inProceedings of the 1998 ACM SIGMOD International Conference on Management of Data, p. 367–378, 1998
1998
-
[5]
Self-Tuning Database Systems: A Decade of Progress,
S. Chaudhuri and V . Narasayya, “Self-Tuning Database Systems: A Decade of Progress,” inProceedings of the 33rd International Con- ference on Very Large Databases (VLDB), pp. 3–14, 2007
2007
-
[6]
Automatic SQL tuning in Oracle 10g,
B. Dageville, D. Das, K. Dias, K. Yagoub, M. Zait, and M. Ziauddin, “Automatic SQL tuning in Oracle 10g,” inProceedings of the 30th International Conference on Very Large Databases (VLDB), pp. 1098– 1109, 2004
2004
-
[7]
Db2 advisor: An optimizer smart enough to recommend its own indexes,
G. Valentin, M. Zuliani, D. C. Zilio, G. Lohman, and A. Skelley, “Db2 advisor: An optimizer smart enough to recommend its own indexes,” in 2000 IEEE 16th International Conference on Data Engineering (ICDE), pp. 101–110, IEEE, 2000
2000
-
[8]
DB2 Design Advisor: Integrated Automatic Physical Database Design,
D. C. Zilio, J. Rao, S. Lightstone, G. Lohman, A. Storm, C. Garcia- Arellano, and S. Fadden, “DB2 Design Advisor: Integrated Automatic Physical Database Design,” inProceedings of the 30th International Conference on Very Large Databases (VLDB), pp. 1087–1097, 2004
2004
-
[9]
Index selection for databases: A hardness study and a principled heuristic solution,
S. Chaudhuri, M. Datar, and V . Narasayya, “Index selection for databases: A hardness study and a principled heuristic solution,”IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 16, no. 11, pp. 1313–1323, 2004
2004
-
[10]
How good are query optimizers, really?,
V . Leis, A. Gubichev, A. Mirchev, P. Boncz, A. Kemper, and T. Neu- mann, “How good are query optimizers, really?,”Proceedings of the VLDB Endowment, vol. 9, no. 3, pp. 204–215, 2015
2015
-
[11]
Efficient scalable multi- attribute index selection using recursive strategies,
R. Schlosser, J. Kossmann, and M. Boissier, “Efficient scalable multi- attribute index selection using recursive strategies,” in2019 IEEE 35th International Conference on Data Engineering (ICDE), pp. 1238–1249, IEEE, 2019
2019
-
[12]
Chaudhuri and V
S. Chaudhuri and V . Narasayya,Anytime Algorithm of Database Tuning Advisor for Microsoft SQL Server, October
-
[13]
https://www.microsoft.com/en-us/research/publication/ anytime-algorithm-of-database-tuning-advisor-for-microsoft-sql-server/
-
[14]
Magic mirror in my hand, which is the best in the land? an experimental evaluation of index selection algorithms,
J. Kossmann, S. Halfpap, M. Jankrift, and R. Schlosser, “Magic mirror in my hand, which is the best in the land? an experimental evaluation of index selection algorithms,”Proceedings of the VLDB Endowment, vol. 13, no. 12, pp. 2382–2395, 2020
2020
-
[15]
Efficient use of the query optimizer for automated physical design,
S. Papadomanolakis, D. Dash, and A. Ailamaki, “Efficient use of the query optimizer for automated physical design,” inProceedings of the 33rd International Conference on Very Large Databases (VLDB), pp. 1093–1104, 2007
2007
-
[16]
Partially ordered sets,
B. Dushnik and E. W. Miller, “Partially ordered sets,”American journal of mathematics, vol. 63, no. 3, pp. 600–610, 1941
1941
-
[17]
Ordinal sums and equational doctrines,
H. Appelgate, M. Barr, J. Beck, F. Lawvere, F. Linton, E. Manes, M. Tierney, F. Ulmer, and F. W. Lawvere, “Ordinal sums and equational doctrines,” inSeminar on Triples and Categorical Homology Theory: ETH 1966/67, pp. 141–155, Springer, 1969
1966
-
[18]
MySQL Reference Manual 8.0,Estimating Query Performance, January
-
[19]
https://dev.mysql.com/doc/refman/8.0/en/estimating-performance. html
-
[20]
Algorithms for knapsack problems,
S. Martello and P. Toth, “Algorithms for knapsack problems,”North- Holland Mathematics Studies, vol. 132, pp. 213–257, 1987
1987
-
[21]
Factorizing Complex Predicates in Queries to Exploit Indexes,
S. Chaudhuri, P. Ganesan, and S. Sarawagi, “Factorizing Complex Predicates in Queries to Exploit Indexes,” inProceedings of the 2003 ACM SIGMOD International Conference on Management of Data, pp. 361–372, 2003
2003
-
[22]
https://dev.mysql.com/doc/refman/8.0/en/ range-optimization.html#range-access-multi-part
MySQL Reference Manual 8.0,Range Access Method for Multiple- Part Indexes, October 2022. https://dev.mysql.com/doc/refman/8.0/en/ range-optimization.html#range-access-multi-part
2022
-
[23]
https://dev.mysql.com/doc/refman/8.0/en/ index-condition-pushdown-optimization.htm
MySQL Reference Manual 8.0,Index Condition Pushdown Op- timization, October 2022. https://dev.mysql.com/doc/refman/8.0/en/ index-condition-pushdown-optimization.htm
2022
-
[24]
https://dev
MySQL Reference Manual 8.0,Join Clause, October 2022. https://dev. mysql.com/doc/refman/8.0/en/join.html
2022
-
[25]
On the optimal nesting order for computing n-relational joins,
I. Toshihide and K. Tiko, “On the optimal nesting order for computing n-relational joins,”ACM Transactions on Database Systems (TODS), vol. 9, no. 3, pp. 482–502, 1984
1984
-
[26]
Analyzing Plan Diagrams of Database Query Optimizers,
N. Reddy and J. R. Haritsa, “Analyzing Plan Diagrams of Database Query Optimizers,” inProceedings of the 31st International Conference on Very Large Databases (VLDB), p. 1228–1239, 2005
2005
-
[27]
CoPhy: A Scalable, Portable, and Interactive Index Advisor for Large Workloads
D. Dash, N. Polyzotis, and A. Ailamaki, “Cophy: A scalable, portable, and interactive index advisor for large workloads,”arXiv preprint arXiv:1104.3214, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[28]
https://github
Dexter,The automatic indexer for Postgres, October 2022. https://github. com/ankane/dexter
2022
-
[29]
Index selection in relational databases,
K. Y . Whang, “Index selection in relational databases,”Foundations of Data Organization, pp. 487–500, 1987
1987
-
[30]
Automatic physical database tuning: A relaxation-based approach,
N. Bruno and S. Chaudhuri, “Automatic physical database tuning: A relaxation-based approach,” inProceedings of the 2005 ACM SIGMOD International Conference on Management of Data, pp. 227–238, 2005
2005
-
[31]
https: //github.com/HypoPG/hypopg
HypoPG,Hypothetical Indexes for PostgreSQL, October 2022. https: //github.com/HypoPG/hypopg
2022
-
[32]
https: //dev.mysql.com/doc/refman/8.0/en/innodb-limits.html
MySQL Reference Manual 8.0,InnoDB Limits, October 2022. https: //dev.mysql.com/doc/refman/8.0/en/innodb-limits.html
2022
-
[33]
AutoIndex: An Incremental Index Management System for Dynamic Workloads,
X. Zhou, L. Liu, W. Li, L. Jin, S. Li, T. Wang, and J. Feng, “AutoIndex: An Incremental Index Management System for Dynamic Workloads,” in 2022 IEEE 38th International Conference on Data Engineering (ICDE), pp. 2196–2208, IEEE, 2022
2022
-
[34]
On-line index selection for shifting workloads,
K. Schnaitter, S. Abiteboul, T. Milo, and N. Polyzotis, “On-line index selection for shifting workloads,” in2007 IEEE 23rd International Conference on Data Engineering Workshop (ICDEW), pp. 459–468, IEEE, 2007
2007
-
[35]
FlexiRaft: Flexible Quorums with Raft,
R. Yadav and A. Rahut, “FlexiRaft: Flexible Quorums with Raft,”The Conference on Innovative Data Systems Research (CIDR), 2023
2023
-
[36]
Apache Kafka: Next generation distributed messaging system,
K. M. M. Thein, “Apache Kafka: Next generation distributed messaging system,”International Journal of Scientific Engineering and Technology Research, vol. 3, no. 47, pp. 9478–9483, 2014
2014
-
[37]
Predicting query execution time: Are optimizer cost models really unusable?,
W. Wu, Y . Chi, S. Zhu, J. Tatemura, H. Hacig ¨um¨us, and J. F. Naughton, “Predicting query execution time: Are optimizer cost models really unusable?,” in2013 IEEE 29th International Conference on Data Engineering (ICDE), pp. 1081–1092, IEEE, 2013
2013
-
[38]
https://dev.mysql.com/doc/refman/8.0/en/range-optimization
MySQL Reference Manual 8.0,Skip Scan Range Access Method, Octo- ber 2022. https://dev.mysql.com/doc/refman/8.0/en/range-optimization. html#range-access-skip-scan
2022
-
[39]
https://dev.mysql.com/doc/refman/8.0/en/ index-merge-optimization.html
MySQL Reference Manual 8.0,Index Merge Optimization, October 2022. https://dev.mysql.com/doc/refman/8.0/en/ index-merge-optimization.html
2022
-
[40]
https: //bugs.mysql.com/bug.php?id=100253
MySQL Bug,Skip Scan retrieves incorrect Result, October 2022. https: //bugs.mysql.com/bug.php?id=100253
2022
-
[41]
https://bugs.mysql.com/bug.php? id=80390
MySQL Bug,Clustered primary key included in index merge may cause higher execution times, October 2022. https://bugs.mysql.com/bug.php? id=80390
2022
-
[42]
A quantitative approach to the selection of secondary indexes,
F. Palermo, “A quantitative approach to the selection of secondary indexes,”IBM Research, RJ, vol. 730, 1970
1970
-
[43]
Configuration-parametric query optimiza- tion for physical design tuning,
N. Bruno and R. V . Nehme, “Configuration-parametric query optimiza- tion for physical design tuning,” inProceedings of the 2008 ACM SIGMOD International Conference on Management of Data, pp. 941– 952, 2008
2008
-
[44]
Budget-aware Index Tuning with Reinforcement Learning,
W. Wu, C. Wang, T. Siddiqui, J. Wang, V . Narasayya, S. Chaudhuri, and P. A. Bernstein, “Budget-aware Index Tuning with Reinforcement Learning,” inProceedings of the 2022 ACM SIGMOD International Conference on Management of Data, pp. 1528–1541, 2022
2022
-
[45]
Automated physical designers: what you see is (not) what you get,
R. Borovica, I. Alagiannis, and A. Ailamaki, “Automated physical designers: what you see is (not) what you get,” inProceedings of the Fifth International Workshop on Testing Database Systems, pp. 1–6, 2012
2012
-
[46]
Automatically indexing millions of databases in Microsoft Azure SQL database,
S. Das, M. Grbic, I. Ilic, I. Jovandic, A. Jovanovic, V . R. Narasayya, M. Radulovic, M. Stikic, G. Xu, and S. Chaudhuri, “Automatically indexing millions of databases in Microsoft Azure SQL database,” in Proceedings of the 2019 ACM SIGMOD International Conference on Management of Data, pp. 666–679, 2019
2019
-
[47]
Exact and approximate al- gorithms for the index selection problem in physical database design,
A. Caprara, M. Fischetti, and D. Maio, “Exact and approximate al- gorithms for the index selection problem in physical database design,” IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 7, no. 6, pp. 955–967, 1995
1995
-
[48]
A branch-and-cut algorithm for a general- ization of the uncapacitated facility location problem,
A. Caprara and J. Gonz ´alez, “A branch-and-cut algorithm for a general- ization of the uncapacitated facility location problem,”Top, vol. 4, no. 1, pp. 135–163, 1996
1996
-
[49]
Regularized cost-model oblivious database tuning with reinforce- ment learning,
D. Basu, Q. Lin, W. Chen, H. T. V o, Z. Yuan, P. Senellart, and S. Bres- san, “Regularized cost-model oblivious database tuning with reinforce- ment learning,” inTransactions on Large-Scale Data-and Knowledge- Centered Systems XXVIII, pp. 96–132, Springer, 2016
2016
-
[50]
The Case for Automatic Database Administration using Deep Reinforcement Learning
A. Sharma, F. M. Schuhknecht, and J. Dittrich, “The case for auto- matic database administration using deep reinforcement learning,”arXiv preprint arXiv:1801.05643, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
Online index selection using deep reinforcement learning for a cluster database,
Z. Sadri, L. Gruenwald, and E. Leal, “Online index selection using deep reinforcement learning for a cluster database,” in2020 IEEE 36th International Conference on Data Engineering Workshops (ICDEW), pp. 158–161, IEEE, 2020
2020
-
[52]
DBA bandits: Self-driving index tuning under ad-hoc, analytical workloads with safety guarantees,
R. M. Perera, B. Oetomo, B. I. Rubinstein, and R. Borovica-Gajic, “DBA bandits: Self-driving index tuning under ad-hoc, analytical workloads with safety guarantees,” in2021 IEEE 37th International Conference on Data Engineering (ICDE), pp. 600–611, IEEE, 2021
2021
-
[53]
UDO: universal database optimiza- tion using reinforcement learning,
J. Wang, I. Trummer, and D. Basu, “UDO: universal database optimiza- tion using reinforcement learning,”arXiv preprint arXiv:2104.01744, 2021
-
[54]
AI meets AI: Leveraging query executions to improve index recom- mendations,
B. Ding, S. Das, R. Marcus, W. Wu, S. Chaudhuri, and V . R. Narasayya, “AI meets AI: Leveraging query executions to improve index recom- mendations,” inProceedings of the 2019 ACM SIGMOD International Conference on Management of Data, pp. 1241–1258, 2019
2019
-
[55]
Deep learning models for selectivity estimation of multi-attribute queries,
S. Hasan, S. Thirumuruganathan, J. Augustine, N. Koudas, and G. Das, “Deep learning models for selectivity estimation of multi-attribute queries,” inProceedings of the 2020 ACM SIGMOD International Conference on Management of Data, pp. 1035–1050, 2020
2020
-
[56]
Which Sort Orders Are Interesting?,
R. Guravannavar, S. Sudarshan, A. A. Diwan, and C. S. Babu, “Which Sort Orders Are Interesting?,”The VLDB Journal, vol. 21, no. 1, pp. 145––165, 2012
2012
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.