DUET: Unified Dual-Space Emotion Control for Diffusion and Flow-Matching Driven Text-to-Speech
Pith reviewed 2026-06-30 17:32 UTC · model grok-4.3
The pith
A plug-and-play framework steers pretrained diffusion and flow-matching TTS models along linearly decodable emotion directions in hidden and mel spaces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We discover that emotion embedding emerges as a linearly decodable direction of frozen hidden states, nearly orthogonal to the direction embedding speaker identity. This inspires DUET, a plug-and-play framework for emotion control over pretrained diffusion and flow-matching based TTS models. During generation, DUET unifies dual-space control to achieve fine-grained emotion intervention in a single per-step update: hidden space steering shifts generation along the target emotion direction, while mel-space guidance refines spectral details through gradients backpropagated from a differentiable vocoder. We validate DUET on five architecturally diverse pretrained TTS backbones across three datas
What carries the argument
Dual-space control that performs hidden-space steering along the linearly decodable emotion direction while applying mel-space guidance via gradients from a differentiable vocoder.
If this is right
- Pretrained diffusion and flow-matching TTS models can receive emotion control without retraining or architectural changes.
- Fine-grained emotion intervention occurs inside a single per-step update during inference.
- The method exceeds the performance of supervised emotional TTS systems trained specifically for the task.
- The same plug-and-play control extends to embodied platforms such as humanoid robots.
Where Pith is reading between the lines
- If comparable linear directions exist for other attributes such as prosody or accent, the same steering approach could add those controls without new training.
- Widespread adoption would lower the barrier to building expressive speech systems by removing the need for emotion-specific labeled datasets.
- Applying the orthogonality test to additional generative audio models outside TTS would clarify how general the linear-decodability property is.
Load-bearing premise
Emotion information forms a linearly decodable direction inside the frozen hidden states of pretrained TTS models and stays nearly orthogonal to speaker identity.
What would settle it
If steering along the extracted emotion direction produces no measurable rise in human-rated emotion appropriateness on the tested backbones, or if the extracted direction proves linearly entangled with speaker identity in the hidden states.
Figures

read the original abstract
Diffusion and flow-matching based text-to-speech (TTS) models excel in naturalness but often lack explicit emotion control, as emotional signals remain entangled with speaker identity. We discover that emotion embedding emerges as a linearly decodable direction of frozen hidden states, nearly orthogonal to the direction embedding speaker identity. This inspires a plug-and-play framework DUET for emotion control over pretrained diffusion and flow-matching based TTS models. During generation, DUET unifies dual-space control to achieve fine-grained emotion intervention in a single per-step update: hidden space steering shifts generation along the target emotion direction, while mel-space guidance refines spectral details through gradients backpropagated from a differentiable vocoder. We validate DUET on five architecturally diverse pretrained TTS backbones across three datasets, where it outperforms 10 supervised state-of-the-art emotional TTS baselines across paradigms and achieves the highest human-rated emotion appropriateness. To further showcase its qualitative behavior, we deploy DUET on an Ameca humanoid robot, where it produces richly expressive emotional speech on the humanoid, demonstrating the strong potential for plug-and-play affective interaction for embodied agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to discover that emotion embeddings emerge as linearly decodable directions in frozen hidden states of diffusion/flow-matching TTS models and are nearly orthogonal to speaker-identity directions; this discovery motivates the DUET plug-and-play framework that performs unified dual-space (hidden + mel) emotion control via a single per-step update, outperforming 10 supervised SOTA emotional TTS baselines on five architecturally diverse pretrained backbones across three datasets while achieving the highest human-rated emotion appropriateness, with an additional qualitative demonstration on an Ameca humanoid robot.
Significance. If the linear-decodability and near-orthogonality findings hold with the reported stability across timesteps and backbones, DUET would constitute a meaningful advance by enabling training-free, fine-grained emotion intervention on existing high-quality TTS models without retraining or architectural changes.
major comments (2)
- [Abstract] Abstract: the central premise that 'emotion embedding emerges as a linearly decodable direction of frozen hidden states, nearly orthogonal to the direction embedding speaker identity' is asserted without any supporting numerical evidence (cosine similarity, linear-probe accuracy, variance explained, or stability across diffusion/flow timesteps), which is load-bearing for the plug-and-play claim and the asserted advantage of the single per-step update.
- [Abstract] Abstract: the validation statement ('outperforms 10 supervised state-of-the-art emotional TTS baselines across paradigms and achieves the highest human-rated emotion appropriateness') supplies no methods, datasets, metrics, error bars, or statistical tests, preventing assessment of whether the outperformance claim is supported.
minor comments (1)
- The abstract lists 'five architecturally diverse pretrained TTS backbones across three datasets' but does not name the backbones or datasets, which would aid reproducibility assessment.
Simulated Author's Rebuttal
We thank the referee for these constructive comments on the abstract. Both points identify opportunities to make the abstract more self-contained while preserving its brevity. We address each below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central premise that 'emotion embedding emerges as a linearly decodable direction of frozen hidden states, nearly orthogonal to the direction embedding speaker identity' is asserted without any supporting numerical evidence (cosine similarity, linear-probe accuracy, variance explained, or stability across diffusion/flow timesteps), which is load-bearing for the plug-and-play claim and the asserted advantage of the single per-step update.
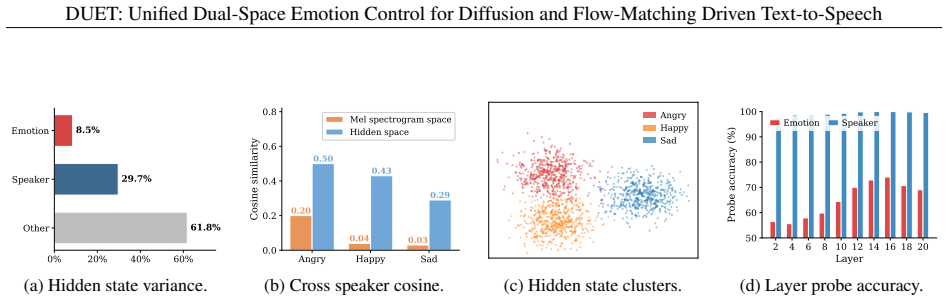
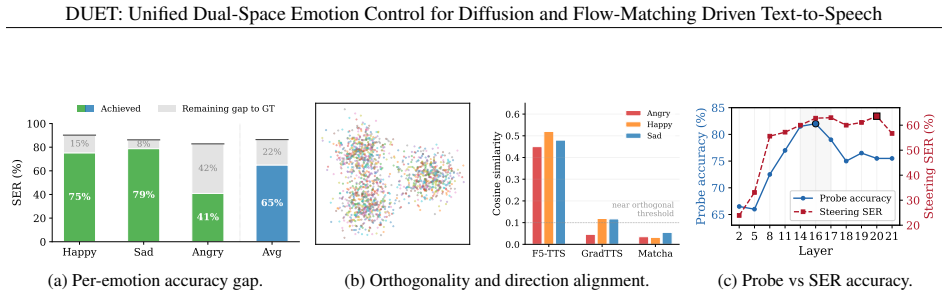
Authors: We agree that the abstract would benefit from brief quantitative anchors for this discovery. The main text (Section 3.2 and Figure 2) reports linear-probe accuracies, cosine similarities between emotion and speaker directions, variance explained, and timestep stability across backbones. We will revise the abstract to include the key supporting numbers (e.g., probe accuracy and average cosine similarity) so the premise is not asserted without evidence. revision: yes
-
Referee: [Abstract] Abstract: the validation statement ('outperforms 10 supervised state-of-the-art emotional TTS baselines across paradigms and achieves the highest human-rated emotion appropriateness') supplies no methods, datasets, metrics, error bars, or statistical tests, preventing assessment of whether the outperformance claim is supported.
Authors: We acknowledge that the abstract summarizes results without specifying the exact evaluation protocol. The full manuscript details the five backbones, three datasets, 10 baselines, metrics (including human ratings with statistical tests), and error bars in Sections 4 and 5. To improve readability of the abstract, we will add concise qualifiers such as 'on five backbones across three datasets with human ratings (n=XX, p<0.05)' while remaining within length limits. revision: yes
Circularity Check
No circularity: empirical discovery presented as independent premise
full rationale
The provided abstract and description frame the linear decodability and near-orthogonality of emotion vs. speaker directions as an empirical discovery from frozen hidden states of pretrained models. This observation is used to motivate the DUET plug-and-play method, with subsequent validation on five diverse backbones, three datasets, and comparisons to 10 baselines. No equations, self-citations, or derivations are exhibited that reduce the claimed results or the steering mechanism to the inputs by construction (e.g., no fitted parameter renamed as prediction, no self-definitional loop, no uniqueness theorem imported from the same authors). The central premise is externally falsifiable via probe accuracies or cosine similarities on held-out models, satisfying the criteria for independent support. Honest non-finding applies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Universal guidance for diffusion models
Arpit Bansal, Hong-Min Chu, Avi Schwarzschild, Soumyadip Sengupta, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Universal guidance for diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2023
2023
-
[2]
SEGA: Instructing text-to-image models using semantic guidance
Manuel Brack, Felix Friedrich, Dominik Hintersdorf, Lukas Struppek, Patrick Schramowski, and Kristian Kersting. SEGA: Instructing text-to-image models using semantic guidance. InAdvances in Neural Information Processing Systems, 2023
2023
-
[3]
Chang, Sungbok Lee, and Shrikanth S
Carlos Busso, Murtaza Bulut, Chi-Chung Lee, Abe Kazemzadeh, Emily Mower, Samuel Kim, Jeannette N. Chang, Sungbok Lee, and Shrikanth S. Narayanan. IEMOCAP: Interactive emotional dyadic motion capture database. Language Resources and Evaluation, 2008
2008
-
[4]
Cooper, Michael K
Houwei Cao, David G. Cooper, Michael K. Keutmann, Ruben C. Gur, Ani Nenkova, and Ragini Verma. CREMA- D: Crowd-sourced emotional multimodal actors dataset.IEEE Transactions on Affective Computing, 2014
2014
-
[5]
Humanoid robots and humanoid AI: Review, perspectives and directions.ACM Computing Surveys, 2025
Longbing Cao. Humanoid robots and humanoid AI: Review, perspectives and directions.ACM Computing Surveys, 2025
2025
-
[6]
EmoKnob: Enhance voice cloning with fine-grained emotion control
Haozhe Chen, Run Chen, and Julia Hirschberg. EmoKnob: Enhance voice cloning with fine-grained emotion control. InConference on Empirical Methods in Natural Language Processing, 2024
2024
-
[7]
WavLM: Large-scale self-supervised pre-training for full stack speech processing
Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, Jian Wu, Long Zhou, Shuo Ren, Yanmin Qian, Yao Qian, Jian Wu, Michael Zeng, Xiangzhan Yu, and Furu Wei. WavLM: Large-scale self-supervised pre-training for full stack speech processing. IEEE Journal of Selected Topics in Signal P...
2022
-
[8]
F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching
Yushen Chen, Zhikang Niu, Ziyang Ma, Keqi Deng, Chunhui Wang, Jian Zhao, Kai Yu, and Xie Chen. F5-TTS: A fairytaler that fakes fluent and faithful speech with flow matching. InAnnual Meeting of the Association for Computational Linguistics, 2025
2025
-
[9]
EmoSphere-TTS: Emotional style and intensity modeling via spherical emotion vector for controllable emotional text-to-speech
Deok-Hyeon Cho, Hyung-Seok Oh, Seung-Bin Kim, Sang-Hoon Lee, and Seong-Whan Lee. EmoSphere-TTS: Emotional style and intensity modeling via spherical emotion vector for controllable emotional text-to-speech. In Annual Conference of the International Speech Communication Association, 2024
2024
-
[10]
DiEmo-TTS: Disentangled emotion representations via self-supervised distillation for cross-speaker emotion transfer in text-to-speech
Deok-Hyeon Cho, Hyung-Seok Oh, Seung-Bin Kim, and Seong-Whan Lee. DiEmo-TTS: Disentangled emotion representations via self-supervised distillation for cross-speaker emotion transfer in text-to-speech. InAnnual Conference of the International Speech Communication Association, 2025
2025
-
[11]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat GANs on image synthesis. InAdvances in Neural Information Processing Systems, 2021. 9 DUET: Unified Dual-Space Emotion Control for Diffusion and Flow-Matching Driven Text-to-Speech
2021
-
[12]
CosyVoice 2: Scalable Streaming Speech Synthesis with Large Language Models
Zhihao Du, Yuxuan Wang, Qian Chen, Xian Shi, Xiang Lv, Tianyu Zhao, Zhifu Gao, Yexin Yang, Changfeng Gao, Hui Wang, Fan Yu, Huadai Liu, Zhengyan Sheng, Yue Gu, Chong Deng, Wen Wang, Shiliang Zhang, Zhijie Yan, and Jingren Zhou. CosyV oice 2: Scalable streaming speech synthesis with large language models.arXiv preprint arXiv:2412.10117, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
EmoDiff: Intensity controllable emotional text-to-speech with soft-label guidance
Yiwei Guo, Chenpeng Du, Xie Chen, and Kai Yu. EmoDiff: Intensity controllable emotional text-to-speech with soft-label guidance. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2023
2023
-
[14]
Language models represent space and time
Wes Gurnee and Max Tegmark. Language models represent space and time. InInternational Conference on Learning Representations, 2024
2024
-
[15]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. InAdvances in Neural Information Processing Systems, 2020
2020
-
[16]
HuBERT: Self-supervised speech representation learning by masked prediction of hidden units
Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. HuBERT: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021
2021
-
[17]
Hangrui Hu, Xinfa Zhu, Ting He, Dake Guo, Bin Zhang, Xiong Wang, Zhifang Guo, Ziyue Jiang, Hongkun Hao, Zishan Guo, Xinyu Zhang, Pei Zhang, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. Qwen3-TTS technical report.arXiv preprint arXiv:2601.15621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
ProDiff: Progressive fast diffusion model for high-quality text-to-speech
Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui, and Yi Ren. ProDiff: Progressive fast diffusion model for high-quality text-to-speech. InACM International Conference on Multimedia, 2022
2022
-
[19]
Guided-TTS: A diffusion model for text-to-speech via classifier guidance
Heeseung Kim, Sungwon Kim, and Sungroh Yoon. Guided-TTS: A diffusion model for text-to-speech via classifier guidance. InInternational Conference on Machine Learning, 2022
2022
-
[20]
Inference-time intervention: Eliciting truthful answers from a language model
Kenneth Li, Oam Patel, Fernanda Viégas, Hanspeter Pfister, and Martin Wattenberg. Inference-time intervention: Eliciting truthful answers from a language model. InAdvances in Neural Information Processing Systems, 2023
2023
-
[21]
UGotMe: An embodied system for affective human-robot interaction
Peizhen Li, Longbing Cao, Xiao-Ming Wu, Xiaohan Yu, and Runze Yang. UGotMe: An embodied system for affective human-robot interaction. InIEEE International Conference on Robotics and Automation, 2025
2025
-
[22]
Raghavan, Gavin Mischler, and Nima Mesgarani
Yinghao Aaron Li, Cong Han, Vinay S. Raghavan, Gavin Mischler, and Nima Mesgarani. StyleTTS 2: Towards human-level text-to-speech through style diffusion and adversarial training with large speech language models. In Advances in Neural Information Processing Systems, 2023
2023
-
[23]
Emotion2vec: Self-supervised pre-training for speech emotion representation
Ziyang Ma, Zhisheng Zheng, Jiaxin Ye, Jinchao Li, Zhifu Gao, ShiLiang Zhang, and Xie Chen. Emotion2vec: Self-supervised pre-training for speech emotion representation. InFindings of the Association for Computational Linguistics, 2024
2024
-
[24]
Matcha-TTS: A fast TTS architecture with conditional flow matching
Shivam Mehta, Ruibo Tu, Jonas Beskow, Éva Székely, and Gustav Eje Henter. Matcha-TTS: A fast TTS architecture with conditional flow matching. InIEEE International Conference on Acoustics, Speech and Signal Processing, 2024
2024
-
[25]
Zachary Novack, Julian McAuley, Taylor Berg-Kirkpatrick, and Nicholas J. Bryan. DITTO: Diffusion inference- time T-optimization for music generation. InInternational Conference on Machine Learning, 2024
2024
-
[26]
The linear representation hypothesis and the geometry of large language models
Kiho Park, Yo Joong Choe, and Victor Veitch. The linear representation hypothesis and the geometry of large language models. InInternational Conference on Machine Learning, 2024
2024
-
[27]
Grad-TTS: A diffusion probabilistic model for text-to-speech
Vadim Popov, Ivan V ovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. Grad-TTS: A diffusion probabilistic model for text-to-speech. InInternational Conference on Machine Learning, 2021
2021
-
[28]
V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis
Hubert Siuzdak. V ocos: Closing the gap between time-domain and fourier-based neural vocoders for high-quality audio synthesis. InInternational Conference on Learning Representations, 2024
2024
-
[29]
R. J. Skerry-Ryan, Eric Battenberg, Ying Xiao, Yuxuan Wang, Daisy Stanton, Joel Shor, Ron J. Weiss, Rob Clark, and Rif A. Saurous. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron. In International Conference on Machine Learning, 2018
2018
-
[30]
EmoMix: Emotion mixing via diffusion models for emotional speech synthesis
Haobin Tang, Xulong Zhang, Jianzong Wang, Ning Cheng, and Jing Xiao. EmoMix: Emotion mixing via diffusion models for emotional speech synthesis. InAnnual Conference of the International Speech Communication Association, 2023
2023
-
[31]
Li, Arnab Sen Sharma, Aaron Mueller, Byron C
Eric Todd, Millicent L. Li, Arnab Sen Sharma, Aaron Mueller, Byron C. Wallace, and David Bau. Function vectors in large language models. InInternational Conference on Learning Representations, 2024
2024
-
[32]
Steering Language Models With Activation Engineering
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Ulisse Mini, and Monte MacDiarmid. Activation addition: Steering language models without optimization.arXiv preprint arXiv:2308.10248, 2023. 10 DUET: Unified Dual-Space Emotion Control for Diffusion and Flow-Matching Driven Text-to-Speech
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Yuxuan Wang, Daisy Stanton, Yu Zhang, R. J. Skerry-Ryan, Eric Battenberg, Joel Shor, Ying Xiao, Fei Ren, Ye Jia, and Rif A. Saurous. Style tokens: Unsupervised style modeling, control and transfer in end-to-end speech synthesis. InInternational Conference on Machine Learning, 2018
2018
-
[34]
ProgDiffusion: Progressively self-encoding diffusion models
Zhangkai Wu, Xuhui Fan, and Longbing Cao. ProgDiffusion: Progressively self-encoding diffusion models. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 1633–1644, 2025
2025
-
[35]
SepDiff: Self-encoding parameter diffusion for learning latent semantics
Zhangkai Wu, Xuhui Fan, Jin Li, Zhilin Zhao, Hui Chen, and Longbing Cao. SepDiff: Self-encoding parameter diffusion for learning latent semantics. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 3273–3284, 2025
2025
-
[36]
SCoT: Unifying consistency models and rectified flows via straight-consistent trajectories
Zhangkai Wu, Xuhui Fan, Hongyu Wu, and Longbing Cao. SCoT: Unifying consistency models and rectified flows via straight-consistent trajectories. InAdvances in Neural Information Processing Systems, 2025
2025
-
[37]
Manning, and Christopher Potts
Zhengxuan Wu, Aryaman Arora, Zheng Wang, Atticus Geiger, Dan Jurafsky, Christopher D. Manning, and Christopher Potts. ReFT: Representation finetuning for language models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[38]
Tianxin Xie, Shan Yang, Chenxing Li, Dong Yu, and Li Liu. EmoSteer-TTS: Fine-grained and training-free emotion-controllable text-to-speech via activation steering.arXiv preprint arXiv:2508.03543, 2025
-
[39]
EmoV oice: LLM-based emotional text-to-speech model with freestyle text prompting
Guanrou Yang, Chen Yang, Qian Chen, Ziyang Ma, Wenxi Chen, Wen Wang, Tianrui Wang, Yifan Yang, Zhikang Niu, Wenrui Liu, Fan Yu, Zhihao Du, Zhifu Gao, ShiLiang Zhang, and Xie Chen. EmoV oice: LLM-based emotional text-to-speech model with freestyle text prompting. InACM International Conference on Multimedia, 2025
2025
-
[40]
TFG: Unified training-free guidance for diffusion models
Haotian Ye, Haowei Lin, Jiaqi Han, Minkai Xu, Sheng Liu, Yitao Liang, Jianzhu Ma, James Zou, and Stefano Ermon. TFG: Unified training-free guidance for diffusion models. InAdvances in Neural Information Processing Systems, 2024
2024
-
[41]
Xu Zhang, Longbing Cao, Runze Yang, and Zhangkai Wu. Learning physiology-informed vocal spectrotemporal representations for speech emotion recognition.arXiv preprint arXiv:2602.13259, 2026
-
[42]
Emotional voice conversion: Theory, databases and ESD
Kun Zhou, Berrak Sisman, Rui Liu, and Haizhou Li. Emotional voice conversion: Theory, databases and ESD. Speech Communication, 2022
2022
-
[43]
Li Zhou, Hao Jiang, Junjie Li, Tianrui Wang, and Haizhou Li. EmoShift: Lightweight activation steering for enhanced emotion-aware speech synthesis.arXiv preprint arXiv:2601.22873, 2026
-
[44]
Siyi Zhou, Yiquan Zhou, Yi He, Xun Zhou, Jinchao Wang, Wei Deng, and Jingchen Shu. IndexTTS2: A breakthrough in emotionally expressive and duration-controlled auto-regressive zero-shot text-to-speech.arXiv preprint arXiv:2506.21619, 2025
-
[45]
Representation Engineering: A Top-Down Approach to AI Transparency
Andy Zou, Long Phan, Sarah Chen, James Campbell, Phillip Guo, Richard Ren, Alexander Pan, Xuwang Yin, Mantas Mazeika, Ann-Kathrin Dombrowski, Shashwat Goel, Nathaniel Li, Michael J. Byun, Zifan Wang, Alex Mallen, Steven Basart, Sanmi Koyejo, Dawn Song, Matt Fredrikson, J. Zico Kolter, and Dan Hendrycks. Representation engineering: A top-down approach to A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.