State Machine Guided Multi-Relational Synthetic Data from Logs for Anomaly Detection
Pith reviewed 2026-06-28 18:24 UTC · model grok-4.3
The pith
Recovering a state machine from logs lets you generate multi-relational synthetic data that improves anomaly and bug detection when added to real logs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Execution logs implicitly encode a relational database governed by a latent state machine. Recovering this state machine directly from the logs induces a corresponding multi-table relational schema and serves as a generative prior that produces realistic multi-relational synthetic data preserving structural, temporal, and process constraints. Augmenting real logs with the resulting synthetic data significantly improves anomaly and bug detection performance on held-out real datasets relative to sequence-based baselines and naive oversampling.
What carries the argument
The state machine recovered directly from logs, used as a generative prior to produce realistic multi-relational synthetic data that preserves structural, temporal, and process constraints.
If this is right
- Augmenting real logs with the synthetic relational data yields higher anomaly and bug detection accuracy on held-out real datasets than sequence-based methods or naive oversampling.
- The generated data satisfies constraint validation, distributional similarity, and process-level metrics that flat sequence generation does not.
- Logs can be treated as a multi-relational database rather than a flat sequence of templates for downstream tasks.
- Rare but valid execution behaviors can be amplified without violating the system's underlying process constraints.
Where Pith is reading between the lines
- The same recovered state machine could be reused to generate targeted test cases for specific rare paths without additional manual specification.
- The relational schema might allow anomaly explanations to point to specific states or transitions rather than opaque sequence patterns.
- If the state machine is stable across versions of a system, the synthetic data pipeline could transfer between related software releases with limited retraining.
Load-bearing premise
The state machine recovered directly from logs accurately represents the true execution structure and can serve as a generative prior that produces realistic multi-relational data preserving structural, temporal, and process constraints.
What would settle it
A direct test would be to measure whether adding the generated multi-relational synthetic data to real training logs fails to improve or reduces anomaly and bug detection accuracy on held-out real test logs compared with sequence baselines and naive oversampling.
Figures
read the original abstract
Software systems generate massive unstructured logs that record execution behavior, failures, and interactions across components, yet existing log anomaly detection methods treat these logs primarily as flat sequences of templates, overlooking the relational execution structure that governs how events co-occur and evolve over time. We propose a framework that discovers this hidden structure by recovering an execution state machine directly from logs and inducing a corresponding multi-table relational schema connecting traces, events, states, transitions, and parameters. This discovered state machine serves as a generative prior to produce realistic multi-relational synthetic data that preserves structural, temporal, and process constraints while amplifying rare but valid execution behaviors. We assess the fidelity of the generated data through constraint validation, distributional similarity, and process-level metrics, and demonstrate its usefulness by showing that augmenting real logs with the synthetic relational data significantly improves anomaly and bug detection on held-out real datasets compared to sequence-based baselines and naive oversampling. Our results show that execution logs implicitly encode a relational database governed by a latent state machine, and that recovering this structure enables principled synthetic data generation for robust and interpretable anomaly detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that recovering an execution state machine directly from logs induces a multi-relational schema (traces, events, states, transitions, parameters); this machine then serves as a generative prior to synthesize realistic multi-relational data preserving structural, temporal, and process constraints while amplifying rare behaviors; augmenting real logs with the synthetic data yields significant gains in anomaly and bug detection on held-out real datasets versus sequence-based baselines and naive oversampling.
Significance. If the state-machine recovery and fidelity results hold, the work would be significant for log anomaly detection by supplying a principled, structure-preserving augmentation technique that addresses data scarcity for rare events. The explicit use of an induced state machine as generative prior and the multi-relational framing are strengths that could improve both performance and interpretability over flat-sequence methods.
major comments (2)
- [Abstract] Abstract: the central claim that synthetic augmentation 'significantly improves' detection is load-bearing, yet the abstract (and the supplied text) contains no quantitative results, dataset sizes, error bars, or statistical tests, preventing verification that gains exceed baselines for reasons other than representation artifacts.
- [State machine recovery] State-machine recovery and generative procedure: the weakest assumption—that the recovered machine faithfully encodes latent relational, temporal, and process constraints—is not supported by any description of the recovery algorithm, uniqueness guarantees, or comparison against ground-truth models. Logs are typically incomplete and noisy; without such validation the generative prior may produce data that violates real constraints, rendering the reported improvement inconclusive.
minor comments (2)
- [Fidelity assessment] The fidelity assessment (constraint validation, distributional similarity, process-level metrics) is mentioned but lacks concrete definitions or thresholds that would allow a reader to reproduce the checks.
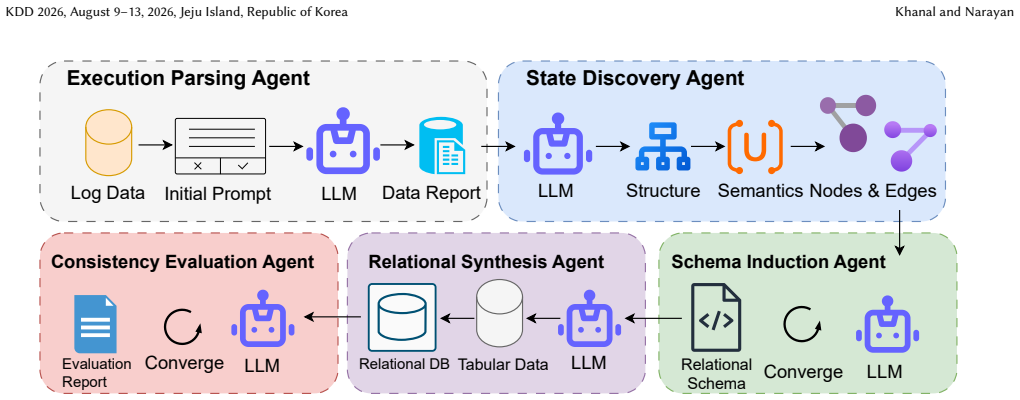
- [Schema induction] Notation for the multi-table schema is introduced without an accompanying diagram or explicit foreign-key relations, reducing clarity of the relational structure.
Simulated Author's Rebuttal
Thank you for the thorough review and constructive feedback. We address each major comment point by point below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that synthetic augmentation 'significantly improves' detection is load-bearing, yet the abstract (and the supplied text) contains no quantitative results, dataset sizes, error bars, or statistical tests, preventing verification that gains exceed baselines for reasons other than representation artifacts.
Authors: We agree that the abstract should include quantitative support for the central claim. The body of the manuscript (Section 4) reports specific dataset sizes, performance metrics with error bars, and statistical comparisons to baselines. We will revise the abstract to include representative quantitative results (e.g., F1-score improvements and significance levels) to enable direct verification. revision: yes
-
Referee: [State machine recovery] State-machine recovery and generative procedure: the weakest assumption—that the recovered machine faithfully encodes latent relational, temporal, and process constraints—is not supported by any description of the recovery algorithm, uniqueness guarantees, or comparison against ground-truth models. Logs are typically incomplete and noisy; without such validation the generative prior may produce data that violates real constraints, rendering the reported improvement inconclusive.
Authors: Section 3.1 describes the state-machine recovery algorithm, including inference of states, transitions, and the induced relational schema from log traces. Fidelity is assessed via constraint validation, distributional similarity, and process-level metrics (as noted in the abstract). We do not provide uniqueness guarantees, as recovery depends on observed (potentially incomplete) logs, and we discuss noise limitations in Section 5. We will add a subsection with explicit comparisons to ground-truth models on synthetic logs to strengthen validation of the generative prior. revision: partial
Circularity Check
No circularity; framework claims rest on empirical augmentation results, not self-referential definitions or fits.
full rationale
The paper describes a log-to-state-machine recovery process used to generate synthetic relational data, then reports empirical gains on held-out real datasets versus baselines. No equations, parameter fits, or self-citations appear in the text that would make any claimed improvement or fidelity metric reduce to its own inputs by construction. The generative prior is induced from the same logs but the evaluation uses separate held-out data and external baselines, keeping the derivation chain non-circular. This is the expected non-finding for a methods paper whose central result is an empirical comparison rather than a closed mathematical derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Execution logs implicitly encode a relational database governed by a latent state machine
Reference graph
Works this paper leans on
-
[1]
Jinze Bai et al. 2023. Qwen Technical Report.arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, et al. 2020. Language Models are Few-Shot Learners.Advances in Neural Information Processing Systems33 (2020), 1877–1901
2020
-
[3]
Varun Chandola, Arindam Banerjee, and Vipin Kumar. 2009. Anomaly Detection: A Survey.Comput. Surveys41, 3 (2009), 1–58
2009
-
[4]
Yutong Chen, Zihan Liu, and Jingbo Zhou. 2023. Agent-Based Modeling with Large Language Models.arXiv preprint arXiv:2306.XXXXX(2023)
2023
-
[5]
DeepSeek-AI. 2024. DeepSeek-R1: Incentivizing Reasoning Capability in Large Language Models.arXiv preprint arXiv:2401.06066(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Kaize Ding, Jundong Huang, et al . 2021. GraphADASYN: Adaptive Synthetic Sampling on Graphs for Imbalanced Node Classification. InProceedings of the 30th ACM International Conference on Information and Knowledge Management. ACM, 339–348
2021
- [7]
-
[8]
Min Du and Feifei Li. 2017. Spell: Streaming Parsing of System Event Logs. InProceedings of the 2017 IEEE International Conference on Data Mining. IEEE, 859–864
2017
-
[9]
Min Du, Feifei Li, Guineng Zheng, and Vivek Srikumar. 2019. Deep Learning- based Log Anomaly Detection.IEEE Transactions on Dependable and Secure Computing18, 5 (2019), 2359–2371
2019
-
[10]
Qiang Fu, Jian-Guang Lou, Yi Wang, and Jiang Li. 2022. A Survey on Log-based Anomaly Detection.Comput. Surveys55, 2 (2022), 1–37
2022
-
[11]
Google DeepMind. 2024. Gemma: Open Models Based on Gemini Research.arXiv preprint arXiv:2403.08295(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Haixuan Guo, Shuai Yuan, Jinyang Wu, and Hongliang Liu. 2021. LogBERT: Log Anomaly Detection via BERT. InProceedings of the 2021 International Joint Conference on Artificial Intelligence. 3449–3455
2021
- [13]
-
[14]
Pinjia He, Jieming Zhu, Zibin Zheng, and Michael R. Lyu. 2017. Drain: An Online Log Parsing Approach with Fixed Depth Tree. InProceedings of the 2017 IEEE International Conference on Web Services. IEEE, 33–40
2017
-
[15]
Shilin He, Jieming Zhu, Pinjia He, and Michael R. Lyu. 2016. Experience Re- port: System Log Analysis for Anomaly Detection. InProceedings of the 27th International Symposium on Software Reliability Engineering. IEEE, 207–218
2016
-
[16]
Shilin He, Jieming Zhu, Pinjia He, and Michael R. Lyu. 2017. DeepLog: Anomaly Detection and Diagnosis from System Logs through Deep Learning. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security. ACM, 1285–1298
2017
-
[17]
Albert Q. Jiang et al. 2023. Mistral 7B.arXiv preprint arXiv:2310.06825(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Ranade, Rishabh Agrawal, Kalyan S
Aja Khanal, Kaushik T. Ranade, Rishabh Agrawal, Kalyan S. Basu, and Apurva Narayan. 2026. Agents of Diffusion: Enhancing Diffusion Language Models with Multi-Agent Reinforcement Learning for Structured Data Generation. In Proceedings of the 25th International Conference on Autonomous Agents and Multi- agent Systems (AAMAS). International Foundation for Au...
2026
- [19]
-
[20]
Qingwei Lin, Hongyu Zhang, Jian-Guang Lou, Yu Zhang, and Xuewei Chen
-
[21]
InProceedings of the 38th International Conference on Software Engineering
Log Clustering Based Problem Identification for Online Service Systems. InProceedings of the 38th International Conference on Software Engineering. ACM, 102–111. KDD 2026, August 9–13, 2026, Jeju Island, Republic of Korea Khanal and Narayan
2026
-
[22]
Hong Liu et al. 2022. AGMixup: Data Augmentation for Graph Neural Networks. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 4616–4624
2022
-
[23]
Xiaoyu Liu and Philip S. Yu. 2021. GAug: Graph Data Augmentation for Graph Neural Networks. InProceedings of the 30th ACM International Conference on Information and Knowledge Management. ACM, 1016–1025
2021
-
[24]
Cai, Meredith Ringel Morris, Percy Liang, and Michael S
Joon Sung Park, Joseph O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Technology. ACM, 1–22
2023
-
[25]
Significant Gravitas. 2023. Auto-GPT: An Autonomous GPT-4 Experiment. GitHub Repository(2023). https://github.com/Significant-Gravitas/Auto-GPT
2023
- [26]
-
[27]
Hugo Touvron et al. 2024. LLaMA 3: Open and Efficient Foundation Language Models.arXiv preprint arXiv:2404.14219(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Vinayak Verma, Alex Lamb, Christopher Beckham, et al. 2019. Graph Mixup. In Advances in Neural Information Processing Systems, Vol. 32
2019
- [29]
-
[30]
Self-Instruct: Aligning Language Models with Self-Generated Instructions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Han- naneh Hajishirzi, and Daniel Khashabi. 2022. Self-Instruct: Aligning Language Models with Self-Generated Instructions.arXiv preprint arXiv:2212.10560(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [31]
- [32]
-
[33]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, et al
-
[34]
Advances in Neural Information Processing Systems35 (2022), 24824–24837
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. Advances in Neural Information Processing Systems35 (2022), 24824–24837
2022
-
[35]
Wenqiang Xia, Xiao Huang, et al . 2023. GraphEdit: Large Language Models for Graph Structure Editing. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
-
[36]
Wei Xu, Ling Huang, Armando Fox, and David Patterson. 2018. Log-based Anomaly Detection: A Systematic Survey. InProceedings of the IEEE International Conference on Cloud Computing
2018
-
[37]
Wei Xu, Ling Huang, Armando Fox, David Patterson, and Michael Jordan. 2009. Detecting Large-Scale System Problems by Mining Console Logs. InProceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles. ACM, 117– 132
2009
-
[38]
Patterson, and Michael I
Wei Xu, Ling Huang, Armando Fox, David A. Patterson, and Michael I. Jordan
-
[39]
InPro- ceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles
Detecting Large-Scale System Problems by Mining Console Logs. InPro- ceedings of the ACM SIGOPS 22nd Symposium on Operating Systems Principles. ACM, 117–132
- [40]
-
[41]
Qingwei Zhang, Meng Chen, Meng Li, Hongyu Zhang, and Yingnong Dang. 2019. Robust Log-based Anomaly Detection on Unstable Log Data. InProceedings of the 27th ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering. ACM, 807–817
2019
-
[42]
Xu Zhang, Yong Xu, Qingwei Lin, Bo Qiao, Hongyu Zhang, Yingnong Dang, Chen Chen, and Tao Xie. 2019. LogAnomaly: Unsupervised Detection of Sequential and Quantitative Anomalies in Unstructured Logs. InProceedings of the 28th International Joint Conference on Artificial Intelligence. 4739–4745
2019
- [43]
-
[44]
Tong Zhao, Yang Liu, Leonardo Neves, et al. 2021. GraphSMOTE: Imbalanced Node Classification on Graphs with Synthetic Minority Over-Sampling. InPro- ceedings of the 14th ACM International Conference on Web Search and Data Mining. ACM, 833–841
2021
-
[45]
Yifan Zhao, Zhen Chen, et al . 2023. FG-SMOTE: Feature Generation Based Oversampling for Imbalanced Graph Classification.IEEE Transactions on Neural Networks and Learning Systems(2023)
2023
-
[46]
e3f1a2c4-9d2a-4f7e-bd9a-12ac34ef56ab
Jieming Zhu, Shilin He, Jieming Zhu, Jian Li, Pinjia He, and Michael R. Lyu. 2019. Tools and Benchmarks for Automated Log Parsing. InProceedings of the 41st International Conference on Software Engineering: Software Engineering in Practice. IEEE, 121–130. A Appendix This appendix provides the information required to reproduce the experiments presented in ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.