Trustworthy Recommendation in the Era of Large Language Models: Opportunities and Challenges
Pith reviewed 2026-06-28 18:39 UTC · model grok-4.3
The pith
Large language models act as a double-edged sword for trustworthy recommendation systems by enabling new capabilities while creating fresh risks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
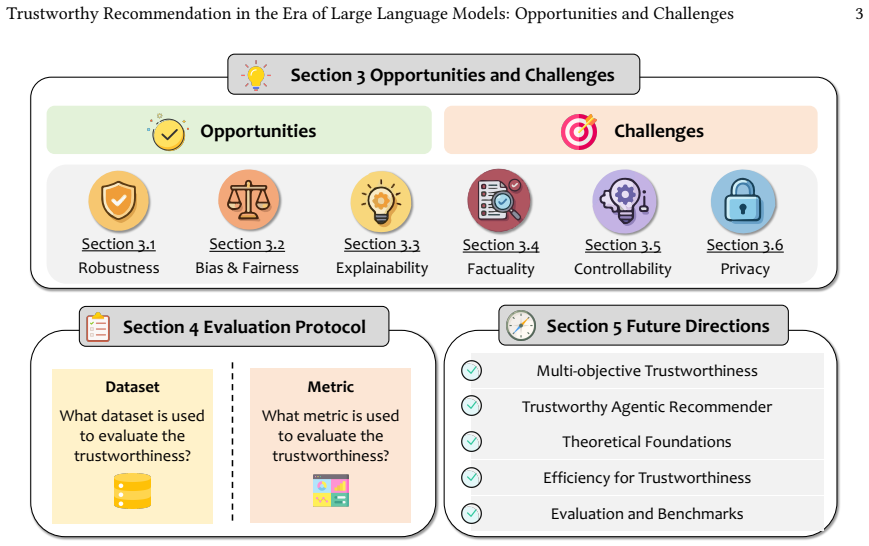
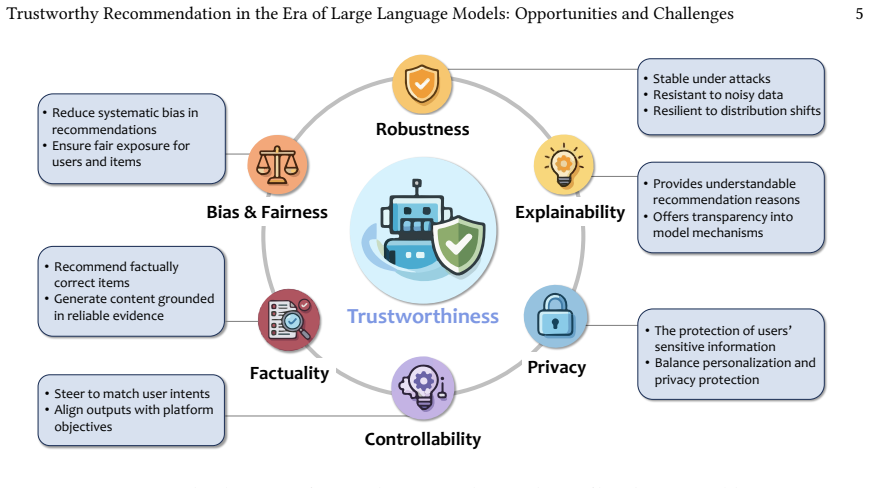
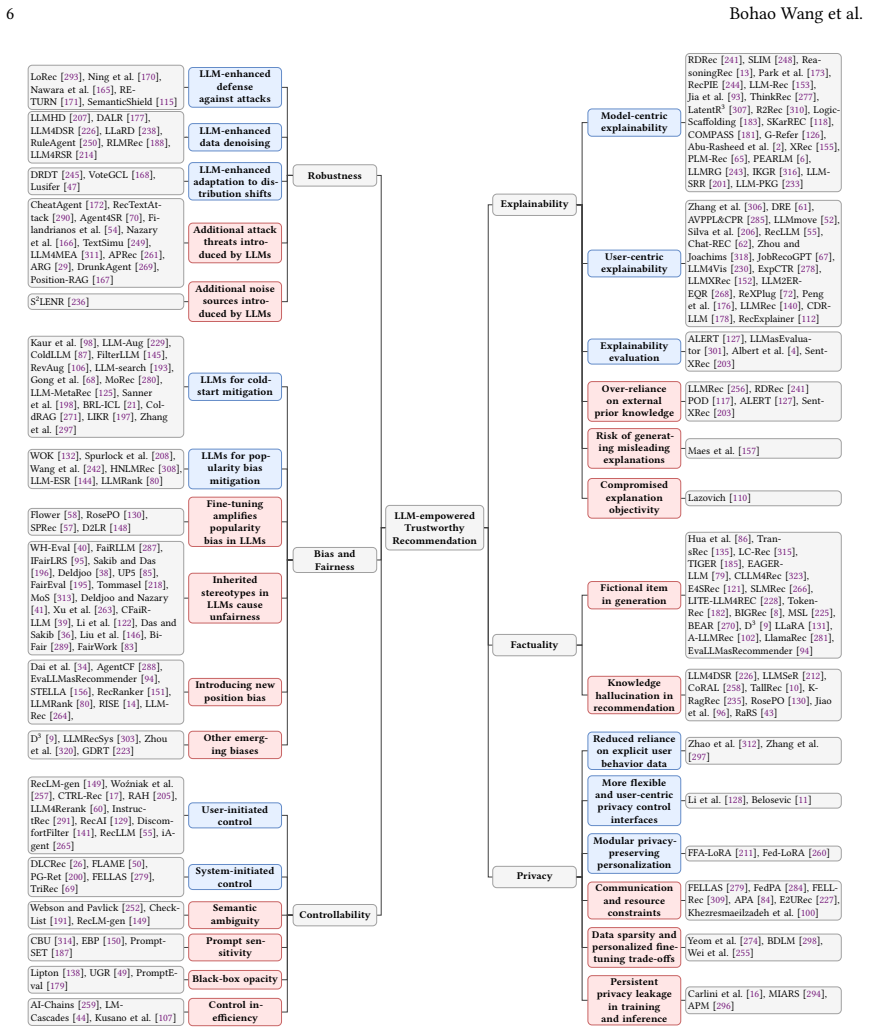
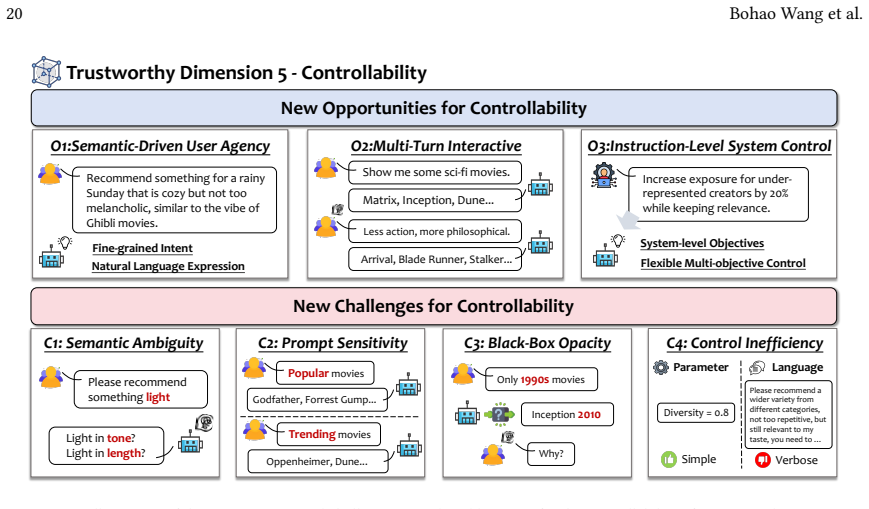
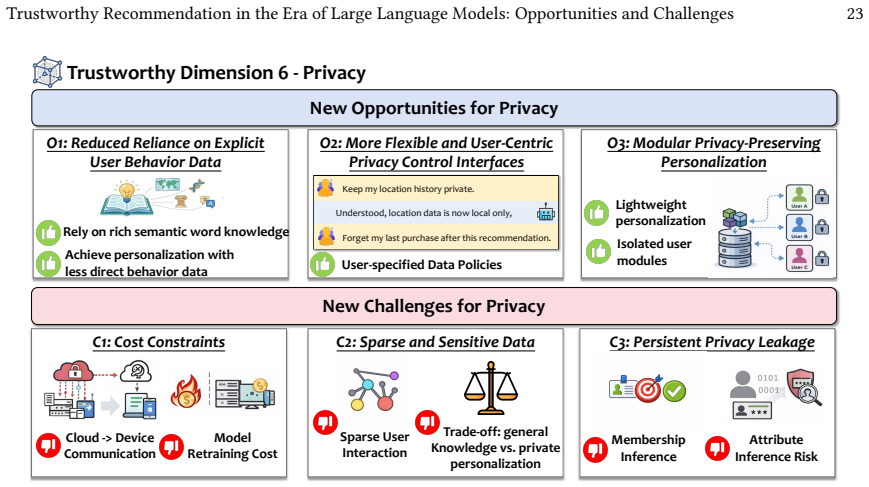
The integration of large language models into recommender systems produces a dual effect on trustworthiness. While the models supply mechanisms for stronger intent reasoning and user interaction that can improve robustness, fairness, and privacy, they simultaneously introduce new failure modes including amplified bias and hallucination-driven errors. Systematic analysis of over 200 studies yields a taxonomy that identifies 13 opportunities and 18 challenges across six fundamental dimensions, together with a survey of supporting datasets and evaluation metrics.
What carries the argument
A taxonomy classifying existing literature on LLM-empowered recommendation into 13 opportunities and 18 challenges distributed across six trustworthiness dimensions.
If this is right
- Evaluation protocols must incorporate new metrics that detect LLM-specific issues such as hallucination in generated recommendations.
- Mitigation strategies are required to address novel bias forms introduced by language-model reasoning.
- Privacy techniques need adaptation to handle the semantic inference capabilities of LLMs.
- Fairness definitions should be revised to account for biases that arise from LLM training data and generation processes.
- Future systems will need hybrid designs that selectively apply LLM components only where their benefits exceed the added risks.
Where Pith is reading between the lines
- The taxonomy may need extension once multimodal large language models become common in recommendation pipelines.
- High-stakes applications such as medical or financial recommendations may require extra verification layers not yet captured in the current challenge list.
- Transferable techniques from general large-model safety research could address some of the hallucination and bias challenges identified here.
- Large-scale experiments on the reviewed datasets could quantify whether the net effect of LLMs on trustworthiness is positive or negative in practice.
Load-bearing premise
A comprehensive review of over 200 studies produces an unbiased and gap-free taxonomy of all relevant opportunities and challenges.
What would settle it
Discovery of a sizable set of studies on LLM-based recommendation whose findings fall outside the proposed 13 opportunities and 18 challenges or that reveal major uncovered areas in the six dimensions.
Figures
read the original abstract
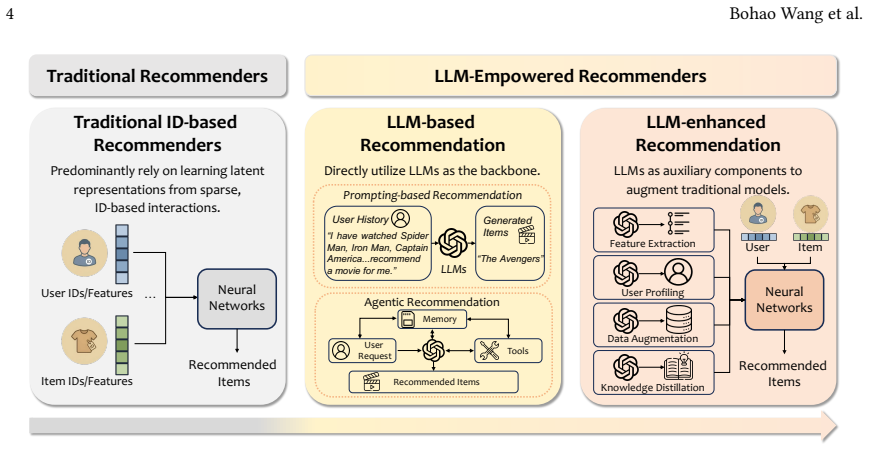
The field of recommender systems (RS) is currently undergoing two profound paradigm shifts. From the perspective of objectives, the goal has shifted beyond mere recommendation accuracy to comprehensive trustworthiness, encompassing multiple dimensions such as robustness, fairness, and privacy preservation. From a technical perspective, Large Language Models (LLMs) have been extensively integrated into RS, reshaping the foundations of recommendation through richer semantic understanding, stronger intent reasoning, and more flexible user interactions. The convergence of these two shifts prompts a timely and pivotal question: how does the integration of LLMs reshape the landscape of trustworthy recommendation? In this work, we present a systematic review of trustworthy LLM-empowered recommendation. By comprehensively analyzing over 200 recent studies, we reveal that the introduction of LLMs acts as a double-edged sword. While their advanced mechanisms and user-friendly interfaces offer unprecedented opportunities to enhance trustworthiness, they simultaneously introduce new risks, such as novel forms of bias and hallucination-induced issues. To characterize this dual impact, we systematically identify 13 opportunities and 18 challenges across six fundamental dimensions of trustworthiness, and accordingly organize the existing literature into a novel taxonomy. We also provide a comprehensive review of commonly used datasets and evaluation metrics to facilitate empirical validation. Finally, we identify critical open challenges and outline future directions, hoping to inspire future research on this emerging topic.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a systematic review of trustworthy LLM-empowered recommender systems. It claims that integrating LLMs into RS creates a double-edged effect: 13 opportunities to improve trustworthiness (across dimensions such as robustness, fairness, and privacy) alongside 18 new challenges (including novel biases and hallucination issues). The authors synthesize findings from over 200 studies into a novel taxonomy, review datasets and evaluation metrics, and outline future research directions.
Significance. A well-executed synthesis of this scope could provide a useful organizing framework for an emerging intersection of LLMs and trustworthy RS, helping researchers navigate both enhancements and risks. The explicit enumeration of opportunities and challenges, together with the dataset/metric review, would be particularly valuable if the underlying corpus selection is reproducible.
major comments (2)
- [Abstract] Abstract: The central claim—that a comprehensive analysis of >200 studies yields a complete taxonomy of 13 opportunities and 18 challenges across six trustworthiness dimensions—rests on an undocumented literature review process. No search strategy, databases, keyword strings, date cutoffs, inclusion/exclusion criteria, or inter-rater reliability measures are described, leaving the taxonomy vulnerable to selection bias and undermining reproducibility of the opportunity/challenge mapping.
- [Abstract] The headline characterization of LLMs as a 'double-edged sword' is derived entirely from the synthesis; without the missing methodological details, it is impossible to assess whether counter-examples or underrepresented venues were systematically omitted, which directly affects the load-bearing claim that the taxonomy is representative.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for greater transparency in our literature review process. We agree that explicit methodological details are required to support the reproducibility and representativeness claims in a systematic review. We address both comments below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim—that a comprehensive analysis of >200 studies yields a complete taxonomy of 13 opportunities and 18 challenges across six trustworthiness dimensions—rests on an undocumented literature review process. No search strategy, databases, keyword strings, date cutoffs, inclusion/exclusion criteria, or inter-rater reliability measures are described, leaving the taxonomy vulnerable to selection bias and undermining reproducibility of the opportunity/challenge mapping.
Authors: We agree that the current manuscript lacks a dedicated description of the literature search and selection process. This omission weakens the ability to evaluate selection bias and reproducibility. In the revision we will add a new 'Review Methodology' subsection (likely in Section 2 or as an appendix) that explicitly documents: (1) the databases and repositories searched (Google Scholar, arXiv, ACM DL, IEEE Xplore), (2) the keyword strings and Boolean combinations used, (3) the time window (primarily 2022 onward for LLM-related work), (4) inclusion/exclusion criteria, (5) the screening and coding procedure, and (6) any inter-rater checks performed. This will allow readers to assess how the 13 opportunities and 18 challenges were mapped from the corpus. revision: yes
-
Referee: [Abstract] The headline characterization of LLMs as a 'double-edged sword' is derived entirely from the synthesis; without the missing methodological details, it is impossible to assess whether counter-examples or underrepresented venues were systematically omitted, which directly affects the load-bearing claim that the taxonomy is representative.
Authors: The double-edged-sword framing is an interpretive summary of the opportunities and challenges identified across the reviewed papers rather than an independent empirical claim. Nevertheless, we accept that without documented search and selection procedures it is difficult to judge coverage or the risk of omitted counter-examples. The added methodology section will include a limitations paragraph that discusses venue coverage, the recency bias inherent to LLM literature, and any steps taken to mitigate under-representation. We will also make the full list of reviewed papers available as supplementary material to further support scrutiny of the taxonomy. revision: yes
Circularity Check
Survey synthesis draws from external literature; no self-referential derivations or load-bearing self-citations
full rationale
The paper is a literature review that organizes >200 external studies into a taxonomy of 13 opportunities and 18 challenges. No equations, fitted parameters, predictions, or uniqueness theorems are present. The central claim (LLMs as double-edged sword) is framed as emerging from analysis of cited external work rather than reducing to any input by construction or author-overlapping citation chain. Self-citation, if present, is not load-bearing for the taxonomy itself. This meets the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard practices for conducting systematic literature reviews are followed when selecting and analyzing the 200 studies.
Reference graph
Works this paper leans on
-
[1]
Himan Abdollahpouri, Gediminas Adomavicius, Robin Burke, Ido Guy, Dietmar Jannach, Toshihiro Kamishima, Jan Krasnodebski, and Luiz Pizzato
-
[2]
Abdollahpouri et al.User Modeling and User-Adapted Interaction30, 1 (2020), 127–158
Multistakeholder recommendation: Survey and research directions: H. Abdollahpouri et al.User Modeling and User-Adapted Interaction30, 1 (2020), 127–158
2020
-
[3]
Hasan Abu-Rasheed, Christian Weber, and Madjid Fathi. 2024. Knowledge graphs as context sources for llm-based explanations of learning recommendations. In2024 IEEE Global Engineering Education Conference (EDUCON). IEEE, 1–5
2024
-
[4]
Aaron Adcock, Aayushi Srivastava, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pande, Abhinav Pandey, Abhinav Sharma, Abhishek Kadian, Abhishek Kumawat, Adam Kelsey, et al. 2026. The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes.arXiv preprint arXiv:2601.11659(2026)
-
[5]
Julien Albert, Martin Balfroid, Miriam Doh, Jérémie Bogaert, Luca La Fisca, Liesbet De Vos, Bryan Renard, Vincent Stragier, and Emmanuel Jean. 2024. User Preferences for Large Language Model versus Template-Based Explanations of Movie Recommendations: A Pilot Study.ArXiv abs/2409.06297 (2024). https://api.semanticscholar.org/CorpusID:272550316
-
[6]
Martin Arjovsky, Léon Bottou, Ishaan Gulrajani, and David Lopez-Paz. 2019. Invariant risk minimization.arXiv preprint arXiv:1907.02893(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
- [7]
-
[8]
Yejin Bang, Ziwei Ji, Alan Schelten, Anthony Hartshorn, Tara Fowler, Cheng Zhang, Nicola Cancedda, and Pascale Fung. 2025. Hallulens: Llm hallucination benchmark. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 24128–24156
2025
-
[9]
Keqin Bao, Jizhi Zhang, Wenjie Wang, Yang Zhang, Zhengyi Yang, Yanchen Luo, Chong Chen, Fuli Feng, and Qi Tian. 2025. A bi-step grounding paradigm for large language models in recommendation systems.ACM Transactions on Recommender Systems3, 4 (2025), 1–27
2025
-
[10]
Keqin Bao, Jizhi Zhang, Yang Zhang, Xinyue Huo, Chong Chen, and Fuli Feng. 2024. Decoding matters: Addressing amplification bias and homogeneity issue in recommendations for large language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 10540–10552
2024
-
[11]
Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. Tallrec: An effective and efficient tuning framework to align large language model with recommendation. InProceedings of the 17th ACM Conference on Recommender Systems. 1007–1014
2023
-
[12]
Milena Belosevic. 2025. User-Centric Design Paradigms for Trust and Control in Human-LLM-Interactions: A Survey. InProceedings of the Fourth Workshop on Bridging Human-Computer Interaction and Natural Language Processing (HCI+ NLP). 17–32
2025
-
[13]
Shai Ben-David, John Blitzer, Koby Crammer, and Fernando Pereira. 2006. Analysis of representations for domain adaptation.Advances in neural information processing systems19 (2006)
2006
- [14]
- [15]
-
[16]
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, Katherine Lee, Florian Tramer, and Chiyuan Zhang. 2022. Quantifying memorization across neural language models. InThe Eleventh International Conference on Learning Representations
2022
-
[17]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, et al. 2021. Extracting training data from large language models. In30th USENIX security symposium (USENIX Security 21). 2633–2650
2021
-
[18]
Micah Carroll, Adeline Foote, Marcus Williams, Anca Dragan, W Bradley Knox, and Smitha Milli. [n. d.]. CTRL-Rec: Controlling Recommender Systems With Natural Language. InICLR 2025 Workshop on Bidirectional Human-AI Alignment
2025
-
[19]
Yukuo Cen, Jianwei Zhang, Xu Zou, Chang Zhou, Hongxia Yang, and Jie Tang. 2020. Controllable multi-interest framework for recommendation. InProceedings of the 26th ACM SIGKDD international conference on knowledge discovery & data mining. 2942–2951
2020
-
[20]
Allison JB Chaney, Brandon M Stewart, and Barbara E Engelhardt. 2018. How algorithmic confounding in recommendation systems increases homogeneity and decreases utility. InProceedings of the 12th ACM conference on recommender systems. 224–232
2018
-
[21]
Ting-Jui Chang, Lydia Hsiao-Mei Lin, and Richard Tzong-Han Tsai. 2024. Conversational product recommendation using LLM. In2024 IEEE 4th International Conference on Electronic Communications, Internet of Things and Big Data (ICEIB). IEEE, 340–343. Manuscript submitted to ACM 36 Bohao Wang et al
2024
-
[22]
Shangkun Che, Minjia Mao, and Hongyan Liu. 2024. New Community Cold-Start Recommendation: A Novel Large Language Model-based Method. (2024)
2024
-
[23]
Chong Chen, Fei Sun, Min Zhang, and Bolin Ding. 2022. Recommendation unlearning. InProceedings of the ACM web conference 2022. 2768–2777
2022
-
[24]
Hanxiong Chen, Shaoyun Shi, Yunqi Li, and Yongfeng Zhang. 2021. Neural collaborative reasoning. InProceedings of the web conference 2021. 1516–1527
2021
- [25]
-
[26]
Jiawei Chen, Hande Dong, Xiang Wang, Fuli Feng, Meng Wang, and Xiangnan He. 2023. Bias and debias in recommender system: A survey and future directions.ACM Transactions on Information Systems41, 3 (2023), 1–39
2023
-
[27]
Jiaju Chen, Chongming Gao, Shuai Yuan, Shuchang Liu, Qingpeng Cai, and Peng Jiang. 2025. DLCRec: A Novel Approach for Managing Diversity in LLM-Based Recommender Systems. InProceedings of the Eighteenth ACM International Conference on Web Search and Data Mining. 857–865
2025
-
[28]
Wei Chen and Dexin Chen. 2025. LLM-as-Critic: Contrastive and Adversarial Strategies for Authentic Text Verification. (2025)
2025
-
[29]
Weixin Chen, Yuhan Zhao, Jingyuan Huang, Zihe Ye, Clark Mingxuan Ju, Tong Zhao, Neil Shah, Li Chen, and Yongfeng Zhang. 2026. MemRec: Collaborative Memory-Augmented Agentic Recommender System.arXiv preprint arXiv:2601.08816(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Hung-Yun Chiang, Yi-Syuan Chen, Yun-Zhu Song, Hong-Han Shuai, and Jason S Chang. 2023. Shilling black-box review-based recommender systems through fake review generation. InProceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 286–297
2023
-
[31]
Chen-Yao Chung, Ping-Yu Hsu, and Shih-Hsiang Huang. 2013. 𝛽P: A novel approach to filter out malicious rating profiles from recommender systems.Decision Support Systems55, 1 (2013), 314–325
2013
-
[32]
Yu Cui, Feng Liu, Pengbo Wang, Bohao Wang, Heng Tang, Yi Wan, Jun Wang, and Jiawei Chen. 2024. Distillation matters: empowering sequential recommenders to match the performance of large language models. InProceedings of the 18th ACM Conference on Recommender Systems. 507–517
2024
- [33]
-
[34]
Ivens da Silva Portugal, Paulo Alencar, and Donald Cowan. 2026. Agentic Recommender Systems: A Systematic Literature Review.IEEE Transactions on Software Engineering(2026)
2026
-
[35]
Sunhao Dai, Chen Xu, Shicheng Xu, Liang Pang, Zhenhua Dong, and Jun Xu. 2024. Bias and unfairness in information retrieval systems: New challenges in the llm era. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 6437–6447
2024
- [36]
- [37]
-
[38]
Badhan Chandra Das, M Hadi Amini, and Yanzhao Wu. 2025. Security and privacy challenges of large language models: A survey.Comput. Surveys 57, 6 (2025), 1–39
2025
-
[39]
Yashar Deldjoo. 2024. Understanding biases in ChatGPT-based recommender systems: Provider fairness, temporal stability, and recency.ACM Transactions on Recommender Systems(2024)
2024
-
[40]
Yashar Deldjoo and Tommaso Di Noia. 2025. Cfairllm: Consumer fairness evaluation in large-language model recommender system.ACM Transactions on Intelligent Systems and Technology(2025)
2025
-
[41]
Yashar Deldjoo, Nikhil Mehta, Maheswaran Sathiamoorthy, Shuai Zhang, Pablo Castells, and Julian McAuley. 2025. Toward Holistic Evaluation of Recommender Systems Powered by Generative Models. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3932–3942
2025
- [42]
-
[43]
Jiaxin Deng, Shiyao Wang, Kuo Cai, Lejian Ren, Qigen Hu, Weifeng Ding, Qiang Luo, and Guorui Zhou. 2025. Onerec: Unifying retrieve and rank with generative recommender and iterative preference alignment.arXiv preprint arXiv:2502.18965(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Dario Di Palma. 2023. Retrieval-augmented recommender system: Enhancing recommender systems with large language models. InProceedings of the 17th ACM Conference on Recommender Systems. 1369–1373
2023
- [45]
- [46]
-
[47]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. 2024. Improving factuality and reasoning in language models through multiagent debate. InForty-first international conference on machine learning
2024
- [48]
-
[49]
Qamar EL Maazouzi, Asmaâ Retbi, and Samir Bennani. 2024. Optimizing Recommendation Systems in E-Learning: Synergistic Integration of Lang Chain, GPT Models, and Retrieval Augmented Generation (RAG). InInternational Conference on Smart Applications and Data Analysis. Springer, 106–118. Manuscript submitted to ACM Trustworthy Recommendation in the Era of La...
2024
-
[50]
Chenxiao Fan, Chongming Gao, Yaxin Gong, Haoyan Liu, Fuli Feng, and Xiangnan He. 2026. Uncertainty-aware Generative Recommendation. arXiv preprint arXiv:2602.11719(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[51]
Chenxiao Fan, Chongming Gao, Wentao Shi, Yaxin Gong, Zihao Zhao, and Fuli Feng. 2025. Fine-grained List-wise Alignment for Generative Medication Recommendation.arXiv preprint arXiv:2505.20218(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [52]
-
[53]
Shanshan Feng, Haoming Lyu, Fan Li, Zhu Sun, and Caishun Chen. 2024. Where to move next: Zero-shot generalization of llms for next poi recommendation. In2024 IEEE Conference on Artificial Intelligence (CAI). IEEE, 1530–1535
2024
-
[54]
Miriam Fernandez and Alejandro Bellogin. 2020. Recommender Systems and Misinformation: The Problem or the Solution?. InOHARS Workshop. 14th ACM Conference on Recommender Systems. OHARS Workshop. 14th ACM Conference on Recommender Systems. https://oro.open.ac.uk/72186/ Conference Website: https://recsys.acm.org/ Workshop Website: https://ohars-recsys2020.i...
2020
- [55]
- [56]
-
[57]
Isabel O Gallegos, Ryan A Rossi, Joe Barrow, Md Mehrab Tanjim, Sungchul Kim, Franck Dernoncourt, Tong Yu, Ruiyi Zhang, and Nesreen K Ahmed. 2024. Bias and fairness in large language models: A survey.Computational Linguistics50, 3 (2024), 1097–1179
2024
-
[58]
Chongming Gao, Ruijun Chen, Shuai Yuan, Kexin Huang, Yuanqing Yu, and Xiangnan He. 2025. Sprec: Self-play to debias llm-based recommendation. InProceedings of the ACM on Web Conference 2025. 5075–5084
2025
-
[59]
Chongming Gao, Mengyao Gao, Chenxiao Fan, Shuai Yuan, Wentao Shi, and Xiangnan He. 2025. Process-supervised llm recommenders via flow-guided tuning. InProceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1934–1943
2025
-
[60]
Chongming Gao, Wenqiang Lei, Xiangnan He, Maarten De Rijke, and Tat-Seng Chua. 2021. Advances and challenges in conversational recommender systems: A survey.AI open2 (2021), 100–126
2021
- [61]
- [62]
- [63]
-
[64]
Yingqiang Ge, Shuchang Liu, Zuohui Fu, Juntao Tan, Zelong Li, Shuyuan Xu, Yunqi Li, Yikun Xian, and Yongfeng Zhang. 2024. A survey on trustworthy recommender systems.ACM Transactions on Recommender Systems3, 2 (2024), 1–68
2024
-
[65]
Yingqiang Ge, Shuya Zhao, Honglu Zhou, Changhua Pei, Fei Sun, Wenwu Ou, and Yongfeng Zhang. 2020. Understanding echo chambers in e-commerce recommender systems. InProceedings of the 43rd international ACM SIGIR conference on research and development in information retrieval. 2261–2270
2020
-
[66]
Shijie Geng, Zuohui Fu, Juntao Tan, Yingqiang Ge, Gerard De Melo, and Yongfeng Zhang. 2022. Path language modeling over knowledge graphsfor explainable recommendation. InProceedings of the ACM web conference 2022. 946–955
2022
-
[67]
Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (rlp): A unified pretrain, personalized prompt & predict paradigm (p5). InProceedings of the 16th ACM conference on recommender systems. 299–315
2022
- [68]
-
[69]
Yuqi Gong, Xichen Ding, Yehui Su, Kaiming Shen, Zhongyi Liu, and Guannan Zhang. 2023. An unified search and recommendation foundation model for cold-start scenario. InProceedings of the 32nd ACM International Conference on Information and Knowledge Management. 4595–4601
2023
-
[70]
Yaxin Gong, Chongming Gao, Chenxiao Fan, Wenjie Wang, Fuli Feng, and Xiangnan He. 2026. Breaking User-Centric Agency: A Tri-Party Framework for Agent-Based Recommendation.arXiv preprint arXiv:2603.10673(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [71]
-
[72]
Ihsan Gunes, Cihan Kaleli, Alper Bilge, and Huseyin Polat. 2014. Shilling attacks against recommender systems: a comprehensive survey.Artificial Intelligence Review42, 4 (2014), 767–799
2014
-
[73]
Deepesh V Hada and Shirish K Shevade. 2021. Rexplug: Explainable recommendation using plug-and-play language model. InProceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 81–91
2021
-
[74]
F Maxwell Harper and Joseph A Konstan. 2015. The movielens datasets: History and context.Acm transactions on interactive intelligent systems (tiis)5, 4 (2015), 1–19
2015
-
[75]
Matthew J Hausknecht and Peter Stone. 2015. Deep Recurrent Q-Learning for Partially Observable MDPs.. InAAAI fall symposia, Vol. 45. 141
2015
-
[76]
Shirley Anugrah Hayati, Dongyeop Kang, Qingxiaoyang Zhu, Weiyan Shi, and Zhou Yu. 2020. Inspired: Toward sociable recommendation dialog systems. InProceedings of the 2020 conference on empirical methods in natural language processing (EMNLP). 8142–8152
2020
-
[77]
Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang, and Meng Wang. 2020. Lightgcn: Simplifying and powering graph convolution network for recommendation. InProceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. Manuscript submitted to ACM 38 Bohao Wang et al. 639–648
2020
-
[78]
Diana C Hernandez-Bocanegra, Tim Donkers, and Jürgen Ziegler. 2020. Effects of argumentative explanation types on the perception of review-based recommendations. InAdjunct Publication of the 28th ACM Conference on User Modeling, Adaptation and Personalization. 219–225
2020
-
[79]
Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. 2015. Session-based recommendations with recurrent neural networks.arXiv preprint arXiv:1511.06939(2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[80]
Minjie Hong, Yan Xia, Zehan Wang, Jieming Zhu, Ye Wang, Sihang Cai, Xiaoda Yang, Quanyu Dai, Zhenhua Dong, Zhimeng Zhang, et al. 2025. EAGER-LLM: Enhancing Large Language Models as Recommenders through Exogenous Behavior-Semantic Integration. InProceedings of the ACM on Web Conference 2025. 2754–2762
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.