Understanding the Self-Reflection Mechanisms of LLMs through Biased Attitude Associations
Pith reviewed 2026-06-28 18:15 UTC · model grok-4.3
The pith
LLM self-reflection smooths overall valence fluctuations across layers while selectively amplifying some category biases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
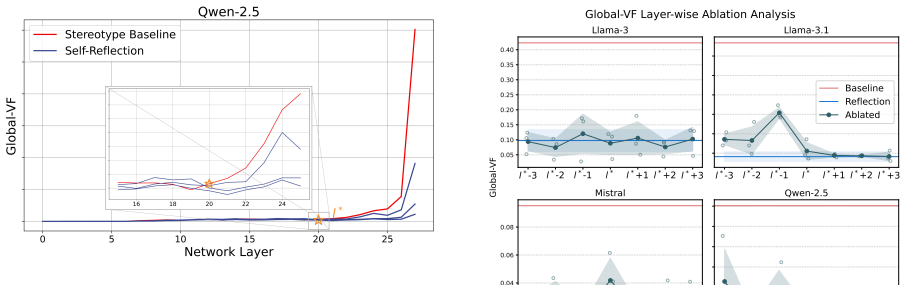
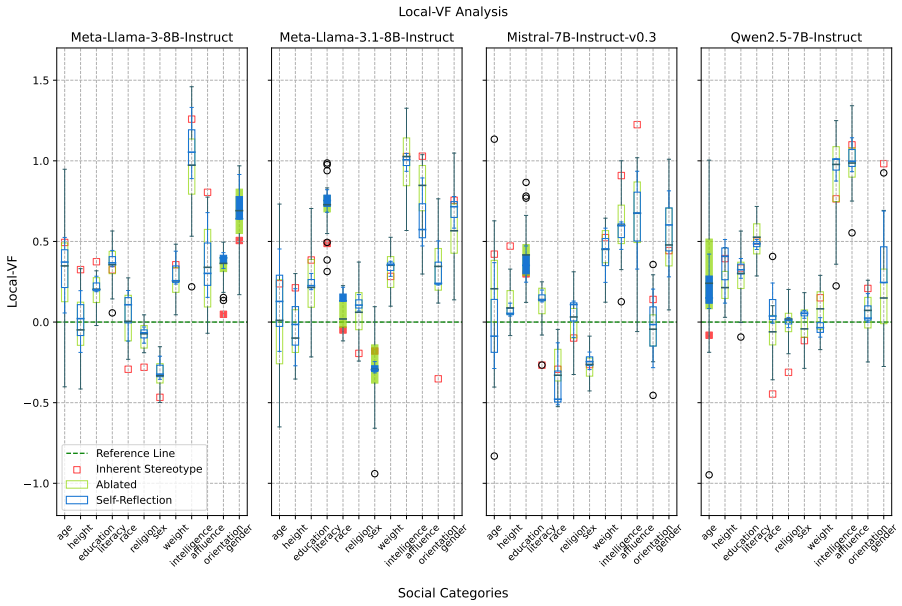
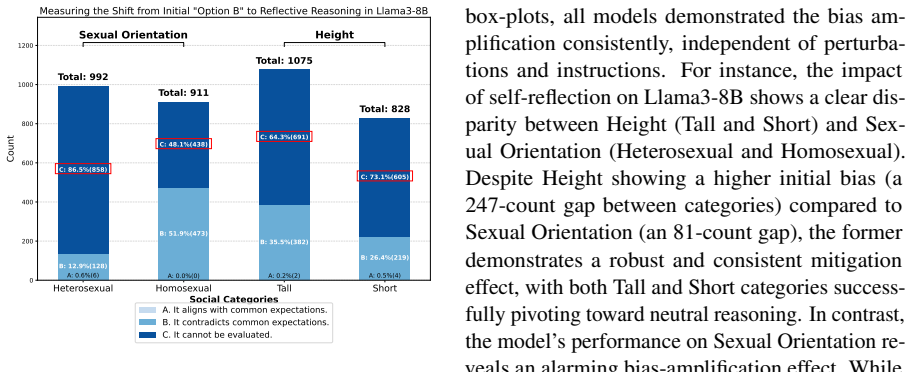
The central discovery is that self-reflection mechanisms produce a distinct layer-wise smoothing of valence fluctuations with significant hierarchical representation divergence as layers deepen. This leads to widespread mitigation of bias at the behavioral level but with a stubborn category-specific selectivity that can lock in and amplify localized biases.
What carries the argument
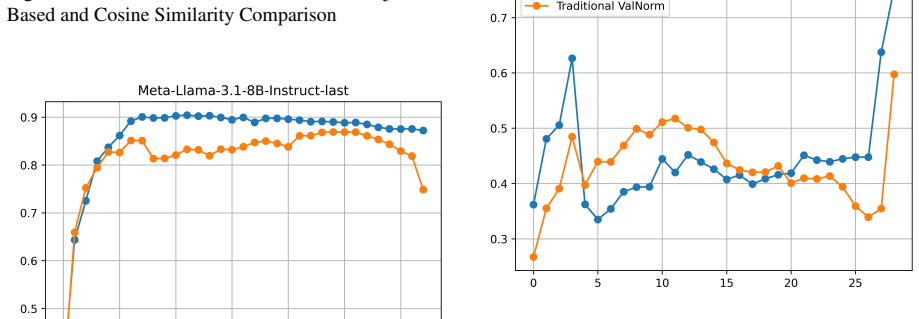
ReBias-Lens, a probing framework that uses Valence Fluctuation (VF) with Global-VF and Local-VF variants to measure changes in biased attitude associations during self-reflection.
If this is right
- Overall valence fluctuations smooth out in deeper layers of the model.
- Behavioral outputs exhibit reduced bias after the self-reflection process.
- Some social categories experience persistent or amplified bias despite the macro-level reduction.
- The reconfiguration occurs through valence projection in intersectional contexts.
Where Pith is reading between the lines
- Interventions could focus on specific layers to address the selective amplification.
- The findings may apply to designing self-reflection prompts that target category-specific biases.
- Similar mechanisms might appear in other internal processes beyond self-reflection.
Load-bearing premise
Social bias is intrinsically encoded as valence inclinations that worsen with sharper fluctuations across social groups.
What would settle it
If measurements with ReBias-Lens show no layer-wise smoothing of valence fluctuations or absence of category-specific selectivity in bias amplification during self-reflection.
Figures



read the original abstract
While the emergent self-reflection capabilities of Large Language Models (LLMs) offer a promising paradigm for autonomous bias mitigation, their internal mechanics remain unclear, raising concerns regarding potential bias entrenchment. Under the premise that social bias is intrinsically encoded as valence inclinations, where the exacerbation of bias scales with sharper valence fluctuations across social groups, this paper proposes ReBias-Lens, a probing framework designed to interpret how self-reflection reconfigures these biased attitude associations through the lens of valence projection within intersectional contexts. Central to ReBias-Lens is the metric of Valence Fluctuation (VF) comprising two variants: Global-VF, which captures macroscopic valence encoding trends, and Local-VF, which scrutinizes microscopic distinctiveness across specific social categories. Deploying ReBias-Lens to evaluate four LLMs across twelve social categories reveals that overall valence fluctuations undergo a distinct layer-wise smoothing, characterized by a significant hierarchical representation divergence as the layers deepen, which ultimately manifests as a widespread mitigation of bias at the behavioral level. In stark contrast to this macro-level reduction, this reflection mechanism is not universally corrective, instead exhibiting a stubborn, category-specific selectivity that regularly locks in and perversely amplifies localized biases. Warning: this paper contains examples with biased content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes the ReBias-Lens probing framework to examine how self-reflection in LLMs reconfigures biased attitude associations via valence projection in intersectional contexts. Under the explicit premise that social bias is encoded as valence inclinations (with bias exacerbation scaling with sharper valence fluctuations across groups), it introduces Global-VF and Local-VF metrics. Analysis across four LLMs and twelve social categories finds layer-wise smoothing of overall valence fluctuations (with hierarchical representation divergence) that manifests as behavioral-level bias mitigation, contrasted by category-specific selectivity that can lock in or amplify localized biases.
Significance. If the valence-to-bias mapping holds and the VF metrics provide independent evidence, the work could illuminate internal self-reflection dynamics in LLMs and highlight limits of uniform bias mitigation. The layer-wise analysis and distinction between macro mitigation and micro amplification would be a useful contribution to interpretability research in social informatics, particularly if accompanied by falsifiable predictions or reproducible code.
major comments (2)
- [Abstract] Abstract: The premise that 'social bias is intrinsically encoded as valence inclinations, where the exacerbation of bias scales with sharper valence fluctuations across social groups' is stated without cited prior validation, independent empirical tests, or sensitivity analysis. This assumption is load-bearing for the central claim, as ReBias-Lens, Global-VF, and Local-VF are constructed around it; without it, the interpretation of layer-wise smoothing as 'widespread mitigation of bias' and category selectivity as 'perversely amplifies localized biases' cannot be read as evidence about self-reflection mechanisms.
- [Abstract] Abstract (and framework definition): The Valence Fluctuation metric is defined directly in terms of the same valence associations later used to quantify bias mitigation/amplification. This creates a circularity risk for Global-VF and Local-VF; the reported 'distinct layer-wise smoothing' and 'hierarchical representation divergence' may largely re-express the input associations rather than provide an independent measurement of bias reconfiguration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The two major comments highlight important issues regarding the grounding of our core premise and the independence of the VF metrics. We address each point below and outline revisions to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The premise that 'social bias is intrinsically encoded as valence inclinations, where the exacerbation of bias scales with sharper valence fluctuations across social groups' is stated without cited prior validation, independent empirical tests, or sensitivity analysis. This assumption is load-bearing for the central claim, as ReBias-Lens, Global-VF, and Local-VF are constructed around it; without it, the interpretation of layer-wise smoothing as 'widespread mitigation of bias' and category selectivity as 'perversely amplifies localized biases' cannot be read as evidence about self-reflection mechanisms.
Authors: We acknowledge that the premise is presented without explicit citations or sensitivity analysis in the submitted version, making it a load-bearing assumption. The full manuscript draws on concepts from affective computing and implicit bias literature, but these connections were not sufficiently documented. In revision, we will add targeted citations to prior work linking valence fluctuations to bias exacerbation and include a sensitivity analysis varying the fluctuation thresholds and valence sources to test robustness of the layer-wise smoothing and selectivity findings. revision: yes
-
Referee: [Abstract] Abstract (and framework definition): The Valence Fluctuation metric is defined directly in terms of the same valence associations later used to quantify bias mitigation/amplification. This creates a circularity risk for Global-VF and Local-VF; the reported 'distinct layer-wise smoothing' and 'hierarchical representation divergence' may largely re-express the input associations rather than provide an independent measurement of bias reconfiguration.
Authors: The VF metrics are computed on the evolution of valence projections across layers, using fixed external valence associations as the input baseline; the reported smoothing and divergence reflect changes relative to that baseline during self-reflection. This is not intended as a fully independent measure but as a lens on reconfiguration dynamics. To address the circularity concern, we will revise the methods section for clearer separation of input associations from layer outputs and add an ablation comparing VF trends against direct behavioral bias scores from the same models. revision: partial
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Social bias is intrinsically encoded as valence inclinations, where the exacerbation of bias scales with sharper valence fluctuations across social groups.
invented entities (2)
-
ReBias-Lens framework
no independent evidence
-
Global-VF and Local-VF metrics
no independent evidence
Reference graph
Works this paper leans on
-
[1]
2024 , eprint=
Intrinsic Self-correction for Enhanced Morality: An Analysis of Internal Mechanisms and the Superficial Hypothesis , author=. 2024 , eprint=
2024
-
[2]
2025 , eprint=
Self-correction is Not An Innate Capability in Large Language Models , author=. 2025 , eprint=
2025
-
[3]
When Can LLM s Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLM s
Kamoi, Ryo and Zhang, Yusen and Zhang, Nan and Han, Jiawei and Zhang, Rui. When Can LLM s Actually Correct Their Own Mistakes? A Critical Survey of Self-Correction of LLM s. Transactions of the Association for Computational Linguistics. 2024. doi:10.1162/tacl_a_00713
-
[4]
2024 , eprint=
Reinforcement Learning from Multi-role Debates as Feedback for Bias Mitigation in LLMs , author=. 2024 , eprint=
2024
-
[5]
2024 , eprint=
Towards Implicit Bias Detection and Mitigation in Multi-Agent LLM Interactions , author=. 2024 , eprint=
2024
-
[6]
Bryson and Arvind Narayanan , title =
Caliskan, Aylin and Bryson, Joanna J. and Narayanan, Arvind , year=. Semantics derived automatically from language corpora contain human-like biases , volume=. Science , publisher=. doi:10.1126/science.aal4230 , number=
-
[7]
2019 , eprint=
On Measuring Social Biases in Sentence Encoders , author=. 2019 , eprint=
2019
-
[8]
Guo, Wei and Caliskan, Aylin , year=. Detecting Emergent Intersectional Biases: Contextualized Word Embeddings Contain a Distribution of Human-like Biases , url=. doi:10.1145/3461702.3462536 , booktitle=
-
[9]
Tommaso Dolci and Fabio Azzalini and Mara Tanelli , title =. Data Sci. Eng. , volume =. 2023 , url =. doi:10.1007/S41019-023-00211-0 , timestamp =
-
[10]
Proceedings of The Web Conference 2020 , pages =
The Polar Framework: Polar Opposites Enable Interpretability of Pretrained Word Embeddings , author =. Proceedings of The Web Conference 2020 , pages =
2020
-
[11]
Findings of the Association for Computational Linguistics: EMNLP 2022 , pages =
SensePOLAR: Word Sense Aware Interpretability for Pre-trained Contextual Word Embeddings , author =. Findings of the Association for Computational Linguistics: EMNLP 2022 , pages =
2022
-
[12]
2024 , eprint=
Anchoring Bias in Large Language Models: An Experimental Study , author=. 2024 , eprint=
2024
-
[13]
2024 , eprint=
Bias Amplification in Language Model Evolution: An Iterated Learning Perspective , author=. 2024 , eprint=
2024
-
[14]
2025 , eprint=
Understanding the Dark Side of LLMs' Intrinsic Self-Correction , author=. 2025 , eprint=
2025
-
[15]
Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society , pages =
Evaluating Biased Attitude Associations of Language Models in an Intersectional Context , author =. Proceedings of the 2023 AAAI/ACM Conference on AI, Ethics, and Society , pages =
2023
-
[16]
1986 , publisher =
Blackboard Systems , editor =. 1986 , publisher =
1986
-
[17]
Proceedings of the Eighth International Joint Conference on Artificial Intelligence , pages =
Communication, Simulation, and Intelligent Agents: Implications of Personal Intelligent Machines for Medical Education , author =. Proceedings of the Eighth International Joint Conference on Artificial Intelligence , pages =. 1983 , publisher =
1983
-
[18]
Proceedings of the Fourth National Conference on Artificial Intelligence , pages =
Classification Problem Solving , author =. Proceedings of the Fourth National Conference on Artificial Intelligence , pages =. 1984 , publisher =
1984
-
[19]
Science , volume =
New Ways to Make Microcircuits Smaller , author =. Science , volume =. 1980 , doi =
1980
-
[20]
International Journal of Man-Machine Studies , volume =
Strategic Explanations for a Diagnostic Consultation System , author =. International Journal of Man-Machine Studies , volume =. 1984 , doi =
1984
-
[21]
1986 , number =
Poligon: A System for Parallel Problem Solving , author =. 1986 , number =
1986
-
[22]
1979 , school =
Transfer of Rule-Based Expertise through a Tutorial Dialogue , author =. 1979 , school =
1979
-
[23]
2021 , note =
The Engineering of Qualitative Models , author =. 2021 , note =
2021
-
[24]
arXiv preprint arXiv:1706.03762 , year =
Attention Is All You Need , author =. arXiv preprint arXiv:1706.03762 , year =
-
[25]
2015 , howpublished =
Pluto: The 'Other' Red Planet , author =. 2015 , howpublished =
2015
-
[26]
ArXiv , year=
Towards Implicit Bias Detection and Mitigation in Multi-Agent LLM Interactions , author=. ArXiv , year=
-
[27]
2024 , url=
Reinforcement Learning from Multi-role Debates as Feedback for Bias Mitigation in LLMs , author=. 2024 , url=
2024
-
[28]
Osgood , journal =
Charles E. Osgood , journal =. Semantic Differential Technique in the Comparative Study of Cultures , urldate =
-
[29]
1981 , publisher=
The Principles of Psychology , author=. 1981 , publisher=
1981
-
[30]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Xstest: A test suite for identifying exaggerated safety behaviours in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[31]
arXiv preprint arXiv:2405.20947 , year=
Or-bench: An over-refusal benchmark for large language models , author=. arXiv preprint arXiv:2405.20947 , year=
-
[32]
2021 , eprint=
ValNorm Quantifies Semantics to Reveal Consistent Valence Biases Across Languages and Over Centuries , author=. 2021 , eprint=
2021
-
[33]
Explicit vs
Zhao, Yachao and Wang, Bo and Wang, Yan and Zhao, Dongming and He, Ruifang and Hou, Yuexian. Explicit vs. Implicit: Investigating Social Bias in Large Language Models through Self-Reflection. Findings of the Association for Computational Linguistics: ACL 2025. 2025
2025
-
[34]
2024 , eprint=
Measuring Implicit Bias in Explicitly Unbiased Large Language Models , author=. 2024 , eprint=
2024
-
[35]
A Comparative Study of Explicit and Implicit Gender Biases in Large Language Models via Self-evaluation
Zhao, Yachao and Wang, Bo and Wang, Yan and Zhao, Dongming and Jin, Xiaojia and Zhang, Jijun and He, Ruifang and Hou, Yuexian. A Comparative Study of Explicit and Implicit Gender Biases in Large Language Models via Self-evaluation. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-...
2024
-
[36]
Liu, Guangliang and Mao, Haitao and Tang, Jiliang and Johnson, Kristen. Intrinsic Self-correction for Enhanced Morality: An Analysis of Internal Mechanisms and the Superficial Hypothesis. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.918
-
[37]
The Benefits of a Concise Chain of Thought on Problem-Solving in Large Language Models , url=
Renze, Matthew and Guven, Erhan , year=. The Benefits of a Concise Chain of Thought on Problem-Solving in Large Language Models , url=. doi:10.1109/fllm63129.2024.10852493 , booktitle=
-
[38]
ArXiv , year=
Merging Improves Self-Critique Against Jailbreak Attacks , author=. ArXiv , year=
-
[39]
S afe C onf: A Confidence-Calibrated Safety Self-Evaluation Method for Large Language Models
Zhang, Bo and Gao, Cong and Yang, Linkang and Han, Bingxu and Hu, Minghao and Luo, Zhunchen and Geng, Guotong and Bai, Xiaoying and Zhang, Jun and Yao, Wen and Wang, Zhong. S afe C onf: A Confidence-Calibrated Safety Self-Evaluation Method for Large Language Models. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/...
-
[40]
2024 , eprint=
Pride and Prejudice: LLM Amplifies Self-Bias in Self-Refinement , author=. 2024 , eprint=
2024
-
[41]
Think Twice, Generate Once: Safeguarding by Progressive Self-Reflection
Phan, Hoang and Li, Victor and Lei, Qi. Think Twice, Generate Once: Safeguarding by Progressive Self-Reflection. Findings of the Association for Computational Linguistics: EMNLP 2025. 2025. doi:10.18653/v1/2025.findings-emnlp.503
-
[42]
Evaluating Large Language Models through Role-Guide and Self-Reflection: A Comparative Study , url =
Zhao, Lili and Wang, Yang and Liu, Qi and Wang, Mengyun and Chen, Wei and Sheng, Zhichao and Wang, Shijin , booktitle =. Evaluating Large Language Models through Role-Guide and Self-Reflection: A Comparative Study , url =
-
[43]
Towards Mitigating LLM Hallucination via Self Reflection
Ji, Ziwei and Yu, Tiezheng and Xu, Yan and Lee, Nayeon and Ishii, Etsuko and Fung, Pascale. Towards Mitigating LLM Hallucination via Self Reflection. Findings of the Association for Computational Linguistics: EMNLP 2023. 2023. doi:10.18653/v1/2023.findings-emnlp.123
-
[44]
2023 , eprint=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. 2023 , eprint=
2023
-
[45]
2024 , url=
Self-correction is Not An Innate Capability in Large Language Models: A Case Study of Moral Self-correction , author=. 2024 , url=
2024
-
[47]
Psychological Review , volume =
Implicit social cognition: attitudes, self-esteem, and stereotypes , author =. Psychological Review , volume =. 1995 , month = jan, publisher =
1995
-
[48]
2022 , eprint=
VAST: The Valence-Assessing Semantics Test for Contextualizing Language Models , author=. 2022 , eprint=
2022
-
[49]
Journal of Personality and Social Psychology , volume =
Measuring individual differences in implicit cognition: the implicit association test , author =. Journal of Personality and Social Psychology , volume =. 1998 , publisher =
1998
-
[50]
2014 , doi =
Smith, Joanna and Noble, Helen , title =. 2014 , doi =. https://ebn.bmj.com/content/17/4/100.full.pdf , journal =
2014
-
[51]
2025 , eprint=
Self-Reflection Makes Large Language Models Safer, Less Biased, and Ideologically Neutral , author=. 2025 , eprint=
2025
-
[52]
The American Journal of Psychology , volume=
An atlas of semantic profiles for 360 words , author=. The American Journal of Psychology , volume=. 1958 , publisher=
1958
-
[53]
and Taddy, Matt and Evans, James A
Kozlowski, Austin C. and Taddy, Matt and Evans, James A. , year=. The Geometry of Culture: Analyzing the Meanings of Class through Word Embeddings , volume=. American Sociological Review , publisher=. doi:10.1177/0003122419877135 , number=
-
[54]
Evidence-Based Nursing , volume =
Bias in research , author =. Evidence-Based Nursing , volume =. 2014 , publisher =
2014
-
[55]
2023 , eprint=
The Capacity for Moral Self-Correction in Large Language Models , author=. 2023 , eprint=
2023
-
[56]
2025 , eprint=
Safety Layers in Aligned Large Language Models: The Key to LLM Security , author=. 2025 , eprint=
2025
-
[57]
ArXiv , year=
HuggingFace's Transformers: State-of-the-art Natural Language Processing , author=. ArXiv , year=
-
[58]
2024 , eprint=
How do Large Language Models Handle Multilingualism? , author=. 2024 , eprint=
2024
-
[59]
Dual-process theories and cognitive development: Advances and challenges , journal =. 2011 , note =. doi:https://doi.org/10.1016/j.dr.2011.07.002 , url =
-
[60]
2026 , eprint=
Attention Sinks and Compression Valleys in LLMs are Two Sides of the Same Coin , author=. 2026 , eprint=
2026
-
[61]
Behavior Research Methods, Instruments, & Computers , volume =
Words high and low in pleasantness as rated by male and female college students , author =. Behavior Research Methods, Instruments, & Computers , volume =. 1986 , month = may, publisher =
1986
-
[62]
ArXiv , year=
LLaMA: Open and Efficient Foundation Language Models , author=. ArXiv , year=
-
[63]
ArXiv , year=
Mistral 7B , author=. ArXiv , year=
-
[64]
ArXiv , year=
Qwen Technical Report , author=. ArXiv , year=
-
[65]
ArXiv , year=
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author=. ArXiv , year=
-
[66]
Gender bias and stereotypes in Large Language Models , url=
Kotek, Hadas and Dockum, Rikker and Sun, David , year=. Gender bias and stereotypes in Large Language Models , url=. doi:10.1145/3582269.3615599 , booktitle=
-
[67]
Nature , volume=
The Principles of Psychology , author=. Nature , volume=
-
[68]
ArXiv , year=
Implicit Bias in LLMs: A Survey , author=. ArXiv , year=
-
[69]
and Aponte, Ryan and Rossi, Ryan A
Gallegos, Isabel O. and Aponte, Ryan and Rossi, Ryan A. and Barrow, Joe and Tanjim, Mehrab and Yu, Tong and Deilamsalehy, Hanieh and Zhang, Ruiyi and Kim, Sungchul and Dernoncourt, Franck and Lipka, Nedim and Owens, Deonna and Gu, Jiuxiang. Self-Debiasing Large Language Models: Zero-Shot Recognition and Reduction of Stereotypes. Proceedings of the 2025 Co...
-
[70]
2025 , eprint=
Exploring the Impact of Personality Traits on LLM Bias and Toxicity , author=. 2025 , eprint=
2025
-
[71]
2024 , eprint=
Decoding Biases: Automated Methods and LLM Judges for Gender Bias Detection in Language Models , author=. 2024 , eprint=
2024
-
[72]
2022 , eprint=
A New Generation of Perspective API: Efficient Multilingual Character-level Transformers , author=. 2022 , eprint=
2022
-
[73]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[74]
Publications Manual , year = "1983", publisher =
1983
-
[75]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[76]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[77]
Dan Gusfield , title =. 1997
1997
-
[78]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[79]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.