SCOPE: Cost-Efficient Model Selection for Compound AI Systems under Quality Constraints
Pith reviewed 2026-06-28 17:53 UTC · model grok-4.3
The pith
SCOPE selects LLM assignments for compound AI systems that minimize average cost while meeting a user-specified quality threshold, with theoretical guarantees.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SCOPE is an optimization algorithm that exploits per-query results to rapidly estimate a compound system's cost and quality, constructs confidence bounds from those results to guide the search over LLM combinations, and supplies theoretical guarantees that the quality threshold will be met while the average cost is near-optimal.
What carries the argument
confidence bounds constructed from per-query results that guide search over LLM assignments while supporting quality and cost guarantees
If this is right
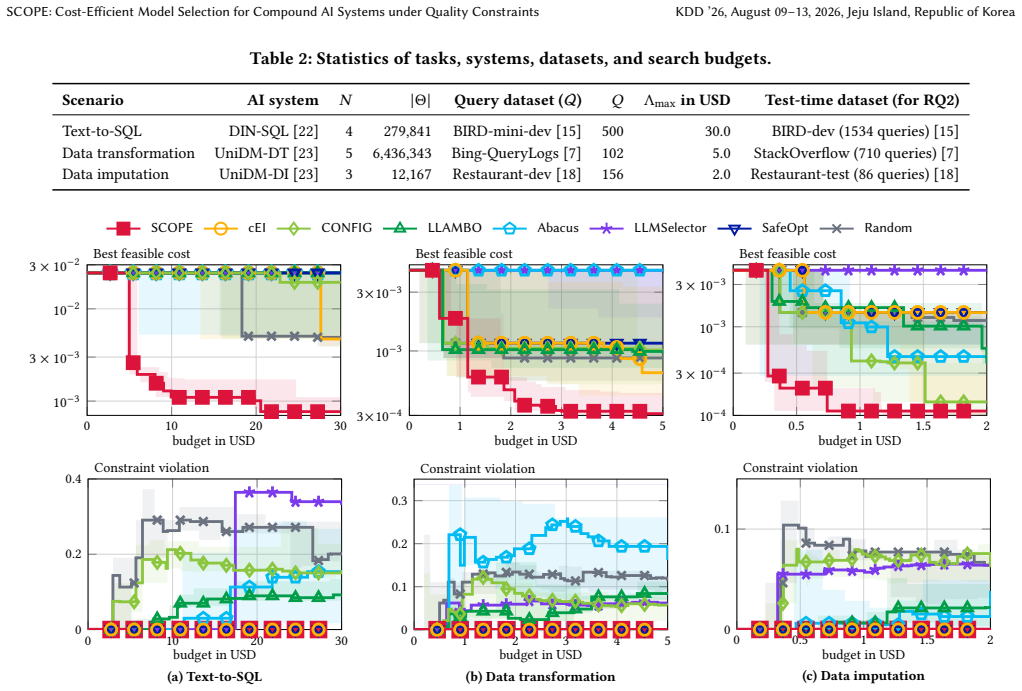
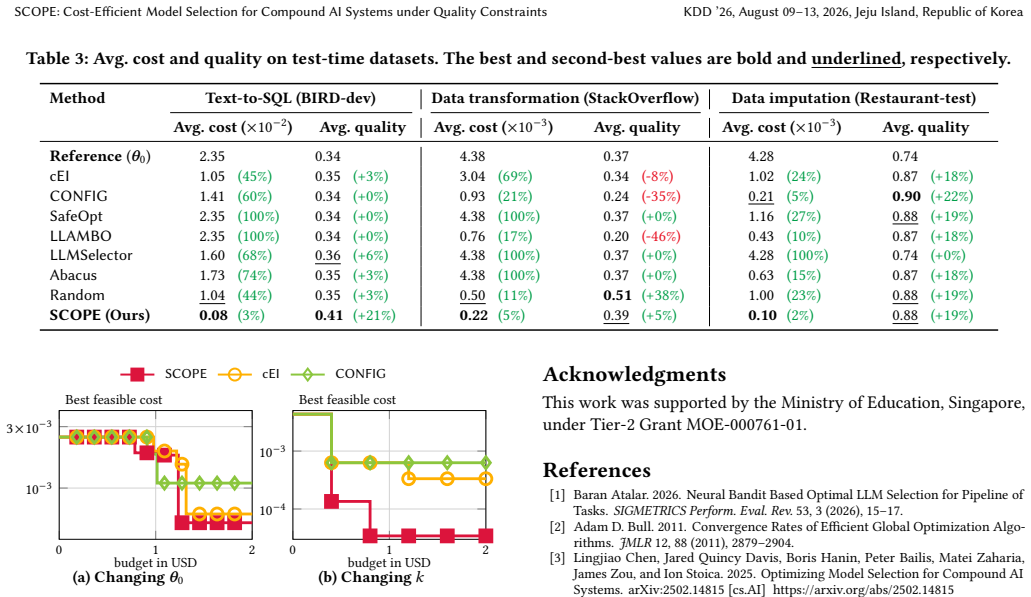
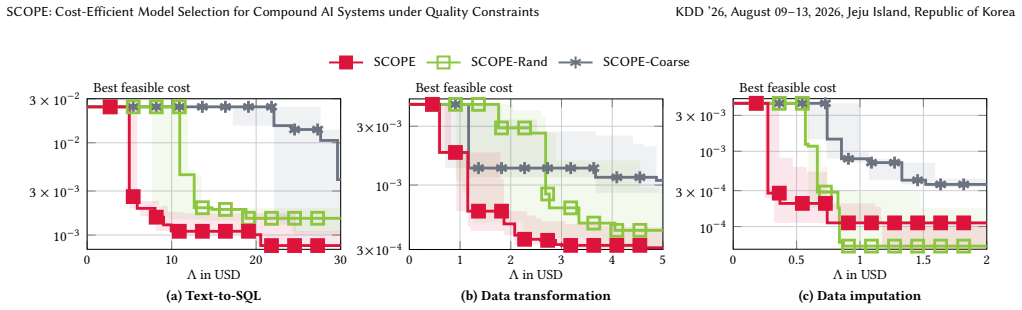
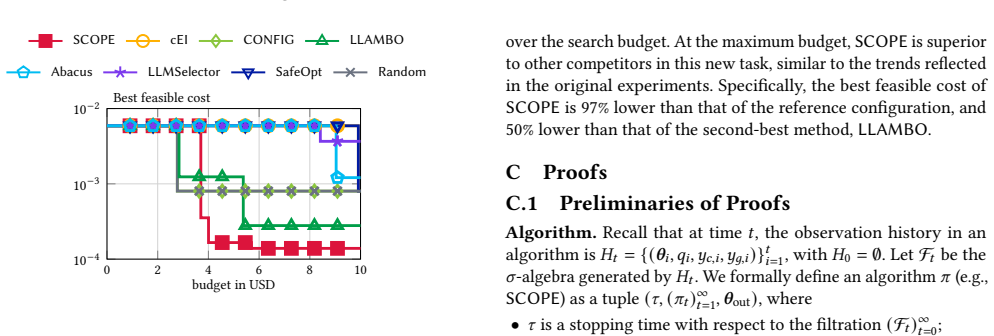
- Under identical search budget and quality constraint, SCOPE returns candidate solutions whose cost during search is up to 20 times lower than the best competing method.
- The final solution returned by SCOPE has up to 6 times lower cost than solutions from prior methods.
- The selected configuration is guaranteed to meet the user quality threshold.
- The returned cost is near-optimal among all configurations that satisfy the quality constraint.
Where Pith is reading between the lines
- The same per-query bounding strategy could be tested on compound pipelines outside data analytics, such as multi-stage reasoning chains.
- If the bounds remain reliable at larger scale, the method would directly lower operating cost for production systems that process thousands of queries per day.
Load-bearing premise
That per-query results suffice to construct reliable confidence bounds that both guide efficient search and support the claimed theoretical guarantees on overall system quality and cost for the target data-processing tasks.
What would settle it
An experiment in which the final selected configuration fails to meet the quality threshold on a large held-out query set, despite the per-query bounds having passed during search.
Figures
read the original abstract
A compound AI system consists of multiple LLM modules, together handling complex and multi-step tasks that exceed the capabilities of a single model. Existing systems often use a single expensive LLM across all modules to improve the result quality of the whole system. However, this configuration incurs prohibitive costs, particularly for data management and analytics tasks at scale, such as data manipulation. To this end, we formalize the problem of constrained LLM selection for compound AI systems, leveraging the diverse pricing and capabilities of different LLMs to achieve competitive quality at lower cost. Given a query dataset and a user-specified quality threshold, we aim to select an LLM for each module to minimize the system's average cost while ensuring that overall quality meets the required threshold. To solve this problem, we propose SCOPE, a cost-efficient optimization algorithm. Unlike existing approaches that rely on expensive dataset-level evaluations, SCOPE exploits per-query results to rapidly estimate the system's cost and quality, and constructs confidence bounds to guide the search for promising LLM combinations. Furthermore, SCOPE provides theoretical guarantees for meeting the quality threshold and achieving near-optimal average cost. We evaluate SCOPE against 7 baselines on three data processing tasks, demonstrating that it outperforms all baselines. Under the same search budget and quality constraint, it finds solutions with up to $20\times$ lower cost than the best competitor during the search and achieves up to $6\times$ lower final cost in the returned solution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the constrained LLM selection problem for compound AI systems, where the goal is to assign an LLM to each module to minimize average cost subject to a quality threshold on a query dataset. It proposes SCOPE, which uses per-query results to estimate cost and quality, constructs confidence bounds to guide search, provides theoretical guarantees on quality and near-optimal cost, and reports empirical results on three data processing tasks against seven baselines with up to 20× lower search cost and 6× lower final cost.
Significance. If the theoretical guarantees are correctly established and the empirical gains are robust to the evaluation methodology, the work could meaningfully advance cost-efficient deployment of compound AI systems for data analytics tasks by enabling mixed-LLM configurations instead of uniform expensive models. The exploitation of per-query results for rapid estimation and the provision of theoretical guarantees are explicit strengths. The stress-test concern on per-query results for reliable confidence bounds does not land as a load-bearing issue in the manuscript.
minor comments (2)
- Abstract: the three data processing tasks and associated datasets are referenced but not described; the full paper should include at least a brief characterization to support the reported gains.
- Abstract: the exact search budget, quality threshold values, and per-task breakdowns for the 20× and 6× claims should be stated explicitly rather than left as 'up to' maxima.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work, the recognition of its strengths in formalization, per-query estimation, confidence bounds, theoretical guarantees, and empirical results on data tasks, and the recommendation for minor revision. We are pleased that the potential stress-test concern on per-query results is not viewed as load-bearing.
Circularity Check
No significant circularity identified
full rationale
The provided abstract and context describe SCOPE as an optimization algorithm that uses per-query results to estimate cost/quality and constructs confidence bounds for search guidance, along with claimed theoretical guarantees on quality thresholds and near-optimal cost. No equations, derivations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes are visible that would reduce any result to its inputs by construction. The central claims rest on algorithmic design and analysis that remain independent of the enumerated circularity patterns. This matches the reader's assessment of no visible reduction in the abstract, yielding a self-contained derivation with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Per-query results can be aggregated via confidence bounds to produce reliable estimates of overall system cost and quality that support both optimization and theoretical guarantees.
Reference graph
Works this paper leans on
-
[1]
Baran Atalar. 2026. Neural Bandit Based Optimal LLM Selection for Pipeline of Tasks.SIGMETRICS Perform. Eval. Rev.53, 3 (2026), 15–17
2026
-
[2]
Adam D. Bull. 2011. Convergence Rates of Efficient Global Optimization Algo- rithms.JMLR12, 88 (2011), 2879–2904
2011
- [3]
-
[4]
Lingjiao Chen, Matei Zaharia, and James Zou. 2024. FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance.TMLR (2024)
2024
-
[5]
Zhijun Chen, Jingzheng Li, Pengpeng Chen, Zhuoran Li, Kai Sun, Yuankai Luo, Qianren Mao, Dingqi Yang, Hailong Sun, and Philip S. Yu. 2025. Harnessing Multi- ple Large Language Models: A Survey on LLM Ensemble. arXiv:2502.18036 [cs.CL] https://arxiv.org/abs/2502.18036
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Sayak Ray Chowdhury and Aditya Gopalan. 2017. On kernelized multi-armed bandits. InICML. 844–853
2017
-
[7]
Yeye He, Xu Chu, Kris Ganjam, Yudian Zheng, Vivek Narasayya, and Surajit Chaudhuri. 2018. Transform-data-by-example (TDE): an extensible search engine for data transformations.PVLDB11, 10 (2018), 1165–1177
2018
-
[8]
Zijian He, Reyna Abhyankar, Vikranth Srivatsa, and Yiying Zhang. 2025. Cognify: Supercharging Gen-AI Workflows with Hierarchical Autotuning. InKDD. 932– 943
2025
-
[9]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. 2024. MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework. In ICLR
2024
-
[10]
Keke Huang, Yimin Shi, Dujian Ding, Yifei Li, Yang Fei, Laks Lakshmanan, and Xiaokui Xiao. 2025. ThriftLLM: On Cost-Effective Selection of Large Language Models for Classification Queries.PVLDB18, 11 (2025), 4410–4423
2025
-
[11]
Yiqian Huang, Shiqi Zhang, and Xiaokui Xiao. 2025. KET-RAG: A Cost-Efficient Multi-Granular Indexing Framework for Graph-RAG. InKDD. 1003–1012
2025
-
[12]
Saehan Jo and Immanuel Trummer. 2025. SpareLLM: Automatically Selecting Task-Specific Minimum-Cost Large Language Models under Equivalence Con- straint.PACMMOD3, 3 (2025)
2025
-
[13]
Emilie Kaufmann, Olivier Cappé, and Aurélien Garivier. 2016. On the complexity of best-arm identification in multi-armed bandit models.JMLR17, 1 (2016), 1–42
2016
-
[14]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan A, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
-
[15]
DSPy: Compiling Declarative Language Model Calls into State-of-the-Art Pipelines. InICLR
-
[16]
Chang, Fei Huang, Reynold Cheng, and Yongbin Li
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C.C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM already serve as a database interface? a big bench for large-scale database grounded text-to-SQLs. InNeurIPS
2023
-
[17]
Chunwei Liu, Matthew Russo, Michael Cafarella, Lei Cao, Peter Baile Chen, Zui Chen, Michael Franklin, Tim Kraska, Samuel Madden, Rana Shahout, and Gerardo Vitagliano. 2025. Palimpzest: Optimizing AI-Powered Analytics with Declarative Query Processing. InCIDR. KDD ’26, August 09–13, 2026, Jeju Island, Republic of Korea Yiqian Huang, Shiqi Zhang, Tianyuan J...
2025
-
[18]
Tennison Liu, Nicolás Astorga, Nabeel Seedat, and Mihaela van der Schaar. 2024. Large Language Models to Enhance Bayesian Optimization. InICLR
2024
-
[19]
Yinan Mei, Shaoxu Song, Chenguang Fang, Haifeng Yang, Jingyun Fang, and Jiang Long. 2021. Capturing Semantics for Imputation with Pre-trained Language Models. InICDE. 61–72
2021
-
[20]
George L Nemhauser, Laurence A Wolsey, and Marshall L Fisher. 1978. An analysis of approximations for maximizing submodular set functions—I.Mathematical programming14, 1 (1978), 265–294
1978
-
[21]
2025.Update to GPT-5 System Card: GPT-5.2
OpenAI. 2025.Update to GPT-5 System Card: GPT-5.2. https://cdn.openai.com/ pdf/3a4153c8-c748-4b71-8e31-aecbde944f8d/oai_5_2_system-card.pdf
2025
-
[22]
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. 2024. Optimizing Instructions and Demonstrations for Multi-Stage Language Model Programs. InEMNLP, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). 9340–9366
2024
-
[23]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed in-context learning of text-to-sql with self-correction.NeurIPS36 (2023), 36339– 36348
2023
-
[24]
Yichen Qian, Yongyi He, Rong Zhu, Jintao Huang, Zhijian Ma, Haibin Wang, Yaohua Wang, Xiuyu Sun, Defu Lian, Bolin Ding, et al. 2024. UniDM: A unified framework for data manipulation with large language models.MLSys6 (2024), 465–482
2024
-
[25]
Carl Edward Rasmussen. 2003. Gaussian processes in machine learning. In Summer school on machine learning. 63–71
2003
- [26]
-
[27]
Jasper Snoek, Hugo Larochelle, and Ryan P Adams. 2012. Practical bayesian optimization of machine learning algorithms.NeurIPS25 (2012)
2012
-
[28]
Niranjan Srinivas, Andreas Krause, Sham Kakade, and Matthias Seeger. 2010. Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design. InICML. 1015–1022
2010
-
[29]
Yanan Sui, Alkis Gotovos, Joel Burdick, and Andreas Krause. 2015. Safe Explo- ration for Optimization with Gaussian Processes. InICML, Vol. 37. 997–1005
2015
-
[30]
Haowei Wang, Jingyi Wang, Zhongxiang Dai, Nai-Yuan Chiang, Szu Hui Ng, and Cosmin G. Petra. 2025. Convergence Rates of Constrained Expected Improvement. InNeurIPS
2025
-
[31]
Shuhei Watanabe and Frank Hutter. 2023. c-TPE: Tree-structured Parzen Estima- tor with Inequality Constraints for Expensive Hyperparameter Optimization. In IJCAI. 9 pages
2023
-
[32]
Wenjie Xu, Yuning Jiang, Bratislav Svetozarevic, and Colin Jones. 2023. Con- strained efficient global optimization of expensive black-box functions. InInter- national Conference on Machine Learning. PMLR, 38485–38498
2023
-
[33]
Murong Yue, Jie Zhao, Min Zhang, Liang Du, and Ziyu Yao. 2024. Large Language Model Cascades with Mixture of Thought Representations for Cost-Efficient Reasoning. InICLR
2024
-
[34]
Sepanta Zeighami, Shreya Shankar, and Aditya Parameswaran. 2025. Cut Costs, Not Accuracy: LLM-Powered Data Processing with Guarantees.PACMMOD3, 6 (2025)
2025
-
[35]
Yiqun Zhang, Hao Li, Jianhao Chen, Hangfan Zhang, Peng Ye, Lei Bai, and Shuyue Hu. 2025. Beyond GPT-5: Making LLMs Cheaper and Better via Performance- Efficiency Optimized Routing. InDAI. 122–129
2025
-
[36]
Xingyu Zhou and Bo Ji. 2022. On kernelized multi-armed bandits with constraints. InNeurIPS. A Experiment Details Candidate LLMs.The candidate LLMs used in the experiments are listed in Table 4. The pricing values are obtained from the official OpenAI, Google, Anthropic, and DeepInfra platforms as of the submission date. According to these platforms, the c...
2022
-
[37]
If max1≤𝑠≤𝑛 𝑀𝑠 >𝑥 , then there exists 𝑠∈ [𝑛] such that 𝑀𝑠 >𝑥 , and thus 𝑍𝑠 =exp 𝜆𝑀𝑠 − 𝜆2𝑅2 𝑐 2 𝑠 ≥exp 𝜆𝑥− 𝜆2𝑅2 𝑐 2 𝑛
By Ville’s inequality, for any𝑎>0, Pr max 1≤𝑠≤𝑛 𝑍𝑠 ≥𝑎 ≤ E[𝑍 0] 𝑎 = 1 𝑎 . If max1≤𝑠≤𝑛 𝑀𝑠 >𝑥 , then there exists 𝑠∈ [𝑛] such that 𝑀𝑠 >𝑥 , and thus 𝑍𝑠 =exp 𝜆𝑀𝑠 − 𝜆2𝑅2 𝑐 2 𝑠 ≥exp 𝜆𝑥− 𝜆2𝑅2 𝑐 2 𝑛 . Consequently, Pr max 1≤𝑠≤𝑛 𝑀𝑠 >𝑥 ≤Pr max 1≤𝑠≤𝑛 𝑍𝑠 ≥exp 𝜆𝑥− 𝜆2𝑅2 𝑐 2 𝑛 ≤exp −𝜆𝑥+ 𝜆2𝑅2 𝑐 2 𝑛 . Optimizing over𝜆>0by choosing𝜆=𝑥/(𝑛𝑅 2 𝑐 )gives Pr max 1≤𝑠≤𝑛 𝑀𝑠 >𝑥 ≤exp ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.