Transpose-free linear algebra
Pith reviewed 2026-06-28 16:19 UTC · model grok-4.3
The pith
Without transpose access, forward matrix-vector products leave core problems like least squares non-identifiable and demand at least n queries for rank-k approximations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In the transpose-free setting, the sequence of projected operator norms from Arnoldi can follow any nondecreasing curve, and distinct matrices can generate identical forward-query transcripts while having fundamentally different solutions to least squares, norm estimation, column subset selection, and local maximum volume problems; any algorithm computing a near-optimal rank-k approximation must use at least n queries.
What carries the argument
Non-identifiability results constructed from pairs of distinct matrices that agree on observed forward matvecs but differ in target quantities such as spectral norm or optimal low-rank factors.
If this is right
- Arnoldi iteration yields no reliable information about the spectral norm of the matrix.
- Estimating the Frobenius norm to relative accuracy eps requires Omega(eps^{-2}) queries for large n.
- Some linear algebra problems remain solvable without transpose access, but many core tasks become unidentifiable or inefficient.
- Any near-optimal rank-k approximation algorithm requires at least n forward matvec queries.
Where Pith is reading between the lines
- Applications relying on matrix-free methods without adjoints, such as certain inverse problems, may need to incorporate additional information or accept higher computational costs.
- The distinction between forward-only and full-access settings could guide whether to use transpose-free solvers in specific operator-learning tasks.
- Randomized estimators for norms may still achieve their known rates but cannot overcome the identifiability barrier for exact recovery of other quantities.
Load-bearing premise
There exist distinct matrices that produce identical forward matvec outputs for all queried vectors yet differ in the solutions to the target problems.
What would settle it
An explicit algorithm that computes a near-optimal rank-k approximation using fewer than n forward matvec queries on matrices where the non-identifiability construction applies.
Figures
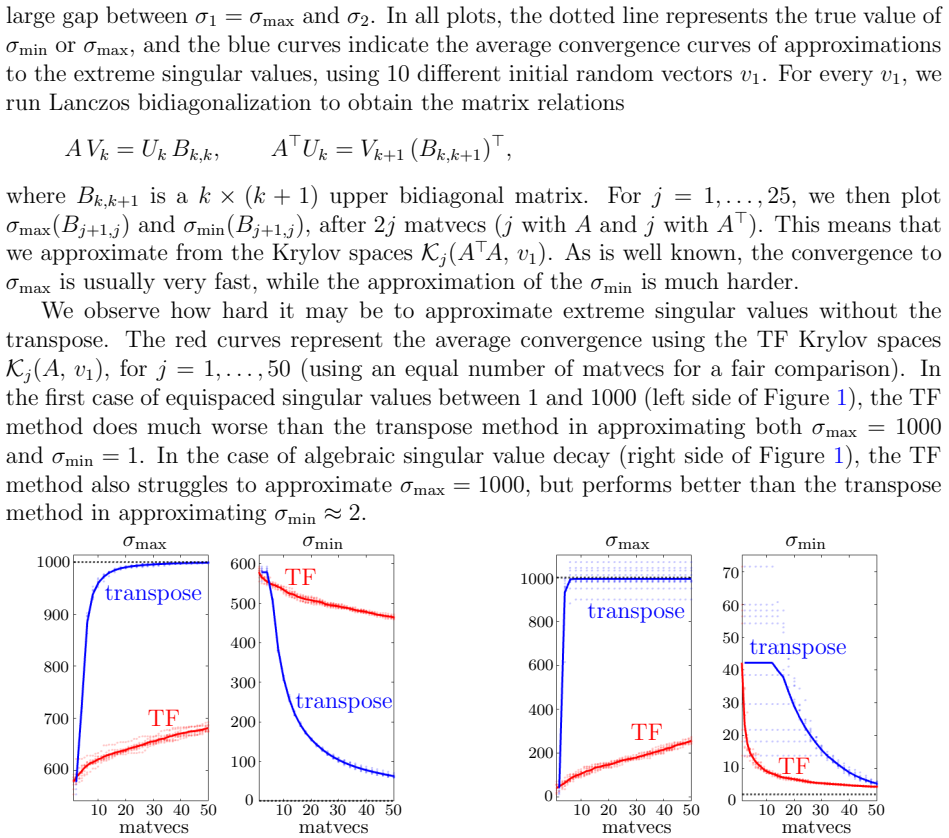
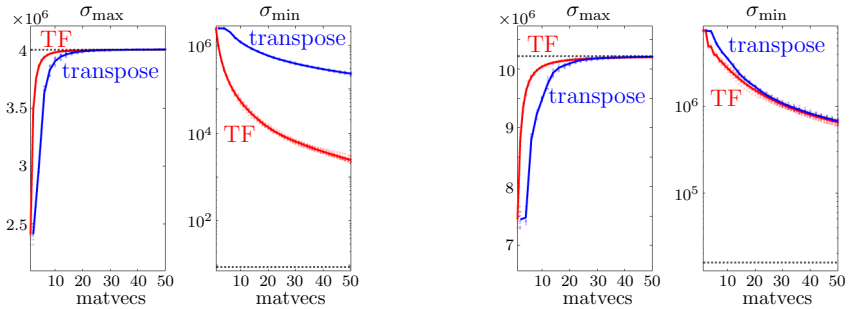
read the original abstract
We study the limitations of matrix-free algorithms that access a matrix $A$ only through forward matrix-vector products (matvecs) $x \mapsto Ax$, without access to the transpose $A^\top$ or its action. This setting arises naturally in operator learning, inverse problems, and matrix-free PDE solvers, where adjoint evaluations may be unavailable or prohibitively expensive. We show that the lack of transpose access creates severe and sometimes insurmountable theoretical barriers. For Krylov methods, we prove that the sequence of projected operator norms produced by Arnoldi iteration can follow any prescribed nondecreasing curve, showing that forward matvecs alone provide essentially no reliable information about the spectral norm. For several core problems, including least squares, norm estimation, column subset selection, and local maximum volume, we establish non-identifiability results; distinct matrices can generate identical forward-query transcripts while having fundamentally different solutions. We also prove quantitative lower bounds on the number of forward matvecs required for approximation tasks. In particular, any algorithm that computes a near-optimal rank-$k$ approximation must use at least $n$ queries, and estimating the Frobenius norm to relative accuracy $\eps$ requires $\Omega(\eps^{-2})$ queries when $n$ is sufficiently large, matching the complexity of Hutchinson-type estimators up to constants. Although some problems remain solvable without transpose access, the transpose-free setting is fundamentally more limited in both identifiability and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies limitations of matrix-free algorithms accessing a matrix only via forward matvecs without transpose access. It proves that Arnoldi iteration projected norms can follow any nondecreasing curve, establishes non-identifiability for least squares, norm estimation, column subset selection and local max-volume problems (distinct matrices yield identical query transcripts but different solutions), and derives quantitative lower bounds including at least n forward matvecs for near-optimal rank-k approximation and Ω(ε^{-2}) queries for relative Frobenius norm estimation to accuracy ε.
Significance. If the lower bounds hold for general (including adaptive) algorithms, the results would be significant for operator learning, inverse problems and matrix-free PDE solvers by establishing fundamental identifiability and query-complexity barriers in the transpose-free setting. Credit is due for deriving all results from standard linear-algebra constructions and query-model arguments with no free parameters, self-referential definitions or invented entities.
major comments (2)
- [Abstract and non-identifiability results] Abstract and the non-identifiability section: the claim that 'any algorithm' computing a near-optimal rank-k approximation requires at least n queries rests on non-identifiability via distinct matrices agreeing on forward-query transcripts. The constructions appear to use a fixed collection of at most n-1 vectors; this does not automatically extend to adaptive algorithms, which could select subsequent vectors to elicit differing responses and distinguish the instances. A minimax or adaptive-adversary argument is needed to close the gap for the stated 'any algorithm' lower bound.
- [Krylov methods section] The Arnoldi-norm result (that projected operator norms can follow any prescribed nondecreasing curve) is invoked to show forward matvecs provide no reliable spectral-norm information. The proof sketch should be checked for whether it holds under the exact arithmetic model used elsewhere or requires additional assumptions on the query model.
minor comments (2)
- [Introduction] Notation for the forward-query transcript and the precise definition of 'near-optimal' rank-k approximation should be introduced earlier and used consistently.
- [Norm estimation section] The Frobenius-norm lower bound is stated to match Hutchinson-type estimators up to constants; an explicit constant comparison or reference to the matching upper bound would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Abstract and non-identifiability results] Abstract and the non-identifiability section: the claim that 'any algorithm' computing a near-optimal rank-k approximation requires at least n queries rests on non-identifiability via distinct matrices agreeing on forward-query transcripts. The constructions appear to use a fixed collection of at most n-1 vectors; this does not automatically extend to adaptive algorithms, which could select subsequent vectors to elicit differing responses and distinguish the instances. A minimax or adaptive-adversary argument is needed to close the gap for the stated 'any algorithm' lower bound.
Authors: We acknowledge the referee's observation on the query model. Our non-identifiability construction for the rank-k approximation lower bound is presented via a fixed collection of vectors. To rigorously support the claim for arbitrary algorithms (including adaptive ones), we will revise the argument by adding an adaptive-adversary construction: for any adaptively chosen sequence of at most n-1 vectors, there exist distinct matrices that produce identical forward matvec responses yet admit different near-optimal rank-k approximations. This minimax-style extension will be incorporated into the revised manuscript. revision: yes
-
Referee: [Krylov methods section] The Arnoldi-norm result (that projected operator norms can follow any prescribed nondecreasing curve) is invoked to show forward matvecs provide no reliable spectral-norm information. The proof sketch should be checked for whether it holds under the exact arithmetic model used elsewhere or requires additional assumptions on the query model.
Authors: The Arnoldi-norm result is established under the exact arithmetic model that is used consistently throughout the paper. The proof proceeds via explicit matrix constructions in which the Arnoldi process yields the prescribed nondecreasing norm sequence without any appeal to floating-point arithmetic or inexact queries. We will insert a clarifying sentence in the revised version to state explicitly that the argument relies only on exact arithmetic and is consistent with the query model employed in the remainder of the manuscript. revision: yes
Circularity Check
No circularity; derivations rely on standard query-model and linear-algebra constructions
full rationale
The paper derives non-identifiability results and query lower bounds (e.g., n queries for near-optimal rank-k approximation, Ω(ε^{-2}) for Frobenius norm) from explicit matrix constructions that agree on forward matvecs yet differ in target quantities, plus standard information-theoretic adversary arguments. No parameters are fitted to data inside the paper, no result is defined in terms of itself, and no load-bearing step reduces to a self-citation or ansatz smuggled from prior work by the same authors. The central claims remain independent of the paper's own outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math Matrix-vector multiplication is linear and associative in the standard sense.
- domain assumption There exist distinct matrices that produce identical sequences of forward matvecs.
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
Amsel, T
N. Amsel, T. Chen, F. D. Keles, D. Halikias, C. Musco, and C. Musco. Fixed-sparsity matrix approxi- mation from matrix-vector products.SIAM J. Matrix Anal. Appl., 47(2):483–511, 2026
2026
-
[5]
A. C. Antoulas.Approximation of Large-Scale Dynamical Systems. SIAM, 2005
2005
-
[6]
Baglama and L
J. Baglama and L. Reichel. Augmented implicitly restarted Lanczos bidiagonalization methods.SIAM J. Sci. Comput., 27(1):19–42, 2005
2005
-
[7]
Bakshi, K
A. Bakshi, K. L. Clarkson, and D. P. Woodruff. Low-rank approximation with 1/ε 1/2 matrix-vector products. InSTOC, pages 1130–1143, 2022
2022
-
[8]
Bakshi and S
A. Bakshi and S. Narayanan. Krylov methods are (nearly) optimal for low-rank approximation. In FOCS, pages 2093–2101. IEEE, 2023
2093
-
[9]
Barrett, M
R. Barrett, M. Berry, T. F. Chan, J. Demmel, J. Donato, J. Dongarra, V. Eijkhout, R. Pozo, C. Romine, and H. van der Vorst.Templates for the Solution of Linear Systems: Building Blocks for Iterative Methods. SIAM, 1994
1994
-
[10]
Bebendorf
M. Bebendorf. Adaptive cross approximation of multivariate functions.Constructive approximation, 34(2):149–179, 2011
2011
-
[11]
Boull´ e, D
N. Boull´ e, D. Halikias, S. E. Otto, and A. Townsend. Operator learning without the adjoint.J. Mach. Learn. Res., 25(364):1–54, 2024
2024
-
[12]
Boull´ e, D
N. Boull´ e, D. Halikias, and A. Townsend. Elliptic PDE learning is provably data-efficient.Proc. Natl. Acad. Sci., 120(39):e2303904120, 2023
2023
-
[13]
Boull´ e and A
N. Boull´ e and A. Townsend. A mathematical guide to operator learning. InHandb. Numer. Anal., volume 25, pages 83–125. Elsevier, 2024
2024
-
[14]
Boutsidis and D
C. Boutsidis and D. P. Woodruff. Optimal cur matrix decompositions. InSTOC, pages 353–362, 2014
2014
- [15]
-
[16]
Brezinski and M
C. Brezinski and M. Redivo-Zaglia. Transpose-free lanczos-type algorithms for nonsymmetric linear systems.Numer. Algorithms, 17(1):67–103, 1998
1998
-
[17]
T. F. Chan, L. G. de Pillis, and H. A. van der Vorst. Transpose-free formulations of Lanczos-type methods for nonsymmetric linear systems.SIAM J. Sci. Comput., 19(4):1169–1184, 1998
1998
-
[18]
T. F. Chan, E. Gallopoulos, V. Simoncini, T. Szeto, and C. H. Tong. A quasi-minimal residual variant of the Bi-CGSTAB algorithm for nonsymmetric systems.SIAM J. Sci. Comput., 15(2):338–347, 1994
1994
-
[19]
Chaturantabut and D
S. Chaturantabut and D. C. Sorensen. Nonlinear model reduction via discrete empirical interpolation. SIAM J. Sci. Comput., 32(5):2737–2764, 2010. 26
2010
-
[20]
T. Chen, F. D. Keles, D. Halikias, C. Musco, C. Musco, and D. Persson. Near-optimal hierarchical matrix approximation from matrix-vector products. InSODA, pages 2656–2692, 2025
2025
-
[21]
Chouzenoux, A
E. Chouzenoux, A. Contreras, J.-C. Pesquet, and M. Savanier. Convergence results for primal-dual algorithms in the presence of adjoint mismatch.SIAM J. Imaging Sci., 16(1):1–34, 2023
2023
-
[22]
Chu and A
Y.-C. Chu and A. Cortinovis. Improved bounds for randomized Schatten norm estimation of numerically low-rank matrices.Linear Algebra Appl., 717:68–93, 2025
2025
-
[23]
Chung and S
J. Chung and S. Gazzola. Flexible Krylov methods forℓ p regularization.SIAM J. Sci. Comput., 41(5):S149–S171, 2019
2019
-
[24]
Cortinovis and D
A. Cortinovis and D. Kressner. Adaptive randomized pivoting for column subset selection, DEIM, and low-rank approximation.SIAM J. Matrix Anal. Appl., 47(1):25–47, 2026
2026
-
[25]
Damle, S
A. Damle, S. Glas, A. Townsend, and A. Yu. Estimating a matrix’s singular values with interpolative decompositions.Linear Algebra Appl., 2025
2025
-
[26]
M. Derezi´ nski, E. N. Epperly, and R. A. Meyer. The matrix-vector complexity ofAx=b. arXiv:2602.04842, 2026
-
[27]
Deshpande and L
A. Deshpande and L. Rademacher. Efficient volume sampling for row/column subset selection. In FOCS, pages 329–338. IEEE, 2010
2010
-
[28]
Deshpande, L
A. Deshpande, L. Rademacher, S. S. Vempala, and G. Wang. Matrix approximation and projective clustering via volume sampling.Theory Comput., 2(1):225–247, 2006
2006
-
[29]
Y. Dong, P. C. Hansen, M. E. Hochstenbach, and N. A. Brogaard Riis. Fixing nonconvergence of alge- braic iterative reconstruction with an unmatched backprojector.SIAM J. Sci. Comput., 41(3):A1822– A1839, 2019
2019
-
[30]
T. A. Driscoll, K.-C. Toh, and L. N. Trefethen. From potential theory to matrix iterations in six steps. SIAM Rev., 40(3):547–578, 1998
1998
-
[31]
K. Du, J. D. Tebbens, and G. Meurant. Any admissible harmonic Ritz value set is possible for GMRES. Electron. Trans. Numer. Anal., 47:37–56, 2017
2017
-
[32]
Elfving and P
T. Elfving and P. C. Hansen. Unmatched projector/backprojector pairs: Perturbation and convergence analysis.SIAM J. Sci. Comput., 40(1):A573–A591, 2018
2018
-
[33]
Faber and T
V. Faber and T. Manteuffel. Necessary and sufficient conditions for the existence of a conjugate gradient method.SIAM J. Numer. Anal., 21(2):352–362, 1984
1984
-
[34]
Feldmann and R
P. Feldmann and R. W. Freund. Efficient linear circuit analysis by Pad´ e approximation via the Lanczos process.IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst., 14(5):639–649, 1995
1995
-
[35]
R. W. Freund. Solution of shifted linear systems by quasi-minimal residual iterations. InNumerical Linear Algebra, pages 101–121, 1993
1993
-
[36]
R. W. Freund. A transpose-free quasi-minimal residual algorithm for non-Hermitian linear systems. SIAM J. Sci. Comput., 14(2):470–482, 1993
1993
-
[37]
S. A. Goreinov, I. V. Oseledets, D. V. Savostyanov, E. E. Tyrtyshnikov, and N. L. Zamarashkin. How to find a good submatrix. InMatrix Methods: Theory, Algorithms And Applications, pages 247–256. 2010
2010
-
[38]
S. A. Goreinov, E. E. Tyrtyshnikov, and N. L. Zamarashkin. A theory of pseudoskeleton approximations. Linear Algebra Appl., 261(1-3):1–21, 1997
1997
-
[39]
Greenbaum, V
A. Greenbaum, V. Pt´ ak, and Z. Strakoˇ s. Any nonincreasing convergence curve is possible for GMRES. SIAM J. Matrix Anal. Appl., 17(3):465–469, 1996
1996
-
[40]
Halikias.Structured Matrix Recovery and Approximation From Matrix-Vector Products
D. Halikias.Structured Matrix Recovery and Approximation From Matrix-Vector Products. PhD thesis, Cornell University, 2025. 27
2025
-
[41]
Halikias and A
D. Halikias and A. Townsend. Structured matrix recovery from matrix-vector products.Numer. Linear Algebra Appl., 31(1):e2531, 2024
2024
-
[42]
Halko, P.-G
N. Halko, P.-G. Martinsson, and J. A. Tropp. Finding structure with randomness: Probabilistic algo- rithms for constructing approximate matrix decompositions.SIAM Rev., 53(2):217–288, 2011
2011
-
[43]
P. C. Hansen. Personal communication, 2025
2025
-
[44]
P. C. Hansen, K. Hayami, and K. Morikuni. GMRES methods for tomographic reconstruction with an unmatched back projector.J. Comput. Appl. Math., 413:114352, 2022
2022
-
[45]
Hochbruck and M
M. Hochbruck and M. E. Hochstenbach. Subspace extraction for matrix functions. Technical report, Case Western Reserve University, Department of Mathematics, 2005
2005
-
[46]
Hutchinson
M. Hutchinson. A stochastic estimator of the trace of the influence matrix for laplacian smoothing splines.Commun. Stat. Simul. Comput., 18(3):1059–1076, 1 1989
1989
-
[47]
Kong and G
W. Kong and G. Valiant. Spectrum estimation from samples.Ann. Stat., 45(5):2218–2247, 2017
2017
- [48]
-
[49]
N. B. Kovachki, S. Lanthaler, and A. M. Stuart. Operator learning: Algorithms and analysis.Handb. Numer. Anal., 25:419–467, 2024
2024
-
[50]
Y. Li, H. L. Nguyen, and D. P. Woodruff. On sketching matrix norms and the top singular vector. In Proceedings of the Twenty-Fifth Annual ACM-SIAM Symposium on Discrete Algorithms, pages 1562– 1581, 2014
2014
-
[51]
D. A. Lorenz, S. Rose, and F. Sch¨ opfer. The randomized Kaczmarz method with mismatched adjoint. BIT Numer. Math., 58(4):1079–1098, 2018
2018
-
[52]
M. W. Mahoney and P. Drineas. Cur matrix decompositions for improved data analysis.Proc. Natl. Acad. Sci., 106(3):697–702, 2009
2009
-
[53]
Martinsson and J
P.-G. Martinsson and J. A. Tropp. Randomized numerical linear algebra: Foundations and algorithms. Acta Numerica, 29:403–572, 2020
2020
-
[54]
Meyer, C
R. Meyer, C. Musco, and C. Musco. On the unreasonable effectiveness of single vector krylov methods for low-rank approximation. InSODA, pages 811–845. SIAM, 2024
2024
-
[55]
Y. Nakatsukasa. Fast and stable randomized low-rank matrix approximation.arXiv:2009.11392, 2020
-
[56]
A. Osinsky. Close to optimal column approximation using a single svd.Linear Algebra and its Appli- cations, 2025
2025
-
[57]
S. E. Otto, A. Padovan, and C. W. Rowley. Model reduction for nonlinear systems by balanced trun- cation of state and gradient covariance.SIAM J. Sci. Comput., 45(5):A2325–A2355, 2023
2023
-
[58]
Persson, A
D. Persson, A. Cortinovis, and D. Kressner. Improved variants of the Hutch++ algorithm for trace estimation.SIAM J. Matrix Anal. Appl., 43(3):1162–1185, 2022
2022
-
[59]
Saad and M
Y. Saad and M. H. Schultz. A generalized minimal residual algorithm for solving nonsymmetric linear systems.SIAM J. Sci. Stat. Comput., 7(3):856–869, 1986
1986
-
[60]
Schweitzer
M. Schweitzer. Any finite convergence curve is possible in the initial iterations of restarted FOM. Electron. Trans. Numer. Anal., 45:133–145, 2016
2016
-
[61]
Y. Shitov. Column subset selection is NP-complete.Linear Algebra Appl., 610:52–58, 2021
2021
-
[62]
Simoncini and E
V. Simoncini and E. Gallopoulos. An iterative method for nonsymmetric systems with multiple right- hand sides.SIAM J. Sci. Comput., 16(4):917–933, 1995
1995
-
[63]
Simoncini and D
V. Simoncini and D. B. Szyld. Recent computational developments in krylov subspace methods for linear systems.Numer. Linear Algebra Appl., 14(1):1–59, 2007. 28
2007
-
[64]
G. L. G. Sleijpen and D. R. Fokkema. BiCGstab(ℓ) for linear equations involving unsymmetric matrices with complex spectrum.Electron. Trans. Numer. Anal., 1:11–32, 1993
1993
-
[65]
Sonneveld
P. Sonneveld. A fast Lanczos-type solver for nonsymmetric linear systems.SIAM J. Sci. Stat. Comput., 10(1):36–52, 1989
1989
-
[66]
Sonneveld and M
P. Sonneveld and M. B. Van Gijzen. IDR(s): A family of simple and fast algorithms for solving large nonsymmetric systems of linear equations.SIAM J. Sci. Comput., 31(2):1035–1062, 2009
2009
-
[67]
M. Stoll. A Krylov–Schur approach to the truncated SVD.Linear Algebra Appl., 436(8):2795–2806, 2012
2012
-
[68]
X. Sun, D. P. Woodruff, G. Yang, and J. Zhang. Querying a matrix through matrix-vector products. ACM Trans. Algorithms, 17(4):Art. 31, 19, 2021
2021
-
[69]
J. D. Tebbens and G. Meurant. Any Ritz value behavior is possible for Arnoldi and for GMRES.SIAM J. Matrix Anal. Appl., 33(3):958–978, 2012
2012
- [70]
-
[71]
H. A. van der Vorst. Bi-CGSTAB: A fast and smoothly converging variant of Bi-CG for the solution of nonsymmetric linear systems.SIAM J. Sci. Stat. Comput., 13(2):631–644, 1992
1992
-
[72]
Vecharynski and J
E. Vecharynski and J. Langou. Any admissible cycle-convergence behavior is possible for restarted GMRES at its initial cycles.Numer. Linear Alg. Appl., 18(3):499–511, 2011
2011
-
[73]
Voronin and P.-G
S. Voronin and P.-G. Martinsson. Efficient algorithms for cur and interpolative matrix decompositions. Adv. Comput. Math., 43(3):495–516, 2017
2017
-
[74]
A. J. Wathen. Least squares and the not-normal equations.SIAM Rev., 67(4):865–872, 2025
2025
-
[75]
D. P. Woodruff. Sketching as a tool for numerical linear algebra.Found. Trends Theor. Comput. Sci., 10(1–2):1–157, 2014
2014
-
[76]
A. C.-C. Yao. Probabilistic computations: Toward a unified measure of complexity. InSFCS ’77, pages 222–227, 1977
1977
-
[77]
G. L. Zeng and G. T. Gullberg. Unmatched projector/backprojector pairs in an iterative reconstruction algorithm.IEEE Trans. Med. Imaging, 19(5):548–555, 2000. 29
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.