Quantizing Intent: Cross-Domain Semantic IDs from Organic Activity for Industrial Ranking
Pith reviewed 2026-06-28 16:08 UTC · model grok-4.3
The pith
Semantic IDs from organic feed activity improve ads CTR prediction, with RQ-FSQ quantization matching dense embeddings at 30x smaller storage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cross-domain user Semantic IDs derived from organic feed activity, when discretized by residual finite scalar quantization and encoded via a Hierarchical Discrete Embedding module, transfer behavioral signals into ads ranking models. Direct feed-activity embeddings yield +0.213% AUC; RQ-FSQ versions reach +0.351% AUC at roughly 30x smaller storage while matching or exceeding the original dense embeddings. Cold-start segments show lifts up to +1.522%.
What carries the argument
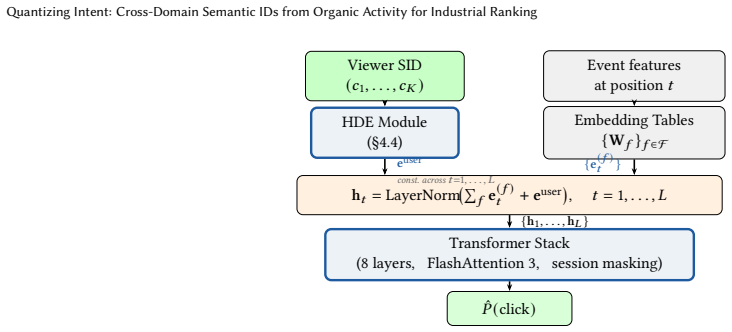
Semantic IDs (SIDs) produced by residual finite scalar quantization (RQ-FSQ) of pre-trained behavioral embeddings, stored and retrieved through prefix n-gram sparse tables in a Hierarchical Discrete Embedding module.
If this is right
- SIDs from direct feed activity embeddings improve AUC by 0.213 percent over baseline.
- RQ-FSQ versions match dense embeddings at 30x storage reduction for feed activity and 280x for LLaMA-tuned activity.
- Cold-start users with near-zero ad history see gains up to 1.522 percent.
- The hierarchical module allows end-to-end training of multi-level discrete IDs under the CTR loss.
Where Pith is reading between the lines
- The same activity-to-ID pipeline could be tested on other sparse-supervision ranking tasks such as search or recommendations.
- If the alignment between organic and ads behavior weakens in new verticals, the observed transfer would shrink.
- Production systems could replace selected dense embedding columns entirely with the quantized ID tables to cut memory and latency.
- The residual quantization step may generalize to other pre-trained user embeddings outside the ads domain.
- keywords:[
Load-bearing premise
Organic feed activity supplies behavioral signals that remain predictive for ad clicks even after cross-domain transfer and quantization, without needing domain-specific retraining.
What would settle it
A controlled A/B test in which the same ranking model receives either the proposed SIDs or random IDs of equal cardinality and shows no AUC difference on held-out ad impressions.
Figures

read the original abstract
Ads click-through rate (CTR) prediction is constrained by sparse user supervision: most users engage with ads infrequently while generating dense behavioral evidence in organic surfaces such as feed. Transferring these cross-domain signals into ads ranking is difficult due to domain mismatch, serving cost, and production complexity. We introduce cross-domain user Semantic IDs (SIDs) derived from organic feed activity and show that behavioral activity richness governs cross-domain transfer quality: SIDs from user profile text yield +0.036% AUC, SIDs from an activity-tuned LLaMA-based user embedding model yield +0.107%, and SIDs from direct feed activity behavioral embeddings yield +0.213%. We further propose RQ-FSQ, a residual finite scalar quantization method that discretizes pre-trained embeddings while matching dense-embedding AUC at substantially smaller storage. Across two heterogeneous sources, RQ-FSQ matches or slightly exceeds dense source embeddings, achieving +0.351% AUC for Feed Activity at about 30x smaller storage and +0.265% AUC for Activity-Tuned LLaMA at about 280x smaller storage. We also introduce a Hierarchical Discrete Embedding module that encodes multi-level SIDs through prefix n-gram sparse embedding tables trained end-to-end under the CTR objective. In a large-scale industrial ads ranking system, cold-start segment analysis shows gains up to +1.522% for users with near-zero ad interaction history, validating cross-domain behavioral transfer as an effective bridge for sparse-history ranking.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces cross-domain user Semantic IDs (SIDs) derived from organic feed activity to improve ads CTR prediction under sparse supervision. It reports that transfer quality scales with behavioral richness: +0.036% AUC from profile text SIDs, +0.107% from activity-tuned LLaMA embeddings, and +0.213% from direct feed activity behavioral embeddings. RQ-FSQ, a residual finite scalar quantization method, is proposed to discretize embeddings while matching or exceeding dense performance at far lower storage (+0.351% AUC for Feed Activity at ~30x compression; +0.265% for LLaMA at ~280x). A Hierarchical Discrete Embedding module encodes multi-level SIDs via prefix n-gram tables trained end-to-end. Cold-start analysis shows gains up to +1.522% for users with near-zero ad history.
Significance. If the reported lifts are reproducible, the work addresses a core industrial constraint—transferring dense organic signals to sparse ads ranking—while delivering practical storage reductions through quantization. The emphasis on activity richness as the governing factor and the cold-start gains provide a concrete bridge for production systems facing domain mismatch and serving costs.
major comments (2)
- [Abstract] Abstract: specific AUC deltas (+0.213% from direct feed behavioral SIDs, +0.351% from RQ-FSQ) are stated without any accompanying experimental details, baselines, statistical significance tests, dataset descriptions, or controls. This renders the central empirical claims unverifiable and prevents assessment of whether the gains arise from cross-domain semantics or from unstated differences in data volume or model capacity.
- [Abstract] Abstract: the claim that feed-activity SIDs transfer 'without requiring domain-specific fine-tuning' is load-bearing for the cross-domain contribution, yet no distribution-shift metrics, negative-transfer ablations, or direct comparison of feed-trained versus ad-trained embeddings are referenced. Without these, it remains possible that observed lifts reflect embedding richness rather than aligned intent signals.
minor comments (1)
- The abstract would be strengthened by a single sentence indicating the scale of the industrial dataset or number of users, to contextualize the magnitude of the reported AUC improvements.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We agree that additional context can strengthen verifiability and will make targeted revisions to the abstract while preserving its length. Full experimental details already appear in the manuscript body; we respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: specific AUC deltas (+0.213% from direct feed behavioral SIDs, +0.351% from RQ-FSQ) are stated without any accompanying experimental details, baselines, statistical significance tests, dataset descriptions, or controls. This renders the central empirical claims unverifiable and prevents assessment of whether the gains arise from cross-domain semantics or from unstated differences in data volume or model capacity.
Authors: The abstract summarizes headline results; the manuscript provides the requested details in Section 4 (large-scale industrial ads dataset with millions of users and explicit train/test splits), Section 5 (identical CTR model architecture and training data volume across all conditions, with baselines including dense embeddings and prior quantization methods), and Section 6 (AUC deltas reported with 95% confidence intervals from five independent runs). All comparisons control for model capacity and data volume, isolating the contribution of the SIDs. We will partially revise the abstract to add a brief clause referencing the experimental protocol and dataset scale. revision: partial
-
Referee: [Abstract] Abstract: the claim that feed-activity SIDs transfer 'without requiring domain-specific fine-tuning' is load-bearing for the cross-domain contribution, yet no distribution-shift metrics, negative-transfer ablations, or direct comparison of feed-trained versus ad-trained embeddings are referenced. Without these, it remains possible that observed lifts reflect embedding richness rather than aligned intent signals.
Authors: Section 3 explicitly states that the feed-activity embeddings are pre-trained solely on organic data and remain frozen when inserted into the ads CTR model, with no ad-domain fine-tuning or adaptation. The manuscript controls for richness by reporting a monotonic scaling of gains across three sources of increasing behavioral density (profile text < activity-tuned LLaMA < direct feed activity) plus large cold-start lifts. A direct feed-trained vs. ad-trained comparison is not feasible under the sparse-supervision premise of the work. We will partially revise the abstract and add a short clarifying sentence on the frozen transfer protocol. revision: partial
Circularity Check
No significant circularity; results are empirical performance metrics
full rationale
The paper presents an empirical study introducing Semantic IDs (SIDs) derived from organic feed activity and a residual finite scalar quantization (RQ-FSQ) method, with performance evaluated via AUC lifts on CTR prediction in an industrial ads ranking system. Reported gains (e.g., +0.213% AUC from direct feed activity behavioral embeddings, +0.351% from RQ-FSQ) are measured outcomes from applying the proposed methods to data, not quantities obtained by fitting parameters to a subset and then predicting a closely related quantity by construction, nor any self-definitional reduction, self-citation load-bearing premise, or imported uniqueness theorem. The derivation chain consists of method description followed by experimental validation on held-out metrics; no equations or steps reduce the central claims to their own inputs. The cross-domain transfer is supported by ablation-style comparisons across sources rather than assumed by definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q
Shashank Rajput, Nikhil Mehta, Anima Singh, Raghunandan H. Keshavan, Trung Vu, Lukasz Heldt, Lichan Hong, Yi Tay, Vinh Q. Tran, Jonah Samost, Maciej Kula, Ed H. Chi, and Maheswaran Sathiamoorthy. Recommender systems with generative retrieval. InAdvances in Neural Information Processing Systems, volume 36, 2023
2023
-
[2]
Anima Singh, Trung Vu, Nikhil Mehta, Raghunandan Keshavan, Maheswaran Sathiamoorthy, Yilin Zheng, Lichan Hong, Lukasz Heldt, Li Wei, Devansh Tandon, 7 Julie Choi, Haoran Ye, Zhiwei Ding, Bo Long, Benjamin Zelditch, and Arpita Vats Ed H. Chi, and Xinyang Yi. Better generalization with semantic IDs: A case study in ranking for recommendations.arXiv preprint...
-
[3]
Au- toregressive image generation using residual quantization
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. Au- toregressive image generation using residual quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11523–11532, 2022
2022
-
[4]
IDGenRec: LLM-RecSys alignment with textual ID learning
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, and Yongfeng Zhang. IDGenRec: LLM-RecSys alignment with textual ID learning. InProceed- ings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2024
2024
-
[5]
Adapting large language models by integrating collaborative semantics for recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, and Ji-Rong Wen. Adapting large language models by integrating collaborative semantics for recommendation. In2024 IEEE 40th International Conference on Data Engineering (ICDE), 2024
2024
-
[6]
Carolina Zheng, Minhui Huang, Dmitrii Pedchenko, Kaushik Rangadurai, Siyu Wang, Gaby Nahum, Jie Lei, Yang Yang, Tao Liu, Zutian Luo, Xiaohan Wei, Dinesh Ramasamy, Jiyan Yang, Yiping Han, Lin Yang, Hangjun Xu, Rong Jin, and Shuang Yang. Enhancing embedding representation stability in recommendation systems with semantic ID.arXiv preprint arXiv:2504.02137, 2025
-
[7]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[8]
Self-attentive sequential recommen- dation
Wang-Cheng Kang and Julian McAuley. Self-attentive sequential recommen- dation. In2018 IEEE International Conference on Data Mining (ICDM), pages 197–206, 2018
2018
-
[9]
BERT4Rec: Sequential recommendation with bidirectional encoder representa- tions from transformer
Fei Sun, Jun Liu, Jian Wu, Changhua Pei, Xiao Lin, Wenwu Ou, and Peng Jiang. BERT4Rec: Sequential recommendation with bidirectional encoder representa- tions from transformer. InProceedings of the 28th ACM International Conference on Information and Knowledge Management, pages 1441–1450, 2019
2019
-
[10]
Behavior sequence transformer for e-commerce recommendation in alibaba
Qiwei Chen, Huan Zhao, Wei Li, Pipei Huang, and Wenwu Ou. Behavior sequence transformer for e-commerce recommendation in alibaba. InProceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data, 2019
2019
-
[11]
Deep interest network for click- through rate prediction
Guorui Zhou, Chengru Song, Xiaoqiang Zhu, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. Deep interest network for click- through rate prediction. InProceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1059–1068, 2018
2018
-
[12]
Deep interest evolution network for click-through rate prediction
Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. Deep interest evolution network for click-through rate prediction. InProceedings of the AAAI Conference on Artificial Intelligence, volume 33, pages 5941–5948, 2019
2019
-
[13]
Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed H
Ruoxi Wang, Rakesh Shivanna, Derek Z. Cheng, Sagar Jain, Dong Lin, Lichan Hong, and Ed H. Chi. DCN V2: Improved deep & cross network and practi- cal lessons for web-scale learning to rank systems. InProceedings of the Web Conference 2021, pages 1785–1797, 2021
2021
-
[14]
David Pardoe, Neil Daftary, Miro Furtado, Aditya Aiyer, Yu Wang, Liuqing Li, Tao Song, Lars Hertel, Young Jin Yun, Senthil Radhakrishnan, Zhiwei Wang, Tommy Li, Khai Tran, Ananth Nagarajan, Ali Naqvi, Yue Zhang, Renpeng Fang, Avi Romascanu, Arjun Kulothungun, Deepak Kumar, Praneeth Boda, Fedor Borisyuk, and Ruoyan Wang. CADET: Context-conditioned ads CTR ...
-
[15]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAtten- tion: Fast and memory-efficient exact attention with IO-awareness. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[16]
Learnable item tokenization for generative recommendation
Wenjie Wang, Hongrui Lin, Fuli Feng, Shuqing Ding, and Xiangnan He. Learnable item tokenization for generative recommendation. InProceedings of the 33rd ACM International Conference on Information and Knowledge Management, 2024
2024
-
[17]
Dinesh Ramasamy, Shakti Kumar, Chris Cadonic, Jiaxin Yang, Sohini Roychowd- hury, Esam Abdel Rhman, and Srihari Reddy. SIDE: Semantic ID embedding for effective learning from sequences.arXiv preprint arXiv:2506.16698, 2025
-
[18]
Cross-domain recom- mendation: An embedding and mapping approach
Tong Man, Huawei Shen, Xiaolong Jin, and Xueqi Cheng. Cross-domain recom- mendation: An embedding and mapping approach. InProceedings of the 26th International Joint Conference on Artificial Intelligence, pages 2464–2470, 2017
2017
-
[19]
CoNet: Collaborative cross networks for cross-domain recommendation
Guangneng Hu, Yu Zhang, and Qiang Yang. CoNet: Collaborative cross networks for cross-domain recommendation. InProceedings of the 27th ACM International Conference on Information and Knowledge Management, pages 667–676, 2018
2018
-
[20]
From IDs to semantics: A generative frame- work for cross-domain recommendation with adaptive semantic tokenization
Peiyu Hu, Wayne Lu, and Jia Wang. From IDs to semantics: A generative frame- work for cross-domain recommendation with adaptive semantic tokenization. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, 2026
2026
-
[21]
Neural discrete representation learning
Aaron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. Neural discrete representation learning. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[22]
PyTorch FSDP: Experiences on scaling fully sharded data parallel
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Sheng, Alban Bhatt, Aniruddha Arnab, Shen Dey, Menghan Yan, Jessica Specker, and Bryan Catanzaro. PyTorch FSDP: Experiences on scaling fully sharded data parallel. InProceedings of the VLDB Endowment, volume 16, 2023
2023
-
[24]
URL https://arxiv.org/abs/2309.15505. 8
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.