Whole-Pool Setwise Reranking with Long-Context Language Models
Pith reviewed 2026-06-28 12:55 UTC · model grok-4.3
The pith
Long-context LLMs let rerankers consider the full candidate pool at once and build rankings from both ends with DualEnd.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
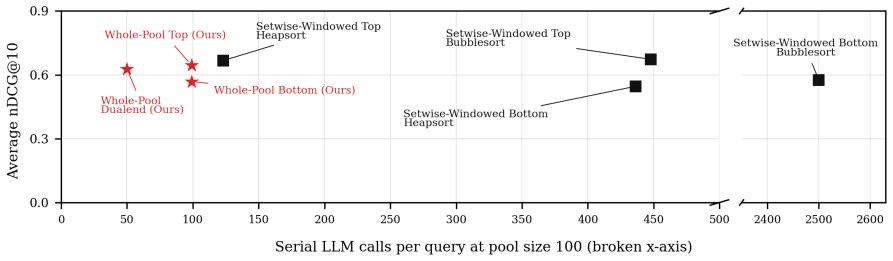
When the full set of retrieved candidate passages can be shown to the model at once, ranking no longer has to be reconstructed from many dependent local comparisons. Whole-Pool Setwise reranking lets each call consider all currently unranked passages, and DualEnd identifies both the most and least relevant passage in one response, so the ranking is built from both ends.
What carries the argument
DualEnd, the prompting strategy that asks the long-context LLM to name both the most relevant and least relevant passage among the current unranked pool in a single response.
If this is right
- 100 candidates can be fully ranked with 50 serial LLM calls rather than 99.
- Effectiveness stays comparable to prior methods while token use and runtime decrease.
- The same approach works across nine different open-weight long-context LLMs on standard passage reranking benchmarks.
- Setwise decisions replace the need to stitch together many overlapping local judgments.
Where Pith is reading between the lines
- The dual-end selection idea could apply to other ordering tasks where a model processes a large set in one step.
- If prompt formatting is refined, pools larger than 100 might become feasible without accuracy loss.
- Production systems could adopt the method once output reliability on full-pool prompts is confirmed at scale.
Load-bearing premise
Long-context LLMs maintain sufficient accuracy and output reliability when the entire candidate pool is placed in one prompt without degradation from length or formatting.
What would settle it
An experiment that shows ranking quality or output consistency drops sharply when the full pool of 100 passages is placed in one prompt compared with smaller subsets.
Figures

read the original abstract
Previous LLM-based passage re-rankers are often expensive and slow because the input context constraints require the LLM to make many dependent model calls. We study how recent long-context LLMs change this problem: when the full set of retrieved candidate passages can be shown to the model at once, ranking no longer has to be reconstructed from many overlapping local comparisons. We propose Whole-Pool Setwise re-ranking, where each call considers all currently unranked candidate passages, and introduce DualEnd, which identifies both the most and least relevant passages in one call. By filling the ranking from both ends, DualEnd ranks 100 candidates with 50 serial LLM calls, compared with 99 calls for comparable one-passage-at-a-time whole-pool methods. Experiments with nine open-weight LLMs on two passage re-ranking benchmarks, measuring effectiveness, call count, token use, runtime, and output reliability shows that long context is not merely more prompt space, but an opportunity to make LLM re-rankers both effective and efficient.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that long-context LLMs enable whole-pool setwise reranking, where each call operates over all remaining candidates; DualEnd identifies both the most and least relevant passage per call, allowing a 100-candidate ranking to be completed in 50 serial calls versus 99 for one-passage-at-a-time whole-pool baselines. Experiments across nine open-weight LLMs on two passage reranking benchmarks report effectiveness, call count, token usage, runtime, and output reliability, concluding that long context yields both effective and efficient rerankers.
Significance. If the results hold, the arithmetic reduction in calls combined with measured reliability offers a practical route to scaling LLM rerankers beyond small candidate sets. The multi-model evaluation and explicit reliability measurements provide a stronger empirical basis than typical single-model prompting studies.
major comments (3)
- [Experiments section] Experiments section: the reported effectiveness results lack any mention of statistical significance tests, error bars, or data-exclusion rules, which is required to substantiate the claim that DualEnd is competitive with or superior to prior methods.
- [Method and Experiments sections] Method and Experiments sections: the central efficiency claim (50 vs. 99 calls) is arithmetically correct, but the paper must explicitly define the "comparable one-passage-at-a-time whole-pool methods" used for comparison and report their exact call counts under identical candidate-pool sizes.
- [Reliability analysis] Reliability analysis: while output reliability is measured, the manuscript does not report how context-length degradation is isolated from prompt-formatting effects, leaving the weakest assumption (maintained setwise accuracy) only partially tested.
minor comments (2)
- Add a summary table collating call count, token usage, and runtime across all nine models and both benchmarks for easier comparison.
- [Abstract] Clarify in the abstract whether the two benchmarks are standard TREC or MS MARCO passage tasks and list their names.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment point by point below and indicate the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the reported effectiveness results lack any mention of statistical significance tests, error bars, or data-exclusion rules, which is required to substantiate the claim that DualEnd is competitive with or superior to prior methods.
Authors: We agree that statistical tests strengthen the empirical claims. In the revised manuscript we will add Wilcoxon signed-rank tests (with p-values) comparing DualEnd against the reported baselines across all queries, report standard deviations as error bars on the effectiveness plots where multiple prompt variations were run, and explicitly state the data-exclusion criteria (queries with no relevant passages in the pool). revision: yes
-
Referee: [Method and Experiments sections] Method and Experiments sections: the central efficiency claim (50 vs. 99 calls) is arithmetically correct, but the paper must explicitly define the "comparable one-passage-at-a-time whole-pool methods" used for comparison and report their exact call counts under identical candidate-pool sizes.
Authors: We will revise the Method section to define the one-passage-at-a-time whole-pool baseline as the sequential procedure that extracts only the single highest-ranked passage per call and removes it from the pool. The Experiments section will then tabulate the exact call counts (99 for 100 candidates, 49 for 50 candidates, etc.) under the same pool sizes used for DualEnd. revision: yes
-
Referee: [Reliability analysis] Reliability analysis: while output reliability is measured, the manuscript does not report how context-length degradation is isolated from prompt-formatting effects, leaving the weakest assumption (maintained setwise accuracy) only partially tested.
Authors: We acknowledge the limitation. Our reliability metric currently aggregates output consistency across repeated calls but does not include controlled ablations that hold prompt formatting fixed while varying context length. We will add an explicit discussion of this assumption and, space permitting, a small additional experiment that varies formatting at fixed context lengths. Full isolation would require further targeted experiments. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper introduces Whole-Pool Setwise reranking and the DualEnd strategy as a prompting technique for long-context LLMs. The efficiency claim (50 serial calls for 100 candidates) follows arithmetically from the method description of identifying both most and least relevant passages per call, with no equations, fitted parameters, or predictions that reduce to inputs by construction. Experiments with nine LLMs empirically measure effectiveness, reliability, and resource use, providing independent validation. No self-citation chains, uniqueness theorems, or ansatzes are load-bearing; the derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Long-context LLMs can accurately identify the single most relevant and single least relevant passage when shown the entire candidate pool in one prompt.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
A setwise approach for effective and highly efficient zero-shot ranking with large language models , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[2]
Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Beyond reproducibility: Advancing zero-shot llm reranking efficiency with setwise insertion , author=. Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[3]
arXiv preprint arXiv:2503.06034 , year=
Rank-r1: Enhancing reasoning in llm-based document rerankers via reinforcement learning , author=. arXiv preprint arXiv:2503.06034 , year=
-
[4]
Proceedings of the ACM on Web Conference 2025 , pages=
Tourrank: Utilizing large language models for documents ranking with a tournament-inspired strategy , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[5]
BlitzRank: Principled Zero-shot Ranking Agents with Tournament Graphs
BLITZRANK: Principled Zero-shot Ranking Agents with Tournament Graphs , author=. arXiv preprint arXiv:2602.05448 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Findings of the association for computational linguistics: EMNLP 2020 , pages=
Document ranking with a pretrained sequence-to-sequence model , author=. Findings of the association for computational linguistics: EMNLP 2020 , pages=
2020
-
[7]
The expando-mono-duo design pattern for text ranking with pretrained sequence-to-sequence models , author=. arXiv preprint arXiv:2101.05667 , year=
-
[8]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
Large language models are effective text rankers with pairwise ranking prompting , author=. Findings of the Association for Computational Linguistics: NAACL 2024 , pages=
2024
-
[9]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Is ChatGPT good at search? investigating large language models as re-ranking agents , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[10]
arXiv preprint arXiv:2305.02156 , year=
Zero-shot listwise document reranking with a large language model , author=. arXiv preprint arXiv:2305.02156 , year=
-
[11]
European Conference on Information Retrieval , pages=
Rank-without-gpt: Building gpt-independent listwise rerankers on open-source large language models , author=. European Conference on Information Retrieval , pages=. 2025 , organization=
2025
-
[12]
Proceedings of the ACM on Web Conference 2025 , pages=
Self-calibrated listwise reranking with large language models , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[13]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
REALM: Recursive Relevance Modeling for LLM-based Document Re-Ranking , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[14]
Advances in Neural Information Processing Systems , volume=
Scalable in-context ranking with generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[16]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
Found in the middle: Permutation self-consistency improves listwise ranking in large language models , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[17]
arXiv preprint arXiv:2406.00231 , year=
Llm-rankfusion: Mitigating intrinsic inconsistency in llm-based ranking , author=. arXiv preprint arXiv:2406.00231 , year=
-
[18]
European Conference on Information Retrieval , pages=
Lost but not only in the middle: Positional bias in retrieval augmented generation , author=. European Conference on Information Retrieval , pages=. 2025 , organization=
2025
-
[19]
International Conference on Learning Representations , volume=
Attention in large language models yields efficient zero-shot re-rankers , author=. International Conference on Learning Representations , volume=
-
[20]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
Efficiency-Effectiveness Reranking FLOPs for LLM-based Rerankers , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
2025
-
[21]
A Survey on Sorting with Large Language Models , author=
-
[22]
Voorhees , title =
Nick Craswell and Bhaskar Mitra and Emine Yilmaz and Daniel Campos and Ellen M. Voorhees , title =. Proceedings of the Twenty-Eighth Text REtrieval Conference (TREC 2019) , year =
2019
-
[23]
Proceedings of the Twenty-Ninth Text REtrieval Conference (TREC 2020) , year =
Nick Craswell and Bhaskar Mitra and Emine Yilmaz and Daniel Campos , title =. Proceedings of the Twenty-Ninth Text REtrieval Conference (TREC 2020) , year =
2020
-
[24]
Foundations and Trends in Information Retrieval , volume =
Stephen Robertson and Hugo Zaragoza , title =. Foundations and Trends in Information Retrieval , volume =
-
[25]
Proceedings of the 44th International
Jimmy Lin and Xueguang Ma and Sheng-Chieh Lin and Jheng-Hong Yang and Ronak Pradeep and Rodrigo Nogueira , title =. Proceedings of the 44th International
-
[26]
Journal of Machine Learning Research , volume=
Scaling instruction-finetuned language models , author=. Journal of Machine Learning Research , volume=
-
[27]
arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Shengyao Zhuang and Bevan Koopman and Guido Zuccon and contributors , title =
-
[29]
Foundations and Trends in Information Retrieval , volume =
The Probabilistic Relevance Framework: BM25 and Beyond , author =. Foundations and Trends in Information Retrieval , volume =
-
[30]
Bajaj, Payal and Campos, Daniel and Craswell, Nick and Deng, Li and Gao, Jianfeng and Liu, Xiaodong and Majumder, Rangan and McNamara, Andrew and Mitra, Bhaskar and Nguyen, Tri and Rosenberg, Mir and Song, Xia and Stoica, Alina and Tiwary, Saurabh and Wang, Tong , booktitle =
-
[31]
, booktitle =
Craswell, Nick and Mitra, Bhaskar and Yilmaz, Emine and Campos, Daniel and Voorhees, Ellen M. , booktitle =. Overview of the
-
[32]
Overview of the
Craswell, Nick and Mitra, Bhaskar and Yilmaz, Emine and Campos, Daniel , booktitle =. Overview of the
-
[33]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
Thakur, Nandan and Reimers, Nils and R. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track , year =
-
[34]
Cumulated Gain-Based Evaluation of
J. Cumulated Gain-Based Evaluation of. ACM Transactions on Information Systems , volume =
-
[35]
Passage Re-ranking with
Nogueira, Rodrigo and Cho, Kyunghyun , journal =. Passage Re-ranking with
-
[36]
Pretrained Transformers for Text Ranking:
Yates, Andrew and Nogueira, Rodrigo and Lin, Jimmy , booktitle =. Pretrained Transformers for Text Ranking:
-
[37]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
Improving passage retrieval with zero-shot question generation , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages=
2022
-
[38]
Rankvicuna: Zero-shot listwise document reranking with open-source large language models , author=. arXiv preprint arXiv:2309.15088 , year=
-
[39]
RankZephyr: Effective and Robust Zero-Shot Listwise Reranking is a Breeze!
Rankzephyr: Effective and robust zero-shot listwise reranking is a breeze! , author=. arXiv preprint arXiv:2312.02724 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Listt5: Listwise reranking with fusion-in-decoder improves zero-shot retrieval , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[41]
International Conference on Learning Representations , volume=
Large language models are not robust multiple choice selectors , author=. International Conference on Learning Representations , volume=
-
[42]
Judging the judges: A systematic study of position bias in llm-as-a-judge , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[43]
Monographs on statistics and applied probability , volume=
An introduction to the bootstrap , author=. Monographs on statistics and applied probability , volume=
-
[44]
Proceedings of the sixteenth ACM conference on Conference on information and knowledge management , pages=
A comparison of statistical significance tests for information retrieval evaluation , author=. Proceedings of the sixteenth ACM conference on Conference on information and knowledge management , pages=
-
[45]
Proceedings of the 42nd International ACM SIGIR conference on Research and development in information retrieval , pages=
Statistical significance testing in information retrieval: an empirical analysis of type I, type II and type III errors , author=. Proceedings of the 42nd International ACM SIGIR conference on Research and development in information retrieval , pages=
-
[46]
2026 , month = feb, url =
2026
-
[47]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
and Khandelwal, Kartik and Subramanian, Sandeep and Jouault, Victor and Rastogi, Abhinav and others , journal =
Liu, Alexander H. and Khandelwal, Kartik and Subramanian, Sandeep and Jouault, Victor and Rastogi, Abhinav and others , journal =
-
[49]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Prp-graph: Pairwise ranking prompting to llms with graph aggregation for effective text re-ranking , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[50]
arXiv preprint arXiv:2506.11452 , year=
Leveraging Reference Documents for Zero-Shot Ranking via Large Language Models , author=. arXiv preprint arXiv:2506.11452 , year=
-
[51]
arXiv preprint arXiv:2602.03422 , year=
RankSteer: Activation Steering for Pointwise LLM Ranking , author=. arXiv preprint arXiv:2602.03422 , year=
-
[52]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
FIRST: Faster improved listwise reranking with single token decoding , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[53]
Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
Fine-tuning llama for multi-stage text retrieval , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[54]
Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval , pages=
Anserini: Enabling the use of lucene for information retrieval research , author=. Proceedings of the 40th international ACM SIGIR conference on research and development in information retrieval , pages=
-
[55]
2026 , howpublished =
2026
-
[56]
2024 , howpublished =
2024
-
[57]
2025 , howpublished =
2025
-
[58]
2025 , eprint =
Gemma 3 Technical Report , author=. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.