Variational Free Energy Pivot Selection for Pivoted Cholesky
Pith reviewed 2026-06-28 13:46 UTC · model grok-4.3
The pith
A pivot rule for Cholesky approximations maximizes the exact one-step gain in variational free energy rather than trace error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
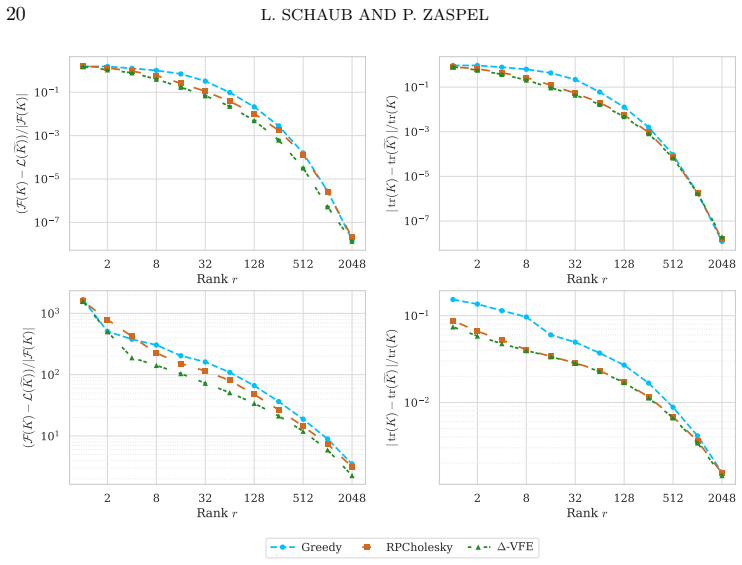
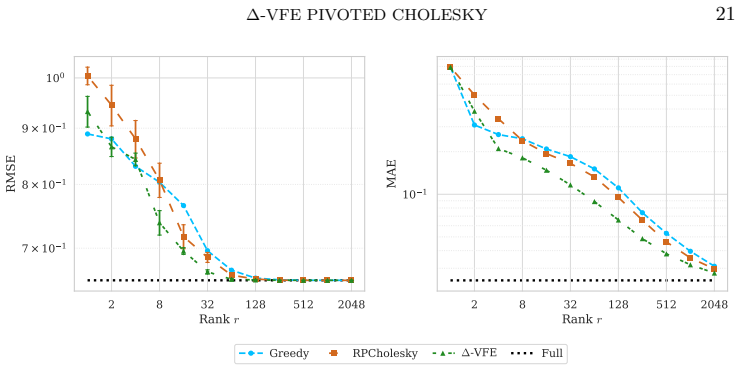
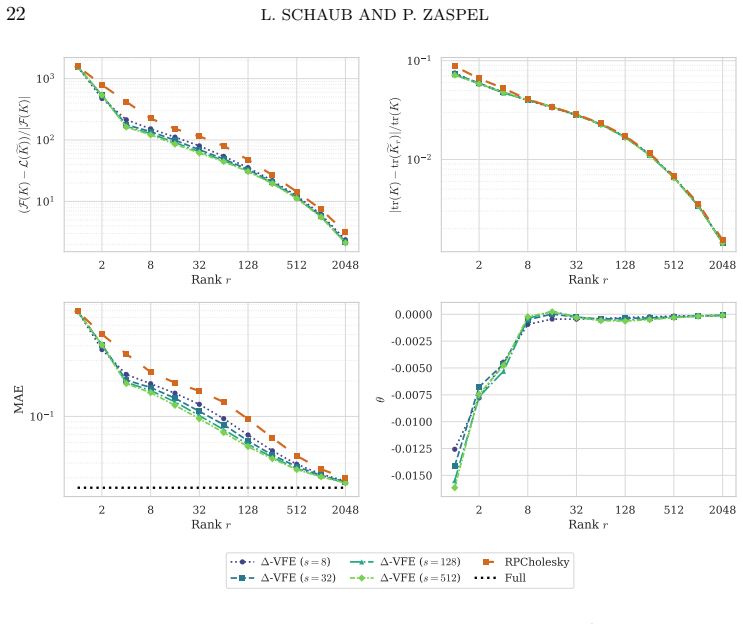
The central claim is that the one-step change in the variational free energy functional under a Cholesky-consistent rank-1 update admits an exact closed-form additive decomposition into complexity, data-fit, and trace contributions. This quantity is used directly as the pivot-selection rule, called Δ-VFE pivoted Cholesky. Candidates are drawn in batches of size s proportionally to the residual diagonal and the criterion is evaluated via incremental Woodbury updates. The resulting method produces monotonically non-decreasing functional values and selects the locally maximal-gain pivot among the sampled candidates.
What carries the argument
The per-step gain of the variational free energy functional, which decomposes additively into complexity, data-fit, and trace contributions and serves as the pivot criterion.
If this is right
- Each accepted update raises the variational free energy value, so the sequence is monotonically non-decreasing.
- The method attains higher objective values and better predictive accuracy than trace-based rules at low to moderate ranks.
- Trace-norm approximation quality remains comparable to randomly pivoted Cholesky.
- The per-iteration cost stays O(s n r^2) and therefore matches randomly pivoted Cholesky up to the constant batch factor s.
Where Pith is reading between the lines
- The same one-step gain-maximization construction could be applied to other matrix functionals that arise in downstream tasks beyond the specific log-det-plus-quadratic-plus-trace combination.
- When the matrix enters a nonlinear objective whose value directly controls decisions, replacing norm-based proxies with the exact functional gain may systematically improve end-task performance even if algebraic error metrics stay the same.
- The batch-sampling strategy proportional to the residual diagonal could be reused with any other pivot criterion that admits an incremental evaluation formula.
Load-bearing premise
That maximizing the one-step change in this particular functional produces globally superior low-rank approximations for the applications of interest rather than merely locally better steps.
What would settle it
A controlled experiment on a kernel matrix from Gaussian process regression in which the Δ-VFE method returns a lower final functional value or worse predictive accuracy than randomly pivoted Cholesky at identical target rank.
Figures
read the original abstract
Pivoted Cholesky factorizations construct low-rank approximations of symmetric positive definite matrices by sequentially selecting pivots from the residual diagonal. Classical greedy and randomized rules, such as randomly pivoted Cholesky, target the algebraic trace-norm error of the residual. In many applications, however, the matrix enters a nonlinear matrix functional whose value, not the trace-norm error, determines solution quality, and residual-based rules ignore this structure. We derive a pivot rule that maximizes the exact one-step change of such a functional under Cholesky-consistent rank-1 updates, for a functional combining log-determinant, quadratic, and trace terms. This functional arises as the variational free energy in Gaussian process regression, where the matrix is a kernel matrix. The resulting per-step gain admits a closed-form additive decomposition into complexity, data-fit, and trace contributions, and is used directly as a pivot-selection criterion. We refer to the resulting method as $\Delta$-VFE pivoted Cholesky. At each iteration, the criterion is evaluated on a batch of $s$ candidate pivots sampled proportionally to the residual diagonal via incremental Woodbury updates, at a total cost of $\mathcal{O}(snr^2)$ for an $n\times n$ matrix and target rank $r$. This matches the asymptotic complexity of randomly pivoted Cholesky up to the batch factor $s$. Cholesky-consistent rank-1 updates yield monotonically non-decreasing functional values, and the proposed rule maximizes the per-step gain among them. Numerical experiments show improved objective values and predictive accuracy at low to moderate ranks compared to classical and randomly pivoted Cholesky, while preserving trace-norm approximation quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Δ-VFE pivoted Cholesky for low-rank approximation of symmetric positive definite kernel matrices. It derives a pivot-selection rule that maximizes the exact one-step change in a variational free energy functional (log-determinant + quadratic + trace) under Cholesky-consistent rank-1 updates, provides a closed-form additive decomposition of the per-step gain into complexity, data-fit, and trace terms, and implements the criterion by evaluating it on a batch of s candidates sampled proportionally to the residual diagonal using incremental Woodbury updates. The method is claimed to produce monotonically non-decreasing functional values and to outperform classical and randomly pivoted Cholesky on objective values and predictive accuracy at low to moderate ranks while preserving trace-norm quality.
Significance. If the closed-form gain derivation is correct and the method reliably improves VFE values over trace-norm baselines, the work would offer a principled alternative to algebraic-error-driven pivoting for applications such as Gaussian process regression where the functional itself determines downstream quality. The explicit decomposition of the gain and the preservation of monotonicity are technical strengths that could generalize to other matrix functionals.
major comments (1)
- [Abstract] Abstract: The central claim states that 'the proposed rule maximizes the per-step gain among' Cholesky-consistent rank-1 updates. However, the described algorithm samples s candidates proportionally to the residual diagonal (the classical trace-norm heuristic) and then selects the best among that batch via the VFE criterion. This means the implemented procedure maximizes the gain only within the sampled subset, not among all possible rank-1 updates; the exact argmax property therefore does not hold for the practical method. Monotonicity is preserved for any chosen update, but the maximization statement is load-bearing for the contribution and requires explicit qualification or a corrected claim.
minor comments (2)
- [Abstract] The abstract asserts that the per-step gain 'admits a closed-form additive decomposition' but does not display the explicit expression; the full manuscript should include the derivation (likely in the methods section) with all intermediate steps shown.
- [Abstract] Complexity is stated as O(s n r²); the manuscript should clarify whether this includes the cost of the Woodbury updates for all s candidates or only the selected pivot, and how s is chosen in practice.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for highlighting the need to qualify the maximization claim in the abstract. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim states that 'the proposed rule maximizes the per-step gain among' Cholesky-consistent rank-1 updates. However, the described algorithm samples s candidates proportionally to the residual diagonal (the classical trace-norm heuristic) and then selects the best among that batch via the VFE criterion. This means the implemented procedure maximizes the gain only within the sampled subset, not among all possible rank-1 updates; the exact argmax property therefore does not hold for the practical method. Monotonicity is preserved for any chosen update, but the maximization statement is load-bearing for the contribution and requires explicit qualification or a corrected claim.
Authors: We agree that the abstract wording is imprecise for the implemented algorithm. The derivation supplies the exact one-step gain for any Cholesky-consistent rank-1 update, so the ideal rule would indeed select the global argmax over all remaining indices. In practice, exhaustive evaluation is O(n) per step and prohibitive; therefore the method evaluates the criterion only on a batch of s candidates drawn proportionally to the residual diagonal (exactly as in randomized pivoted Cholesky) and chooses the best within that batch. The resulting procedure therefore maximizes the gain among the sampled candidates rather than over the full set. We will revise the abstract to state this distinction explicitly while retaining the claim that any chosen update produces a monotonically non-decreasing functional value. The core technical contributions—the closed-form additive decomposition of the gain and the O(snr²) incremental evaluation—remain unchanged and continue to justify the method as a principled, functional-aware alternative to trace-norm pivoting. revision: yes
Circularity Check
No circularity: gain expression derived directly from functional via rank-1 algebra
full rationale
The paper defines the variational free energy functional (log-det + quadratic + trace), then algebraically computes its exact one-step change under Cholesky rank-1 updates to obtain a closed-form gain decomposition. This expression is then used as the selection criterion. No parameter is fitted to data and then renamed a prediction; no self-citation chain supports a uniqueness claim; the batch sampling is an efficiency approximation to the argmax, not a redefinition that collapses the derivation. The central mathematical step is self-contained and falsifiable against the functional definition itself.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The matrix functional combining log-determinant, quadratic, and trace terms is the variational free energy arising in Gaussian process regression.
- standard math Cholesky-consistent rank-1 updates produce monotonically non-decreasing functional values.
Reference graph
Works this paper leans on
-
[1]
When Gaussian Process Meets Big Data: A Review of Scalable GPs , year=
Liu, Haitao and Ong, Yew-Soon and Shen, Xiaobo and Cai, Jianfei , journal=. When Gaussian Process Meets Big Data: A Review of Scalable GPs , year=
-
[2]
2005 , title =
Journal of Machine Learning Research , file =. 2005 , title =
2005
-
[3]
Journal of Machine Learning Research , year =
James Hensman and Nicolas Durrande and Arno Solin , title =. Journal of Machine Learning Research , year =
-
[4]
Revisiting the
Gittens, Alex and Mahoney, Michael , booktitle =. Revisiting the. 2013 , editor =
2013
-
[5]
Using the
Williams, Christopher and Seeger, Matthias , year =. Using the. Advances in Neural Information Processing Systems , file =
-
[6]
2006 , publisher=
Rasmussen, Carl Edward and Williams, Christopher KI , volume=. 2006 , publisher=
2006
-
[7]
Variational Learning of Inducing Variables in Sparse
Titsias, Michalis , booktitle =. Variational Learning of Inducing Variables in Sparse. 2009 , editor =
2009
-
[8]
Mahoney , title =
Petros Drineas and Michael W. Mahoney , title =. Journal of Machine Learning Research , year =
-
[9]
2010 , eprint=
Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions , author=. 2010 , eprint=
2010
-
[10]
Rupp, Matthias and Tkatchenko, Alexandre and Müller, Klaus-Robert and von Lilienfeld, O. Anatole , year=. Fast and Accurate Modeling of Molecular Atomization Energies with Machine Learning , volume=. Physical Review Letters , publisher=. doi:10.1103/physrevlett.108.058301 , number=
-
[11]
1994 , howpublished =
Nash, Warwick and Sellers, Tracy and Talbot, Simon and Cawthorn, Andrew and Ford, Wes , title =. 1994 , howpublished =
1994
-
[12]
2002 , publisher=
Learning with kernels: support vector machines, regularization, optimization, and beyond , author=. 2002 , publisher=
2002
-
[13]
Randomly pivoted
Chen, Yifan and Epperly, Ethan N and Tropp, Joel A and Webber, Robert J , journal=. Randomly pivoted. 2025 , publisher=
2025
-
[14]
and Tropp, Joel A
Epperly, Ethan N. and Tropp, Joel A. and Webber, Robert J. , title =. SIAM Journal on Matrix Analysis and Applications , volume =. 2025 , doi =
2025
-
[15]
Efficient sparsification for Gaussian process regression , journal =
Jens Schreiter and Duy Nguyen-Tuong and Marc Toussaint , keywords =. Efficient sparsification for Gaussian process regression , journal =. 2016 , issn =. doi:https://doi.org/10.1016/j.neucom.2016.02.032 , url =
-
[16]
Filip de Roos and Fabio Muratore , year=. Novel Pivoted. 2507.20678 , archivePrefix=
-
[17]
On the low-rank approximation by the pivoted
Helmut Harbrecht and Michael Peters and Reinhold Schneider , keywords =. On the low-rank approximation by the pivoted. Applied Numerical Mathematics , volume =. 2012 , issn =. doi:https://doi.org/10.1016/j.apnum.2011.10.001 , url =
-
[18]
Sparse G aussian process approximations and applications
Mark van der Wilk. Sparse G aussian process approximations and applications. 2019
2019
-
[19]
1998 , publisher=
Matrix algebra from a statistician's perspective , author=. 1998 , publisher=
1998
-
[20]
Fast Randomized Kernel Ridge Regression with Statistical Guarantees , url =
Alaoui, Ahmed and Mahoney, Michael W , booktitle =. Fast Randomized Kernel Ridge Regression with Statistical Guarantees , url =
-
[21]
L. C. Blum and J.-L. Reymond , title =. J. Am. Chem. Soc
-
[22]
Rupp and A
M. Rupp and A. Tkatchenko and K.-R. M\"uller and O. A. von Lilienfeld , title =. Physical Review Letters
-
[23]
2008 , publisher=
Support vector machines , author=. 2008 , publisher=
2008
-
[24]
Springer , edition=
Pattern recognition and machine learning , author=. Springer , edition=. 2006 , publisher=
2006
-
[25]
Recursive Sampling for the
Musco, Cameron and Musco, Christopher , booktitle =. Recursive Sampling for the
-
[26]
Martinsson, Per-Gunnar and Tropp, Joel A. , year=. Randomized numerical linear algebra: Foundations and algorithms , volume=. doi:10.1017/S0962492920000021 , journal=
-
[27]
Automatic model construction with
Duvenaud, David , year=. Automatic model construction with. doi:10.17863/CAM.14087 , school=
-
[28]
Higham, Nicholas J , isbn =. Analysis of the. Reliable Numerical Commputation , publisher =. 1990 , abstract =. doi:10.1093/oso/9780198535645.003.0010 , url =
-
[29]
Higham, Nicholas J. , title =. WIREs Computational Statistics , volume =. doi:https://doi.org/10.1002/wics.18 , url =. https://wires.onlinelibrary.wiley.com/doi/pdf/10.1002/wics.18 , abstract =
-
[30]
Rates of Convergence for Sparse Variational
Burt, David and Rasmussen, Carl Edward and Van Der Wilk, Mark , booktitle =. Rates of Convergence for Sparse Variational. 2019 , editor =
2019
-
[31]
Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence , pages =
Hensman, James and Fusi, Nicol\`. Proceedings of the Twenty-Ninth Conference on Uncertainty in Artificial Intelligence , pages =. 2013 , publisher =
2013
-
[32]
A Unifying View of Sparse Approximate
Joaquin Qui. A Unifying View of Sparse Approximate. Journal of Machine Learning Research , year =
-
[33]
and Van Loan, Charles F
Golub, Gene H. and Van Loan, Charles F. , title =. 2013 , doi =
2013
-
[34]
and Martinsson, P
Halko, N. and Martinsson, P. G. and Tropp, J. A. , title =. SIAM Review , volume =. 2011 , doi =
2011
-
[35]
and Johnson, Charles R
Horn, Roger A. and Johnson, Charles R. , year=. Matrix Analysis , publisher=
-
[36]
Kernel techniques: From machine learning to meshless methods , volume=
Schaback, Robert and Wendland, Holger , year=. Kernel techniques: From machine learning to meshless methods , volume=. doi:10.1017/S0962492906270016 , journal=
-
[37]
Bach, Francis R. and Jordan, Michael I. , title =. Proceedings of the 22nd International Conference on Machine Learning , pages =. 2005 , isbn =. doi:10.1145/1102351.1102356 , abstract =
-
[38]
Proceedings of the 26th Annual Conference on Learning Theory , pages =
Sharp analysis of low-rank kernel matrix approximations , author =. Proceedings of the 26th Annual Conference on Learning Theory , pages =. 2013 , editor =
2013
-
[39]
Efficient Optimization for Sparse
Cao, Yanshuai and Brubaker, Marcus and Fleet, David J and Hertzmann, Aaron , booktitle =. Efficient Optimization for Sparse
-
[40]
and Fleet, David J
Cao, Yanshuai and Brubaker, Marcus A. and Fleet, David J. and Hertzmann, Aaron , journal=. Efficient Optimization for Sparse. 2015 , volume=
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.