Are Economists Open to AI? Text as Data as Survey on Professional Sentiment and Academic Research Trends
Pith reviewed 2026-06-28 12:17 UTC · model grok-4.3
The pith
Economists display less openness and more negativity toward AI in cross-section, but attitudes improve on all six dimensions as AI becomes more visible in elite journals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
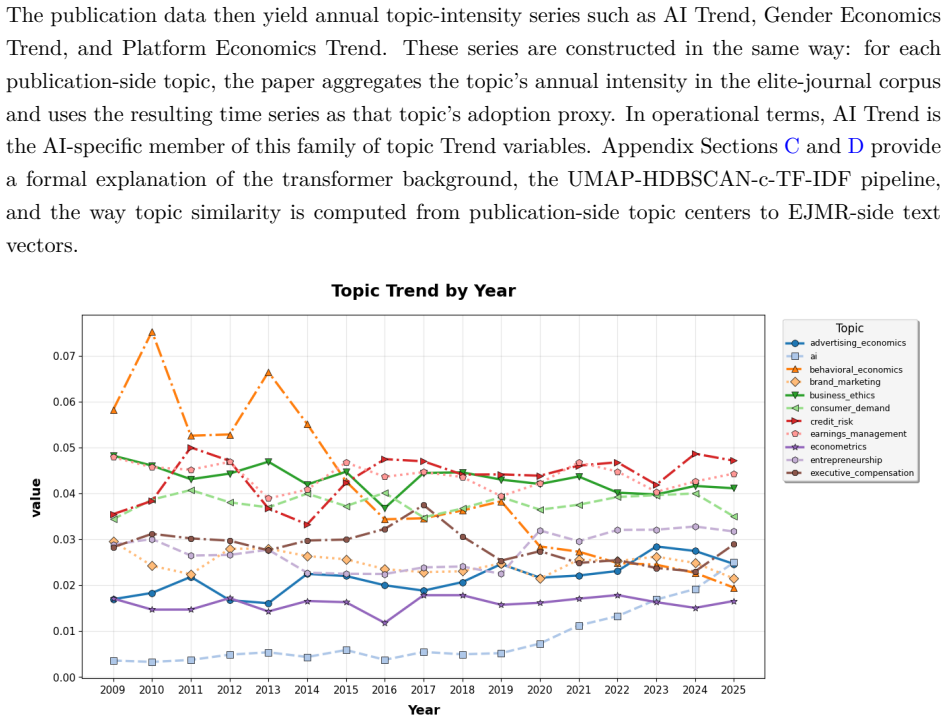
TaDaS first screens a reference question corpus to construct focal and comparable semantic neighborhoods. It then maps unstructured observations from an answer corpus onto these neighborhoods and scores the attitudes expressed in the resulting discourse. Applied to economists, AI-related discussion is less open and more negative in cross-section, but the interaction evidence points in a favorable direction on all six dimensions as AI becomes more visible in elite journals.
What carries the argument
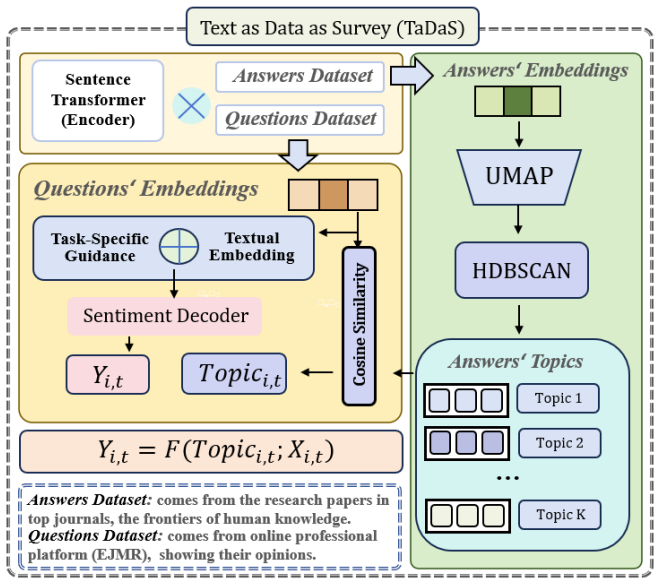
The TaDaS framework, which converts text into survey-like evidence through cross-dataset semantic retrieval between a publication question corpus and a forum answer corpus to score attitudes on six dimensions.
If this is right
- AI visibility in elite journals is associated with more positive professional sentiment among economists.
- Text-based methods can recover retrospective measures of sentiment from existing archives.
- Cross-sectional comparisons may miss dynamic improvements in attitudes over time.
- The six dimensions of openness, negativity, toxicity, arrogance, curiosity, and confusion can be tracked simultaneously in discourse.
- Forum discussions reflect professional reactions that evolve with research trends.
Where Pith is reading between the lines
- The method could be applied to track sentiment toward other emerging technologies or ideas in different academic fields.
- If validated, it might reduce reliance on reactive surveys for understanding community adoption of new tools.
- The trend suggests that publication success of AI papers may help normalize their use among economists.
- Extensions could include testing the method on non-English text or other forum types to check robustness.
Load-bearing premise
That the semantic retrieval between publication questions and forum answers accurately reflects true attitudes without major distortions from differences in language, platform, or retrieval accuracy.
What would settle it
Finding that hand-coded sentiment labels on a sample of AI-related forum posts differ substantially from the scores assigned by the TaDaS retrieval and scoring process.
Figures





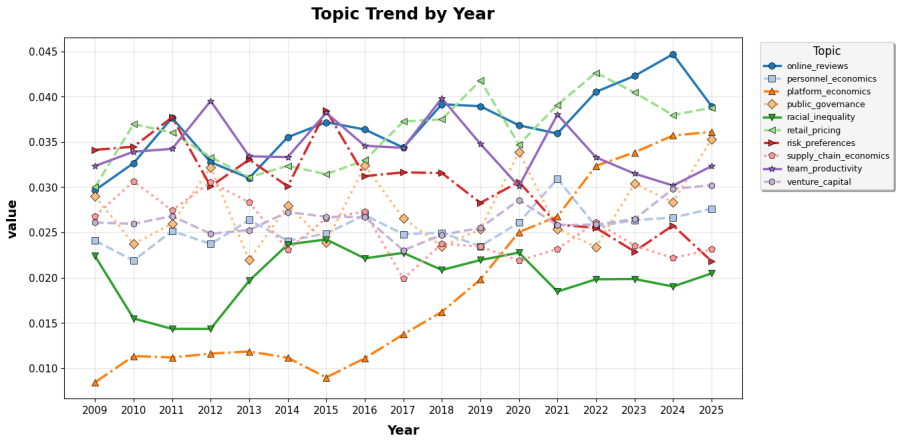
read the original abstract
Traditional surveys are costly, hard to reconstruct retrospectively, and vulnerable to self-presentation bias. Raw internet text is abundant but noisy, weakly structured, and platform-selected. We introduce TaDaS (Text as Data as Survey), a framework that converts naturally occurring text into survey-like evidence by linking a question corpus to an answer corpus through cross-dataset semantic retrieval. TaDaS first screens a reference question corpus to construct focal and comparable semantic neighborhoods. It then maps unstructured observations from an answer corpus onto these neighborhoods and scores the attitudes expressed in the resulting discourse. We apply the framework to economists' reactions to AI by linking 1.3 million research-related posts from Economics Job Market Rumors with 53,585 elite economics and finance publications. Publication-side topics define the research frontier; forum-side replies reveal professional sentiment along six dimensions: openness, negativity, toxicity, arrogance, curiosity, and confusion. AI-related discussion is less open and more negative in cross-section, but the interaction evidence points in a favorable direction on all six dimensions as AI becomes more visible in elite journals. The findings show how TaDaS can recover scalable, retrospective, and non-reactive measures of professional sentiment from existing text archives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TaDaS (Text as Data as Survey), a framework that constructs focal semantic neighborhoods from a question corpus of 53,585 elite economics and finance publications and maps them via cross-dataset semantic retrieval onto an answer corpus of 1.3 million EJMR posts. It scores the resulting discourse along six attitude dimensions (openness, negativity, toxicity, arrogance, curiosity, confusion) to measure economists' sentiment toward AI. The central empirical claim is that AI-related discussion is less open and more negative in cross-section, yet interaction evidence shows favorable movement on all six dimensions as AI visibility increases in elite journals. The method is positioned as recovering scalable, retrospective, non-reactive sentiment measures from existing text archives.
Significance. If the retrieval step can be shown to be reliable, TaDaS would supply a practical alternative to traditional surveys for reconstructing professional sentiment at scale and over time, with direct applicability to questions about technology adoption, field-level opinion dynamics, and the evolution of research agendas in economics. The approach also demonstrates how publication-derived topics can serve as anchors for interpreting unstructured forum data.
major comments (1)
- [TaDaS framework and application description] The central claim rests on the accuracy of cross-dataset semantic retrieval between the publication-derived neighborhoods and the EJMR answer corpus, yet the manuscript supplies no validation metrics, human-coded precision/recall estimates, inter-annotator agreement, ablation on embedding models or similarity thresholds, or error analysis for domain shift between formal academic prose and informal forum language. This is load-bearing: without such checks, the reported cross-sectional negativity and the interaction trends with journal visibility cannot be distinguished from retrieval artifacts.
minor comments (2)
- The six attitude dimensions are introduced without explicit operational definitions or example scoring rubrics, making it difficult to assess how the semantic mapping translates into quantitative scores.
- The manuscript would benefit from a clearer statement of the exact similarity function and any preprocessing steps applied to the two corpora before retrieval.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The primary concern is the absence of validation for the semantic retrieval component, which we address directly below by committing to specific additions in revision.
read point-by-point responses
-
Referee: The central claim rests on the accuracy of cross-dataset semantic retrieval between the publication-derived neighborhoods and the EJMR answer corpus, yet the manuscript supplies no validation metrics, human-coded precision/recall estimates, inter-annotator agreement, ablation on embedding models or similarity thresholds, or error analysis for domain shift between formal academic prose and informal forum language. This is load-bearing: without such checks, the reported cross-sectional negativity and the interaction trends with journal visibility cannot be distinguished from retrieval artifacts.
Authors: We agree that validation of the retrieval step is essential and that its absence leaves the empirical results open to the interpretation raised. The current manuscript relies on standard embedding-based semantic similarity without reporting the requested diagnostics. In the revised version we will add a dedicated validation section containing: (i) human-coded precision and recall on a stratified sample of 300 retrieved posts, (ii) inter-annotator agreement (Cohen’s kappa) from two independent coders, (iii) ablation tables across two embedding models and three similarity thresholds, and (iv) a qualitative error analysis that explicitly discusses domain-shift failures. These additions will allow readers to gauge whether the reported sentiment patterns survive reasonable retrieval perturbations. revision: yes
Circularity Check
No significant circularity; method applies independent corpora via external semantic retrieval.
full rationale
The paper introduces TaDaS as a framework that links a publication-derived question corpus (53k elite papers) to an independent answer corpus (1.3M EJMR posts) through cross-dataset semantic retrieval, then scores attitudes on six dimensions. No equations, fitted parameters, or self-citations are described that reduce the reported sentiment trends or interaction effects to quantities defined by the same inputs. The two corpora are treated as separate external data sources, and the central claims rest on the retrieval mapping rather than any definitional loop or renamed fit. This is the normal case of a self-contained empirical application with no load-bearing reduction to its own construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Artificial Intelligence and Jobs: Evidence from Online Vacancies , journal =
Acemoglu, Daron and Autor, David and Hazell, Jonathon and Restrepo, Pascual , year =. Artificial Intelligence and Jobs: Evidence from Online Vacancies , journal =. doi:10.1086/718327 , note =
-
[2]
and Morris, L
Alberti, Cristina T. and Morris, L. , year =. Online Toxic Communication about the Accounting Academic Job Market , journal =
-
[3]
Araci, Dogu , year =
-
[4]
, year =
Autor, David H. , year =. Why Are There Still So Many Jobs? The History and Future of Workplace Automation , journal =
-
[5]
and Bloom, Nicholas and Davis, Steven J
Baker, Scott R. and Bloom, Nicholas and Davis, Steven J. , year =. Measuring Economic Policy Uncertainty , journal =
-
[6]
Research Similarity and Women in Academia , journal =
Bello, Paolo and Casarico, Alessandra and Nozza, Debora , year =. Research Similarity and Women in Academia , journal =
-
[7]
Do People Mean What They Say? Implications for Subjective Survey Data , journal =
Bertrand, Marianne and Mullainathan, Sendhil , year =. Do People Mean What They Say? Implications for Subjective Survey Data , journal =
-
[8]
and Ng, Andrew Y
Blei, David M. and Ng, Andrew Y. and Jordan, Michael I. , year =. Latent Dirichlet Allocation , journal =
-
[9]
The Specificity of the Scientific Field and the Social Conditions of the Progress of Reason , journal =
Bourdieu, Pierre , year =. The Specificity of the Scientific Field and the Social Conditions of the Progress of Reason , journal =
-
[10]
Brown, Tom B. and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel M. and Wu, Jeffrey and W...
-
[11]
Generative
Brynjolfsson, Erik and Li, Danielle and Raymond, Lindsey , year =. Generative. Quarterly Journal of Economics , volume =
-
[12]
Campello, Ricardo J. G. B. and Moulavi, Davoud and Sander, Joerg , year =. Density-Based Clustering Based on Hierarchical Density Estimates , booktitle =
-
[13]
Anyone Can Become a Troll: Causes of Trolling Behavior in Online Discussions , booktitle =
Cheng, Justin and Bernstein, Michael and Danescu-Niculescu-Mizil, Cristian and Leskovec, Jure , year =. Anyone Can Become a Troll: Causes of Trolling Behavior in Online Discussions , booktitle =
-
[14]
Invisible Colleges: Diffusion of Knowledge in Scientific Communities , publisher =
Crane, Diana , year =. Invisible Colleges: Diffusion of Knowledge in Scientific Communities , publisher =
-
[15]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages =
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , year =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT) , pages =
2019
-
[16]
and Wahba, Sadek , year =
Dehejia, Rajeev H. and Wahba, Sadek , year =. Propensity Score-Matching Methods for Nonexperimental Causal Studies , journal =
-
[17]
Anonymous Attention and Abuse , journal =
Ederer, Florian and Goldsmith-Pinkham, Paul and Jensen, Kyle , year =. Anonymous Attention and Abuse , journal =
-
[18]
Eloundou, Tyna and Manning, Sam and Mishkin, Pamela and Rock, Daniel , year =
-
[19]
Measuring Misinformation in Financial Markets , note =
Fan, Jiahua and Liu, Qiang and Song, Yifei and Wang, Zhuo , year =. Measuring Misinformation in Financial Markets , note =
-
[20]
and Raj, Manav and Seamans, Robert , year =
Felten, Edward W. and Raj, Manav and Seamans, Robert , year =. Occupational, Industry, and Geographic Exposure to Artificial Intelligence: A Novel Dataset and Its Potential Uses , journal =
-
[21]
and Hilbert, Martin , year =
Flores, Pamela M. and Hilbert, Martin , year =. Lean-back and Lean-forward Online Behaviors: The Role of Emotions in Passive versus Proactive Information Diffusion of Social Media Content , journal =
-
[22]
Text as Data , journal =
Gentzkow, Matthew and Kelly, Bryan and Taddy, Matt , year =. Text as Data , journal =
-
[23]
Proceedings of the National Academy of Sciences , volume =
Gilardi, Fabrizio and Alizadeh, Meysam and Kubli, Mael , year =. Proceedings of the National Academy of Sciences , volume =
-
[24]
Tracking the Credibility Revolution Across Fields , note =
Goldsmith-Pinkham, Paul , year =. Tracking the Credibility Revolution Across Fields , note =
-
[25]
, year =
Grimmer, Justin and Stewart, Brandon M. , year =. Text as Data: The Promise and Pitfalls of Automatic Content Analysis Methods for Political Texts , journal =
-
[26]
and Fowler, Floyd J
Groves, Robert M. and Fowler, Floyd J. and Couper, Mick P. and Lepkowski, James M. and Singer, Eleanor and Tourangeau, Roger , year =. Survey Methodology , edition =
-
[27]
Grootendorst, Maarten , year =
-
[28]
and Xu, F
Hao, Q. and Xu, F. and Li, Y. and Evans, J. , year =. Artificial Intelligence Tools Expand Scientists' Impact but Contract Science's Focus , journal =
-
[29]
and Hollander, Stephan and Kalyani, A
Hassan, Tarek A. and Hollander, Stephan and Kalyani, A. and van Lent, Laurence and Schwedeler, M. and Tahoun, Ahmed , year =. Text as Data in Economic Analysis , journal =
-
[30]
and Ichimura, Hidehiko and Todd, Petra , year =
Heckman, James J. and Ichimura, Hidehiko and Todd, Petra , year =. Matching as an Econometric Evaluation Estimator , journal =
-
[31]
Text-Based Network Industries and Endogenous Product Differentiation , journal =
Hoberg, Gerard and Phillips, Gordon , year =. Text-Based Network Industries and Endogenous Product Differentiation , journal =
-
[32]
, year =
Kanazawa, Kyogo and Kawaguchi, Daiji and Shigeoka, Hitoshi and Watanabe, Y. , year =
-
[33]
and Mankad, S
Chen, L. and Mankad, S. , year =. A Structural Topic and Sentiment-Discourse Model for Text Analysis , journal =
-
[34]
and Zhang, X
Cong, Lin William and Liang, T. and Zhang, X. and Zhu, W. , year =. Textual Factors: A Scalable, Interpretable, and Data-Driven Approach to Analyzing Unstructured Information , journal =
-
[35]
Locatelli, M. S. and Calais, P. H. and Miranda, M. P. and Junho, J. P. and Muniz, T. L. and Meira Jr., Wagner and Almeida, Virgilio , year =. Topic Shifts as a Proxy for Assessing Politicization in Social Media , booktitle =. doi:10.1609/icwsm.v18i1.31366 , note =
-
[36]
When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks , journal =
Loughran, Tim and McDonald, Bill , year =. When Is a Liability Not a Liability? Textual Analysis, Dictionaries, and 10-Ks , journal =
-
[37]
hdbscan: Hierarchical Density Based Clustering , journal =
McInnes, Leland and Healy, John and Astels, Steve , year =. hdbscan: Hierarchical Density Based Clustering , journal =
-
[38]
Journal of Open Source Software , volume =
McInnes, Leland and Healy, John and Saul, Nathaniel and Grossberger, Lukas , year =. Journal of Open Source Software , volume =
-
[39]
, year =
Merton, Robert K. , year =. The Matthew Effect in Science: The Reward and Communication Systems of Science Are Considered , journal =
-
[40]
Liu, Yinhan and Ott, Myle and Goyal, Naman and Du, Jingfei and Joshi, Mandar and Chen, Danqi and Levy, Omer and Lewis, Mike and Zettlemoyer, Luke and Stoyanov, Veselin , year =
-
[41]
Liu, Z. and Yang, K. and Xie, Q. and Zhang, T. and Ananiadou, S. , year =. Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD) , pages =. doi:10.1145/3637528.3671552 , note =
-
[42]
Ouyang, Long and Wu, Jeffrey and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe...
-
[43]
Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence , journal =
Noy, Shakked and Zhang, Whitney , year =. Experimental Evidence on the Productivity Effects of Generative Artificial Intelligence , journal =
-
[44]
and Gurevych, Iryna , year =
Pramanick, Aniket and Hou, Yufang and Mohammad, Saif M. and Gurevych, Iryna , year =. Transforming Scholarly Landscapes: The Influence of Large Language Models on Academic Fields Beyond Computer Science , journal =
-
[45]
Reimers, Nils and Gurevych, Iryna , year =. Sentence-. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages =. doi:10.18653/v1/D19-1410 , note =
-
[46]
and Stewart, Brandon M
Roberts, Margaret E. and Stewart, Brandon M. and Tingley, Dustin and Lucas, Christopher and Leder-Luis, Jetson and Gadarian, Shana Kushner and Albertson, Bethany and Rand, David G. , year =. Structural Topic Models for Open-Ended Survey Responses , journal =
-
[47]
and Rubin, Donald B
Rosenbaum, Paul R. and Rubin, Donald B. , year =. The Central Role of the Propensity Score in Observational Studies for Causal Effects , journal =
-
[48]
The News in Earnings Announcement Disclosures: Capturing Word Context Using
Siano, Francesco , year =. The News in Earnings Announcement Disclosures: Capturing Word Context Using. Management Science , volume =. doi:10.1287/mnsc.2024.05417 , note =
-
[49]
The Online Disinhibition Effect , journal =
Suler, John , year =. The Online Disinhibition Effect , journal =
-
[50]
and Kaiser, Lukasz and Polosukhin, Illia , year =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser, Lukasz and Polosukhin, Illia , year =. Attention Is All You Need , booktitle =
-
[51]
Sensitive Questions in Surveys , journal =
Tourangeau, Roger and Yan, Ting , year =. Sensitive Questions in Surveys , journal =
-
[52]
, year =
Wu, Alice H. , year =. Gendered Language on the Economics Job Market Rumors Forum , journal =
-
[53]
Wu, Shijie and Irsoy, Ozan and Lu, Steven and Dabravolski, Vyacheslav and Dredze, Mark and Gehrmann, Sebastian and Kambadur, Prabhanjan and Rosenberg, David and Mann, Gideon , year =
-
[54]
David Card and Stefano DellaVigna
Bybee, Leland and Kelly, Bryan and Manela, Asaf and Xiu, Dacheng , year =. Business News and Business Cycles , journal =. doi:10.1111/jofi.13377 , note =
-
[55]
Can Large Language Models Transform Computational Social Science? , journal =
Ziems, Caleb and Held, William and Shaikh, Omar and Chen, Jiaao and Zhang, Zhehao and Yang, Diyi , year =. Can Large Language Models Transform Computational Social Science? , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.