C2GA: A Class-Controllable Generative Augmentation Framework for Respiratory Sound Classification
Pith reviewed 2026-06-28 12:37 UTC · model grok-4.3
The pith
C2GA generates class-consistent respiratory sound augmentations by decoupling local tokens from global class prototypes in a conditional VQ-VAE.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
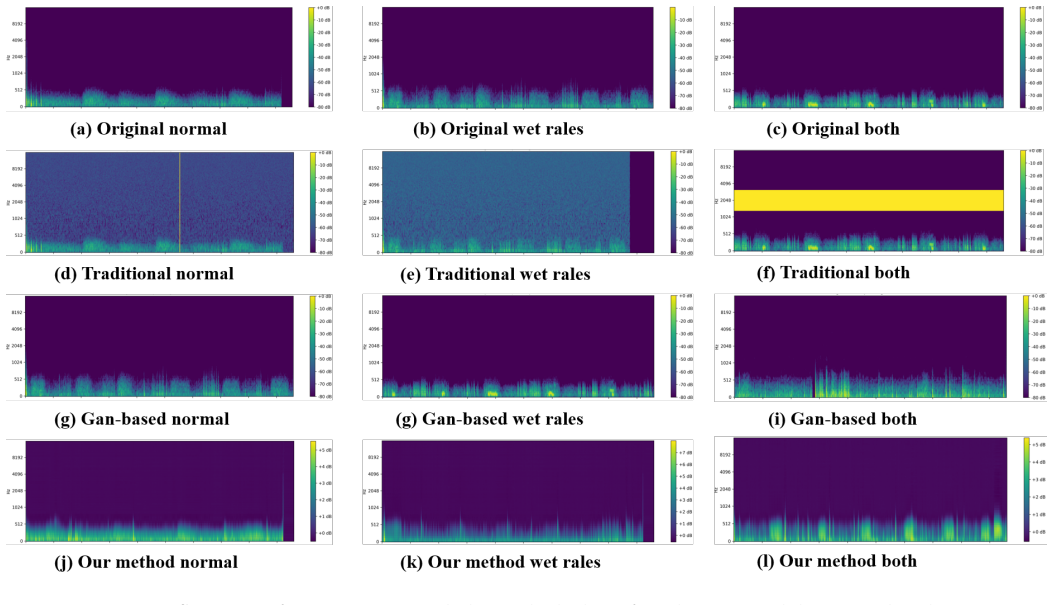
C2GA first constructs a semantically rich discrete latent space using a conditional Vector-Quantized Variational Autoencoder (VQ-VAE), in which local acoustic tokens are explicitly decoupled from global class prototypes. Subsequently, a Transformer-based autoregressive prior is trained to generate label-consistent token sequences. These generated tokens are then fused with the corresponding class prototypes and decoded into high-fidelity Mel-spectrograms for data augmentation.
What carries the argument
conditional VQ-VAE that decouples local acoustic tokens from global class prototypes, paired with a Transformer autoregressive prior for generating label-consistent sequences
If this is right
- Classifiers trained with the generated samples show improved robustness and generalization on real clinical respiratory sound data.
- The method handles class imbalance and noise better than conventional augmentation techniques.
- Generated samples maintain subtle pathological characteristics without semantic distortion.
- Controllability over class semantics enables targeted augmentation for specific pulmonary pathologies.
Where Pith is reading between the lines
- This approach might extend to other audio classification tasks involving imbalanced or noisy data, such as heart sounds or environmental audio.
- Future work could test the generated samples for perceptual quality using human listeners or additional metrics beyond classification accuracy.
- Integration with other modalities like patient metadata could further refine class prototypes.
Load-bearing premise
The decoupling of local acoustic tokens from global class prototypes preserves subtle pathological characteristics without introducing artifacts that distort class semantics or mislead classifiers.
What would settle it
An experiment showing that adding C2GA-generated samples to training sets results in no improvement or a decrease in classification accuracy on a held-out real-world respiratory sound test set, or that the generated spectrograms contain visible artifacts altering pathology indicators.
Figures
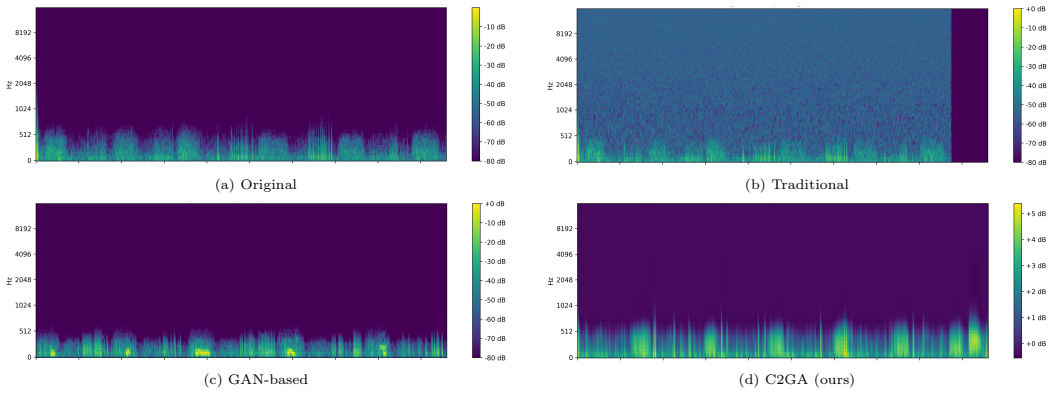
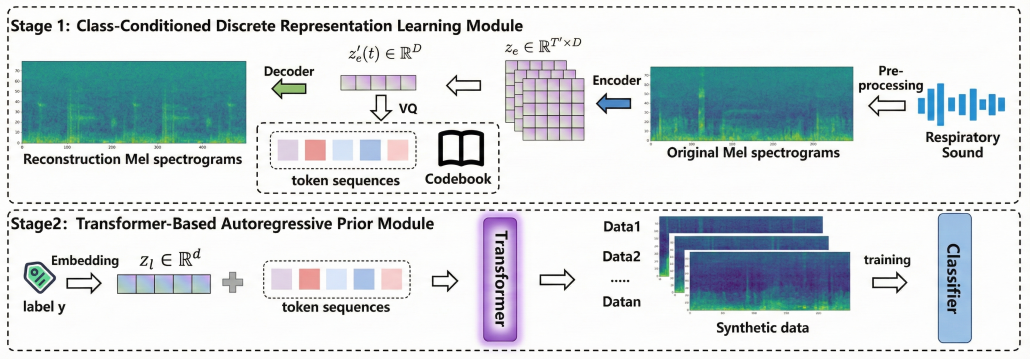
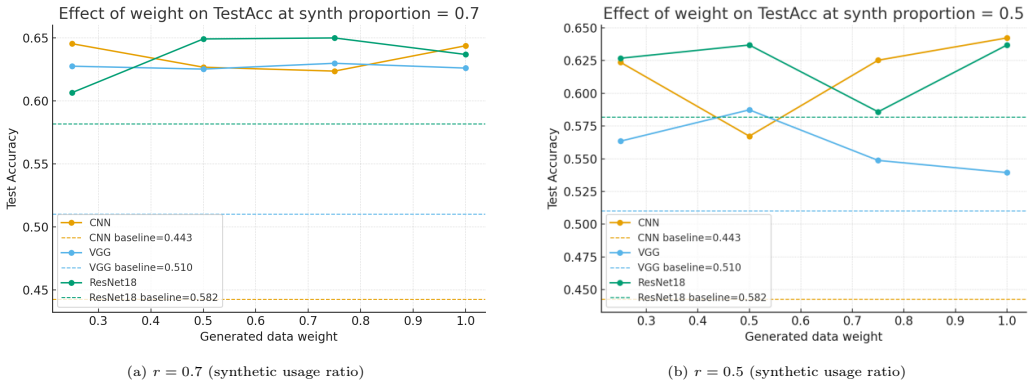
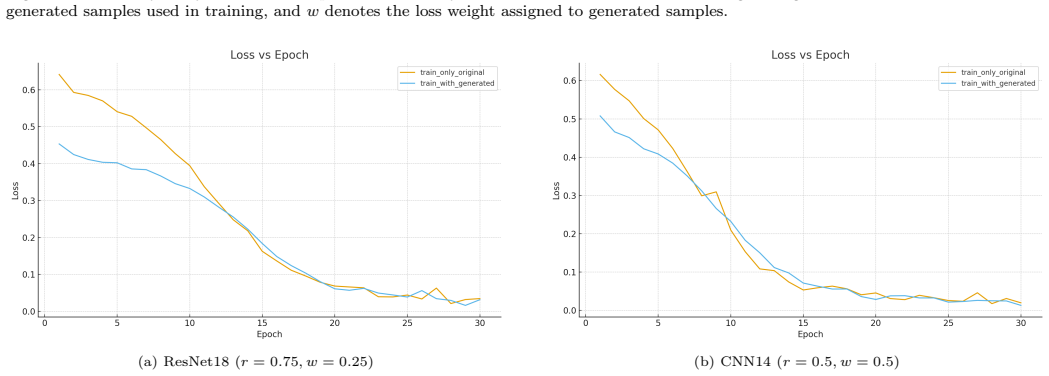
read the original abstract
Background: Respiratory sound classification plays a critical role in the clinical identification of pulmonary pathologies. However, its performance is often hindered by the limited size, severe noise, and class imbalance of real-world auscultation datasets. Although conventional audio augmentation techniques are easy to implement, they may inadvertently distort subtle pathological characteristics. Meanwhile, existing Variational Autoencoder (VAE)- or Generative Adversarial Network (GAN)-based generative approaches often suffer from limited sample fidelity and insufficient controllability over class semantics, particularly under conditions of scarce supervision. Methods: To overcome these limitations, we propose C2GA, a class-controllable generative augmentation framework. C2GA first constructs a semantically rich discrete latent space using a conditional Vector-Quantized Variational Autoencoder (VQ-VAE), in which local acoustic tokens are explicitly decoupled from global class prototypes. Subsequently, a Transformer-based autoregressive prior is trained to generate label-consistent token sequences. These generated tokens are then fused with the corresponding class prototypes and decoded into high-fidelity Mel-spectrograms for data augmentation. Conclusion: These results indicate that C2GA provides an effective and semantically reliable augmentation strategy for respiratory sound analysis. By enabling controllable and high-quality data generation, the proposed framework offers a promising solution for improving the robustness and generalization of respiratory sound classification in realistic clinical scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes C2GA, a class-controllable generative augmentation framework for respiratory sound classification. It constructs a discrete latent space via a conditional VQ-VAE that explicitly decouples local acoustic tokens from global class prototypes, trains a Transformer-based autoregressive prior on label-consistent token sequences, and decodes the outputs into Mel-spectrograms to augment limited, noisy, and imbalanced auscultation datasets.
Significance. If the claimed effectiveness and semantic reliability hold under empirical validation, the framework could meaningfully advance data augmentation techniques for medical audio classification by providing controllable, high-fidelity generation that preserves pathological features. The explicit decoupling mechanism addresses a known limitation of prior VAE/GAN approaches in this domain.
major comments (2)
- [Conclusion] Conclusion: The assertion that 'These results indicate that C2GA provides an effective and semantically reliable augmentation strategy' is unsupported, as the manuscript supplies no experimental results, quantitative metrics (e.g., accuracy, F1, AUC), baselines, datasets, error bars, or ablation studies to substantiate the central claim of effectiveness.
- [Methods] Methods (abstract description): The claim that decoupling local acoustic tokens from global class prototypes 'preserves subtle pathological characteristics without introducing artifacts' is presented without equations, loss terms, architectural diagrams, or training details that would allow verification of whether the construction achieves the intended separation.
minor comments (1)
- [Abstract] Abstract: The background states that conventional augmentations 'may inadvertently distort subtle pathological characteristics' but provides no citations or concrete examples of such distortions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments highlight important gaps in empirical support and methodological transparency. We address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Conclusion] Conclusion: The assertion that 'These results indicate that C2GA provides an effective and semantically reliable augmentation strategy' is unsupported, as the manuscript supplies no experimental results, quantitative metrics (e.g., accuracy, F1, AUC), baselines, datasets, error bars, or ablation studies to substantiate the central claim of effectiveness.
Authors: We agree that the conclusion statement is unsupported by any presented experiments. The manuscript as provided contains only a high-level description and does not include results, metrics, or ablation studies. We will revise the conclusion to remove the claim of empirical effectiveness and instead describe the framework as a proposed approach whose performance requires future validation. revision: yes
-
Referee: [Methods] Methods (abstract description): The claim that decoupling local acoustic tokens from global class prototypes 'preserves subtle pathological characteristics without introducing artifacts' is presented without equations, loss terms, architectural diagrams, or training details that would allow verification of whether the construction achieves the intended separation.
Authors: The provided manuscript text is limited to an abstract-level description and indeed lacks the requested equations, loss terms, diagrams, and training details. We will expand the methods section in the revised manuscript to include the conditional VQ-VAE architecture, explicit decoupling mechanism with corresponding loss functions, architectural diagrams, and training procedure to substantiate the separation claim. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, derivations, fitted parameters, or self-citations that could form a load-bearing chain. The framework is described as a conditional VQ-VAE with token decoupling plus an autoregressive prior, but the central claim of semantic reliability rests on external experimental results rather than any internal reduction to inputs by construction. No self-definitional, fitted-input, or uniqueness-imported steps are present.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Y. Chu, Q. Wang, E. Zhou, L. Fu, Q. Liu, G. Zheng, Cycleguardian: a framework for automatic respira- tory sound classification based on improved deep clus- teringandcontrastivelearning, Complex&Intelligent Systems 11 (4) (2025) 200
2025
-
[2]
Kumar, Y
D. Kumar, Y. Meena, K. Singh, et al., Respiratory sound classification utilizing human auditory-based feature extraction, Physica Scripta 100 (4) (2025) 046003
2025
-
[3]
Bahoura, Comparative studyofrespi- ratorysoundsclassificationmethodsbasedoncepstral analysis and artificial neural networks, Computers in Biology and Medicine 171 (2024) 108190
A.Semmad, M. Bahoura, Comparative studyofrespi- ratorysoundsclassificationmethodsbasedoncepstral analysis and artificial neural networks, Computers in Biology and Medicine 171 (2024) 108190
2024
-
[4]
J.-W. Kim, M. Toikkanen, A. Jalali, M. Kim, H.-J. Han, H. Kim, W. Shin, H.-Y. Jung, K. Kim, Adap- tive metadata-guided supervised contrastive learning for domain adaptation on respiratory sound classifi- cation, IEEE Journal of Biomedical and Health Infor- matics 29 (8) (2025) 5381–5393.doi:10.1109/JBHI. 2025.3545159
-
[5]
Razavi, A
A. Razavi, A. Van den Oord, O. Vinyals, Generating diverse high-fidelity images with vq-vae-2, Advances in neural information processing systems 32 (2019)
2019
-
[6]
A. Fan, M. Lewis, Y. Dauphin, Hierarchical neu- ral story generation, arXiv preprint arXiv:1805.04833 (2018)
Pith/arXiv arXiv 2018
-
[7]
T. Pál, B. Molnár, A respiratory sound database for the development of automated classifica-tion, in: 13th Joint Conference on Mathematics and Informatics, 2020
2020
-
[8]
Pandey, C
A. Pandey, C. Liu, Y. Wang, Y. Saraf, Dual appli- cation of speech enhancement for automatic speech recognition, in: 2021 IEEE spoken language technol- ogy workshop (SLT), IEEE, 2021, pp. 223–228
2021
-
[9]
Y.-J. Lu, X. Chang, C. Li, W. Zhang, S. Cornell, Z. Ni, Y. Masuyama, B. Yan, R. Scheibler, Z.-Q. Wang, et al., Espnet-se++: Speech enhancement for robust speech recognition, translation, and under- standing, arXiv preprint arXiv:2207.09514 (2022)
arXiv 2022
-
[10]
M. T. García-Ordás, J. A. Benítez-Andrades, I. García-Rodríguez, C. Benavides, H. Alaiz-Moretón, Detecting respiratory pathologies using convolutional neural networks and variational autoencoders for un- balancing data, Sensors 20 (4) (2020) 1214
2020
-
[11]
C. Donahue, J. McAuley, M. Puckette, Adversar- ial audio synthesis, arXiv preprint arXiv:1802.04208 (2018)
Pith/arXiv arXiv 2018
-
[12]
J.-W. Kim, C. Yoon, M. Toikkanen, S. Bae, H.-Y. Jung, Adversarial fine-tuning using generated respira- tory sound to address class imbalance, arXiv preprint arXiv:2311.06480 (2023)
arXiv 2023
-
[13]
H. Liu, Y. Yuan, X. Liu, X. Mei, Q. Kong, Q. Tian, Y. Wang, W. Wang, Y. Wang, M. D. Plumbley, Audi- oldm 2: Learning holistic audio generation with self- supervised pretraining, IEEE/ACM Transactions on Audio, Speech, and Language Processing (2024)
2024
-
[14]
H. He, E. A. Garcia, Learning from imbalanced data, IEEE Transactions on knowledge and data engineer- ing 21 (9) (2009) 1263–1284. 10
2009
-
[15]
T.-Y. Lin, P. Goyal, R. Girshick, K. He, P. Dollár, Focal loss for dense object detection, in: Proceedings of the IEEE international conference on computer vi- sion, 2017, pp. 2980–2988
2017
-
[16]
Petmezas, G.-A
G. Petmezas, G.-A. Cheimariotis, L. Stefanopoulos, B. Rocha, R. P. Paiva, A. K. Katsaggelos, N. Maglav- eras, Automated lung sound classification using a hy- brid cnn-lstm network and focal loss function, Sensors 22 (3) (2022) 1232
2022
-
[17]
L. Arts, E. H. T. Lim, P. M. van de Ven, L. He- unks, P. R. Tuinman, The diagnostic accuracy of lung auscultation in adult patients with acute pulmonary pathologies: a meta-analysis, Scientific Reports 10 (1) (2020) 7347
2020
-
[18]
Huang, Y.-H
W.-C. Huang, Y.-H. Tsai, Y.-F. Wei, P.-H. Kuo, C.- W. Tao, S.-L. Cheng, C.-H. Lee, Y.-K. Wu, N.-H. Chen, W.-H. Hsu, et al., Wheezing, a significant clin- ical phenotype of copd: experience from the taiwan obstructive lung disease study, International journal ofchronicobstructivepulmonarydisease(2015)2121– 2126
2015
-
[19]
Piirila, A
P. Piirila, A. Sovijarvi, Crackles: recording, analysis and clinical significance, European Respiratory Jour- nal 8 (12) (1995) 2139–2148
1995
-
[20]
Chambres, P
G. Chambres, P. Hanna, M. Desainte-Catherine, Au- tomatic detection of patient with respiratory diseases using lung sound analysis, in: 2018 International Conference on Content-Based Multimedia Indexing (CBMI), IEEE, 2018, pp. 1–6
2018
-
[21]
Y. Kim, Y. Hyon, S. S. Jung, S. Lee, G. Yoo, C. Chung, T. Ha, Respiratory sound classification for crackles, wheezes, and rhonchi in the clinical field using deep learning, Scientific reports 11 (1) (2021) 17186
2021
-
[22]
Wanasinghe, S
T. Wanasinghe, S. Bandara, S. Madusanka, D. Mee- deniya, M. Bandara, I. D. L. T. Díez, Lung sound classification with multi-feature integration utilizing lightweight cnn model, IEEE Access 12 (2024) 21262– 21276
2024
-
[23]
Pessoa, G
D. Pessoa, G. Petmezas, V. E. Papageorgiou, B. M. Rocha, L. Stefanopoulos, V. Kilintzis, N. Maglaveras, I. Frerichs, P. de Carvalho, R. P. Paiva, Pediatric res- piratory sound classification using a dual input deep learning architecture, in: 2023 IEEE Biomedical Cir- cuits and Systems Conference (BioCAS), IEEE, 2023, pp. 1–5
2023
-
[24]
9007–9011
S.Yu, Y.Ding, K.Qian, B.Hu, W.Li, B.W.Schuller, A glance-and-gaze network for respiratory sound clas- sification, in: ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), IEEE, 2022, pp. 9007–9011
2022
-
[25]
Z. Zhao, Z. Gong, M. Niu, J. Ma, H. Wang, Z. Zhang, Y. Li, Automatic respiratory sound classification via multi-branch temporal convolutional network, in: ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2022, pp. 9102–9106
2022
-
[26]
W. He, Y. Yan, J. Ren, R. Bai, X. Jiang, Multi-view spectrogram transformer for respiratory sound clas- sification, in: ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), IEEE, 2024, pp. 8626–8630
2024
-
[27]
Zhang, Q
Y. Zhang, Q. Huang, W. Sun, F. Chen, D. Lin, F. Chen, Research on lung sound classification model based on dual-channel cnn-lstm algorithm, Biomedi- cal Signal Processing and Control 94 (2024) 106257
2024
-
[28]
W. Song, J. Han, H. Song, Contrastive embeddind learning method for respiratory sound classification, in: ICASSP 2021-2021 IEEE International Confer- ence on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2021, pp. 1275–1279
2021
-
[29]
A. Roy, U. Satija, Asthmascelnet: A lightweight su- pervised contrastive embedding learning framework for asthma classification using lung sounds, entropy 1282 (2023) 100
2023
- [30]
-
[31]
Moummad, N
I. Moummad, N. Farrugia, Pretraining respiratory sound representations using metadata and contrastive learning, in: 2023 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WAS- PAA), IEEE, 2023, pp. 1–5
2023
-
[32]
Kochetov, E
K. Kochetov, E. Putin, M. Balashov, A. Filchenkov, A. Shalyto, Noise masking recurrent neural network for respiratory sound classification, in: International Conference on Artificial Neural Networks, Springer, 2018, pp. 208–217
2018
-
[33]
Z. Wang, Z. Wang, A domain transfer based data augmentation method for automated respiratory clas- sification, in: ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), IEEE, 2022, pp. 9017–9021
2022
-
[34]
Nguyen, F
T. Nguyen, F. Pernkopf, Lung sound classification using co-tuning and stochastic normalization, IEEE Transactions on Biomedical Engineering 69 (9) (2022) 2872–2882
2022
-
[35]
Gairola, F
S. Gairola, F. Tom, N. Kwatra, M. Jain, Respirenet: A deep neural network for accurately detecting ab- normal lung sounds in limited data setting, in: 2021 11 43rd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), IEEE, 2021, pp. 527–530
2021
-
[36]
Kinoshita, T
K. Kinoshita, T. Ochiai, M. Delcroix, T. Nakatani, Improving noise robust automatic speech recognition with single-channel time-domain enhancement net- work, in: ICASSP 2020-2020 IEEE international con- ference on acoustics, speech and signal processing (ICASSP), IEEE, 2020, pp. 7009–7013
2020
-
[37]
Chang, C.-C
J. Chang, C.-C. Huang, Semi-supervised pulmonary auscultation analysis with cross pseudo supervision, in: 2023 IEEE MIT Undergraduate Research Tech- nology Conference (URTC), IEEE, 2023, pp. 1–5
2023
-
[38]
Mukherjee, P
H. Mukherjee, P. Sreerama, A. Dhar, S. M. Obaidul- lah, K.Roy, M.Mahmud, K.Santosh, Automaticlung health screening using respiratory sounds, Journal of Medical Systems 45 (2) (2021) 19
2021
-
[39]
Senthilnathan, P
H. Senthilnathan, P. Deshpande, B. Rai, Breath sounds as a biomarker for screening infectious lung diseases, Engineering Proceedings 2 (1) (2020)
2020
-
[40]
Demir, A
F. Demir, A. Sengur, V. Bajaj, Convolutional neural networks based efficient approach for classification of lung diseases, Health information science and systems 8 (1) (2019) 4
2019
-
[41]
Perna, A
D. Perna, A. Tagarelli, Deep auscultation: Predict- ing respiratory anomalies and diseases via recur- rent neural networks, in: 2019 IEEE 32nd Interna- tional Symposium on Computer-Based Medical Sys- tems (CBMS), IEEE, 2019, pp. 50–55
2019
-
[42]
Jakovljević, T
N. Jakovljević, T. Lončar-Turukalo, Hidden markov model based respiratory sound classification, in: In- ternational Conference on Biomedical and Health In- formatics, Springer, 2017, pp. 39–43
2017
-
[43]
Chamberlain, J
D. Chamberlain, J. Mofor, R. Fletcher, R. Kodgule, Mobile stethoscope and signal processing algorithms for pulmonary screening and diagnostics, in: 2015 IEEE Global Humanitarian Technology Conference (GHTC), IEEE, 2015, pp. 385–392
2015
-
[44]
Salamon, J
J. Salamon, J. P. Bello, Deep convolutional neural networks and data augmentation for environmental sound classification, IEEE Signal processing letters 24 (3) (2017) 279–283
2017
-
[45]
Hongyi, C
Z. Hongyi, C. Moustapha, Y. N. Dauphin, D. Lopez- Paz, mixup: Beyond empirical risk minimization, in: International conference on learning representations, 2018, pp. 1–13
2018
-
[46]
H. Nishizaki, Data augmentation and feature extrac- tion using variational autoencoder for acoustic mod- eling, in: 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Confer- ence (APSIPA ASC), IEEE, 2017, pp. 1222–1227
2017
-
[47]
D. S. Park, W. Chan, Y. Zhang, C.-C. Chiu, B. Zoph, E. D. Cubuk, Q. V. Le, Specaugment: A simple data augmentation method for automatic speech recogni- tion, arXiv preprint arXiv:1904.08779 (2019)
arXiv 1904
-
[48]
K. Koutini, H. Eghbal-Zadeh, G. Widmer, Receptive- field-regularized cnn variants for acoustic scene clas- sification, arXiv preprint arXiv:1909.02859 (2019)
arXiv 1909
-
[49]
B. He, S. Wang, W. Yuan, J. Wang, M. Unoki, Data augmentation for monaural singing voice separation based on variational autoencoder-generative adver- sarial network, in: 2019 IEEE International Confer- ence on Multimedia and Expo (ICME), IEEE, 2019, pp. 1354–1359
2019
-
[50]
Madhu, S
A. Madhu, S. Kumaraswamy, Data augmentation us- ing generative adversarial network for environmental sound classification, in: 2019 27th European signal processing conference (EUSIPCO), IEEE, 2019, pp. 1–5
2019
-
[51]
Nanni, G
L. Nanni, G. Maguolo, M. Paci, Data augmentation approaches for improving animal audio classification, Ecological Informatics 57 (2020) 101084
2020
-
[52]
H. Wang, Y. Zou, W. Wang, Specaugment++: A hidden space data augmentation method for acoustic scene classification, arXiv preprint arXiv:2103.16858 (2021). Appendix A. DetailsofDatasetConstructionPro- cess The following sections detail the systematic construc- tion of our primary Binary Dataset. It should be empha- sized that while the parameters are deri...
arXiv 2021
-
[53]
Implementation of a feed- forward Multilayer Percep- tron (MLP) neural network classifier
Anomaly- based Detec- tion Linear Predictive Cepstral Coefficients (LPCC) ex- tracted from audio signals. Implementation of a feed- forward Multilayer Percep- tron (MLP) neural network classifier. Demonstrates exceptional efficacy with a reported classification accuracy of 99.22% on the target dataset
-
[54]
Deployment of the RespireNet framework (based on ResNet-34), uti- lizing concatenation-based data augmentation and device-specific optimiza- tions
Anomaly- based Detec- tion Mel-spectrograms pro- cessed to clip black (zero- energy) regions for noise reduction. Deployment of the RespireNet framework (based on ResNet-34), uti- lizing concatenation-based data augmentation and device-specific optimiza- tions. Achieved a Sensitivity of 0.54 and Specificity of 0.83 across four distinct classes: Wheeze (W)...
-
[55]
Utilization of classical ma- chinelearningensemblesin- cluding K-Nearest Neigh- bors (KNN), Random For- est, and Logistic Regression specifically for breath cycle detection
Breath Event Detection A combination of Mel- Frequency Cepstral Coeffi- cients (MFCCs) and Power Spectral Density (PSD). Utilization of classical ma- chinelearningensemblesin- cluding K-Nearest Neigh- bors (KNN), Random For- est, and Logistic Regression specifically for breath cycle detection. All proposed models exhib- ited robust performance, maintainin...
-
[56]
Fine-tuningofapre-trained Deep Convolutional Neural Network (CNN) architec- tureadaptedforrespiratory sound analysis
Anomaly- based Detec- tion Time-frequency domain representations generated via Short-Time Fourier Transform (STFT). Fine-tuningofapre-trained Deep Convolutional Neural Network (CNN) architec- tureadaptedforrespiratory sound analysis. The model attained an overall classification accu- racy of 63.09%, highlight- ing the challenges of trans- fer learning in ...
-
[57]
Comparative investigation of Recurrent Neural Net- work (RNN) variants, in- cluding LSTM, GRU, Bi- directional GRU, and Bi- LSTM models
Anomaly- based Detec- tion Standard Mel-Frequency Cepstral Coefficients (MFCCs). Comparative investigation of Recurrent Neural Net- work (RNN) variants, in- cluding LSTM, GRU, Bi- directional GRU, and Bi- LSTM models. The optimal architecture achieved a Sensitivity of 64% and a Specificity of 82%, demonstrating the utility of temporal model- ing
-
[58]
Development of a specific Noise Masking Recurrent Neural Network (NMRNN) designed to mitigate envi- ronmental interference
Noise-Robust Detection Mel-Frequency Cepstral Coefficients (MFCCs) extracted from noisy envi- ronments. Development of a specific Noise Masking Recurrent Neural Network (NMRNN) designed to mitigate envi- ronmental interference. Yielded an end-to-end clas- sification performance with 56% Sensitivity and 73.6% Specificity under noisy con- ditions
-
[59]
A probabilistic model- ing approach combining Hidden Markov Models (HMM) with Gaussian Mixture Models (GMM)
Anomaly- based Detec- tion Mel-Frequency Cepstral Coefficients (MFCCs). A probabilistic model- ing approach combining Hidden Markov Models (HMM) with Gaussian Mixture Models (GMM). Recorded a performance score of 39.56 during the rigorous second evaluation phase of the ICBHI chal- lenge
-
[60]
Application of a Logis- tic Regression classifier en- hanced with L1 Regular- ization for feature selection and sparsity
Multimodal Pathology Diagnosis Integration of abnormal lung sound features with clinical metadata (e.g., breathlessness, peak flow meter readings, family history). Application of a Logis- tic Regression classifier en- hanced with L1 Regular- ization for feature selection and sparsity. Achieved high diagnostic separation with AUC scores of 0.95 (COPD/Asthm...
-
[61]
Environmental Sound Classifi- cation Time Stretching, Pitch Shift- ing, Dynamic Range Compres- sion, Background Noise Addi- tion Log-Mel Spectro- gram The accuracy for the pro- posed CNN (SB-CNN) in- creased from 73% (before aug- mentation) to 79% (after aug- mentation)
-
[62]
Speech Recogni- tion Mixup Augmentation Normalized Spec- trogram The authors compared the classification performance of a VGG-11 model trained with empirical risk minimization and mixup augmentation and observed a lower classification error with mixup augmenta- tion
-
[63]
However, all four classification models suf- fered an increase in the WER after augmentation
Speech Recogni- tion Variational Autoencoder Discrete Fourier Transform The authors proposed four classification models and eval- uated these using Word Er- ror Rate (WER). However, all four classification models suf- fered an increase in the WER after augmentation
-
[64]
Speech Recogni- tion SpecAugment Log-Mel Spectro- gram Listen Attend Spell obtained WER of 2.8 with Augmenta- tion and without presence of Language Model whereas LAS obtained WER of 4.1 without Augmentation
-
[65]
Acoustic Scene Classification Spectrogram Rolling and Mixup Mel Frequency Cepstral Coeffi- cient ResNet mean accuracy im- proved from 80.97% to 82.85% after augmentation
-
[66]
Monaural Singing Voice Separation VAE-GAN Short-Time Fourier Transform Evaluated by SDR/SIR/SAR on DSD; VAE-GAN achieved higher SDR and SAR than RNN baseline
-
[67]
Environmental Sound Classifi- cation WaveGAN Raw Audio Baseline accuracy was 94.84%; with GAN-generated data ac- curacy improved to 97.03%
-
[68]
Animal Audio Classification Signal Speed Scaling, Pitch Shift, Volume In- crease/Decrease, Random Noise Addition, Time Shift Raw Audio VGG19 on CAT dataset im- proved from 83.05% to 85.59% after augmentation
-
[69]
Abnormal Res- piratory Sounds Detection Convolutional VAE Mel Spectrogram Specificity, sensitivity, and F-score increased from 0.286/0.936/0.888 to 0.988/0.988/0.900 after aug- mentation
-
[70]
Acoustic Scene Classification Zero-value Masking, Mini- batch Mixup Masking, Mini- batch Cutting Masking Log-Mel Spectro- gram On DCASE18, accuracy im- proved from 76.2% to 77.0% and 76.9% under different masking strategies. 17
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.