Towards Precise Intent-Aligned VLA Aerial Navigation via Expert-Guided GRPO
Pith reviewed 2026-06-28 14:25 UTC · model grok-4.3
The pith
Expert-guided group relative policy optimization raises VLA aerial navigation success rates to 2.13 times the supervised fine-tuning baseline while lifting intent alignment by 60.9 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
EG-GRPO augments online rollouts with few-shot expert data inside a group-relative policy optimization procedure, and a heterogeneous parallel pipeline enables simultaneous simulation and inference; together these changes raise success rate to 2.13 times the SFT baseline and intent alignment performance by 60.9 percent on tasks specified by complex human instructions.
What carries the argument
EG-GRPO (Expert-Guided Group Relative Policy Optimization), which mixes few-shot expert trajectories into the online rollout buffer to shape relative advantage estimates during policy updates.
If this is right
- Policies achieve 2.13 times higher task success than SFT across tested complex intents.
- Intent alignment metric improves by 60.9 percent relative to the SFT baseline.
- Rollout generation time drops 43.5 percent due to the parallel simulation-inference pipeline.
- The method mitigates data scarcity and inefficient exploration in continuous aerial action spaces.
Where Pith is reading between the lines
- The same expert-augmented GRPO structure could be tested on ground robots or manipulators that also use VLA backbones.
- If expert data quality is the dominant factor, collecting a small but diverse set of demonstrations may be more cost-effective than scaling pure RL compute.
- Real-world deployment would still require explicit handling of sensor noise and wind disturbances not present in the reported simulation results.
Load-bearing premise
The few-shot expert demonstrations are representative of the full range of target human intents and the simulation environment does not create systematic biases or reality gaps that distort the learned policy.
What would settle it
Run the trained policy on a physical UAV with a set of novel intent phrases absent from the expert data and measure whether success rate falls below the reported 2.13 times baseline.
Figures
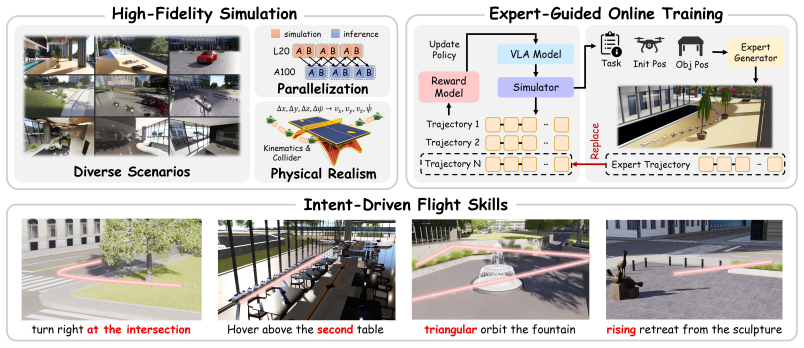
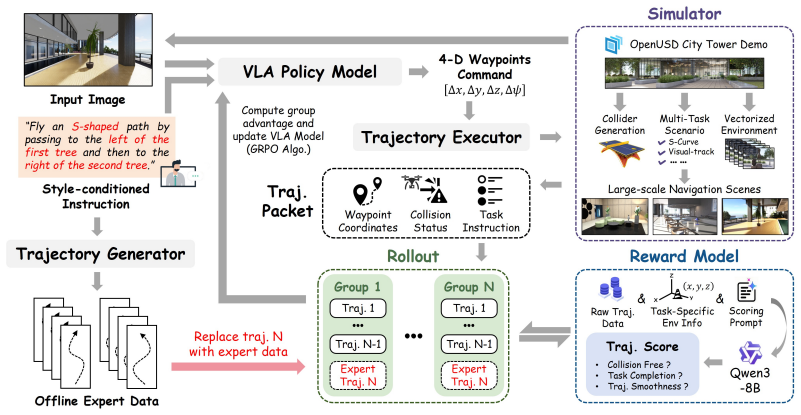
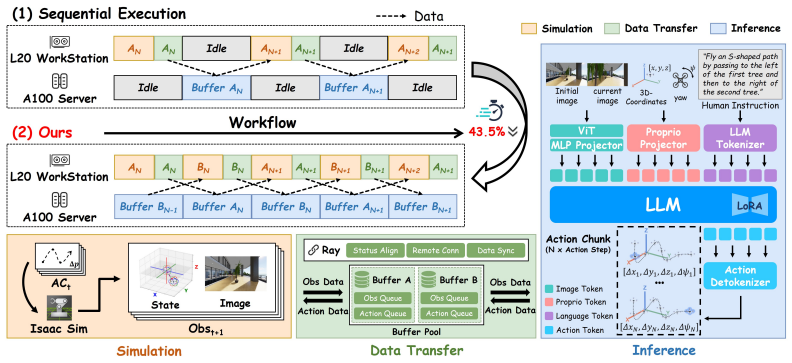

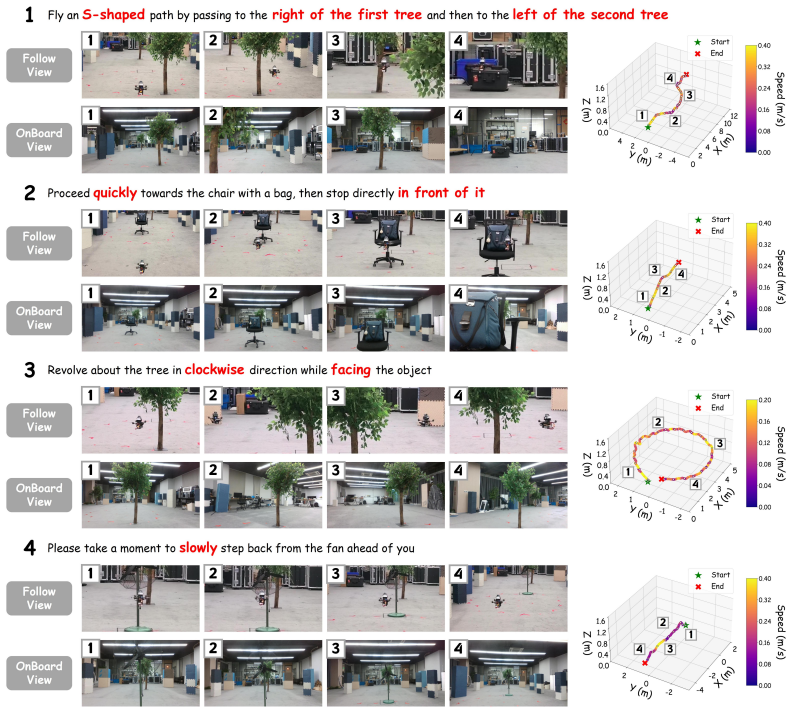
read the original abstract
Vision-Language-Action (VLA) models offer a promising end-to-end paradigm for unmanned aerial vehicles (UAVs) to accomplish complex tasks specified by fine-grained instructions. However, standard supervised fine-tuning (SFT) suffers from data scarcity, limited generalization, and weak supervision for nuanced and complicated human intents. Reinforcement fine-tuning offers a natural way to mitigate these challenges and align policy behaviors with human intents through designable feedback, but applying it to aerial navigation remains challenging due to inefficient exploration in expansive continuous spaces. To address these challenges, we introduce an efficient reinforcement learning (RL) framework for VLA-based aerial navigation. At its core, we propose EG-GRPO (Expert-Guided Group Relative Policy Optimization) to augment online rollouts with few-shot expert data. Additionally, we design a heterogeneous pipeline enabling parallel simulation and inference, which reduces rollout time by 43.5%. Across multiple tasks specified by complex human intents, EG-GRPO improves the success rate to 2.13x that of the SFT baseline, while improving intent alignment performance by 60.9%. These results demonstrate that our framework can move aerial navigation toward precise intent-aligned flight.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce an efficient RL framework called EG-GRPO for VLA-based aerial navigation. It augments online rollouts with few-shot expert data and uses a heterogeneous pipeline for parallel simulation and inference, reducing rollout time by 43.5%. The method is reported to improve success rate to 2.13x of the SFT baseline and intent alignment by 60.9% across multiple tasks with complex human intents.
Significance. If the empirical results are robust, this work would be significant for the field of robotics and RL, as it provides a way to align VLA policies with nuanced human intents in UAV navigation despite data scarcity and exploration challenges. The expert-guided approach and efficiency improvements in the pipeline are notable contributions. The paper demonstrates potential for practical deployment in aerial systems requiring precise intent following.
major comments (2)
- [Results] The headline results of 2.13x success rate and 60.9% intent alignment gain are presented without accompanying details on experimental protocol, dataset sizes, error bars, or ablation studies. This undermines the ability to verify that the improvements are due to EG-GRPO rather than the few-shot data or other factors.
- [Method] The description of the heterogeneous parallel simulation-inference pipeline does not include analysis or metrics to rule out simulation-reality gaps or bias in the state distribution that could affect the group-relative advantage estimates, which is central to the method's validity.
minor comments (2)
- Consider adding a figure illustrating the EG-GRPO framework and the pipeline to improve clarity.
- The abstract mentions 'multiple tasks' but does not specify how many or what they are; this would help contextualize the results.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions to improve clarity and verifiability.
read point-by-point responses
-
Referee: [Results] The headline results of 2.13x success rate and 60.9% intent alignment gain are presented without accompanying details on experimental protocol, dataset sizes, error bars, or ablation studies. This undermines the ability to verify that the improvements are due to EG-GRPO rather than the few-shot data or other factors.
Authors: We agree that the main text would benefit from explicit inclusion of these details to strengthen verifiability. The headline metrics are reported in the abstract and Section 4, but supporting information on protocol, dataset sizes, error bars, and ablations is currently only in the supplementary material. In the revised manuscript we will expand the experimental setup and results sections to summarize the protocol, specify dataset sizes (e.g., expert trajectories per task), report error bars from multiple random seeds, and highlight key ablation results that isolate the contribution of the expert-guided component. revision: yes
-
Referee: [Method] The description of the heterogeneous parallel simulation-inference pipeline does not include analysis or metrics to rule out simulation-reality gaps or bias in the state distribution that could affect the group-relative advantage estimates, which is central to the method's validity.
Authors: We agree that the current method description would be strengthened by explicit analysis of these potential issues. The manuscript focuses on the reported 43.5% rollout time reduction but does not provide dedicated metrics or discussion of simulation-reality gaps or state-distribution bias. We will add a short subsection to the method that includes available validation metrics (e.g., real-world consistency checks) and an examination of advantage estimate distributions to address bias concerns. revision: yes
Circularity Check
No circularity: empirical performance claims rest on measured rollouts, not self-referential derivation
full rationale
The manuscript presents EG-GRPO as an RL method that augments online rollouts with few-shot expert data and uses a heterogeneous simulation-inference pipeline. The headline metrics (2.13x success rate, 60.9% intent-alignment gain) are reported as outcomes of running the trained policy on held-out tasks. No equations, parameter-fitting steps, or uniqueness theorems appear in the supplied text that would reduce a claimed prediction back to the input data or to a self-citation. The method description does not invoke prior author work to justify an ansatz or to forbid alternatives; the results are framed as experimental measurements against an SFT baseline. Because the central claims are externally falsifiable via simulation benchmarks and do not contain a closed derivation loop, the paper is self-contained against external evaluation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
R. Sapkota, Y . Cao, K. I. Roumeliotis, and M. Karkee. Vision-language-action models: Con- cepts, progress, applications and challenges.arXiv preprint arXiv:2505.04769, 2025
arXiv 2025
-
[2]
G. Tie, Z. Zhao, D. Song, F. Wei, R. Zhou, Y . Dai, W. Yin, Z. Yang, J. Yan, Y . Su, et al. A survey on post-training of large language models.arXiv preprint arXiv:2503.06072, 2025
arXiv 2025
-
[3]
J. Gao, A. Xie, T. Xiao, C. Finn, and D. Sadigh. Efficient data collection for robotic manipu- lation via compositional generalization.arXiv preprint arXiv:2403.05110, 2024
arXiv 2024
-
[4]
J. Liu, F. Gao, B. Wei, X. Chen, Q. Liao, Y . Wu, C. Yu, and Y . Wang. What can rl bring to vla generalization? an empirical study.arXiv preprint arXiv:2505.19789, 2025
arXiv 2025
-
[5]
D. Kim, S. Park, H. Jang, J. Shin, J. Kim, and Y . Seo. Robot-r1: Reinforcement learning for enhanced embodied reasoning in robotics.arXiv preprint arXiv:2506.00070, 2025
arXiv 2025
-
[6]
Z. Chen, R. Niu, H. Kong, Q. Wang, Q. Xing, and Z. Fan. Tgrpo: Fine-tuning vision- language-action model via trajectory-wise group relative policy optimization.arXiv preprint arXiv:2506.08440, 2025
arXiv 2025
-
[7]
A. Ye, Z. Zhang, B. Wang, X. Wang, D. Zhang, and Z. Zhu. Vla-r1: Enhancing reasoning in vision-language-action models.arXiv preprint arXiv:2510.01623, 2025
arXiv 2025
-
[8]
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[9]
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y . Li, Y . Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[10]
L. H. K. Wong, X. Kang, K. Bai, and J. Zhang. A survey of robotic navigation and manipulation with physics simulators in the era of embodied ai.arXiv preprint arXiv:2505.01458, 2025
Pith/arXiv arXiv 2025
-
[11]
J. Luo, C. Xu, J. Wu, and S. Levine. Precise and dexterous robotic manipulation via human- in-the-loop reinforcement learning.Science Robotics, 10(105):eads5033, 2025
2025
-
[12]
Y . Chen, S. Tian, S. Liu, Y . Zhou, H. Li, and D. Zhao. Conrft: A reinforced fine-tuning method for vla models via consistency policy.arXiv preprint arXiv:2502.05450, 2025
arXiv 2025
-
[13]
Kilinc and G
O. Kilinc and G. Montana. Reinforcement learning for robotic manipulation using simulated locomotion demonstrations.Machine Learning, 111(2):465–486, 2022
2022
-
[14]
Nahavandi, R
S. Nahavandi, R. Alizadehsani, D. Nahavandi, S. Mohamed, N. Mohajer, M. Rokonuzzaman, and I. Hossain. A comprehensive review on autonomous navigation.ACM Computing Surveys, 57(9):1–67, 2025
2025
-
[15]
S. Liu, H. Zhang, Y . Qi, P. Wang, Y . Zhang, and Q. Wu. Aerialvln: Vision-and-language navigation for uavs. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15384–15394, 2023
2023
-
[16]
Ladosz, L
P. Ladosz, L. Weng, M. Kim, and H. Oh. Exploration in deep reinforcement learning: A survey. Information Fusion, 85:1–22, 2022
2022
-
[17]
T. Wu, G. Xu, Z. Wang, J. Lin, T. Chen, Y . Wu, Z. Han, Z. Liu, and F. Gao. Precise aggressive aerial maneuvers with sensorimotor policies.arXiv preprint arXiv:2604.05828, 2026
Pith/arXiv arXiv 2026
-
[18]
P. Lin, G. Sun, C. Liu, F. Li, W. Ren, and Y . Cong. Openvln: Open-world aerial vision-language navigation.arXiv preprint arXiv:2511.06182, 2025. 11
arXiv 2025
-
[19]
J. Lee, T. Miyanishi, S. Kurita, K. Sakamoto, D. Azuma, Y . Matsuo, and N. Inoue. City- nav: A large-scale dataset for real-world aerial navigation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5912–5922, 2025
2025
- [20]
-
[21]
H. Zang, M. Wei, S. Xu, Y . Wu, Z. Guo, Y . Wang, H. Lin, L. Shi, Y . Xie, Z. Xu, et al. Rlinf-vla: A unified and efficient framework for vla+ rl training.arXiv preprint arXiv:2510.06710, 2025
arXiv 2025
- [22]
-
[23]
V . Blukis, N. Brukhim, A. Bennett, R. A. Knepper, and Y . Artzi. Following high-level navigation instructions on a simulated quadcopter with imitation learning.arXiv preprint arXiv:1806.00047, 2018
Pith/arXiv arXiv 2018
-
[24]
Blukis, D
V . Blukis, D. Misra, R. A. Knepper, and Y . Artzi. Mapping navigation instructions to con- tinuous control actions with position-visitation prediction. InConference on Robot Learning, pages 505–518. PMLR, 2018
2018
-
[25]
X. Wang, D. Yang, Z. Wang, H. Kwan, J. Chen, W. Wu, H. Li, Y . Liao, and S. Liu. Towards re- alistic uav vision-language navigation: Platform, benchmark, and methodology.arXiv preprint arXiv:2410.07087, 2024
arXiv 2024
-
[26]
Y . Gao, C. Li, Z. You, J. Liu, Z. Li, P. Chen, Q. Chen, Z. Tang, L. Wang, P. Yang, et al. Openfly: A comprehensive platform for aerial vision-language navigation.arXiv preprint arXiv:2502.18041, 2025
arXiv 2025
-
[27]
Y . Wu, M. Zhu, X. Li, Y . Du, Y . Fan, W. Li, Z. Han, X. Zhou, and F. Gao. Vla-an: An efficient and onboard vision-language-action framework for aerial navigation in complex environments. arXiv preprint arXiv:2512.15258, 2025
arXiv 2025
-
[28]
Zhang, Y
X. Zhang, Y . Tian, F. Lin, Y . Liu, J. Ma, X. Wang, K. S. Szatm ´ary, and F.-Y . Wang. Logis- ticsvln: Vision-language navigation for low-altitude terminal delivery based on agentic uavs. In2025 IEEE 28th International Conference on Intelligent Transportation Systems (ITSC), pages 4437–4442. IEEE, 2025
2025
-
[29]
Saxena, N
P. Saxena, N. Raghuvanshi, and N. Goveas. Uav-vln: End-to-end vision language guided navigation for uavs. In2025 European Conference on Mobile Robots (ECMR), pages 1–6. IEEE, 2025
2025
-
[30]
H. Cai, J. Dong, J. Tan, J. Deng, S. Li, Z. Gao, H. Wang, Z. Su, A. Sumalee, and R. Zhong. Flightgpt: Towards generalizable and interpretable uav vision-and-language navigation with vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 6670–6687, 2025
2025
-
[31]
Sautenkov, Y
O. Sautenkov, Y . Yaqoot, A. Lykov, M. A. Mustafa, G. Tadevosyan, A. Akhmetkazy, M. A. Cabrera, M. Martynov, S. Karaf, and D. Tsetserukou. Uav-vla: Vision-language-action system for large scale aerial mission generation. In2025 20th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 1588–1592. IEEE, 2025
2025
- [32]
-
[33]
Y . Guo, J. Zhang, X. Chen, X. Ji, Y .-J. Wang, Y . Hu, and J. Chen. Improving vision-language- action model with online reinforcement learning. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 15665–15672. IEEE, 2025
2025
-
[34]
G. Lu, W. Guo, C. Zhang, Y . Zhou, H. Jiang, Z. Gao, Y . Tang, and Z. Wang. Vla-rl: To- wards masterful and general robotic manipulation with scalable reinforcement learning.arXiv preprint arXiv:2505.18719, 2025
Pith/arXiv arXiv 2025
-
[35]
H. Li, Y . Zuo, J. Yu, Y . Zhang, Z. Yang, K. Zhang, X. Zhu, Y . Zhang, T. Chen, G. Cui, et al. Simplevla-rl: Scaling vla training via reinforcement learning.arXiv preprint arXiv:2509.09674, 2025
Pith/arXiv arXiv 2025
-
[36]
H. Zhao, W. Song, D. Wang, X. Tong, P. Ding, X. Cheng, and Z. Ge. More: Unlocking scal- ability in reinforcement learning for quadruped vision-language-action models. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 11212–11218. IEEE, 2025
2025
-
[37]
J. Li, C. Wan, S. Dong, C. Ding, Q. Wang, Z. Ma, and Y . Gong. Trajectory-diversity-driven robust vision-and-language navigation.arXiv preprint arXiv:2603.15370, 2026
arXiv 2026
-
[38]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[39]
X. Wang, D. Yang, Y . Liao, W. Zheng, B. Dai, H. Li, S. Liu, et al. Uav-flow colosseo: A real- world benchmark for flying-on-a-word uav imitation learning.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[40]
P. J. Ball, L. Smith, I. Kostrikov, and S. Levine. Efficient online reinforcement learning with offline data. InInternational Conference on Machine Learning, pages 1577–1594. PMLR, 2023
2023
-
[41]
M. Mittal, P. Roth, J. Tigue, A. Richard, O. Zhang, P. Du, A. Serrano-Munoz, X. Yao, R. Zurbr ¨ugg, N. Rudin, et al. Isaac lab: A gpu-accelerated simulation framework for multi- modal robot learning.arXiv preprint arXiv:2511.04831, 2025
Pith/arXiv arXiv 2025
-
[42]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.pi 0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024. 13
Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.