O-POPE: High-Frequency Pipelined Outer Product based GEMM acceleration with minimal buffering overhead
Pith reviewed 2026-06-28 12:09 UTC · model grok-4.3
The pith
O-POPE enables 1 GHz floating-point GEMM by repurposing FPU pipeline registers as buffers in an outer-product design.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
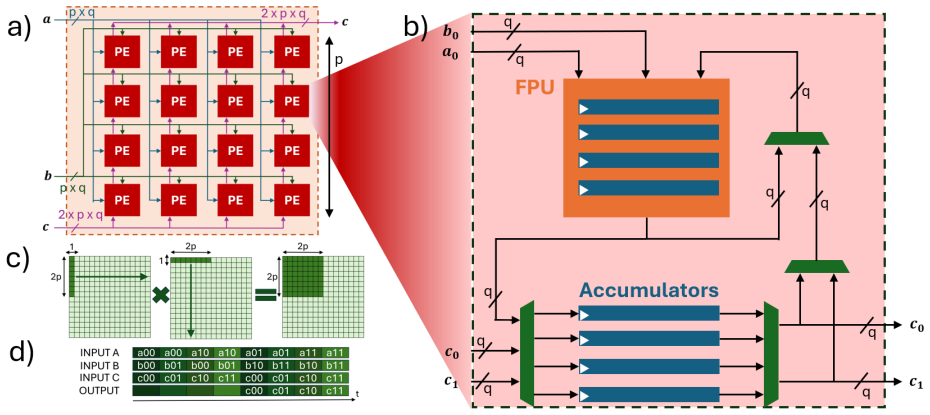
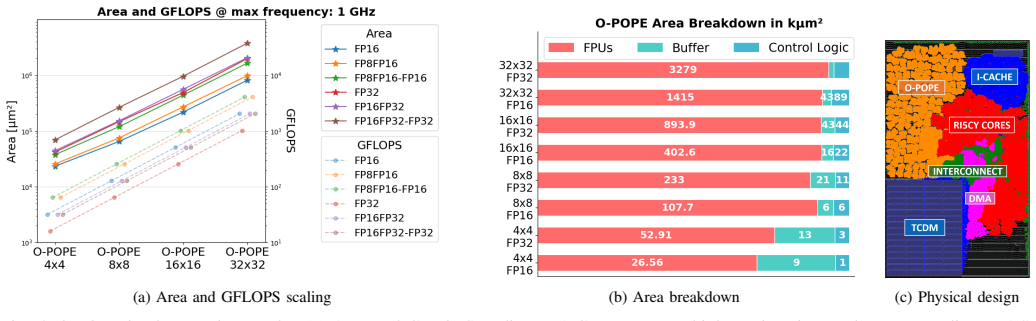
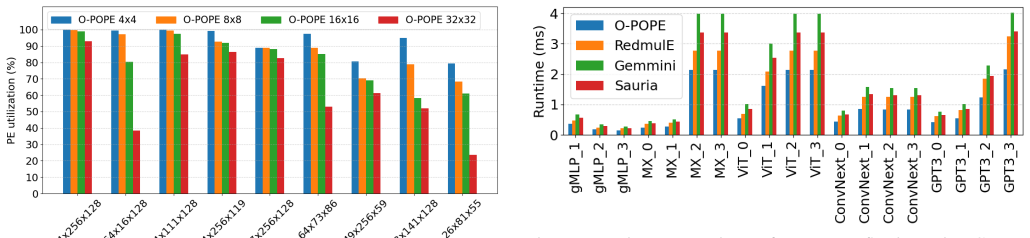
O-POPE is a scalable outer-product engine that achieves concurrently high utilization, low overhead, and a fast operating frequency by repurposing floating-point unit pipeline registers as buffers. This solution leverages the data-reuse advantages of output-stationary outer-product execution and enables 1 GHz operation in 12 nm FINFET technology with less than 2 percent buffer area for a 2048-MACs configuration, reaching up to 99.97 percent FPU utilization along with 1.33 times performance, 9 percent performance density, and 8 percent energy efficiency gains over state-of-the-art floating-point GEMM accelerators.
What carries the argument
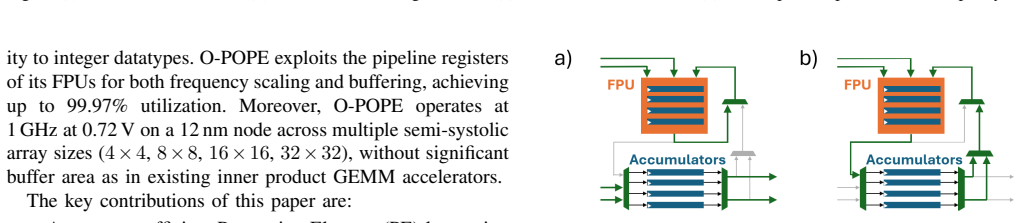
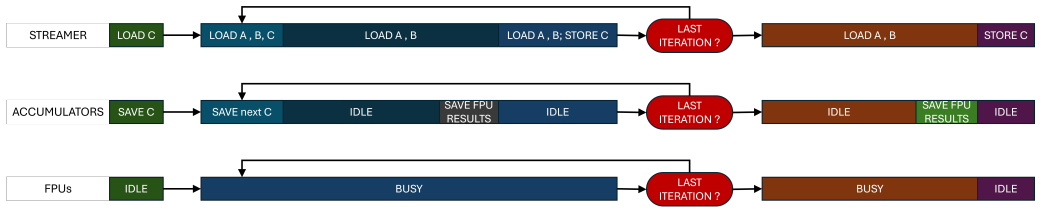
Pipelined outer-product execution that repurposes FPU pipeline registers to hold intermediate results and thereby eliminates most dedicated buffering.
If this is right
- FPU utilization reaches 99.97 percent under the claimed execution flow.
- Performance improves by a factor of 1.33 relative to prior floating-point GEMM accelerators.
- Performance density increases by 9 percent.
- Energy efficiency improves by 8 percent.
Where Pith is reading between the lines
- The same register-repurposing idea could be tested on systolic or other dataflow patterns for matrix operations.
- Buffer-area savings may allow larger MAC arrays to fit within a fixed die area while preserving frequency.
- Designs for training accelerators that must retain high-precision arithmetic could adopt the approach to reduce overall memory hierarchy pressure.
Load-bearing premise
FPU pipeline registers can be repurposed as buffers without compromising arithmetic correctness, timing closure at 1 GHz, or pipeline behavior in the target 12 nm FINFET process.
What would settle it
A post-layout timing report or silicon measurement showing that the design cannot sustain 1 GHz at 0.72 V while keeping buffer area under 2 percent and preserving floating-point accuracy.
Figures

read the original abstract
General matrix multiply (GEMM) dominates both execution time and energy consumption of modern machine learning (ML) workloads, placing increasing pressure on hardware efficiency. While quantization mitigates computational and data movement costs, accuracy-sensitive tasks such as training still require higher-precision floating-point formats. Existing floating-point GEMM accelerators face trade-offs between operating frequency, arithmetic utilization, and buffering overhead. This work presents O-POPE, a scalable outer-product engine that achieves concurrently high utilization, low overhead, and a fast operating frequency by repurposing floating-point unit (FPU) pipeline registers as buffers. This solution leverages the data-reuse advantages of output-stationary outer-product execution and enables 1 GHz (0.72 V) operation in 12 nm FINFET technology with less than 2% buffer area for a 2048-MACs configuration. Our evaluation shows that O-POPE achieves up to 99.97% FPU utilization and improves performance (1.33x), performance density by 9%, and energy efficiency by 8%, compared to state-of-the-art floating-point GEMM accelerators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces O-POPE, a scalable outer-product GEMM accelerator for floating-point operations that repurposes FPU pipeline registers as buffers to enable output-stationary execution. It claims 1 GHz operation at 0.72 V in 12 nm FINFET with <2% buffer area overhead for a 2048-MAC configuration, up to 99.97% FPU utilization, and improvements of 1.33x performance, 9% performance density, and 8% energy efficiency over prior floating-point GEMM accelerators.
Significance. If the register-repurposing mechanism is shown to preserve timing and arithmetic correctness, the design would address a key trade-off in high-precision GEMM accelerators by achieving high utilization and frequency with negligible buffering overhead, which is relevant for accuracy-sensitive ML workloads.
major comments (2)
- [Abstract / Solution description] Abstract / Solution description: The claim that FPU pipeline registers can be repurposed as buffers to support output-stationary outer-product execution without lengthening the critical path, altering rounding behavior, or requiring extra staging at 1 GHz in 12 nm FINFET is load-bearing for the reported <2% buffer area, 99.97% utilization, and all quantitative gains, yet no modified pipeline diagram, critical-path analysis, or post-synthesis timing report is provided to substantiate it.
- [Evaluation] Evaluation: The stated improvements (1.33x performance, 9% density, 8% efficiency) and 99.97% utilization lack accompanying workload characteristics, baseline accelerator configurations, area/power breakdowns, or verification methodology, preventing assessment of whether the gains are attributable to the proposed buffering technique.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify areas where additional documentation would strengthen the manuscript. We address each point below and will incorporate revisions to provide the requested substantiation and details.
read point-by-point responses
-
Referee: [Abstract / Solution description] The claim that FPU pipeline registers can be repurposed as buffers to support output-stationary outer-product execution without lengthening the critical path, altering rounding behavior, or requiring extra staging at 1 GHz in 12 nm FINFET is load-bearing for the reported <2% buffer area, 99.97% utilization, and all quantitative gains, yet no modified pipeline diagram, critical-path analysis, or post-synthesis timing report is provided to substantiate it.
Authors: We agree that explicit evidence for the pipeline modifications is essential to support the core claims. The design section describes how the existing FPU pipeline registers are reused for output-stationary buffering without extending the critical path or changing rounding semantics, as the reuse occurs within the existing pipeline stages. To address the concern, we will add a modified pipeline diagram, a critical-path timing analysis, and relevant excerpts from post-synthesis reports confirming 1 GHz operation at 0.72 V in 12 nm FINFET. These additions will directly substantiate the area, utilization, and performance claims. revision: yes
-
Referee: [Evaluation] The stated improvements (1.33x performance, 9% density, 8% efficiency) and 99.97% utilization lack accompanying workload characteristics, baseline accelerator configurations, area/power breakdowns, or verification methodology, preventing assessment of whether the gains are attributable to the proposed buffering technique.
Authors: The evaluation section reports the quantitative gains from comparisons against prior floating-point GEMM accelerators using standard matrix-multiplication workloads. To improve clarity and allow readers to attribute gains specifically to the buffering approach, we will expand the section with explicit workload characteristics (matrix sizes and precisions), baseline accelerator configurations, detailed area and power breakdowns, and the verification methodology (including how utilization was measured via cycle-accurate simulation and post-synthesis power analysis). revision: yes
Circularity Check
No circularity: design claims rest on synthesis/evaluation, not self-referential definitions or fitted predictions
full rationale
The paper is a hardware architecture description for an outer-product GEMM accelerator. Its central claims (1 GHz operation, <2% buffer area via FPU register repurposing, 99.97% utilization, and reported speedups) are presented as outcomes of the proposed microarchitecture and post-synthesis evaluation in 12 nm FINFET. No equations, parameter fits, or predictions appear in the abstract or described text. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify the core mechanism. The register-repurposing step is a design choice whose timing and correctness impact is asserted via implementation results rather than derived from prior results by the same authors. This matches the default case of a self-contained engineering paper whose derivation chain does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard performance and area models for 12 nm FINFET technology at 0.72 V
Reference graph
Works this paper leans on
-
[1]
Recent advances in artificial intelligence and machine learning: Trends, challenges, and future directions,
N. Soni and N. Nigam, “Recent advances in artificial intelligence and machine learning: Trends, challenges, and future directions,”Interna- tional Journal of Engineering Trends and Applications (IJETA), vol. 12, no. 1, pp. 9–12, 2025
2025
-
[2]
Understanding the performance horizon of the latest ml workloads with nongemm workloads,
R. Karami, S.-C. Kao, and H. Kwon, “Understanding the performance horizon of the latest ml workloads with nongemm workloads,” in2025 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), 2025, pp. 1–14
2025
-
[3]
Scaling Laws for Neural Language Models
J. Kaplanet al., “Scaling laws for neural language models,”arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[4]
Contemporary advances in neural network quantization: A survey,
M. Liet al., “Contemporary advances in neural network quantization: A survey,” in2024 International Joint Conference on Neural Networks (IJCNN), 2024, pp. 1–10
2024
-
[5]
Accelerating deep learning workloads with advanced matrix extensions,
W. Huanget al., “Accelerating deep learning workloads with advanced matrix extensions,” in2023 5th International Conference on Machine Learning, Big Data and Business Intelligence (MLBDBI), 2023, pp. 70– 73
2023
-
[6]
Efficient acceleration of deep learning inference on resource-constrained edge devices: A review,
M. M. H. Shuvoet al., “Efficient acceleration of deep learning inference on resource-constrained edge devices: A review,”Proceedings of the IEEE, vol. 111, no. 1, pp. 42–91, 2023
2023
-
[7]
Llm-fp4: 4-bit floating-point quantized transformers,
S. Liuet al., “Llm-fp4: 4-bit floating-point quantized transformers,” in Proceedings of the 2023 conference on empirical methods in natural language processing, 2023, pp. 592–605
2023
-
[8]
Microscaling data formats for deep learning, 2023
B. D. Rouhaniet al., “Microscaling data formats for deep learning,” arXiv preprint arXiv:2310.10537, 2023
-
[9]
Pretraining large language models with nvfp4,
F. Abecassiset al., “Pretraining large language models with nvfp4,” arXiv preprint arXiv:2509.25149, 2025
-
[10]
Exploring the trade-offs: quantization methods, task difficulty, and model size in large language models from edge to giant,
J. Leeet al., “Exploring the trade-offs: quantization methods, task difficulty, and model size in large language models from edge to giant,” inProceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, 2025, pp. 8113–8121
2025
-
[11]
Fp64 is all you need: Rethinking failure modes in physics- informed neural networks,
C. Xuet al., “Fp64 is all you need: Rethinking failure modes in physics- informed neural networks,”Advances in Neural Information Processing Systems, vol. 38, pp. 142 949–142 970, 2026
2026
-
[12]
Quadrilatero: A risc-v programmable matrix co- processor for low-power edge applications,
D. Cammarataet al., “Quadrilatero: A risc-v programmable matrix co- processor for low-power edge applications,” inProceedings of the 22nd ACM International Conference on Computing Frontiers: Workshops and Special Sessions, 2025, pp. 66–69
2025
-
[13]
Arm Architecture Reference Manual for A- profile architecture,
Arm developer, “Arm Architecture Reference Manual for A- profile architecture,” accessed May 11, 2026. [Online]. Available: https://developer.arm.com/documentation/ddi0487/latest/
2026
-
[14]
Intel Architecture Instruction Set Extensions and Future Features,
Intel, “Intel Architecture Instruction Set Extensions and Future Features,” accessed May 11, 2026. [Online]. Avail- able: https://cdrdv2-public.intel.com/671368/architecture-instruction- set-extensions-programming-reference.pdf
2026
-
[15]
A matrix math facility for power isa (tm) processors,
J. E. Moreiraet al., “A matrix math facility for power isa (tm) processors,”arXiv preprint arXiv:2104.03142, 2021
-
[16]
Integrated Matrix Extension,
RISC-V, “Integrated Matrix Extension,” accessed May 11, 2026. [On- line]. Available: https://riscv.atlassian.net/wiki/spaces/IMEX/overview
2026
-
[17]
Attached Matrix Extension,
RISC-V , “Attached Matrix Extension,” accessed May 11, 2026. [Online]. Available: https://riscv.atlassian.net/wiki/spaces/AMEX/overview
2026
-
[18]
A multi-mode 8k-mac hw-utilization-aware neural processing unit with a unified multi-precision datapath in 4nm flagship mobile soc,
J.-S. Parket al., “A multi-mode 8k-mac hw-utilization-aware neural processing unit with a unified multi-precision datapath in 4nm flagship mobile soc,” in2022 IEEE International Solid-State Circuits Conference (ISSCC), vol. 65, 2022, pp. 246–248
2022
-
[19]
Redmule: A mixed-precision matrix–matrix opera- tion engine for flexible and energy-efficient on-chip linear algebra and tinyml training acceleration,
Y . Tortorellaet al., “Redmule: A mixed-precision matrix–matrix opera- tion engine for flexible and energy-efficient on-chip linear algebra and tinyml training acceleration,”Future Generation Computer Systems, vol. 149, pp. 122–135, 2023
2023
-
[20]
Fpnew: An open-source multiformat floating-point unit architecture for energy-proportional transprecision computing,
S. Machet al., “Fpnew: An open-source multiformat floating-point unit architecture for energy-proportional transprecision computing,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 29, no. 4, pp. 774–787, 2020
2020
-
[21]
An energy-efficient gemm-based convolution acceler- ator with on-the-fly im2col,
J. Forntet al., “An energy-efficient gemm-based convolution acceler- ator with on-the-fly im2col,”IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 31, no. 11, pp. 1874–1878, 2023
2023
-
[22]
Gemmini: Enabling systematic deep-learning archi- tecture evaluation via full-stack integration,
H. Gencet al., “Gemmini: Enabling systematic deep-learning archi- tecture evaluation via full-stack integration,” in2021 58th ACM/IEEE Design Automation Conference (DAC), 2021, pp. 769–774
2021
-
[23]
Axon: A novel systolic array architecture for improved run time and energy efficient gemm and conv operation with on-chip im2col,
M. M. Rahaman Nayanet al., “Axon: A novel systolic array architecture for improved run time and energy efficient gemm and conv operation with on-chip im2col,” in2025 Design, Automation & Test in Europe Conference (DATE), 2025, pp. 1–7
2025
-
[24]
Why systolic architectures?
Kung, “Why systolic architectures?”Computer, vol. 15, no. 1, pp. 37– 46, 1982
1982
-
[25]
Pulp: A parallel ultra low power platform for next generation iot applications,
D. Rossiet al., “Pulp: A parallel ultra low power platform for next generation iot applications,” in2015 IEEE Hot Chips 27 Symposium (HCS), 2015, pp. 1–39
2015
-
[26]
Deepscaletool: A tool for the accurate estimation of technology scaling in the deep-submicron era,
S. Sarangi and B. Baas, “Deepscaletool: A tool for the accurate estimation of technology scaling in the deep-submicron era,” in2021 IEEE International Symposium on Circuits and Systems (ISCAS), 2021, pp. 1–5
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.