Less Is More? When Dataset Context Hurts LLM-Generated Dataset Descriptions
Pith reviewed 2026-06-28 12:00 UTC · model grok-4.3
The pith
Table schemas degrade narrative quality in LLM-generated dataset descriptions while representative data offers only partial grounding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
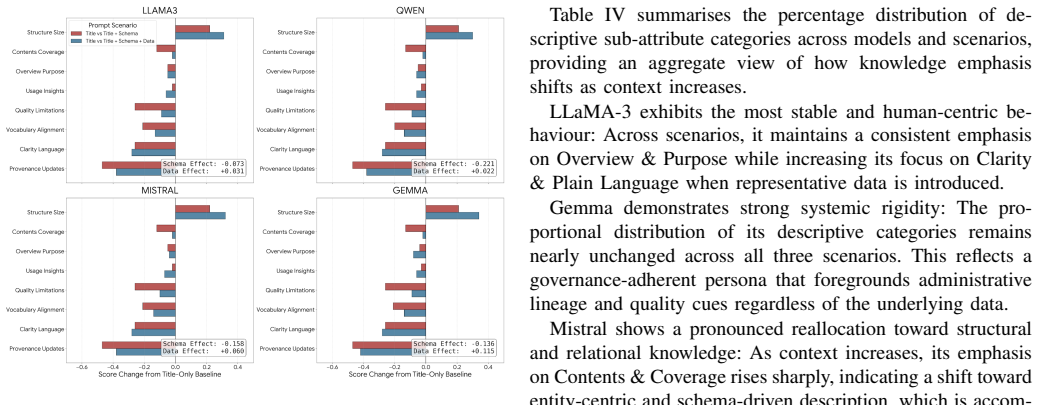
The authors establish that LLMs exhibit a consistent schema penalty in dataset description generation: providing table schemas alone often degrades narrative quality compared with title-only inputs, while adding representative data partially restores grounding and factual accuracy without improving overall human-facing quality metrics.
What carries the argument
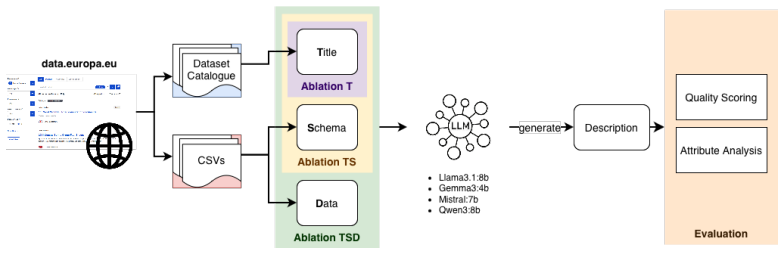
The three-way ablation of input context (titles; titles plus schema; titles plus schema plus representative data) evaluated by an LLM-as-a-judge framework and semantic descriptive attribute analysis.
If this is right
- Title-only prompts can produce higher narrative quality than prompts that also include table schemas.
- Representative data samples improve grounding and factual correctness but leave overall description quality unchanged.
- Different LLMs maintain stable descriptive personas when generating dataset metadata.
- Data publishing pipelines can reduce context to titles when narrative flow matters more than precise column details.
Where Pith is reading between the lines
- Workflows that generate descriptions at scale may achieve better results by defaulting to minimal context rather than maximal context.
- The observed schema penalty raises the question of whether schema information should be filtered or summarized before being passed to the model.
- Stable LLM personas suggest that model choice can be treated as a fixed variable when tuning description generation pipelines.
Load-bearing premise
The LLM-as-a-judge framework together with the semantic attribute analysis correctly measures human-facing description quality.
What would settle it
A controlled human rating study on the same set of generated descriptions that finds no schema penalty or finds that schemas improve quality.
Figures



read the original abstract
Dataset search and reuse are strongly constrained by the quality of metadata such as natural language descriptions, which are often sparse or inconsistent. Although large language models (LLMs) can generate such descriptions automatically, little empirical guidance exists on what makes a good dataset description and what dataset context LLMs actually need. We study these questions through a literature-grounded framework of dataset description quality and a large-scale ablation study using 252 datasets (1,336 CSV files) from the European data portal data.europa.eu. We generate descriptions with LLMs in a baseline scenario and two ablation scenarios: (1) using only dataset titles, (2) titles and schema, and (3) titles, schema and representative data, and evaluate them with an LLM-as-a- judge framework and a semantic descriptive attribute analysis grounded in our quality dimensions. Our results reveal a consis- tent schema penalty: table-schemas alone often degrade narrative quality, while representative data partially restores grounding without improving overall human-facing quality. We further show that different LLMs exhibit stable descriptive personas. These findings provide practical guidance for LLM-supported data publishing workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a large-scale ablation study on 252 datasets (1,336 CSV files) from data.europa.eu to examine how different input contexts (titles alone, titles+schema, titles+schema+representative data) affect LLM-generated dataset descriptions. It defines a literature-grounded quality framework, evaluates outputs via an LLM-as-a-judge framework and semantic descriptive attribute analysis, and reports a consistent 'schema penalty' that degrades narrative quality, with representative data partially restoring grounding but not overall human-facing quality; it also notes stable descriptive personas across LLMs.
Significance. The scale of the ablation (252 datasets) and the identification of stable LLM personas across models are clear strengths that could support reproducible follow-up work if the evaluation pipeline is made fully transparent. If the LLM-as-a-judge and semantic-attribute proxies are shown to track human judgments, the schema-penalty finding would supply actionable guidance for data-publishing workflows. At present the significance is constrained by the absence of any reported validation of those proxies against human raters on the same quality dimensions.
major comments (2)
- [Abstract and evaluation paragraph] Abstract and evaluation paragraph: the central claim is framed in terms of 'human-facing quality' and 'practical guidance for LLM-supported data publishing workflows,' yet the LLM-as-a-judge framework and semantic descriptive attribute analysis are presented without any correlation, inter-rater agreement, or other validation against human judgments on the same dimensions. Because the schema penalty and data-restoration effects are measured exclusively through these unvalidated proxies, the practical claim rests on an untested assumption.
- [Abstract] Abstract: no quantitative results, error bars, sample sizes per condition, or details on post-hoc exclusions and judge-prompt construction are supplied, so the robustness of the reported 'consistent schema penalty' cannot be assessed from the provided information.
minor comments (1)
- [Abstract] The hyphenated line-break 'consis- tent' in the abstract should be corrected to 'consistent'.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract and evaluation paragraph] Abstract and evaluation paragraph: the central claim is framed in terms of 'human-facing quality' and 'practical guidance for LLM-supported data publishing workflows,' yet the LLM-as-a-judge framework and semantic descriptive attribute analysis are presented without any correlation, inter-rater agreement, or other validation against human judgments on the same dimensions. Because the schema penalty and data-restoration effects are measured exclusively through these unvalidated proxies, the practical claim rests on an untested assumption.
Authors: We appreciate the referee highlighting the reliance on unvalidated proxies. Our quality framework draws directly from prior literature on dataset metadata, and the LLM-as-a-judge approach enables evaluation at the scale of 252 datasets. We acknowledge that explicit correlation with human ratings on these dimensions would strengthen the practical claims. In revision we will add a limitations subsection that discusses the grounding and assumptions of the proxies, cites supporting prior work on automated evaluation, and notes the absence of direct human validation in the current study. revision: partial
-
Referee: [Abstract] Abstract: no quantitative results, error bars, sample sizes per condition, or details on post-hoc exclusions and judge-prompt construction are supplied, so the robustness of the reported 'consistent schema penalty' cannot be assessed from the provided information.
Authors: We agree the abstract would be more informative with key quantitative details. The manuscript evaluates 252 datasets (1,336 files) across three conditions with multiple LLMs. We will revise the abstract to state the sample size, note the consistency of the schema penalty, and briefly reference the evaluation pipeline. Full details on judge prompts, any exclusions, and statistical reporting appear in the methods section; we will ensure the abstract points readers there without exceeding length limits. revision: yes
Circularity Check
No circularity: purely empirical ablation with external benchmarks
full rationale
The paper performs a large-scale empirical ablation on 252 datasets, generating LLM descriptions under three context conditions and scoring them via LLM-as-a-judge plus a semantic attribute analysis. No equations, fitted parameters, predictions derived from the study's own quantities, or self-citation chains appear; the quality framework is literature-grounded and the results are measured against external data and automated proxies rather than defined in terms of the paper's inputs. This is the normal case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Open data and high-value datasets: step-by-step access guide,
European Commission, “Open data and high-value datasets: step-by-step access guide,” https://digital-strategy.ec.europa.eu/en/factpages/open- data-and-high-value-datasets-step-step-access-guide, 2024, last updated 14 Nov 2024; accessed 2026-01-14
2024
-
[2]
Dataset search: a survey,
A. Chapman, E. Simperl, L. Koesten, G. Konstantinidis, L.-D. Ib ´a˜nez, E. Kacprzak, and P. Groth, “Dataset search: a survey,”The VLDB Journal, vol. 29, no. 1, pp. 251–272, Jan. 2020
2020
-
[3]
A dataset describing data discovery and reuse practices in research,
K. Gregory, “A dataset describing data discovery and reuse practices in research,”Scientific Data, vol. 7, no. 1, p. 232, Jul. 2020
2020
-
[4]
It took longer than i was expecting: Why is dataset search still so hard?
M. Hulsebos, W. Lin, S. Shankar, and A. Parameswaran, “It took longer than i was expecting: Why is dataset search still so hard?” inProceedings of the 2024 Workshop on Human-In-the-Loop Data Analytics, ser. HILDA 24. New York, NY , USA: Association for Computing Machinery, 2024, p. 1–4. [Online]. Available: https://doi.org/10.1145/3665939.3665959
-
[5]
What are researchers’ needs in data discovery? analysis and ranking of a large- scale collection of crowdsourced use cases,
B. Mathiak, N. Juty, A. Bardi, J. Colomb, and P. Kraker, “What are researchers’ needs in data discovery? analysis and ranking of a large- scale collection of crowdsourced use cases,”Data Science Journal, Feb 2023
2023
-
[6]
Talking datasets – understanding data sensemaking be- haviours,
L. Koesten, K. Gregory, P. Groth, and E. Simperl, “Talking datasets – understanding data sensemaking be- haviours,”International Journal of Human-Computer Stud- ies, vol. 146, p. 102562, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1071581920301646
2021
-
[7]
F. L ¨offler, V . Wesp, B. K ¨onig-Ries, and F. Klan, “Dataset search in biodiversity research: Do metadata in data repositories reflect scholarly information needs?”PLOS ONE, vol. 16, no. 3, pp. 1–36, 03 2021. [Online]. Available: https://doi.org/10.1371/journal.pone.0246099
-
[8]
Understanding the nature of metadata: Systematic review,
H. Ulrich, A.-K. Kock-Schoppenhauer, N. Deppenwiese, R. G ¨ott, J. Kern, M. Lablans, R. W. Majeed, M. R. St ¨ohr, J. Stausberg, J. Varghese, M. Dugas, and J. Ingenerf, “Understanding the nature of metadata: Systematic review,”J Med Internet Res, vol. 24, no. 1, p. e25440, Jan 2022. [Online]. Available: https://www.jmir.org/2022/1/e25440
2022
-
[9]
L. M. Koesten, E. Kacprzak, J. F. A. Tennison, and E. Simperl, “The trials and tribulations of working with structured data: - a study on information seeking behaviour,” inProceedings of the 2017 CHI Conference on Human Factors in Computing Systems, ser. CHI ’17. New York, NY , USA: Association for Computing Machinery, 2017, p. 1277–1289. [Online]. Availa...
-
[10]
Autoddg: Automated dataset description generation using large language models,
H. Zhang, Y . Liu, A. Santos, W.-L. Hung, and J. Freire, “Autoddg: Automated dataset description generation using large language models,”
-
[11]
Available: https://arxiv.org/abs/2502.01050
[Online]. Available: https://arxiv.org/abs/2502.01050
-
[12]
Data prompting: Assessing the potential of conversational generative ai for dataset discovery,
J. Walker, E. Koutsiana, A. Das, J. Massey, G. Thuermer, and E. Simperl, “Data prompting: Assessing the potential of conversational generative ai for dataset discovery,”SSRN Electronic Journal, 2024, manuscript PATTERNS-D-24-00133. [Online]. Available: https://ssrn.com/abstract=4928179
2024
-
[13]
L.-Y . Gan, A. Das, J. Walker, and E. Simperl, “Keywords are not always the key: A metadata field analysis for natural language search on open data portals,” 2025. [Online]. Available: https://arxiv.org/abs/2509.14457
arXiv 2025
-
[14]
The impact of modern AI in metadata management,
W. Yang, R. Fu, M. B. Amin, and B. Kang, “The impact of modern AI in metadata management,”Human-Centric Intelligent Systems, vol. 5, no. 3, pp. 323–350, Sep. 2025
2025
-
[15]
Pre-meta: priors- augmented retrieval for llm-based metadata generation,
P. Tinn, S. Sørbø, S. Jiang, K. V outetakis, S. M. Giounis, E. Pilalis, O. Papadodima, and D. Roman, “Pre-meta: priors- augmented retrieval for llm-based metadata generation,”Bioinformatics, vol. 41, no. 10, p. btaf519, 09 2025. [Online]. Available: https://doi.org/10.1093/bioinformatics/btaf519
-
[16]
Enhancing open data findability: Fine- tuning llms(t5) for metadata generation,
U. Ahmed and A. Polini, “Enhancing open data findability: Fine- tuning llms(t5) for metadata generation,”Conference on Digital Government Research, vol. 26, May 2025. [Online]. Available: https://proceedings.open.tudelft.nl/DGO2025/article/view/941
2025
-
[17]
Large language models can extract metadata for annotation of human neuroimaging publications,
M. D. Turner, A. Appaji, N. Ar Rakib, P. Golnari, A. K. Rajasekar, A. R. K, V , S. S. Sahoo, Y . Wang, L. Wang, and J. A. Turner, “Large language models can extract metadata for annotation of human neuroimaging publications,”Front Neuroinform, vol. 19, p. 1609077, Aug. 2025
2025
-
[18]
Metadata generation and evaluation using llms - case study on canonical titles,
S. Zhu, S. Simonovikj, D. Edmonds, and Y . Sun, “Metadata generation and evaluation using llms - case study on canonical titles,” in Proceedings of the Nineteenth ACM Conference on Recommender Systems, ser. RecSys ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 1010–1013. [Online]. Available: https://doi.org/10.1145/3705328.3748100
-
[19]
Looking ahead: The research nexus and the state of metadata in 2050,
E. Pentz, M. Rittman, and D. Tkaczyk, “Looking ahead: The research nexus and the state of metadata in 2050,”Science Editor, vol. 48, no. 1, pp. 19–21, 2025
2050
-
[20]
APPLS: Evaluating evaluation metrics for plain language summarization,
Y . Guo, T. August, G. Leroy, T. Cohen, and L. L. Wang, “APPLS: Evaluating evaluation metrics for plain language summarization,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, Eds. Miami, Florida, USA: Association for Computational Linguistics, Nov. 2024, pp. 9194–9211....
2024
-
[21]
R. Lin, B. Chopra, W. Lin, S. Shankar, M. Hulsebos, and A. G. Parameswaran, “Rethinking dataset discovery with datascout,” in Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology, ser. UIST ’25. New York, NY , USA: Association for Computing Machinery, 2025. [Online]. Available: https://doi.org/10.1145/3746059.3747727
-
[22]
Characterising dataset search—an analysis of search logs and data requests,
E. Kacprzak, L. Koesten, L.-D. Ib ´a˜nez, T. Blount, J. Tennison, and E. Simperl, “Characterising dataset search—an analysis of search logs and data requests,”Journal of Web Semantics, vol. 55, pp. 37–55, 2019. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1570826818300556
2019
-
[23]
The role of metadata in reproducible computational research,
J. Leipzig, D. N ¨ust, C. T. Hoyt, K. Ram, and J. Greenberg, “The role of metadata in reproducible computational research,” Patterns, vol. 2, no. 9, p. 100322, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S2666389921001707
2021
-
[24]
A metadata schema for data objects in clinical research,
S. Canham and C. Ohmann, “A metadata schema for data objects in clinical research,”Trials, vol. 17, no. 1, p. 557, Nov. 2016
2016
-
[25]
Metadata standard for continuous preservation, discovery, and reuse of research data in repositories by higher education institutions: A systematic review,
N. F. Mosha and P. Ngulube, “Metadata standard for continuous preservation, discovery, and reuse of research data in repositories by higher education institutions: A systematic review,”Information, vol. 14, no. 8, 2023. [Online]. Available: https://www.mdpi.com/2078- 2489/14/8/427
2023
-
[26]
Everything you always wanted to know about a dataset: Studies in data summarisation,
L. Koesten, E. Simperl, T. Blount, E. Kacprzak, and J. Tennison, “Everything you always wanted to know about a dataset: Studies in data summarisation,”International Journal of Human- Computer Studies, vol. 135, p. 102367, 2020. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1071581918306153
2020
-
[27]
Q. Li, P. Wang, C. Liu, X. Li, and J. Hou, “Integration patterns in the use of metadata for data sense-making during relevance evaluation: An interpretable deep learning-based prediction,” Journal of the Association for Information Science and Technology, vol. 76, no. 3, pp. 621–641, 2025. [Online]. Available: https://asistdl.onlinelibrary.wiley.com/doi/a...
-
[28]
Fair data pipeline: provenance-driven data management for traceable scientific workflows,
S. N. Mitchell, A. Lahiff, N. Cummings, J. Hollocombe, B. Boskamp, R. Field, D. Reddyhoff, K. Zarebski, A. Wilson, B. Viola, M. Burke, B. Archibald, P. Bessell, R. Blackwell, L. A. Boden, A. Brett, S. Brett, R. Dundas, J. Enright, A. N. Gonzalez-Beltran, C. Harris, I. Hinder, C. David Hughes, M. Knight, V . Mano, C. McMonagle, D. Mellor, S. Mohr, G. Mario...
-
[29]
Practices do not make perfect: Disciplinary data sharing and reuse practices and their implications for repository data curation,
I. M. Faniel and E. Yakel, “Practices do not make perfect: Disciplinary data sharing and reuse practices and their implications for repository data curation,” inCurating Research Data, Volume One: Practical Strategies for Your Digital Repository. Chicago, Illinois: Association of College and Research Libraries, 2017, pp. 103–126
2017
-
[30]
Understanding data search as a socio-technical practice,
K. M. Gregory, H. Cousijn, P. Groth, A. Scharnhorst, and S. Wyatt, “Understanding data search as a socio-technical practice,”Journal of Information Science, vol. 46, no. 4, pp. 459–475, 2020. [Online]. Available: https://doi.org/10.1177/0165551519837182
-
[31]
Data reusers’ trust development,
A. Yoon, “Data reusers’ trust development,”Journal of the Association for Information Science and Technology, vol. 68, no. 4, pp. 946–956, 2017. [Online]. Available: https://asistdl.onlinelibrary.wiley.com/doi/abs/10.1002/asi.23730
-
[32]
On the reuse of scientific data,
I. V . Pasquetto, B. M. Randles, and C. L. Borgman, “On the reuse of scientific data,”Data Science Journal, Mar 2017
2017
-
[33]
The conundrum of sharing research data,
C. L. Borgman, “The conundrum of sharing research data,” Journal of the American Society for Information Science and Technology, vol. 63, no. 6, pp. 1059–1078, 2012. [Online]. Available: https://onlinelibrary.wiley.com/doi/abs/10.1002/asi.22634
-
[34]
Exploratory search: from finding to understanding,
G. Marchionini, “Exploratory search: from finding to understanding,” Commun. ACM, vol. 49, no. 4, p. 41–46, Apr. 2006. [Online]. Available: https://doi.org/10.1145/1121949.1121979
-
[35]
Are there any differences in data set retrieval compared to well-known literature retrieval?
D. Kern and B. Mathiak, “Are there any differences in data set retrieval compared to well-known literature retrieval?” inResearch and Advanced Technology for Digital Libraries, ser. Lecture Notes in Computer Science. Cham: Springer, 2015, vol. 9316, pp. 197–208. [Online]. Available: http://kups.ub.uni-koeln.de/9359/
2015
-
[36]
What are data? the many kinds of data and their implications for data re-use,
S. Carlson and B. Anderson, “What are data? the many kinds of data and their implications for data re-use,”Journal of Computer-Mediated Communication, vol. 12, no. 2, pp. 635–651, 01 2007. [Online]. Available: https://doi.org/10.1111/j.1083-6101.2007.00342.x
-
[37]
Unfolding the downloads of datasets: A multifaceted exploration of influencing factors,
Z. Liu, P. Luo, X. Tang, J. Wang, and L. Nie, “Unfolding the downloads of datasets: A multifaceted exploration of influencing factors,”Scientific Data, vol. 11, no. 1, p. 760, Jul. 2024
2024
-
[38]
User centred methods for measuring the value of open data,
J. Walker, M. Frank, and N. Thompson, “User centred methods for measuring the value of open data,” inOpen Data Research Symposium 2015 (27/05/15 - 27/05/15), May 2015. [Online]. Available: https://eprints.soton.ac.uk/375700/
2015
-
[39]
Improving discoverability of open government data with rich metadata descriptions using semantic government vocabulary,
P. K ˇremen and M. Ne ˇcask´y, “Improving discoverability of open government data with rich metadata descriptions using semantic government vocabulary,”Journal of Web Semantics, vol. 55, pp. 1–20, 2019. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1570826818300714
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.