SoulX-Transcriber: A Robust End-to-End Framework for Multi-Speaker Speech Transcription
Pith reviewed 2026-06-28 12:36 UTC · model grok-4.3
The pith
SoulX-Transcriber jointly models speaker diarization and automatic speech recognition in one LLM-based system via two-stage training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
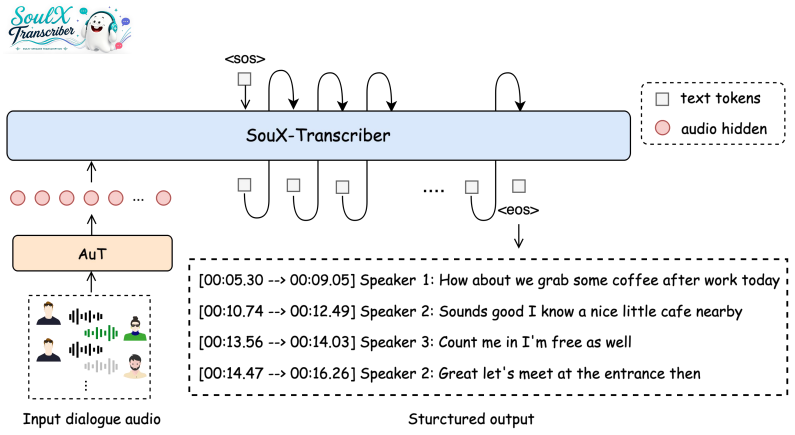
SoulX-Transcriber is a unified multi-speaker transcription system that jointly models speaker diarization and ASR within an LLM-based framework. It adopts a two-stage training strategy in which speaker-aware multi-task continuous pre-training first enhances speaker representation learning and boundary perception, after which supervised fine-tuning optimizes the model for accurate end-to-end speaker-attributed transcription under complex conditions.
What carries the argument
The two-stage training strategy of speaker-aware multi-task continuous pre-training followed by supervised fine-tuning, which jointly optimizes speaker discrimination and transcription accuracy inside the LLM.
If this is right
- Strong results are achieved on AliMeeting, AISHELL-4, and AMI benchmarks.
- The model maintains adaptability across multiple domains without separate pipelines.
- Speaker discrimination and transcription robustness both improve through the staged training.
- End-to-end speaker-attributed output becomes feasible directly from the LLM.
Where Pith is reading between the lines
- The joint LLM approach could reduce error propagation that occurs when diarization and ASR run sequentially.
- Extending the pre-training to include more acoustic variability might further improve boundary accuracy on noisy data.
- Production systems could replace two separate models with one, lowering latency for live transcription.
- Similar joint modeling might apply to other audio tasks such as emotion detection alongside transcription.
Load-bearing premise
The two-stage training strategy is sufficient to overcome similar voices, rapid turn-taking, overlapping utterances, and inaccurate boundary segmentation in variable real-world conditions.
What would settle it
Performance on a new test set with higher speaker similarity or denser overlaps that falls below strong separate diarization-plus-ASR pipelines would show the joint model does not deliver the claimed robustness.
Figures


read the original abstract
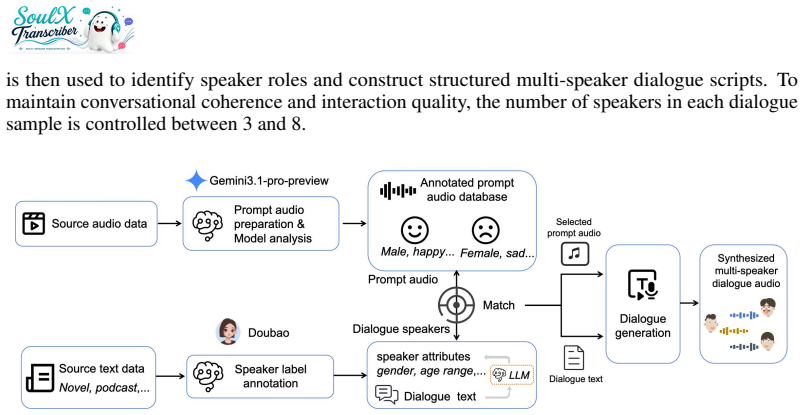
Recent advances in Automatic Speech Recognition (ASR) and Large Language Models (LLMs) have significantly improved speech understanding capabilities. However, multi-speaker speech transcription remains challenging task, constrained by highly similar speaker voices, rapid turn-taking transitions, overlapping utterances and inaccurate speaker boundary segmentation. These challenges become particularly pronounced in real-world conversational audio, where speaker dynamics and acoustic conditions are highly variable. This technical report presents SoulX-Transcriber, a unified multi-speaker transcription system that jointly models speaker diarization (SD) and ASR within an LLM-based framework. SoulX-Transcriber adopts a two-stage training strategy to improve both speaker discrimination and transcription robustness. In the first stage, speaker-aware multi-task continuous pre-training enhances speaker representation learning and boundary perception. In the second stage, supervised fine-tuning further optimizes the model for accurate end-to-end speaker-attributed transcription under complex multi-speaker conditions. SoulX-Transcriber delivers strong performance and robustness across multiple public benchmarks, including AliMeeting, AISHELL-4, and AMI, while maintaining high adaptability to multi-domain scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents SoulX-Transcriber, an LLM-based end-to-end framework for multi-speaker speech transcription that jointly models speaker diarization and automatic speech recognition. It employs a two-stage training strategy consisting of speaker-aware multi-task continuous pre-training to enhance speaker representation and boundary perception, followed by supervised fine-tuning for accurate speaker-attributed transcription. The paper claims that this approach delivers strong performance and robustness on public benchmarks including AliMeeting, AISHELL-4, and AMI, with high adaptability to multi-domain scenarios.
Significance. If the performance claims hold with supporting evidence, the work would be significant for advancing unified modeling of speaker diarization and ASR in challenging conversational settings by using a targeted two-stage LLM training approach that addresses speaker similarity, overlaps, and boundary issues.
major comments (1)
- [Abstract] Abstract: The manuscript asserts that SoulX-Transcriber 'delivers strong performance and robustness across multiple public benchmarks' but supplies no quantitative metrics (e.g., diarization error rate, word error rate), baseline comparisons, ablation results, or experimental details. This absence is load-bearing for the central claim that the two-stage training overcomes the listed challenges of similar voices, rapid turn-taking, and overlapping utterances.
minor comments (1)
- [Abstract] Grammatical error: 'remains challenging task' should read 'remains a challenging task'.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback. We address the major comment below and commit to revisions that strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript asserts that SoulX-Transcriber 'delivers strong performance and robustness across multiple public benchmarks' but supplies no quantitative metrics (e.g., diarization error rate, word error rate), baseline comparisons, ablation results, or experimental details. This absence is load-bearing for the central claim that the two-stage training overcomes the listed challenges of similar voices, rapid turn-taking, and overlapping utterances.
Authors: We agree that the abstract as written does not include specific quantitative metrics or comparisons, which weakens the central performance claim. The full manuscript contains dedicated experimental sections with tables reporting DER, cpWER, and baseline comparisons on AliMeeting, AISHELL-4, and AMI. To directly address the concern, we will revise the abstract to include key numerical highlights (e.g., achieved DER/WER values and relative gains) while preserving brevity, thereby making the claims evidence-based within the abstract itself. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical system description and training procedure for multi-speaker transcription without any mathematical derivations, equations, fitted parameters, or self-referential predictions. Performance claims rest on benchmark results rather than any chain that reduces to its own inputs by construction. No load-bearing steps qualify under the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
M. Shi, X. Xiao, R. Fan, S. Ling, and J. Li, “Train short, infer long: Speech-llm enables zero-shot streamable joint asr and diarization on long audio,”arXiv preprint arXiv:2511.16046, 2025
-
[2]
Vibevoice-asr technical report,
Z. Peng, J. Yu, Y . Chang, Z. Wang, L. Dong, Y . Hao, Y . Tu, C. Yang, W. Wang, S. Xu, et al., “Vibevoice-asr technical report,”arXiv preprint arXiv:2601.18184, 2026
-
[3]
Connecting speech encoder and large language model for asr,
W. Yu, C. Tang, G. Sun, X. Chen, T. Tan, W. Li, L. Lu, Z. Ma, and C. Zhang, “Connecting speech encoder and large language model for asr,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2024, pp. 12 637–12 641
2024
-
[4]
An embarrassingly simple approach for llm with strong asr capacity,
Z. Ma, G. Yang, Y . Yang, Z. Gao, J. Wang, Z. Du, F. Yu, Q. Chen, S. Zheng, S. Zhang, et al., “An embarrassingly simple approach for llm with strong asr capacity,”arXiv preprint arXiv:2402.08846, 2024
-
[5]
Enhancing speaker diarization with large language models: A contextual beam search approach,
T. J. Park, K. Dhawan, N. Koluguri, and J. Balam, “Enhancing speaker diarization with large language models: A contextual beam search approach,” inICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2024, pp. 10 861– 10 865
2024
-
[6]
Large language model can transcribe speech in multi-talker scenarios with versatile instructions,
L. Meng, S. Hu, J. Kang, Z. Li, Y . Wang, W. Wu, X. Wu, X. Liu, and H. Meng, “Large language model can transcribe speech in multi-talker scenarios with versatile instructions,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), IEEE, 2025, pp. 1–5
2025
-
[7]
Tagspeech: End-to-end multi-speaker asr and diarization with fine-grained temporal grounding,
M. Huo, Y . Shao, and Y . Zhang, “Tagspeech: End-to-end multi-speaker asr and diarization with fine-grained temporal grounding,”arXiv preprint arXiv:2601.06896, 2026
-
[8]
H. Yin, Y . Chen, C. Deng, L. Cheng, H. Wang, C.-H. Tan, Q. Chen, W. Wang, and X. Li, “Speakerlm: End-to-end versatile speaker diarization and recognition with multimodal large language models,”arXiv preprint arXiv:2508.06372, 2025
- [9]
-
[10]
Y . Dai, H. Lin, J. Qian, R. Yan, H. Meng, H. Xie, H. Wen, S. Yin, M. Tao, X. Chen, L. Xie, and X. Wang,Joint learning global-local speaker classification to enhance end-to-end speaker diarization and recognition, 2026. arXiv: 2603.25377 [cs.SD]. [Online]. Available: https://arxiv.org/abs/2603.25377
-
[11]
Z. Lin, S. Wang, Z. Sun, P. Xie, C. Xie, J. Liu, Q. Zhang, and L. Xie, “Speaker-reasoner: Scaling interaction turns and reasoning patterns for timestamped speaker-attributed asr,” 2026. arXiv:2604.03074
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Diarizationlm: Speaker di- arization post-processing with large language models,
Q. Wang, Y . Huang, G. Zhao, E. Clark, W. Xia, and H. Liao, “Diarizationlm: Speaker di- arization post-processing with large language models,”arXiv preprint arXiv:2401.03506, 2024
-
[13]
Speaker diarization with lexical informa- tion,
T. J. Park, K. J. Han, M. Kumar, and S. Narayanan, “Speaker diarization with lexical informa- tion,” inProc. Interspeech 2019, 2019, pp. 391–395
2019
-
[14]
M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,
F. Yu, S. Zhang, Y . Fu, L. Xie, S. Zheng, Z. Du, W. Huang, P. Guo, Z. Yan, B. Ma, X. Xu, and H. Bu, “M2MeT: The ICASSP 2022 multi-channel multi-party meeting transcription challenge,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2022, pp. 6167–6171
2022
-
[15]
AISHELL-4: An open source dataset for speech enhancement, separation, recognition and speaker diarization in conference scenario,
Y . Fu, L. Cheng, S. Lv, Y . Jv, Y . Kong, Z. Chen, Y . Hu, L. Xie, J. Wu, H. Bu, X. Xu, J. Du, and J. Chen, “AISHELL-4: An open source dataset for speech enhancement, separation, recognition and speaker diarization in conference scenario,” inProc. Interspeech 2021, 2021, pp. 3216–3220
2021
-
[16]
The AMI meeting corpus: A pre-announcement,
J. Carletta, S. Ashby, S. Bourban, M. Flynn, M. Guillemot, T. Hain, J. Kadlec, V . Karaiskos, W. Kraaij, M. Kronenthal, G. Lathoud, M. Lincoln, A. Lisowska, I. McCowan, W. Post, D. Reidsma, and P. Wellner, “The AMI meeting corpus: A pre-announcement,” inMachine Learning for Multimodal Interaction: Second International Workshop, MLMI 2005, Edinburgh, UK, J...
2005
-
[17]
Team,Silero vad: Pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,https://github.com/snakers4/silero-vad, 2024
S. Team,Silero vad: Pre-trained enterprise-grade voice activity detector (vad), number detector and language classifier,https://github.com/snakers4/silero-vad, 2024
2024
-
[18]
pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe,
H. Bredin, “pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe,” inProc. INTERSPEECH 2023, 2023
2023
-
[19]
Wenetspeech-chuan: A large-scale sichuanese corpus with rich annotation for dialectal speech processing,
Y . Dai, Z. Zhang, S. Wang, L. Li, Z. Guo, T. Zuo, S. Wang, H. Xue, C. Wang, Q. Wang, et al., “Wenetspeech-chuan: A large-scale sichuanese corpus with rich annotation for dialectal speech processing,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2026, pp. 19 507–19 511
2026
-
[20]
Hdbscan: Hierarchical density based clustering.,
L. McInnes, J. Healy, S. Astels, et al., “Hdbscan: Hierarchical density based clustering.,”J. Open Source Softw., vol. 2, no. 11, p. 205, 2017
2017
-
[21]
J. Chen, S. Xiao, P. Zhang, K. Luo, D. Lian, and Z. Liu,Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,
-
[22]
J. Xu, Z. Guo, H. Hu, Y . Chu, X. Wang, J. He, Y . Wang, X. Shi, T. He, X. Zhu, et al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Can audio large language models verify speaker identity?
Y . Ren, X. Xu, B. Li, S. Wang, and C. Zhang, “Can audio large language models verify speaker identity?”arXiv preprint arXiv:2509.19755, 2025
-
[24]
Summary on the multilingual conversational speech language model challenge: Datasets, tasks, baselines, and methods,
B. Mu, P. Guo, Z. Sun, S. Wang, H. Liu, M. Shao, L. Xie, E. S. Chng, L. Xiao, Q. Feng, et al., “Summary on the multilingual conversational speech language model challenge: Datasets, tasks, baselines, and methods,” inICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2026, pp. 19 442–19 446
2026
-
[25]
Transcribe- to-diarize: Neural speaker diarization for unlimited number of speakers using end-to-end speaker-attributed asr,
N. Kanda, X. Xiao, Y . Gaur, X. Wang, Z. Meng, Z. Chen, and T. Yoshioka, “Transcribe- to-diarize: Neural speaker diarization for unlimited number of speakers using end-to-end speaker-attributed asr,” inICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing, IEEE, 2022, pp. 8082–8086
2022
-
[26]
Chime-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings,
S. Watanabe, M. Mandel, J. Barker, E. Vincent, A. Arora, X. Chang, S. Khudanpur, V . Manohar, D. Povey, D. Raj, et al., “Chime-6 challenge: Tackling multispeaker speech recognition for unsegmented recordings,”arXiv preprint arXiv:2004.09249, 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.