LAANN: I/O-Aware Look-Ahead Search for Disk-Based Approximate Nearest Neighbor Search
Pith reviewed 2026-06-28 11:46 UTC · model grok-4.3
The pith
LAANN makes graph search in disk-based ANNS explicitly I/O-aware by processing cached candidates before committing to disk reads.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
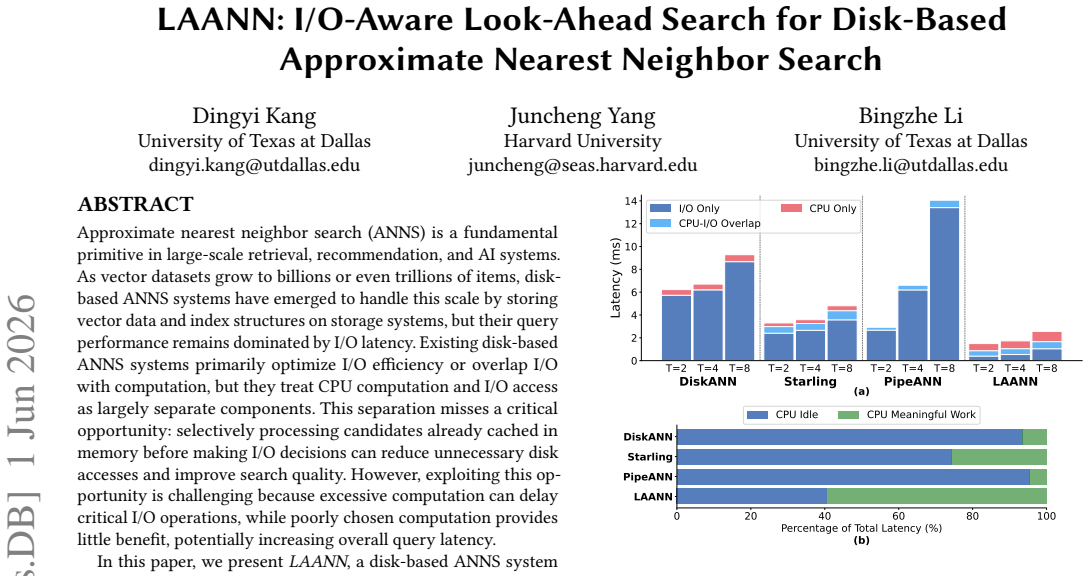
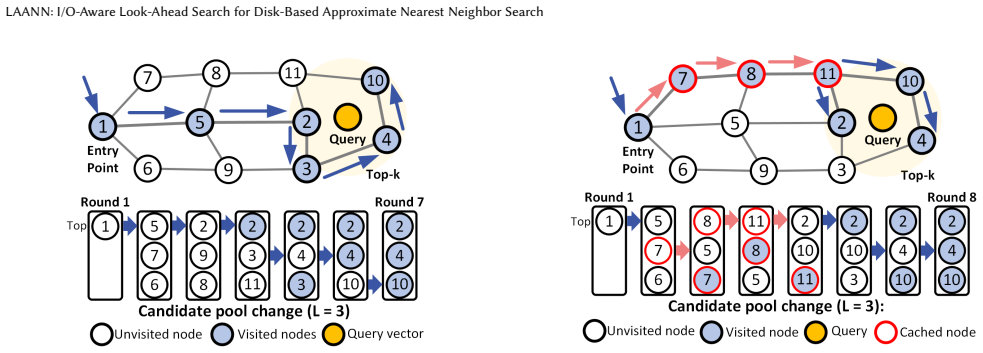
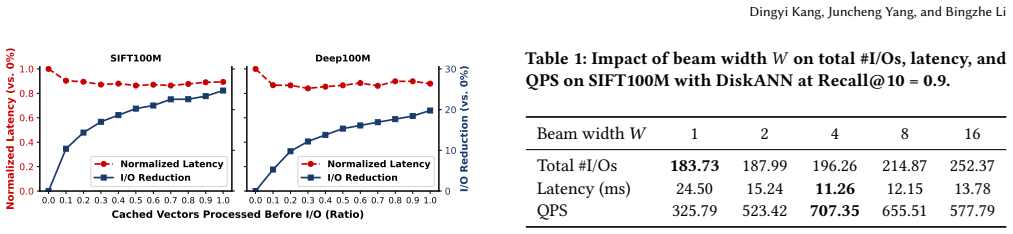
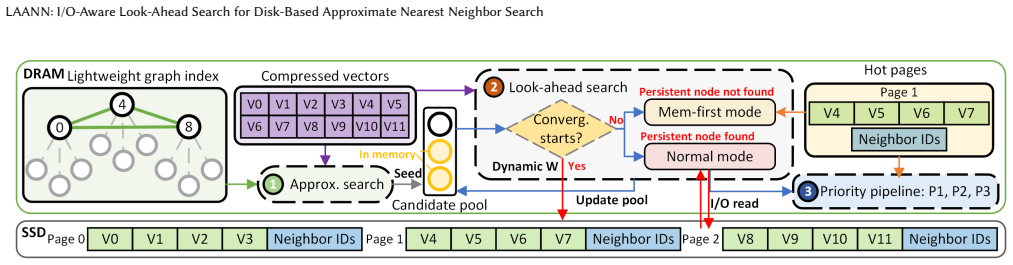
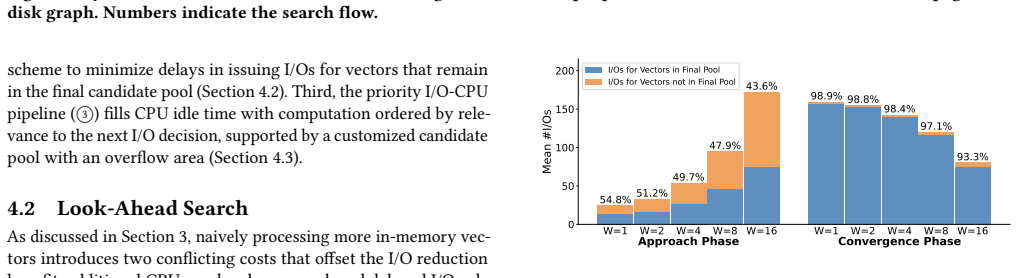
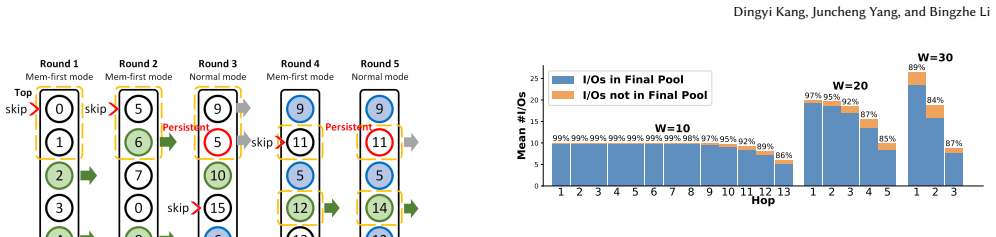
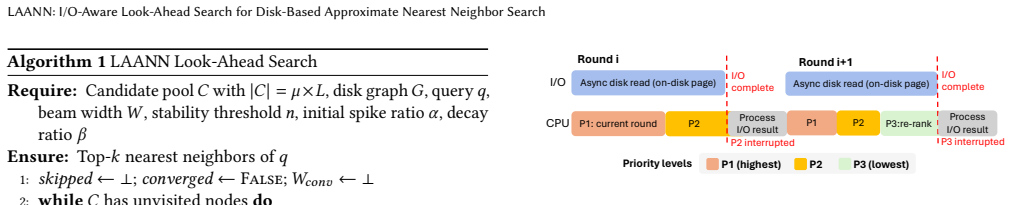
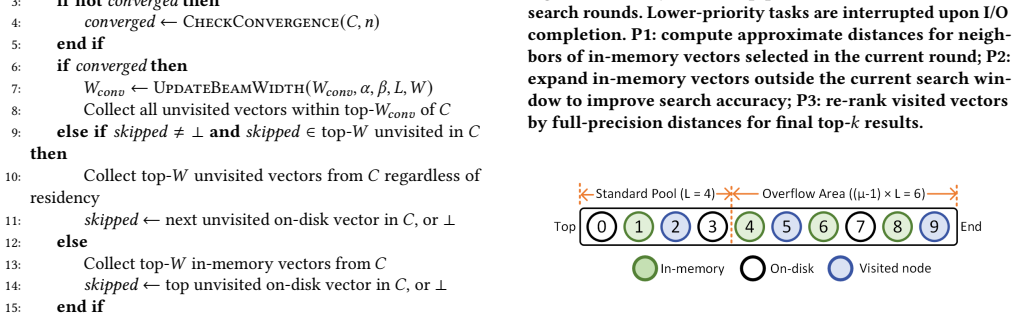
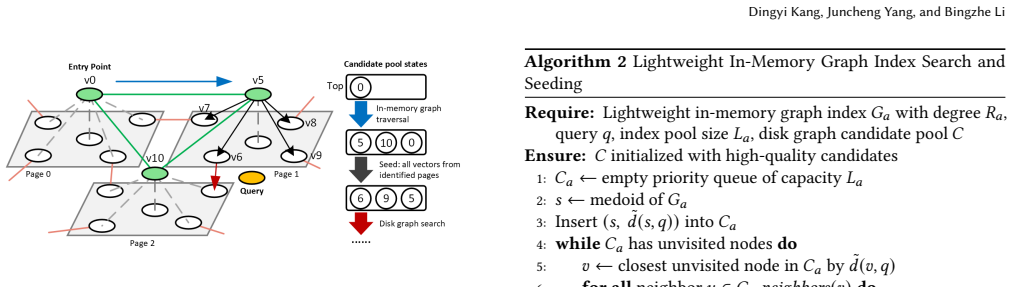
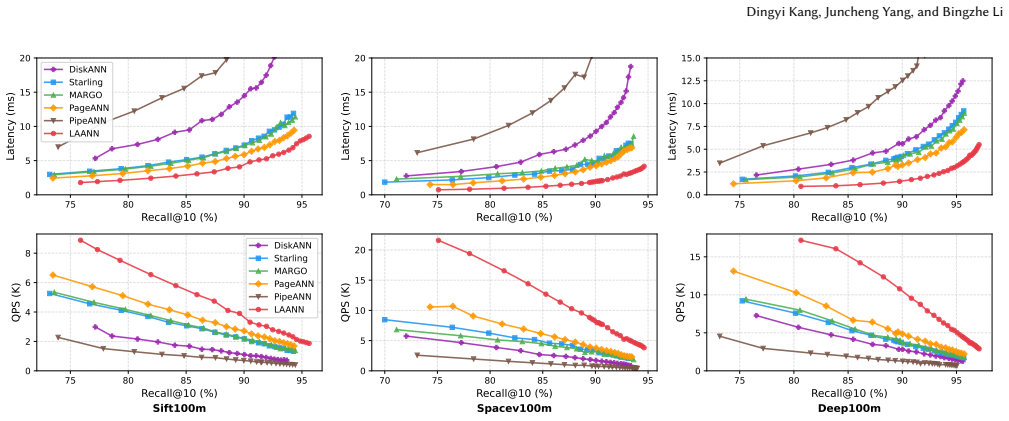
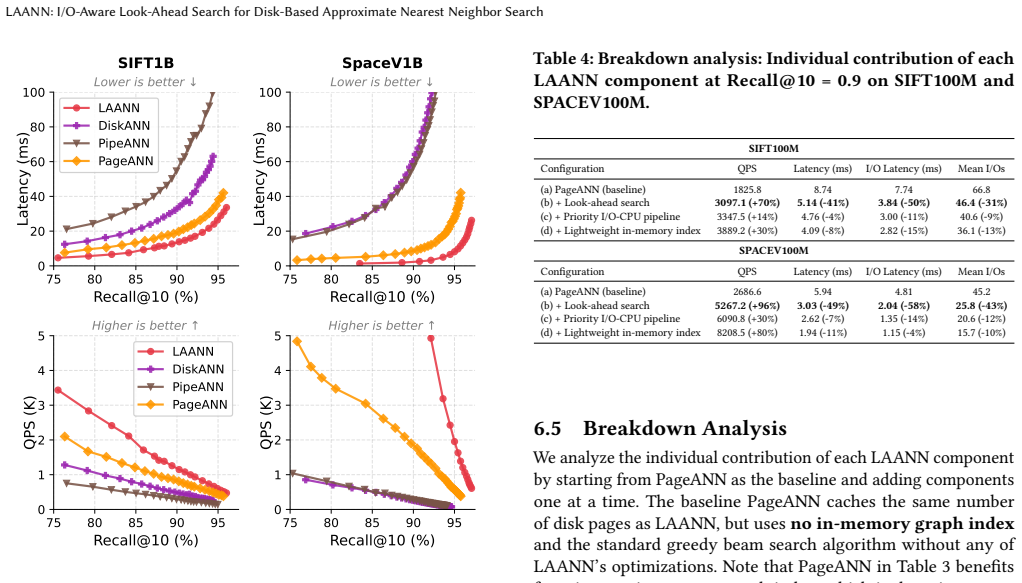
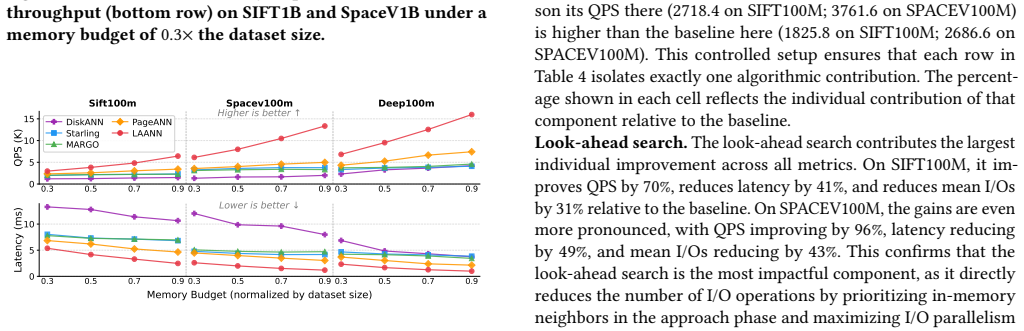
LAANN is a disk-based ANNS system that co-optimizes CPU computation and I/O access during graph search. It achieves this through three techniques: look-ahead search that changes strategy across query stages to balance I/O reduction with timely disk issuance; a priority I/O-CPU pipeline that processes memory-cached candidates during I/O waits according to their expected impact on future decisions; and a fast lightweight in-memory graph index that supplies high-quality initial candidates. On million- and billion-scale datasets this yields 1.41x-4.66x higher throughput, 29%-79% lower latency, and 1.59x-6.34x fewer I/O operations than prior disk-based systems at Recall@10 = 0.9.
What carries the argument
I/O-aware look-ahead graph search that adapts traversal while using a priority pipeline to compute on cached candidates during I/O waits, supported by a lightweight in-memory index for initial candidates.
If this is right
- Fewer disk accesses translate directly into lower query latency when storage is the bottleneck.
- The priority pipeline allows useful CPU work to overlap with I/O without postponing necessary reads.
- High-quality initial candidates from the in-memory index accelerate convergence and cut later disk accesses.
- The gains hold on both million-scale and billion-scale vector datasets.
Where Pith is reading between the lines
- The same co-optimization pattern could be applied to other storage-bound graph algorithms beyond ANNS.
- Workloads with very small memory caches might see diminished returns unless the pipeline cost is further reduced.
- Tighter CPU-I/O coupling might improve other database operations such as joins or index builds that also mix computation and disk access.
Load-bearing premise
Selectively processing cached candidates before I/O decisions will reduce unnecessary disk accesses without the added computation delaying critical I/O operations or providing negligible benefit.
What would settle it
A direct measurement on a workload with low cache-hit rates showing that the priority pipeline's extra computation increases end-to-end query latency relative to a pure I/O-optimized baseline.
Figures
read the original abstract
Approximate nearest neighbor search (ANNS) is a fundamental primitive in large-scale retrieval, recommendation, and AI systems. As vector datasets grow to billions or even trillions of items, disk-based ANNS systems have emerged to handle this scale by storing vector data and index structures on storage systems, but their query performance remains dominated by I/O latency. Existing disk-based ANNS systems primarily optimize I/O efficiency or overlap I/O with computation, but they treat CPU computation and I/O access as largely separate components. This separation misses a critical opportunity: selectively processing candidates already cached in memory before making I/O decisions can reduce unnecessary disk accesses and improve search quality. However, exploiting this opportunity is challenging because excessive computation can delay critical I/O operations, while poorly chosen computation provides little benefit, potentially increasing overall query latency. In this paper, we present LAANN, a disk-based ANNS system that makes graph search explicitly I/O-aware by co-optimizing CPU computation and I/O access. LAANN combines three techniques: look-ahead search, which adapts the search strategy across query stages to balance I/O reduction and timely I/O issuance; a priority I/O-CPU pipeline, which uses I/O waiting time to process candidates cached in memory according to their expected impact on upcoming I/O decisions; and a fast lightweight in-memory graph index, which provides high-quality initial candidates to accelerate convergence and reduce disk accesses. Experiments on million- and billion-scale datasets demonstrate that LAANN substantially outperforms state-of-the-art disk-based ANNS systems. At Recall@10 = 0.9, LAANN achieves 1.41x-4.66x higher throughput, 29%-79% lower latency, and 1.59x-6.34x fewer I/O operations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces LAANN, a disk-based ANNS system that co-optimizes CPU computation and I/O access via three techniques: look-ahead search (adapting strategy across query stages), a priority I/O-CPU pipeline (processing cached candidates during I/O waits according to expected impact), and a fast lightweight in-memory graph index (providing high-quality initial candidates). It claims that at Recall@10 = 0.9, LAANN delivers 1.41x-4.66x higher throughput, 29%-79% lower latency, and 1.59x-6.34x fewer I/O operations than prior disk-based ANNS systems on million- and billion-scale datasets.
Significance. If the experimental claims are reproducible and the pipeline demonstrably overlaps computation with I/O waits without net latency penalty, the work would advance disk-based ANNS by closing the gap between separate CPU and I/O optimizations, with potential impact on large-scale retrieval and AI systems. The reported I/O reductions and latency improvements are substantial enough to matter at billion-scale, but the current manuscript supplies only aggregate numbers without supporting methodology or traces.
major comments (2)
- [Abstract] Abstract: the central empirical claims (specific throughput, latency, and I/O multipliers at Recall@10 = 0.9) rest on experimental comparisons, yet the manuscript provides no description of datasets, baseline implementations, hardware, measurement methodology, or verification procedures, rendering the reported speedups and I/O counts impossible to assess or reproduce.
- [Technical description of the priority I/O-CPU pipeline] Technical description of the priority I/O-CPU pipeline: the abstract itself notes the risk that added computation can delay critical I/O, but no timing breakdown, per-stage latency traces, cache-hit statistics, or analysis is supplied to show that processing cached candidates actually shortens the critical path or produces the claimed 1.59x-6.34x I/O reduction rather than extending total latency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity and reproducibility.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claims (specific throughput, latency, and I/O multipliers at Recall@10 = 0.9) rest on experimental comparisons, yet the manuscript provides no description of datasets, baseline implementations, hardware, measurement methodology, or verification procedures, rendering the reported speedups and I/O counts impossible to assess or reproduce.
Authors: We agree that the abstract does not contain methodological details, as abstracts are typically concise. The full manuscript contains dedicated experimental sections describing the datasets (million- and billion-scale), baselines, hardware, and measurement procedures. To address the concern, we will revise the abstract to include a brief high-level description of the evaluation setup and add an explicit reproducibility subsection in the experimental evaluation. revision: yes
-
Referee: [Technical description of the priority I/O-CPU pipeline] Technical description of the priority I/O-CPU pipeline: the abstract itself notes the risk that added computation can delay critical I/O, but no timing breakdown, per-stage latency traces, cache-hit statistics, or analysis is supplied to show that processing cached candidates actually shortens the critical path or produces the claimed 1.59x-6.34x I/O reduction rather than extending total latency.
Authors: We acknowledge that the current description of the priority I/O-CPU pipeline lacks supporting timing analysis. The manuscript explains the design rationale but does not provide the requested breakdowns or traces. In the revision, we will add per-stage latency traces, cache-hit statistics, and a timing breakdown demonstrating that candidate processing overlaps with I/O waits without extending the critical path, thereby supporting the reported I/O reductions. revision: yes
Circularity Check
No circularity: claims rest on experimental benchmarks, not equations or self-referential fits.
full rationale
The paper presents LAANN as an engineering system combining look-ahead search, priority I/O-CPU pipeline, and a lightweight in-memory index. All performance claims (throughput, latency, I/O counts at fixed Recall@10) are supported solely by direct measurements on million- and billion-scale datasets against prior systems. No derivation chain, equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central argument is empirical comparison, not a mathematical reduction that collapses to its own inputs. This is the normal, non-circular case for systems papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Akari Asai, Sewon Min, Zexuan Zhong, and Danqi Chen. 2023. Retrieval-based language models and applications. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 6: Tutorial Abstracts). 41–46
2023
-
[2]
Artem Babenko and Victor Lempitsky. 2016. Efficient Indexing of Billion-Scale Datasets of Deep Descriptors. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2055–2063
2016
-
[3]
Vishwanath Bijalwan, Vinay Kumar, Pinki Kumari, and Jordan Pascual. 2014. KNN based machine learning approach for text and document mining.Interna- tional Journal of Database Theory and Application7, 1 (2014), 61–70
2014
-
[4]
Wout Bittremieux, Pieter Meysman, William Stafford Noble, and Kris Laukens
-
[5]
Fast open modification spectral library searching through approximate nearest neighbor indexing.Journal of proteome research17, 10 (2018), 3463–3474
2018
-
[6]
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Ruther- ford, Katie Millican, George Bm Van Den Driessche, Jean-Baptiste Lespiau, Bog- dan Damoc, Aidan Clark, et al. 2022. Improving language models by retrieving from trillions of tokens. InInternational conference on machine learning. PMLR, 2206–2240
2022
-
[7]
Yuan Cao, Heng Qi, Wenrui Zhou, Jien Kato, Keqiu Li, Xiulong Liu, and Jie Gui
-
[8]
Binary hashing for approximate nearest neighbor search on big data: A survey.IEEE Access6 (2017), 2039–2054
2017
-
[9]
Qi Chen, Haidong Wang, Mingqin Li, Gang Ren, Scarlett Li, Jeffery Zhu, Jason Li, Chuanjie Liu, Lintao Zhang, and Jingdong Wang. 2018. SPTAG: A library for fast approximate nearest neighbor search
2018
-
[10]
Thomas Cover and Peter Hart. 1967. Nearest neighbor pattern classification. IEEE transactions on information theory13, 1 (1967), 21–27
1967
-
[11]
Shiyuan Deng, Xiao Yan, KW Ng Kelvin, Chenyu Jiang, and James Cheng. 2019. Pyramid: A general framework for distributed similarity search on large-scale datasets. In2019 IEEE International Conference on Big Data (Big Data). IEEE, 1066–1071
2019
-
[12]
Myron Flickner, Harpreet Sawhney, Wayne Niblack, Jonathan Ashley, Qian Huang, Byron Dom, Monika Gorkani, Jim Hafner, Denis Lee, Dragutin Petkovic, et al. 1995. Query by image and video content: The QBIC system.computer28, 9 (1995), 23–32. LAANN: I/O-Aware Look-Ahead Search for Disk-Based Approximate Nearest Neighbor Search
1995
-
[13]
Cong Fu and Deng Cai. 2019. Efficient Approximate Nearest Neighbor Search with the Navigable Small World Graph. InIEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 41. 1102–1116
2019
- [14]
-
[15]
Hao Guo and Youyou Lu. 2025. Achieving Low-Latency Graph-Based Vec- tor Search via Aligning Best-First Search Algorithm with SSD (PipeANN). In Proceedings of the 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI ’25). Boston, MA, USA. Available as Open Access
2025
-
[16]
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang
-
[17]
InInternational confer- ence on machine learning
Retrieval augmented language model pre-training. InInternational confer- ence on machine learning. PMLR, 3929–3938
-
[18]
Jui-Ting Huang, Ashish Sharma, Shuying Sun, Li Xia, David Zhang, Philip Pronin, Janani Padmanabhan, Giuseppe Ottaviano, and Linjun Yang. 2020. Embedding- based retrieval in facebook search. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2553–2561
2020
-
[19]
Piotr Indyk and Rajeev Motwani. 1998. Approximate nearest neighbors: towards removing the curse of dimensionality. InProceedings of the thirtieth annual ACM symposium on Theory of computing. 604–613
1998
-
[20]
INRIA. [n.d.]. Datasets for Approximate Nearest Neighbor Search. http://corpus- texmex.irisa.fr/. Accessed: 2025-08-12
2025
-
[21]
Gautier Izacard, Patrick Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. Journal of Machine Learning Research24, 251 (2023), 1–43
2023
- [22]
-
[23]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rock- täschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[24]
Wen Li, Ying Zhang, Yifang Sun, Wei Wang, Mingjie Li, Wenjie Zhang, and Xuemin Lin. 2019. Approximate nearest neighbor search on high dimensional data—experiments, analyses, and improvement.IEEE Transactions on Knowledge and Data Engineering32, 8 (2019), 1475–1488
2019
-
[25]
Haotian Liu, Kilho Son, Jianwei Yang, Ce Liu, Jianfeng Gao, Yong Jae Lee, and Chunyuan Li. 2023. Learning customized visual models with retrieval-augmented knowledge. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 15148–15158
2023
-
[26]
Yury Malkov, Alexander Ponomarenko, Andrey Logvinov, and Vladimir Krylov
-
[27]
Approximate nearest neighbor algorithm based on navigable small world graphs.Information Systems45 (2014), 61–68
2014
-
[28]
Yu. A. Malkov and D. A. Yashunin. 2016. Efficient and Robust Approximate Nearest Neighbor Search Using Hierarchical Navigable Small World Graphs. In IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 40. 1249– 1265
2016
-
[29]
Microsoft Research. [n.d.]. Spacev1b: A Billion-Scale Vector Dataset for Text De- scriptors. https://github.com/microsoft/SPTAG/tree/master/datasets/SPACEV1B. Accessed: 2025-08-12
2025
- [30]
-
[31]
Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, and Yoav Shoham. 2023. In-context retrieval-augmented language models.Transactions of the Association for Computational Linguistics11 (2023), 1316–1331
2023
-
[32]
Hao Ren, Feng Liu, Pengfei Zhao, Jianliang Wang, and Rong Jin. 2020. HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory. In Advances in Neural Information Processing Systems (NeurIPS)
2020
-
[33]
Konstantin Schütze, Michael Heinzinger, Martin Steinegger, and Burkhard Rost
-
[34]
Nearest neighbor search on embeddings rapidly identifies distant protein relations.Frontiers in Bioinformatics2 (2022), 1033775
2022
-
[35]
Jayaram Subramanya, Devvrit Lovekar, Harsha Vardhan Simhadri, and An- shumali Shrivastava. 2019. DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node. InAdvances in Neural Information Process- ing Systems (NeurIPS). 13748–13758. https://papers.nips.cc/paper/2019/file/ 09853c7fb1dc7d9fd451d4980d70d63c-Paper.pdf
2019
-
[36]
Yukihiro Tagami. 2017. Annexml: Approximate nearest neighbor search for extreme multi-label classification. InProceedings of the 23rd ACM SIGKDD inter- national conference on knowledge discovery and data mining. 455–464
2017
-
[37]
Bing Tian, Haikun Liu, Yuhang Tang, Shihai Xiao, Zhuohui Duan, Xiaofei Liao, Hai Jin, Xuecang Zhang, Junhua Zhu, and Yu Zhang. 2025. Towards High- throughput and Low-latency Billion-scale Vector Search via{CPU/GPU } Collab- orative Filtering and Re-ranking. In23rd USENIX Conference on File and Storage Technologies (FAST 25). 171–185
2025
-
[38]
Jianguo Wang, Xiaomeng Yi, Rentong Guo, Hai Jin, Peng Xu, Shengjun Li, Xi- angyu Wang, Xiangzhou Guo, Chengming Li, Xiaohai Xu, et al. 2021. Milvus: A purpose-built vector data management system. InProceedings of the 2021 international conference on management of data. 2614–2627
2021
-
[39]
Mengzhao Wang, Weizhi Xu, Xiaomeng Yi, Songlin Wu, Zhangyang Peng, Xi- angyu Ke, Yunjun Gao, Xiaoliang Xu, Rentong Guo, and Charles Xie. 2024. Star- ling: An i/o-efficient disk-resident graph index framework for high-dimensional vector similarity search on data segment.Proceedings of the ACM on Management of Data2, 1 (2024), 1–27
2024
-
[40]
Chuangxian Wei, Bin Wu, Sheng Wang, Renjie Lou, Chaoqun Zhan, Feifei Li, and Yuanzhe Cai. 2020. Analyticdb-v: A hybrid analytical engine towards query fusion for structured and unstructured data.Proceedings of the VLDB Endowment 13, 12 (2020), 3152–3165
2020
-
[41]
Ziyang Yue, Bolong Zheng, Ling Xu, Kanru Xu, Shuhao Zhang, Yajuan Du, Yunjun Gao, Xiaofang Zhou, and Christian S Jensen. 2025. Select Edges Wisely: Monotonic Path Aware Graph Layout Optimization for Disk-Based ANN Search. Proceedings of the VLDB Endowment18, 11 (2025), 4337–4349
2025
-
[42]
Jianjin Zhang, Zheng Liu, Weihao Han, Shitao Xiao, Ruicheng Zheng, Yingxia Shao, Hao Sun, Hanqing Zhu, Premkumar Srinivasan, Weiwei Deng, et al. 2022. Uni-retriever: Towards learning the unified embedding based retriever in bing sponsored search. InProceedings of the 28th ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining. 4493–4501
2022
-
[43]
Yanhao Zhang, Pan Pan, Yun Zheng, Kang Zhao, Yingya Zhang, Xiaofeng Ren, and Rong Jin. 2018. Visual search at alibaba. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 993– 1001
2018
-
[44]
Pengfei Zhao, Jianliang Wang, Hao Ren, and Rong Jin. 2024. SmartANNS: Near- Data Processing for Billion-scale Approximate Nearest Neighbor Search. In USENIX Annual Technical Conference (ATC)
2024
- [45]
- [46]
-
[47]
Chun Jiang Zhu, Tan Zhu, Haining Li, Jinbo Bi, and Minghu Song. 2019. Accel- erating large-scale molecular similarity search through exploiting high perfor- mance computing. In2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). IEEE, 330–333
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.