Fast Transformer Inference on ARM-Based HMPSoCs
Pith reviewed 2026-06-28 11:41 UTC · model grok-4.3
The pith
Extending the ARM Compute Library with new transformer kernels enables up to three times faster inference on ARM-based embedded boards, with cooperative CPU-GPU execution adding up to 15.72 percent further latency reduction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
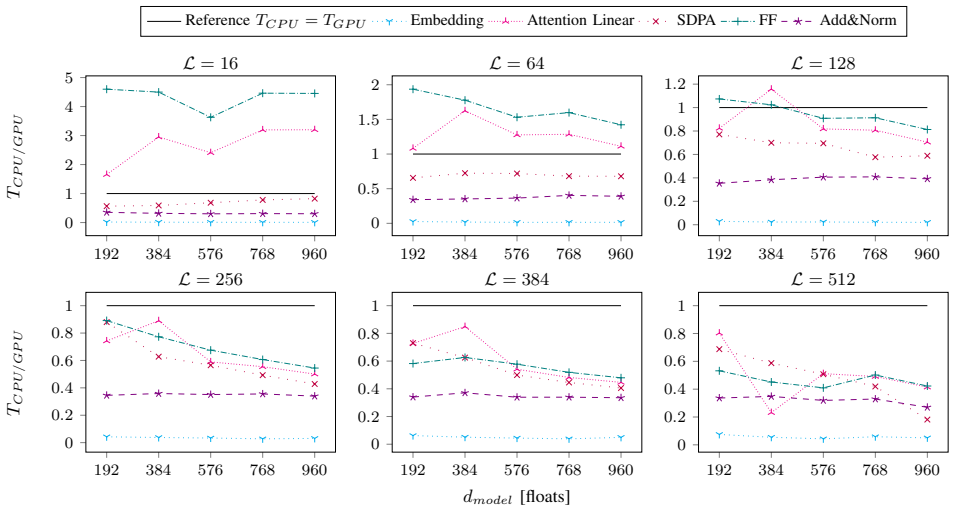
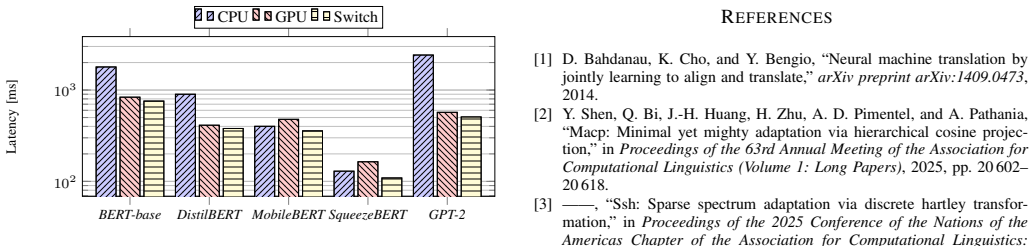
By implementing transformer kernels inside ARM-CL and adding a low-overhead cooperative CPU-GPU execution path, the authors demonstrate that transformer inference latency on an ARM-based embedded board can be reduced by up to a factor of three relative to prior CPU-only or GPU-only baselines, with an extra 15.72 percent improvement from the cooperative schedule.
What carries the argument
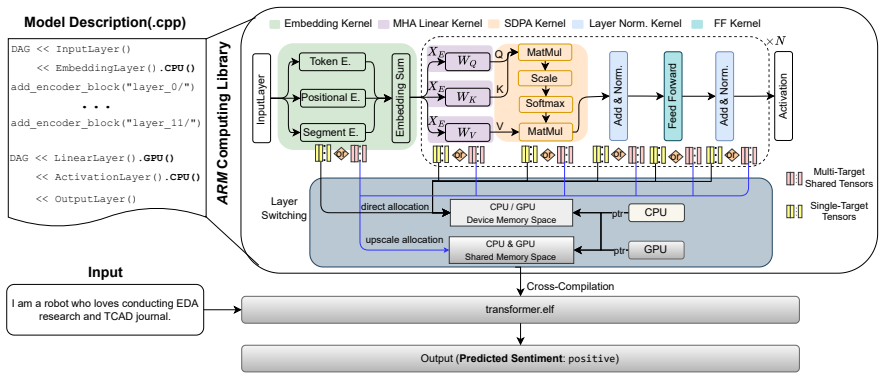
The extended ARM Compute Library containing newly added transformer kernels together with a cooperative scheduler that maps memory-intensive operations to CPU and parallelizable operations to GPU on HMPSoCs.
If this is right
- Transformer models can execute with substantially lower latency on existing ARM edge hardware without cloud offload.
- Cooperative CPU-GPU scheduling becomes a viable way to exploit both processors on HMPSoCs for inference workloads.
- Other edge frameworks could adopt similar kernel extensions to support transformers on ARM platforms.
Where Pith is reading between the lines
- The same kernel-extension approach could be tested on additional neural-network families beyond transformers to check breadth of applicability.
- Future HMPSoC designs might incorporate tighter CPU-GPU memory sharing to reduce the remaining overhead of the cooperative schedule.
- Energy measurements on the same board would reveal whether the latency gains also translate into lower power draw during inference.
Load-bearing premise
The reported speedups rest on the premise that the chosen transformer models, input sizes, and baseline implementations are representative and that the new kernels contain no hidden overheads or correctness issues.
What would settle it
Re-running the experiments on a different family of transformer models or with substantially larger batch sizes and measuring whether the factor-of-three and 15.72 percent speedups remain or shrink.
Figures


read the original abstract
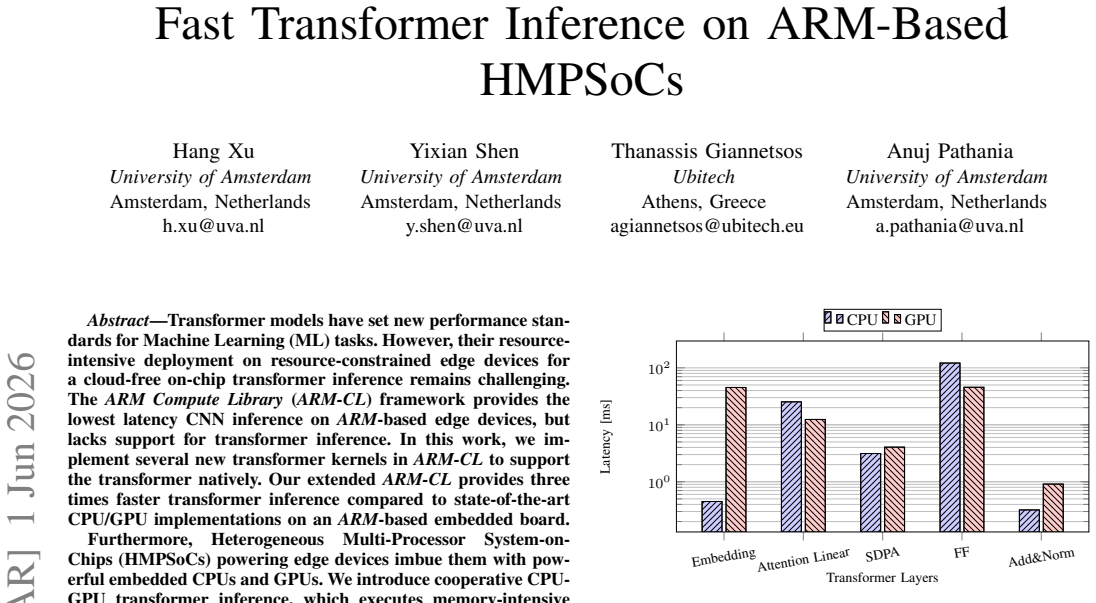
Transformer models have set new performance standards for machine learning (ML) tasks. However, their resource-intensive deployment on resource-constrained edge devices for cloud-free, on-chip transformer inference remains challenging. The ARM Compute Library (ARM-CL) framework provides low-latency CNN inference on ARM-based edge devices but lacks support for transformer inference. In this work, we implement several new transformer kernels in ARM-CL to support native transformer execution. Our extended ARM-CL achieves up to three times faster transformer inference compared to state-of-the-art CPU/GPU implementations on an ARM-based embedded board. Furthermore, heterogeneous multi-processor system-on-chips (HMPSoCs) powering edge devices provide both embedded CPUs and GPUs. We introduce cooperative CPU-GPU transformer inference, which executes memory-intensive operations on the CPU while utilizing the GPU for highly parallelizable, compute-intensive operations. This cooperative execution, implemented with minimal overhead, further reduces transformer inference latency by up to 15.72% compared to the best single-processor inference on ARM-CL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes extending the ARM Compute Library (ARM-CL) with new kernels to support transformer inference on ARM-based HMPSoCs. It reports achieving up to three times faster transformer inference compared to state-of-the-art implementations and an additional reduction in latency of up to 15.72% through cooperative CPU-GPU execution.
Significance. If validated with detailed experiments, the work could be significant for enabling efficient on-device transformer inference on resource-constrained edge devices by building on the established ARM-CL framework and exploiting HMPSoC heterogeneity. The approach of cooperative execution for memory vs compute intensive ops is a reasonable strategy for such platforms.
major comments (1)
- [Abstract] Abstract: The abstract states numerical speedups (up to 3× and 15.72%) but supplies no model names, layer counts, hardware specifications, baseline versions, measurement methodology, or variance. This prevents evaluation of whether the chosen configurations are representative and whether the new kernels introduce hidden overheads or correctness issues.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment. We agree that the abstract would benefit from additional specificity to allow readers to better assess the reported results. We address the point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract states numerical speedups (up to 3× and 15.72%) but supplies no model names, layer counts, hardware specifications, baseline versions, measurement methodology, or variance. This prevents evaluation of whether the chosen configurations are representative and whether the new kernels introduce hidden overheads or correctness issues.
Authors: We agree with the referee that the abstract, as currently written, lacks sufficient context. In the revised version we will expand the abstract to name the evaluated models (BERT-base with 12 encoder layers and a 4-layer decoder-only transformer), the target platform (specific ARM-based HMPSoC board with its CPU and GPU specifications), the exact baselines (current ARM-CL release plus the strongest published CPU-only and GPU-only implementations), and the measurement protocol (latency averaged over 1000 inferences with standard deviation reported). These additions will be kept concise while directly addressing the concerns about representativeness, overhead, and correctness. revision: yes
Circularity Check
No circularity: empirical implementation paper with no derivations
full rationale
This paper extends the ARM Compute Library with new transformer kernels and reports empirical speedups on HMPSoC hardware. It contains no equations, fitted parameters, first-principles derivations, or predictions that could reduce to their own inputs. All claims rest on direct code changes and measured latencies, with no self-citation chains or ansatzes invoked to justify results. The analysis is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Neural machine translation by jointly learning to align and translate,
D. Bahdanau, K. Cho, and Y . Bengio, “Neural machine translation by jointly learning to align and translate,”arXiv preprint arXiv:1409.0473, 2014
Pith/arXiv arXiv 2014
-
[2]
Macp: Minimal yet mighty adaptation via hierarchical cosine projec- tion,
Y . Shen, Q. Bi, J.-H. Huang, H. Zhu, A. D. Pimentel, and A. Pathania, “Macp: Minimal yet mighty adaptation via hierarchical cosine projec- tion,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), 2025, pp. 20 602– 20 618
2025
-
[3]
Ssh: Sparse spectrum adaptation via discrete hartley transfor- mation,
——, “Ssh: Sparse spectrum adaptation via discrete hartley transfor- mation,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), 2025, pp. 10 400–10 415
2025
-
[4]
Bae: Bert-based adversarial examples for text classification,
S. Garg and G. Ramakrishnan, “Bae: Bert-based adversarial examples for text classification,”arXiv preprint arXiv:2004.01970, 2020
arXiv 2004
-
[5]
End-to-end object detection with transformers,
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, “End-to-end object detection with transformers,” in European conference on computer vision. Springer, 2020, pp. 213– 229
2020
-
[6]
J. Li, S. Zheng, Y . Shen, J.-H. Huang, X. Lu, M. Ni, and Y . Guan, “Keeping the evidence chain: Semantic evidence allocation for training- free token pruning in video temporal grounding,”arXiv preprint arXiv:2603.05663, 2026
Pith/arXiv arXiv 2026
-
[7]
Mobilebert: a compact task-agnostic bert for resource-limited devices,
Z. Sun, H. Yu, X. Song, R. Liu, Y . Yang, and D. Zhou, “Mobilebert: a compact task-agnostic bert for resource-limited devices,”arXiv preprint arXiv:2004.02984, 2020
arXiv 2004
-
[8]
Tcps: a task and cache-aware partitioned scheduler for hard real-time multi-core systems,
Y . Shen, J. Xiao, and A. D. Pimentel, “Tcps: a task and cache-aware partitioned scheduler for hard real-time multi-core systems,” inProceed- ings of the 23rd ACM SIGPLAN/SIGBED International Conference on Languages, Compilers, and Tools for Embedded Systems, 2022, pp. 37– 49
2022
-
[9]
Cache interference-aware task partitioning for non-preemptive real-time multi-core systems,
J. Xiao, Y . Shen, and A. D. Pimentel, “Cache interference-aware task partitioning for non-preemptive real-time multi-core systems,”ACM Transactions on Embedded Computing Systems (TECS), vol. 21, no. 3, pp. 1–28, 2022
2022
-
[10]
Thermal management for 3d-stacked systems via unified core-memory power reg- ulation,
Y . Shen, L. Schreuders, A. Pathania, and A. D. Pimentel, “Thermal management for 3d-stacked systems via unified core-memory power reg- ulation,”ACM Transactions on Embedded Computing Systems, vol. 22, no. 5s, pp. 1–26, 2023
2023
-
[11]
Piqi: Partially quantized dnn inference on hmpsocs,
E. Aghapour, Y . Shen, D. Sapra, A. Pimentel, and A. Pathania, “Piqi: Partially quantized dnn inference on hmpsocs,” inProceedings of the 29th ACM/IEEE International Symposium on Low Power Electronics and Design, 2024, pp. 1–6
2024
-
[12]
Active imitation learning for thermal-and kernel-aware lfm inference on 3d s-nuca many-cores,
Y . Shen, C. Shen, J. Deen, G. Floros, A. Pimentel, and A. Pathania, “Active imitation learning for thermal-and kernel-aware lfm inference on 3d s-nuca many-cores,”arXiv preprint arXiv:2604.11948, 2026
Pith/arXiv arXiv 2026
-
[13]
{TVM}: An automated{End-to-End} optimizing compiler for deep learning,
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan, H. Shen, M. Cowan, L. Wang, Y . Hu, L. Cezeet al., “{TVM}: An automated{End-to-End} optimizing compiler for deep learning,” in13th USENIX Symposium on Operating Systems Design and Implementation (OSDI 18), 2018, pp. 578–594
2018
-
[14]
Pytorch,
S. Imambi, K. B. Prakash, and G. Kanagachidambaresan, “Pytorch,” Programming with TensorFlow: solution for edge computing applica- tions, pp. 87–104, 2021
2021
-
[15]
Enabling embedded inference engine with arm compute library: A case study,
D. Sun, S. Liu, and J.-L. Gaudiot, “Enabling embedded inference engine with arm compute library: A case study,”arXiv preprint arXiv:1704.03751, 2017
Pith/arXiv arXiv 2017
-
[16]
Cpu-gpu layer- switched low latency cnn inference,
E. Aghapour, D. Sapra, A. Pimentel, and A. Pathania, “Cpu-gpu layer- switched low latency cnn inference,” in2022 25th Euromicro Conference on Digital System Design (DSD). IEEE, 2022, pp. 324–331
2022
-
[17]
Novel casestudy and benchmarking of alexnet for edge ai: From cpu and gpu to fpga,
F. Al-Ali, T. D. Gamage, H. W. Nanayakkara, F. Mehdipour, and S. K. Ray, “Novel casestudy and benchmarking of alexnet for edge ai: From cpu and gpu to fpga,” in2020 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE). IEEE, 2020, pp. 1–4
2020
-
[18]
Towards efficient vision transformer inference: A first study of transformers on mobile devices,
X. Wang, L. L. Zhang, Y . Wang, and M. Yang, “Towards efficient vision transformer inference: A first study of transformers on mobile devices,” inProceedings of the 23rd annual international workshop on mobile computing systems and applications, 2022, pp. 1–7
2022
-
[19]
Squeezebert: What can computer vision teach nlp about efficient neural networks?
F. N. Iandola, A. E. Shaw, R. Krishna, and K. W. Keutzer, “Squeezebert: What can computer vision teach nlp about efficient neural networks?” arXiv preprint arXiv:2006.11316, 2020
arXiv 2006
-
[20]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015
Pith/arXiv arXiv 2015
-
[21]
Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,”arXiv preprint arXiv:1910.01108, 2019
Pith/arXiv arXiv 1910
-
[22]
Omniboost: Boosting throughput of heterogeneous embedded devices under multi-dnn workload,
A. Karatzas and I. Anagnostopoulos, “Omniboost: Boosting throughput of heterogeneous embedded devices under multi-dnn workload,” in2023 60th ACM/IEEE Design Automation Conference (DAC). IEEE, 2023
2023
-
[23]
Hidp: Hierarchical dnn partitioning for distributed inference on heterogeneous edge platforms,
Z. Taufique, A. Vyas, A. Miele, P. Liljeberg, and A. Kanduri, “Hidp: Hierarchical dnn partitioning for distributed inference on heterogeneous edge platforms,” in2025 Design, Automation & Test in Europe Confer- ence (DATE). IEEE, 2025, pp. 1–7
2025
-
[24]
Twill: Scheduling compound ai systems on heterogeneous mo- bile edge platforms,
——, “Twill: Scheduling compound ai systems on heterogeneous mo- bile edge platforms,” in2025 IEEE/ACM International Conference On Computer Aided Design (ICCAD). IEEE, 2025, pp. 1–9
2025
-
[25]
Pipebert: high-throughput bert inference for arm big. little multi-core processors,
H.-Y . Chang, S. H. Mozafari, C. Chen, J. J. Clark, B. H. Meyer, and W. J. Gross, “Pipebert: high-throughput bert inference for arm big. little multi-core processors,”Journal of Signal Processing Systems, vol. 95, no. 7, pp. 877–894, 2023
2023
-
[26]
Autoscale: Energy efficiency optimization for stochastic edge inference using reinforcement learning,
Y . G. Kim and C.-J. Wu, “Autoscale: Energy efficiency optimization for stochastic edge inference using reinforcement learning,” in2020 53rd Annual IEEE/ACM international symposium on microarchitecture (MICRO). IEEE, 2020, pp. 1082–1096
2020
-
[27]
Shared memory-contention-aware con- current dnn execution for diversely heterogeneous system-on-chips,
I. Dagli and M. E. Belviranli, “Shared memory-contention-aware con- current dnn execution for diversely heterogeneous system-on-chips,” inProceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming, 2024, pp. 243–256
2024
-
[28]
Band: coordinated multi-dnn inference on heterogeneous mobile processors,
J. S. Jeong, J. Lee, D. Kim, C. Jeon, C. Jeong, Y . Lee, and B.-G. Chun, “Band: coordinated multi-dnn inference on heterogeneous mobile processors,” inProceedings of the 20th Annual International Conference on Mobile Systems, Applications and Services, 2022, pp. 235–247
2022
-
[29]
Bert: Pre-training of deep bidirectional transformers for language understanding,
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.