The Case for Text-to-SQL Friendly Logical Database Design
Pith reviewed 2026-06-28 08:22 UTC · model grok-4.3
The pith
Database schemas can be redesigned with three semantics-preserving transformations to raise Text-to-SQL accuracy by up to 4.2 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
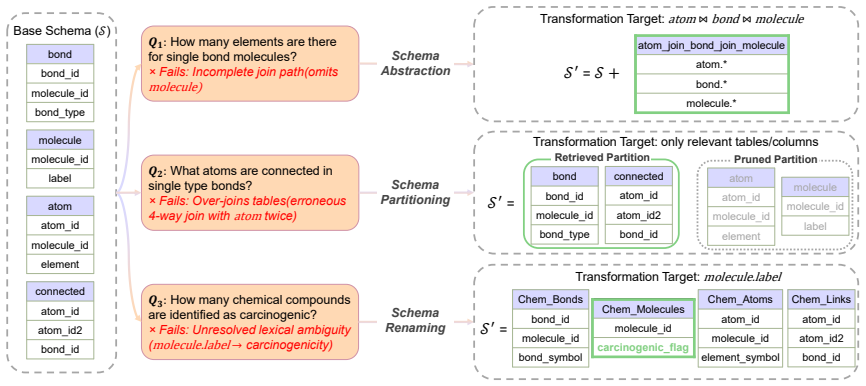
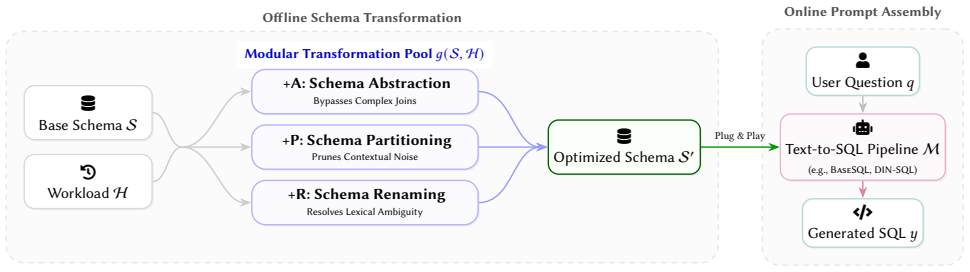
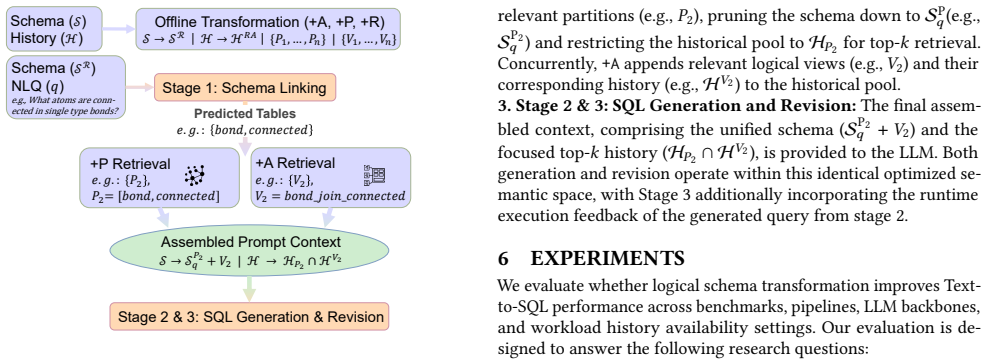
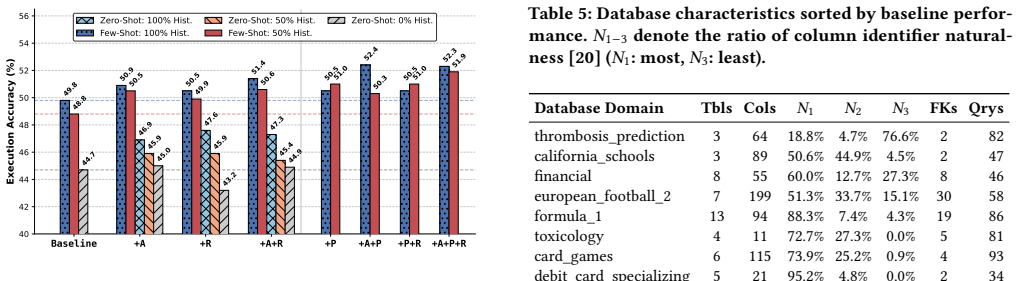
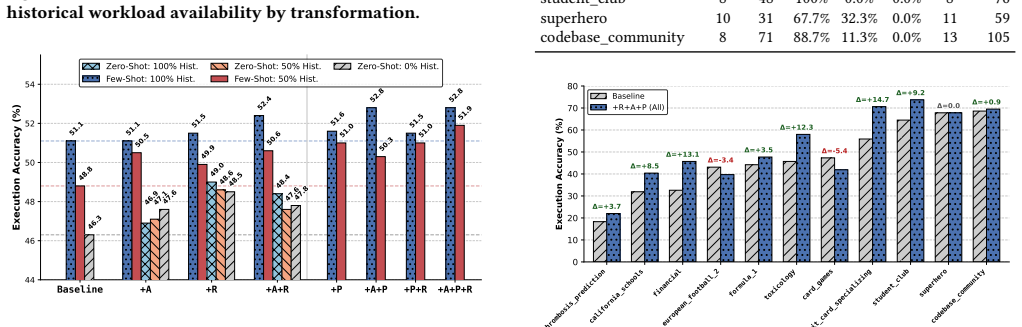
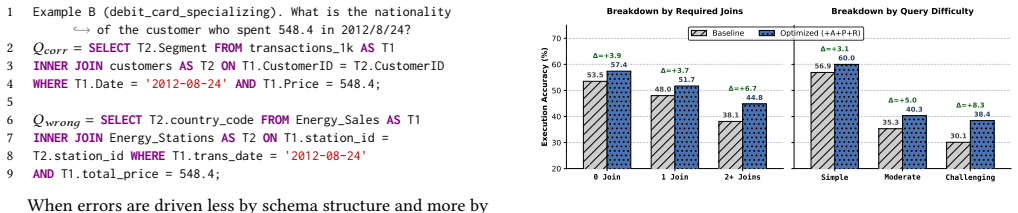
LLM-friendly logical database design is a practical optimization target. The three operators—schema abstraction that materializes recurring join paths as views, workload-aware partitioning that prunes irrelevant context, and descriptive renaming—compose without altering database semantics. When applied to schemas from BIRD-Union and Spider-Union they produce consistent execution-accuracy gains of up to 4.2 percent across multiple Text-to-SQL pipelines and language-model backbones; the full combination is reliably competitive and the best single operator varies modestly by pipeline.
What carries the argument
Three semantics-preserving schema transformations (+A abstraction via logical views, +P workload-aware partitioning, +R descriptive renaming) that re-purpose classical design ideas to improve language-model readability while leaving the underlying data model unchanged.
If this is right
- The three operators compose and the full +A+P+R combination improves accuracy on every tested pipeline.
- Renaming alone suffices in zero-shot settings; abstraction and partitioning gain extra guidance from historical question-SQL pairs when available.
- Different operator combinations remain competitive, so practitioners can choose subsets without losing all benefit.
- Gains appear across multiple language-model backbones, indicating the effect is not tied to one model family.
Where Pith is reading between the lines
- Schema design tools could expose these operators as an optional preprocessing step before any Text-to-SQL deployment.
- Similar readability-oriented transformations might benefit other LLM-driven database tasks such as query explanation or data discovery.
- If historical queries are scarce, the zero-shot renaming operator still provides a low-cost starting point.
Load-bearing premise
The transformations leave database semantics exactly the same and any measured accuracy gains are caused by better LLM understanding rather than incidental changes in context length, naming conventions, or evaluation details.
What would settle it
Re-run the full evaluation suite after applying the transformations but then randomly permuting column and table names (keeping context length fixed); if the accuracy gains disappear, the claim that the gains come from LLM-friendliness is supported.
Figures

read the original abstract
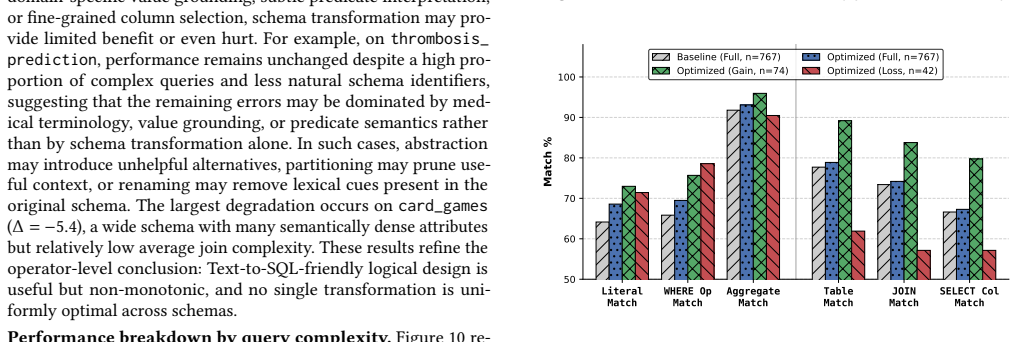
Logical database design has traditionally optimized database schemas, including tables, columns, keys, constraints, and views, for correctness, integrity, and human-written application queries. LLM-based Text-to-SQL changes the consumer: the schema is now often read as text by a language model, so design choices that preserve database semantics can still change SQL-generation accuracy. We argue that this creates a new design objective alongside the classical ones - LLM-friendly logical database design, the property that a schema is easy for a language model to map from natural language to correct SQL - and treat it as the optimization target of this paper. We instantiate this objective with three semantics-preserving schema transformations that re-purpose classical schema-design ideas: schema abstraction (+A: logical views that materialize recurring join paths), schema partitioning (+P: workload-aware logical partitions that prune irrelevant context), and schema renaming (+R: descriptive identifiers that improve downstream column linking and predicate construction). The three operators compose, and each preserves the underlying database semantics. When historical question-SQL pairs are available, they guide both partitioning and abstraction; in zero-shot settings, renaming applies directly, and abstraction falls back to an ad-hoc per-question variant. We evaluate the resulting schemas on BIRD-Union and Spider-Union across multiple Text-to-SQL pipelines and language model backbones, with gains of up to 4.2% in execution accuracy. The best transformation varies modestly across pipelines and models, with the full +A+P+R consistently improving; multiple operator combinations are competitive on each pipeline. These results show that LLM-friendly logical design is a practical and underexplored database-side optimization target, complementary to existing Text-to-SQL pipelines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that logical database design should target LLM-friendliness in addition to classical objectives, because Text-to-SQL systems consume schemas as text. It proposes three composable, semantics-preserving transformations—abstraction via logical views (+A), workload-aware partitioning (+P), and descriptive renaming (+R)—that can be guided by historical queries when available. These are evaluated on BIRD-Union and Spider-Union across multiple Text-to-SQL pipelines and LLM backbones, reporting execution-accuracy gains of up to 4.2 % with the full +A+P+R combination consistently helpful.
Significance. If the transformations are exactly semantics-preserving and the measured gains are shown to arise from LLM-friendliness rather than incidental prompt-length or naming changes, the work identifies a practical, database-side complement to existing Text-to-SQL pipelines. The use of public benchmarks and multiple pipelines is a strength; the absence of formal equivalence arguments or confound controls currently limits the strength of that conclusion.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the central claim that accuracy gains are caused by improved LLM-friendliness rests on the unverified premise that +A, +P, and +R preserve semantics exactly. No formal equivalence argument, rewrite rules, or workload-equivalence checks are supplied, so it remains possible that the 4.2 % delta arises from shorter context (+P) or altered column identifiers (+R) rather than the intended design objective.
- [Evaluation] Evaluation section: the reported experiments do not describe controls or ablations that isolate the effect of LLM-friendliness from changes in prompt length, identifier distinctiveness, or pipeline details. Without such controls the attribution of gains specifically to the new design objective cannot be verified from the given results.
minor comments (1)
- [Methodology] The description of how the three operators compose and how the ad-hoc per-question abstraction variant is constructed in zero-shot settings could be clarified with a small example.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and will revise the manuscript accordingly to strengthen the formal arguments and experimental controls.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the central claim that accuracy gains are caused by improved LLM-friendliness rests on the unverified premise that +A, +P, and +R preserve semantics exactly. No formal equivalence argument, rewrite rules, or workload-equivalence checks are supplied, so it remains possible that the 4.2 % delta arises from shorter context (+P) or altered column identifiers (+R) rather than the intended design objective.
Authors: We acknowledge that the current manuscript lacks explicit formal equivalence arguments, rewrite rules, or workload-equivalence checks, even though Sections 3.1–3.3 describe each operator as semantics-preserving by construction. In the revised version we will add a new subsection (likely 3.4) that supplies (i) rewrite rules showing how any query on the transformed schema maps to an equivalent query on the original schema, (ii) a workload-equivalence argument based on the historical query set used to guide +A and +P, and (iii) a short proof sketch that +R is a pure renaming that leaves result sets unchanged. These additions will directly address the possibility that gains stem from incidental length or naming changes rather than the intended LLM-friendly design. revision: yes
-
Referee: [Evaluation] Evaluation section: the reported experiments do not describe controls or ablations that isolate the effect of LLM-friendliness from changes in prompt length, identifier distinctiveness, or pipeline details. Without such controls the attribution of gains specifically to the new design objective cannot be verified from the given results.
Authors: We agree that the present evaluation does not contain explicit controls that separate LLM-friendliness from prompt-length reduction or identifier changes. In the revision we will add a dedicated ablation subsection that reports: (1) a length-matched baseline that applies only the +P operator’s pruning without the semantic partitioning logic, (2) a random-renaming control that applies +R-style identifier changes without the descriptive semantics, and (3) per-pipeline measurements of token count versus accuracy to quantify length effects. These controls, together with the already-reported multi-pipeline and multi-model results, will allow readers to attribute gains more precisely to the LLM-friendly design objective. revision: yes
Circularity Check
No significant circularity; empirical evaluation on public benchmarks
full rationale
The paper proposes three schema transformations (+A, +P, +R) and reports execution-accuracy gains on standard public benchmarks (BIRD-Union, Spider-Union) across multiple pipelines and models. No load-bearing steps reduce by construction to fitted inputs, self-definitions, or author self-citations; the central claim rests on new empirical measurements against external benchmarks rather than any of the enumerated circular patterns. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The three schema transformations preserve the underlying database semantics exactly.
Reference graph
Works this paper leans on
-
[1]
Narasayya
Sanjay Agrawal, Surajit Chaudhuri, and Vivek R. Narasayya. 2000. Automated Selection of Materialized Views and Indexes in SQL Databases. InProceedings of the 26th International Conference on Very Large Data Bases (VLDB). VLDB Endowment, 496–505. http://www.vldb.org/conf/2000/P496.pdf
2000
-
[2]
Sanjay Agrawal, Vivek R. Narasayya, and Beverly Yang. 2004. Integrating Verti- cal and Horizontal Partitioning Into Automated Physical Database Design. In Proceedings of the ACM SIGMOD International Conference on Management of Data. ACM, 359–370. https://doi.org/10.1145/1007568.1007609
-
[3]
Zhenbiao Cao, Yuanlei Zheng, Zhihao Fan, Xiaojin Zhang, Wei Chen, and Xiang Bai. 2024. RSL-SQL: Robust Schema Linking in Text-to-SQL Generation.arXiv preprint arXiv:2411.00073(2024). https://doi.org/10.48550/arXiv.2411.00073
-
[4]
Surajit Chaudhuri and Vivek Narasayya. 1997. An Efficient, Cost-Driven Index Selection Tool for Microsoft SQL Server. InProceedings of the 23rd International Conference on Very Large Data Bases (VLDB)
1997
-
[5]
Surajit Chaudhuri and Gerhard Weikum. 2008. Foundations of Automated Data- base Tuning.Proceedings of the VLDB Endowment1, 1 (2008), 3–14
2008
-
[6]
b-mc2 Contributors. 2022. SQL Create Context: A Dataset with Attribute- Annotated DDL for Text-to-SQL. Hugging Face dataset. https://huggingface.co/ datasets/b-mc2/sql-create-context
2022
-
[7]
Carlo Curino, Yang Zhang, Evan P. C. Jones, and Samuel Madden. 2010. Schism: a Workload-Driven Approach to Database Replication and Partitioning.Proceed- ings of the VLDB Endowment3, 1 (2010), 48–57. https://doi.org/10.14778/1920841. 1920853
-
[8]
Minghang Deng, Ashwin Ramachandran, Canwen Xu, Lanxiang Hu, Zhewei Yao, Anupam Datta, and Hao Zhang. 2025. ReFoRCE: A Text-to-SQL Agent with Self-Refinement, Format Restriction, and Column Exploration. InICLR 2025 Workshop on VerifAI
2025
-
[9]
Jeffrey Eben, Aitzaz Ahmad, and Stephen Lau. 2025. RASL: Retrieval Augmented Schema Linking for Massive Database Text-to-SQL.CoRRabs/2507.23104 (2025). https://doi.org/10.48550/ARXIV.2507.23104 arXiv:2507.23104
-
[10]
Jonathan Fürst, Catherine Kosten, Farhad Nooralahzadeh, Yi Zhang, and Kurt Stockinger. 2025. Evaluating the Data Model Robustness of Text-to-SQL Systems Based on Real User Queries. InProceedings of the 28th International Conference on Extending Database Technology (EDBT)
2025
-
[11]
Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation.Proceedings of the VLDB Endowment17, 5 (2024), 1132– 1145
2024
-
[12]
Ullman, and Jennifer Widom
Hector Garcia-Molina, Jeffrey D. Ullman, and Jennifer Widom. 2008.Database Systems: The Complete Book(2 ed.). Pearson
2008
-
[13]
Alon Y. Halevy. 2001. Answering queries using views: A survey.The VLDB Journal10 (2001), 270–294. https://doi.org/10.1007/s007780100054
-
[14]
Venky Harinarayan, Anand Rajaraman, and Jeffrey D. Ullman. 1996. Imple- menting Data Cubes Efficiently. InProceedings of the ACM SIGMOD Inter- national Conference on Management of Data. ACM Press, 205–216. https: //doi.org/10.1145/233269.233333
-
[15]
Yannis Kotidis and Nick Roussopoulos. 1999. DynaMat: A Dynamic View Man- agement System for Data Warehouses. InProceedings of the 1999 ACM SIGMOD International Conference on Management of Data. 371–382
1999
-
[16]
Boyan Li, Chong Chen, Zhujun Xue, Yinan Mei, and Yuyu Luo. 2026. DeepEye- SQL: A Software-Engineering-Inspired Text-to-SQL Framework.Proceedings of the ACM on Management of Data
2026
-
[17]
Boyan Li, Jiayi Zhang, Ju Fan, Yanwei Xu, Chong Chen, Tang Nan, and Yuyu Luo. 2025. Alpha-SQL: Zero-Shot Text-to-SQL using Monte Carlo Tree Search. InProceedings of the 42nd International Conference on Machine Learning (ICML)
2025
-
[18]
Haoyang Li, Shang Wu, Xiaokang Zhang, Xinmei Huang, Jing Zhang, Fuxin Jiang, Shuai Wang, Tieying Zhang, Jianjun Chen, Rui Shi, Hong Chen, and Cuiping Li. 2025. OmniSQL: Synthesizing High-Quality Text-to-SQL Data at Scale.Proceedings of the VLDB Endowment18, 11 (2025), 4695–4709. https: //doi.org/10.14778/3749646.3749723
-
[19]
Jinyang Li, Binyuan Hui, Ge Qu, Jiaxi Yang, Binhua Li, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C. C. Chang, Fei Huang, Reynold Cheng, and Yongbin Li. 2023. Can LLM Already Serve as A Database Interface? A Big Bench for Large-Scale Database Grounded Text-to-SQLs. InAdvances in Neural ...
2023
-
[20]
Kyle Luoma and Arun Kumar. 2025. SNAILS: Schema Naming Assessments for Improved LLM-Based SQL Inference.Proceedings of the ACM on Management of Data (PACMMOD)3, 1, Article 77 (February 2025), 26 pages. https://doi.org/10. 1145/3709727
2025
-
[21]
Mowry, Matthew Perron, Ian Quah, Siddharth San- turkar, Anthony Tomasic, Skye Toor, Dana Van Aken, Ziqi Wang, Yingjun Wu, Ran Xian, and Tieying Zhang
Andrew Pavlo, Gustavo Angulo, Joy Arulraj, Haibin Lin, Jiexi Lin, Lin Ma, Prashanth Menon, Todd C. Mowry, Matthew Perron, Ian Quah, Siddharth San- turkar, Anthony Tomasic, Skye Toor, Dana Van Aken, Ziqi Wang, Yingjun Wu, Ran Xian, and Tieying Zhang. 2017. Self-Driving Database Management Systems. InProceedings of the 8th Biennial Conference on Innovative ...
2017
-
[22]
Mohammadreza Pourreza and Davood Rafiei. 2023. DIN-SQL: Decomposed In- Context Learning of Text-to-SQL with Self-Correction. InAdvances in Neural Information Processing Systems (NeurIPS), Vol. 36. 28448–28472
2023
-
[23]
Lei Sheng and Xu Shuai Shuai. 2025. CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning. InFindings of the Association for Computational Linguistics: IJCNLP-AACL 2025. Association for Computational Linguistics, 1473–1496. https://doi.org/10.18653/v1/2025.findings-ijcnlp.91
-
[24]
Shayan Talaei, Mohammadreza Pourreza, Yu-Chen Chang, Azalia Mirhoseini, and Amin Saberi. 2025. CHESS: Contextual Harnessing for Efficient SQL Synthesis. InICML 2025 Workshop on Multi-Agent Systems in the Era of Foundation Models
2025
-
[25]
Bing Wang, Changyu Ren, Jian Yang, Xinnian Liang, Jiaqi Bai, Linzheng Chai, Zhao Yan, Qian-Wen Zhang, Di Yin, Xing Sun, et al. 2025. MAC-SQL: A Multi- Agent Collaborative Framework for Text-to-SQL. InProceedings of the 31st Inter- national Conference on Computational Linguistics. 540–557
2025
-
[26]
Xiangjin Xie, Guangwei Xu, Lingyan Zhao, and Ruijie Guo. 2025. OpenSearch- SQL: Enhancing Text-to-SQL with Dynamic Few-shot and Consistency Align- ment.Proceedings of the ACM on Management of Data3, 3, Article 194 (2025), 24 pages. https://doi.org/10.1145/3725331
-
[27]
Wenbo Xu, Haifeng Zhu, Liang Yan, Chuanyi Liu, Peiyi Han, Shaoming Duan, and Jeff Z. Pan. 2025. TS-SQL: Test-driven Self-refinement for Text-to-SQL. In Findings of the Association for Computational Linguistics: EMNLP 2025. Association for Computational Linguistics, 2864–2889
2025
-
[28]
Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. InProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing
2018
-
[29]
Tianshu Zhang, Kun Qian, Siddartha Sahai, Yuan Tian, Shaddy Garg, Huan Sun, and Yunyao Li. 2025. EvoSchema: Towards Text-to-SQL Robustness Against Schema Evolution.Proceedings of the VLDB Endowment18, 10 (2025), 3655–3668
2025
-
[30]
Chen Zhao, Yu Su, Adam Pauls, and Emmanouil Antonios Platanios. 2022. Bridg- ing the Generalization Gap in Text-to-SQL Parsing with Schema Expansion. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL). 5568–5578. https://doi.org/10.18653/v1/2022.acl-long.381
-
[31]
Zilio, Jun Rao, Sam Lightstone, Guy M
Daniel C. Zilio, Jun Rao, Sam Lightstone, Guy M. Lohman, Adam J. Storm, Chris- tian Garcia-Arellano, and Scott Fadden. 2004. DB2 Design Advisor: Integrated Automatic Physical Database Design. InProceedings of the 30th International Conference on Very Large Data Bases (VLDB). VLDB Endowment, 1087–1097. https://doi.org/10.1016/B978-012088469-8.50095-4 13
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.